◎正当な理由による書き込みの削除について: 生島英之とみられる方へ:
【統計分析】機械学習・データマイニング28 YouTube動画>12本 ->画像>12枚
動画、画像抽出 ||
この掲示板へ
類似スレ
掲示板一覧 人気スレ 動画人気順
このスレへの固定リンク: http://5chb.net/r/tech/1588293154/
ヒント:5chスレのurlに http://xxxx.5chb.net/xxxx のようにbを入れるだけでここでスレ保存、閲覧できます。
!extend:on:vvvvvv:1000:512
!extend:on:vvvvvv:1000:512
!extend:on:vvvvvv:1000:512
機械学習とデータマイニングについて語れ若人
*機械学習に意識・知能は存在しません。
人の意識に触れたい方はスレ違いです
■前スレ
【統計分析】機械学習・データマイニング27
http://2chb.net/r/tech/1578892284/ スレ立ての際は、一行目冒頭に
!extend:on:vvvvvv:1000:512
をお願いします。
VIPQ2_EXTDAT: default:vvvvvv:1000:512:: EXT was configured
多次元weightを持つnodeの有向グラフに使えるgraph embeddingの実装に心当たりありませんか?
karateclubに入ってる実装では、有向グラフは扱えなかったです。
10万貰ったらグラボ更新しようかと思ってるんだけどみんなCPUとGPUは何使ってる?
>>7 どさくさに紛れて
何をやってるのか!
橋本かんなで
抜いてるだろ!
タイホする!
初心者です。
「0から作るディープラーニング」読んだけど、肝心の難しいところの説明を全部省いておいて読者に簡単だと印象づけるうまさはさすがだと思った。
結局、数学できない人間は騙されるってことか。
今、「パターン認識と機械学習」を勉強中。
「0から作るディープラーニング」の3は良さげだぞ。
数式の意味するところがなんとなくでも理解できるくらい
数値計算の行列操作においてはジョルダン標準形は全く使わんけどね。
一番難しいのは理論より変数探し
無限に広がるリアル世界と数値化まで終っているkaggleの違い
今更になって専門家会議がPCR検査の少なさを批判して
人手がどうこうとか言ってるけど
オリンピックがあるからか知らないが蔓延する前から検査する気なかったよな
スタートから「検査数を絞って、、、」とかやってなかったっけ
いつから「検査をしなければならいが体制が整わない」になっちゃった?
たまたま日本は文化的に感染しにくかったというその部分をひたすら強調して
死者数も経済復旧までにかかる日数も少なくすることが出来たけど
しなかったという事実は無視するということだね
「0から作るディープラーニング」は、畳み込みの所で、「連鎖律使うと時間がかかるので、行列を変形して全結合として逆伝播の計算してます」と一言説明してくれれば、1週間の無駄な時間を節約できた。
コロナ対策成功は政府のもの。コロナ対策失敗は国民の責任。
わりとこんな感じよ。
>>25 今もやる気無いよ
検査すると感染者増えるからねω
毎年のインフルは患者数(感染した上に症状が出ている人)をカウントしているのに対し
今回のコロナは無症状の感染者数までカウントしているから、
相当、混乱しているんだな
データ以前の状態で分析屋の出る幕無し
だからサンプリングに偏りがあるときには
統計的な処理は全滅なんだって
統計学の初歩中の初歩
欧州帰りの医師、テレ朝グッドモーニングにインタビュー編集され愕然 「PCR検査増やすべき」と真逆に
http://2chb.net/r/news/1588852625/ どう考えてもスタートの段階でPCR検査増やさなかったのは失敗だろ
検査しない方が正しいと主張していた奴もたくさん居たが
そいつ等もいつの間にか体制が整わないのに
検査数を増やすのはおかしいという主張に変えたのか?
いいとこだけ切り取って繋げるメディアとやってること同じだけど
検体採取怖いやん。韓国みたいに兵役免除の餌があればええけどな
>>37 最初に決定したプランA は保健所主導のクラスター追跡で、これは割合成功したほうだと思います
問題は、感染が広まってしまった後でもプランAを墨守し、プランB = PCR 検査を増量する方針に切り替えることができなかったこと
プランA で時間稼ぎをしているボーナス期間に、プランB を実行するキャパシティを増強すべきだったのだが、時間的ボーナスを有効活用できなかった。
神戸で無作為抗体検査をした結果、3.3% に抗体がみとめられ、これは人口に換算すると 5 万人は感染、という悲惨なありさまですね。
>>38 そんなもの金で解決すればいいでしょうね
一回採取すれば 3 万円の謝礼、とかが効果的でしょう、そういうことすら決められないのが問題なのでは?
結局は現状肯定が先に来てるだけだからな。
社会に対して問題を感じたくないんだよ。
結局「感染数」の遷移を基に政策を決めるのか
実際の感染者は「感染者」よりもはるか多いのは確実だから
感染爆発しても知らないよ
>>37 > 検査しない方が正しいと主張していた奴もたくさん居たが
誰か言ってたな。
検査すると医療崩壊が起きるとか言ってたような。
ぶっちゃけ正しい意見だと思ったけどな。
抗体持ってるのが5%から8%ぐらいだっけ?
全員検査したら一瞬で医療崩壊起こしてパニックだぜ?
と思った。
既に持ってる人がいる抗体は新コロナ対応なのかね
普通の風邪の旧コロナ対応の抗体だったりしてな
偽陽性が5%とすると全体検査したら5百万人の自宅退避や隔離が必要。
死者が抑えられてるんだから現状は問題ない
ケンサーズは身内だけで盛り上がってほしい
コロナなのにコロナ認定されずに死んだのがどれだけ隠れているのやら
結局事実上8000萬人から9500萬人くらいは自宅退避状態やん
>>47 葬儀屋が感染しないのが不思議なんだよな
観戦者の職種別グラフとか出せば良いのにな
あっ感染源不明ってあれのことか
>>43 で、自分は受けてた人いましたね(しかもほぼ平熱)。
どこぞのテレビタレントで知事なんかもやってた人だけど。
そういう人は四日待って実際死んだ方に何か言うべきだと思いますよ。
岡江さんは我慢し過ぎたね
持病あるんだからもっと早く検査出来てればなー
全体最適を優先するなら軽い症状の人はそのまま放置しても回復する可能性が高いから検査しないのが最適解
ただただ自身の命だけを優先するならわずかでも死亡の可能性はあるのだから軽い症状でも即検査が最適解
正確な情報がなんでそんな簡単に取れると思ってるのか。
>>49 幼稚教諭・学校教師・電車の運転士・ナス・医者あたりは
2,3年で耐性が高まる体質のやつしか残ってない業界の件
>>52 今はまだ買えるから血中酸素濃度計を買って、
やばくなったら病院へ がベター
ベストは
おまいらがスマホのライト&センサーを使って
血中酸素濃度を簡易測定記録するアプリを作って公開
>>54 それそれ
PCR検査よりも血中酸素濃度測定をした方が現実的
重症者、死亡者は血中酸素濃度の低下を経由することが多いので
少しでも熱や咳があれば、とりあえず病院とかで検査するのはこちらかと
>>55 パルス-オキシメーターを買いました
中華製なら \5k, 国内メーカーなら \50k 程度
>>56 マスクとかガウンが品薄になって医療現場が困っている二の舞になるので
個人で買うなという製造側の警告がある
やっぱおまいらがAndroidで動く血中酸素濃度ロガーつくれよ
>>57 なるほど、一理ありますね
でも中華製 \5k なら、まあ問題にはならないかと思います
>>60 いいえ、単に安くてそこそこの値が出るのなら一家にひとつあってもいいと思っているだけです
別に測定しなくても、血中酸素下がったら息苦しいからわかるだろう?
それで「あなたは検査の対象ではありません。」と50回電話してやっとつながった後に言われるんだ。
ゼー・ゼー・ゼー
>63
トロントでなにやってる人?
あるいはVPNですか?
これで日本がしっかり検査してると思う理屈がわからんわ。。知性がないのか?
マスゴミの世界でもネットの世界でもリアルの世界でも
コロチャンをチャンスと観て工作員が活動している
これはサヨクもウヨクも同じ
そいつらに惑わされずに平等に客観的に事実を観ようとする姿勢が大事
漏れはどちらかというと右派になると思うが
***少なくとも岡田のおばちゃんは初期の段階ではまともなことを言っていた***
日本の対応は政府が無能だったから今回の事態になってしまった
もちろん足を引っ張った野党の責任も大きい
現実に合わない理想を唱えてもしかたがない、そもそもPCR検査は万能ではないが
>>64 vpn ですよ、いまどき生でつなぐとかありえないと思いますよ…
>>49 死者の総数が例年に比べて増えているデータも無いわな >感染者隠蔽論
検査数を増やして現状を把握することは必要だけど、方法論はなんでもいい。
未だにPCRだけを連呼してる奴が一定数居るけど、別の病気にかかってそう
万能ではないがそれすらできてないから言ってるんだけどね。。
馬鹿はあの手この手でやらない理由を掘り出してくる。。ありゃもう病気だよ
中国も中国でここまで拡散するとどうなんだろうな?
アメリカは中国が意図的にやったとか言ってるけど
武漢研究所でコロナの研究やってるし論文も2019年に出てるし
コウモリのコロナウイルス研究を行う研究者を雇用してたんだろ、、、
証拠を隠滅してるだけで状況証拠的には
研究所が作って漏れ出たものを封鎖出来なかった臭いけど
「真珠湾攻撃よりひどい」とかトランプが言ってるけど
「発生源で止めれたはずだ!」とか
あのまま
中国「私たちは被害者だ!」を貫き通すのか
どこかの国から検査キット買ってくれって頼まれてんのか?w
手書き数字を認識するニューラルネットワークがありますが
ニューラルネットワークを使わなくても認識させる方法を思い付きました。
以下のこの方法はニューラルネットワークよりも有効でしょうか?
良い方法だと言えますか?
28×28ピクセルの画像の中で、数字によって塗り潰されたピクセルは
数字によって違ってきます。
その数字ごとに統計をとれば、この数字はピクセルの中のこのピクセルが塗り潰される確率が高いとわかります。
それによって、認識させたい数字を入れたら
その数字は何かわかると思います。
「28×28ピクセルの画像の中で、数字によって塗り潰されたピクセルは数字によって違ってきます。」
この前提が間違い。ピクセルの位置を基準したのでは、1ピクセル上下左右に動かすだけで全く違うものになってしまう。
>>80 ある程度の範囲内のピクセルとしたらどうなの?
例えば1なら真ん中あたりに、縦に塗りつぶされる可能性が高くなると思う。
実際はピクセルの組み合わせに対する分布だったりするからね。
それだと確率を考える空間が広すぎるからニューラルネットワークで次元圧縮を良い感じに学習するわけだ。
ニューラルネットワーク以前も、文字を細線化して方向抽出したり、って研究は山ほどなされてたけどね
>>79 やってみてニューラルネットワークの結果と比較したら判るだろう
自分の勘だとそんなに良い結果にはならなそう
>>79 数十年前の郵便番号を自動認識するアルゴリズムはそんな感じ
当時でも実用に耐えうる性能は出せた
文字の種類が増えるとその方法ではほぼ無理
機械学習のサポートベクトルマシンでも一応は出来ますよ
というだけの話
>>81 畳み込みやプーリングしたあとに、クラスター分析すればけっこういい結果は得られそうだけど
標準から大きく逸れたデータがあると対応できなさそう。
SVMの方が結果が良かった事もある(最適化が足らんかったかも)
精度っていうよりは計算量の話で、ランダムフォレストでよくね?
一昔前はSVMやブースティングでやってたみたいだよ
パンチョッパリがクソチョンw
韓国に住んでる朝鮮民族は普通の韓国人
日本に住んでる朝鮮民族はゴキブリ以下
死亡率では~言ってた馬鹿、これ見て土下座してくれますかね。
https://news.google.com/covid19/map?hl=en-US&;gl=US&ceid=US:en
>>91 問題によるんだろうが、計算量はNN>>>RFだと思ってたのに
NN評価してみたらGPUなしでもRFより学習速くてワロタ
TFの実装が優秀なのもあるんだろうが、やっぱ単純な積和演算の塊だから速いんかね
NNの方がOL対策もしやすいし、RF存在意義ないじゃんとオモタ
あと、仕事ではSVMも使ってるよ
精度が多少劣ってもいいから、モデルサイズとpredictionの計算量を抑えたい
組み込み向けね
>>100 その辺の制約はハードウェアの進歩で解消されていくだろう
20年前は今のディープラーニングは実現できなかったかもしれない
量子コンピュータが実用化したらNNじゃなくて組合せ最適化の方が良い結果を得られるかもしれないし
>>99 回帰ではRF系の方がカクカクだけど安定感あるイメージ
DLより単なるolsのほうが
精度が良いなんていくらでもある。
Ordinary Least Squares regression
ヒトの脳には
BERT的なものが備わっているのかな?
詳しくは引用論文よめ、ってことだろうけど
オラクルはオラクルマシンのことかと
要はアルゴリズムは不明(計算不可能かもしれん)だけど仮にベストがあるとすればこれ、ってやつ
ソフトバンクG最終赤字1兆4381億円、1~3月期
T-モバイルをドイツテレコムへ売却交渉中
禿げザマー
顧客対応酷いからね、一度離れたユーザーは二度と戻らないだろう
pepperの怨念が溜まってるなら、ちょいと関係ある
国連から表彰されても引退なの?個人アプリ開発の世界は残酷だ。
https://appmarketinglabo.net/leorivas-interview/ 「約3年で1,180万円を稼いだ、いま広告収入は月100万くらい」地味だけど
寿命は長い「電卓アプリ」実際に効果があった5つの施策。
https://appmarketinglabo.net/calculator-1100man/ パチスロ生活しながらアプリ開発で1,500万円稼いだ「ダメ人間」が語る、ソシャゲと
パチンコ パチスロの客層融合説と、電卓アプリ作者が語る3年の収益推移
https://appmarketinglabo.net/pachislotapp-damehuman/ 1日に3〜5万円だったアプリ収益が「プロモーションで大化け」数百万円を稼げるように。
AppLovinが語る「ハイパーカジュアル」の可能性と成功のコツ。
https://appmarketinglabo.net/hypercasual-applovin/ なぜそこにアラブ人。スマホゲームに飢えた「アラブの課金王」国境を越える。そこに
「存在しないはずのアラブ人」が欧米のアプリストアをつかう真実。
https://appmarketinglabo.net/arab-mobilegame/ 約4年でアプリ売上1億円。副業からスタートしたアプリ開発会社「AppStair」が
730万ダウンロードを達成し、メタップスに買収されるまで。
https://appmarketinglabo.net/appstair-ma/ > お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
またまた朝鮮人の犯罪!!!
> 職質中逃走の車、ひき逃げ歩行者は死亡、運転の31歳女逮捕 東京
> 逮捕されたのは、川崎市川崎区藤崎の飲食店店員、中川真理紗容疑者(31)。
この中川は朝鮮人!!!
本当に朝鮮人は残虐な犯罪者ばかり!
朝鮮人は皆殺しにすべし!
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
【Twitter】中国系AI学者が独立取締役に就任→トランプの投稿に「根拠無し」と警告w
http://2chb.net/r/news/1590615046/ どうすんの?
>>123 上級国民さんはトロントで何をされてるんですか?
>>124 横だけどQZはカナダ(シナ、チョン移民が多くて人種差別がひどい)にいるの?
>>125 VPN のカナダサーバに接続いでいるだけですよ…
ひどい目にあったから、もう生 IP で接続することはないでしょう
>>129 私が荒らしたことなどありましたかね?
記憶にございませんが…
心当たりがあるだろう!胸に手を当てて考えなさい!(適当)
>>130 >>71で異なるVPNを利用した理由は何故でしょうか?。
また、現在は元に戻した理由は何故でしょうか?
>>71のみニュージーランドとなっているのは何故でしょうか?
>>130 上級国民とは貴方にとってどういう意味を持ちますか?
>>133 カナダとかオーストラリアとかニュージーランドとか、いろいろ回して試してはいます
>>135 お布施するかわりに便利に使わせてもらっています、ただ、それだけですね
>>136 とりあえずQZトロントさんとお呼びしてよろしいでしょうか。
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
どなたか初心者に特異値分解を詳しく説明した参考書かサイト教えて下さい、エロい人。
高校数学でやった行列の対角化の大人バージョンという認識でOKですか?
ある種の一般化?
なお、一般化の方向はいくつもある
ゼロから作るDeep Learning2でSVDでてくるけど、共起行列は対称行列なんだから、ようするに対角化して次元削減ですねよ?
>>147 (A^T)*AとA*(A^T)の固有ベクトルも求めないとだめですよね?
>>142 これ読みなはれ
線形代数セミナー: 射影,特異値分解,一般逆行列 金谷
機械学習に数学はいらないから
線形代数なんて勉強しなくていいよ
>>154 A=U*Z*(V^T)のUかVかとちらか片方だけでいいの?
>>154 解像度の選択の問題です。
常に大きい正方行列となるほうを選んでおいたほうが、得られる情報が多く、何の情報を捨てるべきか選択できる一方で、正方行列が小さくなるほうを選んだ場合は計算負荷が小さくできるメリットがあります。
行列を大か小何れかを選択するのは、計算負荷を考えて最初に選択すればよいだけです。
>>151 ㌧クス
>>152-153 どうやって結果を検証するんですか?
学習は for ループで既存のライブラリを呼ぶだけ
パラメータ調整も近頃全自動でやってくれるし
お金を出せば GPU とか借りられるし
数学とか専門家の出る幕はどこ?
>>158 そのライブラリを直接触る時に必要になる
数学分からない人はハイパーパラメータの扱いが錬金術にしかならなかったりベイズ的な拡張の仕方を理解できないだろう
そういうライブラリあったんじゃないか
ベイズで最適化してくれる奴
随分そっち系のコンペに参加してないんで
今どうなっているのかは知らないが
数学分からないと「ベイズ使いました」っていう最低限の説明を人にできんでしょ
ベイズというのは「パラメータに確率分布を仮定する」程度の意味しかないので「ベイズで最適化しました」などと言われてもほぼ意味をなさない
意味のある説明をしたければ数学の素養が不可欠
昔々Geman&Gemanという論文があってだな、たいそうもてはやされたそうだ
しかし聞く方もそんなに数学の知識があるわけでもないので
>>164みたいな説明でもokだったりする
ベイズ推計はこれがお勧め
データ解析のための統計モデリング入門 久保
久保本は統計検定2級レベルがギリ合格点取れる程度に理解できていれば読める
データに基づいてパラメータの値が取る分布を更新するって感じじゃないかな
>>169 統計検定は知らんけど赤本の予備知識で読めるだろ
研究者っぽい奴が多いな
現実的にはベイズなんて知っていても知らなくても
少しでも成果が出ているなら多少なりとも話題になっているであろう
その何種類かある似たようなライブラリを試して
いい奴をチョイスするだけの話し
スコアを上げる為にやらなければならないこと
試さないといけない別部分での新手法的なものは他にもたくさんあるだろう
ベイズよりカーネルとのコンビネーション考えたほうがよい。
カグルでさえハイパーパラメータの知識必要なのに意味わからずライブラリ使うだけだから日本は遅れてるのでは
逆に糞みたいな理論ばっかりおってるからNASでガツガツチューニングするようなやり方に負けるのでは?
そんなkagglerいる?
論文はみたことあるけど
東大のやつで
いやkaggleの話でなくてな。。そういうスコアゲームに熱上げる奴バッカだからじゃねーのって話でもあるな。
ハイパラも数学も分からない機械学習屋って、好意的に見てエンジニア業務にほぼ特化してるてことでいいのか
自分で説明すらできない物を納品してきてエンジニアを自称されても困る
>>179 でも深層学習の中で何が起きているのか誰も説明できないよね
何をやってるかは当然わかるけど、結果は入力するデータ次第だからね。
機械学習をもう一段上から制御する「意識」みたいな仕組みが必要かもしれない。
>>182 旬の野菜、みそ炒め、揚げびたしがお勧め
NAS(Neural architecture search)
秋茄子はトマス
NAS(Network Attached Storage)かと思っていた
Zornの 補題により有限個までしか分解できません
どの学問領域になるかも不明だろうけど、数学ではないし一番近いのは物理学か情報科学だろうね
学習の理論的解析では統計力学的アプローチが続けられてるんだろうし
運転中に可愛い娘を観かけたら脇見運転するのが意識というもの
理系エンジニアが言いそうなことは万国共通なんだな
>>184のコメント
AI開発者を大量に採用してた大手もリストラして残す奴を絞り出してるし
バブルが弾けて適正需要に落ち着きそう
機械学習研究者は残るけど
api叩いて終わりどころか
データ投入だけであとは良きに計らえでなんとかなれば
そりゃ機械学習エンジニアなんていらないよね
>>202 日本企業は正社員を簡単に首にはできないが、リストラする話はソースあるのか?
特に大企業は労組あるから厳しそうだが。
>>204 不可能ではない
過去にいくつかの大企業で早期退職募集とかやってる
子会社に出向させたり部署単位で分社化して給料ダウンしてコストカットとかよくあるれい
>>204じゃないがuberあたりのこと指したのかと
>>206 リストラの実現手段の一つとして早期退職募集もあるんじゃないの?
サラリーマンって切ないよな
卒業した時に好景気か不景気かでもう人生ガラリと変わる
頑張って会社に入ったとしても運的要素が強い
いい大学出ても横領した30億円をFXにつぎ込んで溶かした挙句
逮捕された人もいるし
何がいいのか
>>212 日本人に生まれただけで超勝ち組
こんな平和で幸福な国は他にないよ
>>197 >学習の理論的解析では統計力学的アプローチ
それ古くないですか?
>>212 世の中の大半の職業はサラリーマン以上に景気や運に左右されるだろ。サラリーマンより安定しているのは公務員くらいじゃね?
>>214 何が古くて何が新しいのでしょうか?
統計力学も情報幾何も情報量の加法性(A利氏著の本の表現より)を仮定すれば、エントロピーのような共通の構造は見え隠れします。根本にある原理は同じと思いますが…。
>>212 経団連も通年採用とか言い出してるし
コロナでテレワークとかも導入されてるとこもあるし
会社によっては基本テレワークみたいなとこもあるし
変わっていくのでは?
自分にとっていい方向か悪い方向かは判らないけど
>>218 会社の体質はそう簡単に変わらんし、シナ礼賛の経団連だし、東芝の例もあるし
東大発AIベンチャー企業元取締役だっけ
なんで30億も横領してFXにつぎ込んだんだろうな
利益だして30億円は戻すつもりだったんだろうか?
東大出身で「俺が負けるはずはない」と思ってたんだろうか?
会社の金30億円を私用で使ってほとんど溶かすってどういう感覚なんだろうな
45歳だっけ
会社ぐるみでやってた可能性は無いんかな
一人でかぶって握りつぶしたとかさ
東大卒はその他大卒にくらべ
統計的に
詐欺だの横領だの贈収賄だのといった犯罪で捕まる確率が高いぞ
横領や収賄に関わるのはそれなりの地位や権力、資金のある立場の人間だから、東大生の比率が高いという相関があったとしても何ら不思議はないと思うが。
ヤバい経済学って本でも、会社での地位が高い人のほうが低い人より支払いをごまかす傾向にあるって話があったな
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
医療系AIベンチャーじゃなく、ファンドでAIにFX予測させますと謳っていればセーフ?
負けて損をしても投資した奴の自己責任
>>228 まあ誤魔化しても下の奴より咎められない世の中だってのはあるか。
てか電通の中抜きなんてほとんどヤクザの世界だろ
中抜きって便利な言葉をマスゴミは生み出した様だが
判りやすくピンハネって言えば良いのにな
なんでピンハネって言わなくなったんだろ
>>231 最近あやしいバナー広告でよくみかけるもんごんだな
>>233 中抜きって不要な中間業者を抜くことだと思ってたけど違うんだっけ?
ピンハネさせないように中間を抜く、中抜きするだと思っていた
ちょっと検索してみたら両方の使われ方があるようだな
同音異義語で意味が反対になる
中間業者を抜くのと、中間の金を抜くので意味が逆になるのか
後者の意味を誤用と書いてる人も居るのに、マスコミ用語として定着しちゃってるのか
文脈で明らかに分かるものをわざわざ定義がー、辞書がー、とか言う人って頭悪そう
中抜きくらいなら意味もまぎれんかもしれんが、キャプションしか読まんような人も居るのにマスコミがそんな適当な言葉遣い許されんでしょ
>>228 昔武田鉄矢が今朝の三枚おろしで
文武両道の時代はまだ時代的背景や風潮みたいなものを考えると
理解できる行動が多かったけど
日本帝国軍になって軍上層部が勤勉エリート軍団になってから
有り得ない行動が増えたとか言ってたからな
巨人みたいに4番ばかり集めても勝てないとか
アンサンブル学習みたいに似たような優秀モデル同士を組み合わせてもスコア伸びないとか
混ざらないとダメなんだろうな
総理、副総理あたりは
優秀であればそれに越したことはないけど
回りに優秀なのがいればいいんじゃない?
元々学生時代の専攻が統計学・機械学習よりでそれで就職したが、
もうデータサイエンティストよりプログラマや他職種のが良いんじゃないかと思える。
コンサル屋もどきな業務で、業務時間の8割はパワポ作成。何を分析しても
上司・客からNG食らえば成果とはみなされないのが不満。
逆に客からOKがでれば、どんな分析をしてもいい、別にデータ使わなくても良い。巷で言うエクセルしか
使えないデータサイエンティストは実在するよ。それよりゴマすりの技術や、作文技術を磨いたほうが客から
OKが出やすいから、しょうがない。
自分にはそういうのが向いてないとつくづく感じる。
むしろコミュ障でもスキル積み上げのできるプログラマの方がいいんじゃないかって
最近は思っている。
あと最近東大生にデータサイエンティストが人気というのも理解できない。
なにか、論文から手法実装やライブラリ開発が仕事のメインなんだろうか。
名前が同じ、全く別職種だな、それだとしたら。
頭が良い、数学できるから目指すってのも安直すぎるし。Pythonのライブラリで数行でおわる分析の
数学的仕組みを説明できる必要もなければ、できて感謝される事なんてまず無い。
むしろ過学習しまくりのよく見える方がありがたがれるまである。『このデータ量・種類だと深層学習でも
〇〇程度が関の山です、他の課題設定が良いです』よりも、『R2乗98%の結果を、深層学習手法で実装しました』、の方が
客の納得感あるんだよなあ。残念なことに。それに比べて分析の正しい知識は、夢のない解決法に行きがちだから。
>>247 プログラマもおんなじようなもんよ
30までは黙々とやってていいけど、年取ったら口が上手くないと
どんな商売もそんなでしょ
そんななら公務員か電車の運転手がいいぞ
向いてない職種で頑張るのも一つの手だが
体調崩してまでやるぐらいなら早めに方向転換した方がいいぞ
テストでいい点を取ることと会社で高い評価を得ることは別物なんで
運転手や第一次産業に行くのも長い目で見れば悪くない選択かもしれない
>>250 口”も”うまくないとやれない、ならまだわかる。プログラマー上級症としてのSEは理解できるが。
問題は、機械学習の理論知らない、プログラムできない、分析内容は過学習しまくり、
でも、パワポだけピカイチ、みたいなのが持て囃されるのが現状。
コミュ力も要る、ならわかるが。
職務年数長くても、積み上げが無さそうなのがイヤ。
エクセル職人の上級職なんか?
業務詳しくなって総合職になった方がよかったりするのかねえ
>>247 ビジネス的には相手方のキーパーソンがOK出せばいいからな
データ分析をしっかりやっていても
相手に理解できるようにプレゼンできないと無駄になる
相手があまり深掘りしないならデータ分析に時間かけても表に出ることはないかも
長期的に取引するなら後々変なことが起きて問題になって取引停止とかになるリスクはあるけど時間もかかるし必ず起きるかどうかも判らない
運転手なんてそれこそ
自動運転で一掃されそうじゃん(笑)
一年くらいそのプロジェクトやってるのに実は中身まるでわからんとか
普通に言い出すのがSIerだからな。。頭抱えるわ。。
>>241 キャプションしか読まん人が居るのを判ってて
わざとやってるマスゴミは卑怯って話では
全文読まない人にも理解させることを前提に記事を書くならキャプションにも全文相当の説明を追加する必要があるがそもそもそんな長文を読まない人を対象としているわけで
他に専門があった上でのプラスアルファとして機械学習が使えるのがいいね
>>262 完全に同意
機械学習は問題解決の一手段に過ぎない。専門の軸足は別のものにおくべき
パワポ、エクセルもきれいに書いてあるだけで
何が言いたいのか全く分からないものもの多いんだけどな
問題提起も方法論も評価も結論もはっきりしない
これで客は喜ぶのかね?
データが欲しい
おまえの考えなどどうでもいい
そういう要求に応じる資料もある
逆にそいつより評価低いとか
よっぽどだと思うけど
本人が気付いてないだけで
何か特別な問題がありそうな気がしてならない
説明できない理由は大体ろくでもない
気が弱そうだから毟れそうとか
顔が汚いとか
低レベルな環境にいる時点で自分もそれと同類だと認識できないと
ほんとはたから見る程度じゃ
仕事できるイメージなんて
偉そうな面してるかどうかだけだわ
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
>>254 日本じゃ、御用聞き型の案件受注が主流になってるから、仕方が無いし、
論拠より感覚を重んじる適当な仕事する奴に決定権与えてるのは客だから、これまた仕方が無い
コミュ力が一番重視されるのは故に
発注側が出来なすぎるんだよね
物事の定義が難しいみたい
論理的じゃないのかな
給付金の額と範囲決めるのに、誰それのの顔を立てるように総理が配慮して決める国だからね。
所謂できる人は、その辺も読み切って提案考えんだろね
それぞれの顔を立てるから両者が 満足しない ところに落ち着く
結果誰も得をしないって言う(笑)
さすがにそろそろ揺り返し来ると思うがな。
こなきゃ海外逃亡した方がマシなくらい今の日本ヤバい。
日本のIT産業の殆どがメーカーなどの下請けと言うことを考えると
機械学習や深層学習など流行るわけがないと思ってたよ
氷河期がついに来た
>>279 第3次AIブームの終わり:AIの「冬の時代」
https://slofia.com/long-term/the-end-of-third-ai-boom.html 第1次AIブーム:1950年代~1970年頃(約20年)
第2次AIブーム:1980年代~1995年頃(約15年)
第3次AIブーム:2010年代~2020年頃(約10年)
日本のエグゼクティブの爺さんたちは、ハンコの必要な書類に目を通すのが仕事だ。
どの会社も役員室でもPCはお飾りで、印刷した紙を読んでいる。
そんな連中がAIの利点なんて実感できるはずがない。
定着はしてるけど、そもそも実用化できるかわからないリスクを負ってしまうのが最悪
人間の判断なら信用できる、ってのもなんだかなあ
機械だから信用できる、ってのもおかしいけど
結局信用するかどうかはその人の判断だし
責任は人間しか取れない、ってだけだと思うよ
完全自動運転なんかだと特にシビアに問われるけど
コロナショックに自動的に対処してリスクを低減しようとする動きができる自称「AI」はどれだけあるだろうねえ
人間の判断ってのはそういうこと
人工知能も家電製品も
衣装ケースにかくれんぼしてたとか
チェーンソーで庭木の手入れ中にとか
洗濯機でペットを洗おうとしたとか
電子レンジでペットを温めようとしたとか
包丁や拳銃の責任割合は何%だ?
爆弾の責任は誰が取るのか?
とほぼ似たようなトロッコ問題だろう?
>>286 コロナショックとやらを明確に定義してやればコンピュータで対処できる範囲内では人間より圧倒的にコンピュータの勝利でしょ
なんで自動運転の試験急にやめちゃってそのままなんだろう
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
>>289 事故が起きた時の責任の取り方が決められないからでしょ
乗ってた人なのか、プログラマなのか、データを集めた人なのか
この辺の人に業務上過失致死を負わせるわけにはいかないだろうし
法律系の人から言えば、人が死傷したら誰か人間が責任を
取らなければいけないわけだし。
個人的には保険金を払ってはい終わりでいいと思うけどね
>>285 現状では予見不可能な事は人間も責任は問われない仕組みだと思う
責任を取るといっても元に戻せないこともある
例えば生き返らせるとかはできないので
お金で解決するくらいしかできない
責任の取り方としては
人間か機械かは関係ないものもある
まあ言い換えるとトラック運転手が何で儲けているかといえば
過失責任を担保することによって儲けてるといえるわけだ。
日本は保守的なんで新しい分野に対しての対応なんてそんなもんだろう
外資が突っ走ってそれに追従する形じゃないと
団塊世代がトップに就いた頃からもう自分の時代さえ良ければいいと思ったのか
既得権益を重んじたのか国内で芽が出そうな分野を潰してきた節があるけど
日本は年功序列なんで
保険だと事故などの確率が低い方が保険料を安くできる
AIなどを活用する事で例えば交通事故確率を下げられるのなら保険料は安くなるしそもそも事故が起きなければ責任を取る必要もなくなる
金で解決できるのは民事上の責任だけだけどな
確率低いから安価の保険で民事の賠償が賄えても刑事罰・行政罰は誰かが受けなければならない
>>301 刑事罰の対象になるようなこととは限らないと思う
悪意があるとか予見可能性とかそこら辺も絡んでくるだろう
Adversarial Examples を恣意的に入れた犯罪とか立証難しいだろうしな。
悪意なくても、自動運転で偶然道路に見える服とかあったりな
雪で線が見えなくなったら?
前に名古屋で大雪降って大渋滞に巻き込まれたことあるw
>>304 ドピザがダークグレー地に白ゴシックで「ウェェェェイ!」って縦書きになってるTシャツ着てたら。。。 :((´゙゚'ω゚')):ガクブル
>>305 それは予見可能な範囲だろうから対応できてないと作った側が責任負うことになりそう
そういうケースでは人間でも見間違えると思うよ(笑)
自動運転不能な状況になったら停止するとか
人間に代わるとかして制御を明け渡すようにするのが無難か
多くの場合は停止すりゃいいんだろうけど、トロッコ問題みたいに人の命の二者択一の場合もありうるから
人間のバグに起因する事故は、開発者の神に責任をとってもらおう
トロッコ問題っていかにも文系の人が考えた問題設定 だよね
http://moralmachine.mit.edu/ まあ自動運転で何を優先すべきかはパラメータで決まることになるんだろうけど
>>314 投票して政策を決めるみたいなもので
最終的にはその時代のその地域の社会の多数派の考えに近いものになる
哲学とかやってるのは
金持ちのボンボンの世間知らず
>>308 もしあなたがこの業界の人ならば、そういう意見は今後やめたほうがよい。
第三者から聞けば只の言い訳にしか聞こえない。
人間より運転の上手いaiができたら
人間の責任はより重くなるかな?
ならないよね?
>>320 第三者から見ればあなたの意見はどうでもよいと言っている
ついでに言うならば…
>人間より上手いaiができたなら…
それを法的に立証するのは難しい。
>>320 ならない
今、実は馬は車両として使っていいことになっている
馬だから責任重大なんてことはない
いくら技術がハッテンしても、かWラナイ物はある
が、今後変わるかもしれないなー
>>323 何かしらの公的な公表数になるならば、単純に事故の立件数になるだろう
よほど乱暴なら各交差点の事故件数になるかもしれないが、今みても乱暴とはとても思えない
むしろ名古屋のほうがよっぽどヤバイ
>>325 十分な検証数まで達成するのにどのくらい時間と事件数が必要だと思ってる。
>名古屋のほうが…
論点をずらすな。
>>320 >人間より上手いaiが…
死亡事故が一件でも発生した場合、そんな言い訳は通用しない。
法的、とか言っちゃう部外者来ちゃった(笑)
分からんなら黙れ
>>327 あなたがよくわかってないみたいなので申告してるんですよ。
>>308は只の言い訳にしか過ぎない。理解してますか?
>>326 >十分な検証数まで達成するのにどのくらい時間と事件数が必要だと思ってる。
はい、俺はもうそれが十分な数で検証されて人間以上に運転が上手とと知っています
>>327 はい、死亡事故は発生していますが人間の運転事故の数万分の一です
責任はメーカーが負っています
実質的に事故が減っているので社会貢献していますが、何が問題ですか?
プログラムで事故が起きると問題ですか?それが老人やてんかんが起こす事故を防いでも問題なのでしょうか?
>>331 自動運転 キロ数
で検索してもらっていいですか
結論から言うと仮想空間では100億キロ走ってるんですわ
>ワッチョイ 96da-n0yj
何を言いたいのだろう
今後自動運転が走り回るのは確実で、ビビてるのはあなたみたいな一部の方だけ
死ぬほど検証実験をしているのでソースなんて無尽蔵にある
絶対に論破されるだけだぞ
>>333 ???
いずれの記事も高速道路っていう条件付きのように見えますが…?
法的に実際の自動運転の許可は降りてないはずですが…
>335
「法的に実際」とは何を表しますか
不思議なことに、「法的に実際」に禁止されているとしても、何故かビュンビュン走り回っているんですよねぇ
なんででしょうか。法律がおかしいのでしょうか
正直、全然意味がないのでそんなもんは調べませんが君が否定したいのなら論破して下さい
なぜ自動運転車が法律も整備されていないのに闊歩しているのでしょう
>>336 前の車を追いかける機能と間違えてない?
カチンとくるけえ
こんなアホが運転するなら確実にAIのほうが良いだろう
>>333 仮想空間て只のシミュレーションでは??
まさかこれを実績と言っている???
>>340 無い。
クソみたいな法律とクソみたいな企業のコラボで100mぐらい移動しただけ。確かそれでも問題あって死のうかとおもった
まぁ俺は国産自動車は諦めたな。nVidia+トヨタがなんか作るだろう
自分がやりたいことが法規制でできない=法律が悪いからとっとと規制とっぱらえ
みたいなことしか言えない人の相手するのは面倒臭い
規制緩和ってそういうもんでは?
まあ、ここで上がってた話は別に既得権益の問題ではないけど
現に日本でも自動運転用に法改正されてるわけで
自動運転で首都高なんか走らせたら確実に事故ると思うわ
ぜーんぶの車が自動運転になって
相互に通信できたら
相当事故や混雑が無くなるんじゃない?
>>322 事故が起きないようにする方向の努力と
起きた時の被害を少なくする努力と
両方必要
車で言えば両方とも停止する速度を落とすのが効果的だと思う
円滑な交通の観点では停止しない方がいいとも言えるし
事故が起きると通行止めになるから一旦停止した方が良いとも言える
レベル5の自動運転を実現するには現状すごいスペックのパソコンが必要とか見たけど、すげぇリソースの浪費でエコと専ブランド反対や
リソースの問題て大概あとで解決するし
使えないといま断罪してしまって忘却するのは早計
Jetson Nanoは、CUDAが使えるエントリー開発者向けキットが$99でんがな
しょうもない自動化するよりも東京をバイパスできる高速作る方がよっぽど効率的だがな。
>>350 Yes
>>357 既に外環道とかいうのの計画は途中まで進んでるぞ
使うとジッサイベンリ
首都高レースゲーム内ではまだまだ
互いにぶつかりまくりなんですけどね
外環道は三鷹練馬がまだなのか
あと計画は圏央道ってのもあるでよ
茅ヶ崎、八王子、つくば、木更津、更に大外回る
首都高はマジで終わってるわな
あれは国家的損失だと思う。
機械学習方面は割とむだに技術押しする輩が多いわ。
それ必要?ってのに予算無理やりねじ込むのがあまりに多すぎ。
SBなんてまさにそれですね。
社外取締役に名ばかりのAI専門家入れたことも影響してるかな?
DeepLあたりは上手いなと思うんだけど日本のAI系プロジェクト・プロダクトでこれはというものあるのかね
>>367 東京オリンピックでスタジアムとかを顔認証で入場するとかやる予定だったと思うけどどの程度役立つのかはわからないな
AIってか深層学習は画像処理しかできないんだな。日経やその他ニュースサイトでも画像生成、
男女入れ替え、若返り、ノイズ除去しか成果でてないイメージ。
日本的に重要なのは強化学習を使った制御とか
そんな地味な分野なんじゃないの
>>371 囲碁への応用もあったんじゃないか?
視覚情報で処理できるものへの応用が可能性あるんだと思う
USB接続のカメラとか安く入手できるし
赤外線や紫外線カメラをつけたら可視光で判断できないものも判断可能になる
新型コロナ関連では発熱のチェックとか
発症前からウイルス排出してるから発熱してからだと遅いかもしれないけど
微妙な変化の特徴があれば発症前に判別できるかも
来店客を個人識別してマーケティングとかセールスにつなげるのは出てきそうだけどな
他には防犯で万引き注意みたいな
あれは出来るこれは出来るというのはあるだろうが
ミス無く長く居続けた方が有利な日本社会で
ワザワザ新しいことになんて本腰入れてチャレンジせんのじゃないか
何かあったら誰が責任を取るんだ!っていう話しになり
取り合えず保留って状態が永遠に続いて終了する
>>374 マーケティングで言うなら画像処理よりも顧客注文データを地道に分析する方が結果は出る。
もっと言うなら機械学習する前にデータベース整備を本気で行う方がその会社的に利益出るだろって
ことは往々にしてある。
めんどくさいし言っても聞かないからほっといてるけど。
>>379 ホント何処もかしこもエクセル様様ばっかりで
MySQLで組んだ人がやめちゃってメンテ不能
データはCSVかTSVでゼロから構築したあげく
最後はまたエクセルにダウンロードしてWordにコピペ
プリント印刷してハンコ待ち。
AIというより単なるライントレーサーみたいなもんだろそれ
障害物を検知したときの非常停止に画像認識を使うくらいはやってるかもしれんが
畑に線を引くわけにも行かんからSLAMが何かの技術は使ってそう
普通のトラクターは400万ぐらいだ、高すぎる、絵に描いた餅
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
タクシーの完全自動運転なら車両価格が3千万円でもペイする。
トラクターも24時間稼働するような場所があれば同じ。
できますか?
「はい」「いいえ」
これだけやんω
ちゃんと裏獲れよωωω
「人工的につくられた知能」とかそんなまんまな回答を期待してるんだろうか
最低賃金や実習生の賃金が安すぎて、価格競争に負けるAI
>>392 人工知能というワードには具体的な手法の意味合いなど含まれないから「人工的に作られた知能っぽいもの」以上の説明など誰もできない
印鑑って現時点でもほとんどの契約で法的には必須ではないと散々言われてるだろ
当事者間で印鑑不要と決めてしまえばそれでいいだけのこと
日本の田畑は狭すぎてAIトラクターなんていらない!
AIは危険な作業すべき。
トンネル掘削とか、
海底や高所での作業とか。
でもそのためには
もっともっとボディも知能も
進化させる必要あり!
詐欺とか
高い値段で買わせる為の一手法とか
書かれなくて良かったじゃん
良いイメージ勝っている
人工知能とは何か説明できますか?はタイムマシンは・・・?と同じだな。
まだ誰も作れていいないものの、何を説明するのか?w
>>400 日本の田畑は狭すぎて畦道を無理やり走った
トラクター横転で運転手死亡とか普通にある
そういうのがAI自動運転に変われば
老人の無駄死にを減らせる
AIで畦道自動走行はまた別物じゃないかい?
舗装道路とは別に学習し直さないと行けないんでわ
AIは特殊な道を走るのは苦手だぞ
この間も横転したトラックに思いっきり突っ込んでたし
ドライブレコーダーの動画ってどこかで吸い上げて
自動運転の学習データに使ってたりするのかしら?
https://github.com/SystemErrorWang/White-box-Cartoonization ↑
ネットニュースでやってて見てたんだけど
プログラムにCCライセンスってあるの?
仮に出力した画像に対してだったとして
生写真の著作権は撮った本人が持ってるよね
アニメ風に変換すると著作権がプログラムを作った人に
移行するとかってあるの?
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
Pythonさえろくにできないバカチョンのくせに
できるとほざくクソチョンw
>>409 写真を見て人が絵を描いたら絵の方には絵を描いた人に著作権が発生すると思うけど
単に作るだけではなくて思想感情を表現したものが著作物だから機械的な変換には著作権は発生しないかも
プログラムの方には著作権が発生するけど
C言語をコンパイルしてもコンパイラ作成者の著作物にはならないし
一行目、
二次的著作物だから、写真を撮った人、絵を書いた人それぞれに著作権が発生するのでは?
>>249 まず、東大=頭がいい、数学が出来るというのは偏見だと思う
東大入試では情報幾何学とか出てこないし、大規模OSSのソースコードの解読とかもないから。
誤解がないように言っておくが、東大生は平均すると確かに頭がいいと思う。しかし、人の頭の良さは1つの観点から見たとしてもあまりに分散が大きいから、その平均にはほとんど意味がないというのが俺の考えだ
ちなみに当方中卒
そして、因果推論では理論が大切だと思うぞ
例えば、当たり前のように多くの人がスパースモデリンングの回帰分析のマージナルエフェクト(要するにlasso回帰の回帰係数)を使ってるがその根拠はどこにある?因果推論では強い多重共線性があるから、その根拠はほとんどの教科書にも書かれてないだろ?結局皆んながやってる方法が本当に因果推論として機能してるのか自分で計算して証明しなきゃならない
予測の問題と違って因果推論では考えなきゃいけないことが多い
>>417 次元削減とは関係がない
例えば気温とコインランドリーの売上との因果を知りたいとしよう
雨が降れば気温が下がるから天気の影響を取り除いた条件付き共分散COV(売上,気温|天気)、これを求めるのが因果推論の目的。
しかし、その時よく使われる回帰分析は条件付き期待値E(売上|気温,天気)を求めていて、さらに古典的な回帰分析は気温と天気が無相関であることを仮定している
そこでlasso回帰というベイジアンを導入してその
>>418 共分散が因果関係を表すとは自分は理解していないけどそうなのか?
回帰分析は気温の変数と売上の変数の関係を数式で表してるだけで因果関係は判らないのはそうだと思う
>>419 >共分散が因果関係を表すとは自分は理解していない
条件付き共分散には方向がないし、天気以外にも色んな影響を受けてるかもしれないから、その辺注意しながらデータを作っていく必要があるな
それをして、さらに正規分布に従うことを仮定したとしてもlassoの回帰係数を使うのが線形な因果関係を知るのに本当に正しい方法なのか疑問を持つべきだと思ってる
因果推論の手法は証明があって使い物になると思ってるからな
まあ、とりあえず共分散を信じきってる人よりましかな
一昔前のおじさんにはわかると思うけど
共分散構造解析が流行った時代があっての
ホッホ
>>422 共分散の話はしていない
条件付き共分散の話をしているがそれを信じるかどうかの話もしていない
条件付き共分散を信じるとして、それをどうやって求めるのかという話をしている
受験勉強ができるなんてのはオーバーフィットの典型例じゃん
>>424 条件を満たすデータを集めて分散共分散行列を計算したらいいのではないの?
相関行列でも線形な相関の程度は分りそうだけど
共分散が分かると何が出来る?
何のために共分散が必要?
まるちんげーる(確率変数と時間の相関)
カルマんフィルタ
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
Pythonさえろくにできないバカチョンのくせに
できるとほざくクソチョンw
日本で強姦と窃盗を繰り返す
犯罪者在日のクソチョンw
G検定受け終わったー
教師強制なんて参考書に出てこなかったんだが
Raschkaの機械学習の本を読んでいて、一番最初のパーセプトロンのところで躓いた。
重みをああいう風に更新しても正しく分類されていない点が正しく分類されるようになるとは限らないと思う。
中井悦司の機械学習理論入門の4.2.2でいうと、
点(x, y)が以下のように正しく分類されていないとする。
w_1*x + w_2*y < 0
t = 1
重みは以下のように更新される。
w'_1 = w_1 + x
w'_2 = w_2 + y
w'_1*x + w'_2*y = w_1*x + w_2*y + x^2 + y^2となるが、これがかならずしも正になるとは限らないと思う。
x^2 + y^2 > 0 ならば改善はされるとは思いますが。
xORのパターンはパーセプトロンでは分類できない
次元を増やすとか層を増やすとかで解決するんじゃないか
>>432 パーセプトロンで分類できることがあらかじめわかっているデータにアルゴリズムを適用したときの話をしています。
最小値じゃなくて極小値ローカルミニマムに捕まるときはあるだろうね
>>431 パーセプトロンの収束定理というものがあるので、必ず有限回で正しく分類できるようになる
全くついていけない。1%もお前らの話を理解できない
そんな能力あるなあdeepnudeとかいろいろ貢献しろよ
>>431 その本読んでみないと何とも言えんな
パーセプトロンの解説なんてネット上に腐るほどあると思うんだがな
一般的には分類用の単純パーセプトロンはロジスティック回帰が使われる事が多くて、指数型分布族でコスト関数が凸になるからつまずくとこなんてあるかーって感じだわ
普通にロジスティック回帰の勾配法での更新式を自分で計算してみたらどうだ?
「ロジスティック回帰 勾配法 導出」とかで検索すれば直ぐ答えが得られるが
>>431 あーなるほど、これは活性化関数にステップ関数を使っていて、さらにデータは線形モデルで精度100%が達成可能である事を前提としてんのね
それじゃあロジスティック回帰とは全然違うわなw
重みの更新式は学習率に応じて少しずつ何度も繰り返し計算されるからいずれ正になるぞー
w'_1*x=w_1*x+η*x^2 > w_1*x
となるわけだから
ηは学習率
>>439 ありがとうございました。
ループの途中でi番目の点(x, y)のところに来たとします。
点(x, y)が以下のように正しく分類されていないとします。
w_1*x + w_2*y < 0
t = 1
重みは以下のように更新されます。
w'_1 = w_1 + x
w'_2 = w_2 + y
w'_1*x + w'_2*y = w_1*x + w_2*y + x^2 + y^2となります。
x^2 + y^2 > 0 ならば改善される。
ループを回して、次にまたi番目の点(x, y)のところに来たとします。
この時点で重みの値は他の点の処理によって、一般的に何度も更新されているはずです。
w_1*x + w_2*yの値を計算したときに、一つ前に計算処理をしたときよりも状況が悪くなっている可能性もあるのではないかと思うのですが、いかがでしょうか?
現時点でのw_1*x + w_2*yの値 < 一つ前の計算時点でのw_1*x + w_2*yの値 < 0
となってしまう可能性です。
>>436 そういう定理があるということは、結局は、分類されるということだと思いますが、
>>443 のようなことが起こらないということは自明なことではないと思います。
>>443 2乗したら虚数でなければまだ負にならないんじゃないか?
xもyもゼロの時は正にならないけど
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
Pythonさえろくにできないバカチョンのくせに
できるとほざくクソチョンw
日本で強姦と窃盗を繰り返す
犯罪者在日のクソチョンw
>>443 w_3の存在を忘れてたりしない?
サンプルに1次元追加してそこを1で埋めればw_3はちょうど切片の役割を果たす
まずは1次元の場合で考えてみたらどうかな?
そうしたら切片の役割がより分かりやすいと思う
その上で、ステップ関数を使った単純パーセプトロンは損失関数をmax(0,-twx)とする事が出来る為、不正解となったサンプルのみ勾配法によって重み更新する事を考える
不正解の場合損失関数は-twx返す為、-twxをwで微分して、答えは-txとなる
従って更新式は勾配法によってw+txとなることがわかる
証明としては不完全だけど分かりやすくイメージがつかめると思う
xorなんて加群の準同型定理からなんとでもなりそうだが。
データサイエンスを過度に民主化するな
https://ainow.ai/2020/06/29/223422/ 理論が分からないバカを量産するなという記事が出ていた
分析や機械学習を安易に外に投げるような企業は、
納品された結果を検証する能力も無いから問題無し
稼げるうちに稼いでおけ
http://pfi.kishou.go.jp/Presen2019/2_shimizu.pdf https://www.nict.go.jp/publication/shuppan/kihou-journal/houkoku65-1_HTML/2019R-02-04(02).pdf#page=4
MP-PAWR及びPAWRの高空間分解能な観測データを教師データとし、
従来型現業気象レーダーで取得される従来データとの 4次元関係(空間+時間)を機械学習することで、
従来型レーダーの4次元情報から線状降水帯等の積乱雲群の発達を
低コストに予測する手法を開発する
線状降水帯をAIで予測するプロジェクトが始まった


https://www.cc.u-tokyo.ac.jp/supercomputer/ofp/service/olympic.php >最先端共同HPC基盤施設(JCAHPC)と理化学研究所計算科学研究センター(理研R-CCS)は、2020年東京オリンピック・パラリンピック期間中に、
>関東地区における「ゲリラ豪雨」リアルタイム予報と情報配信を協力して実施する予定です。
>今回はOakforest-PACSシステム上で、理研R-CCSの開発した「SCALE-LETKF」コードを使用して、
>埼玉大学に設置されたMP-PAWRの観測データに基づき、リアルタイムシミュレーション及びデータ同化による予測を行います。
線状降水帯の予測も京超えのスパコンを占有使用することで、
予測が可能となる
全然しらないけど
雲が出て来はじめたら
雨降るよ、で案内すればいいだけなので
簡単そう?
>>455 雲が発生してからでは遅い場合もある
積乱雲は急発達するので。
この分野って人工知能とか夢のある名前がついているけど、結局のところある特殊な関数の最適化を行う分野ということ?
×特殊
◎正直ブラックボックス
だろやし
>>459 ただ人工知能の研究分野と言えるだけで機械学習=人工知能技術というわけではない
>>457 じゃあ積乱雲がでそうなら
雨降るよ、でいいんじゃない?
>>463 ・どの場所で
・どういう強さで
・どのくらい降るのか
この三つを正確に予測しないと、空振りになったり、
間違った避難をしてしまう可能性がある
滞在時間も災害になるかどうかに影響が大きい
短時間なら耐えられても
川が氾濫する閾値を超えたら大きな被害になる
近未来を予測するタイプの研究はすぐに結果が出るから
自然淘汰されやすいよね。はずれが多いと相手にされなくなる
俺の調べた限りでは、気象予測も頭打ちらしいな
予報精度はこの5年間でちっとも向上していない
気象庁は一昨年辺りにスパコンの処理能力を向上させるため、新型スパコン(Cray製)を導入したが、
予報時間を延長できたりしただけで、精度自体は上がっていない
雲の物理過程をモデル化した方程式や数式に改良をしたり、そういう質的な精度向上もうまくいっていないようだ
頭打ちの根本原因は、高信頼性のある初期値の作成方法に限界にあると見た
2025年までの間に、全球モデル(GSM)の高解像度化が予定されているが、
その高解像度化に伴って初期値(観測データ)も高解像度化する必要がある
それも地球全体で。
だが地球全土に隙間なく気温計や気圧計、降水計、気象レーダーを設置するわけにもいかない
莫大なコストがかかるから難しいのだ
これを解決するために、(レーダーが無くても)雲の衛星画像から降水強度を推定できる人工知能をウェザーニュースが開発中だが、
これも精度に限界がある
長期的な予報の精度向上は見られないが、
比較的短期的で、ミクロな現象であるゲリラ雷雨の予測には精度向上が見られる
(ただし高密度な観測網がある日本に限る)
関東域の密なアメダス観測データと、新型MP-PAWRを組み合わせて、超高解像度の初期値を作れるようになっている。
この初期値を模擬実験(シミュレータ)に同化させて予測させるのが従来の手法。
しかし最近は、MP-PAWRで捉えた雲の発生、発達、衰退までの全過程を
「機械学習(AI)」に学習させて、次の雲の状態を予測できるようになった。
この次世代の手法を使えば、わざわざ手の作り込んだ数式を考えたり、模擬実験させなくても、
気象レーダーの観測値だけで気象予報ができるようになる。
しかしこれは気象レーダーの守備範囲でのみ適用できる手法で、
長期的で全地球的な予報には使えない。
降雨というのは、単に湿度と気圧の関係だけじゃなく、空気中のホコリや僅かな風の動きで結果が大きく振れるカオス系。
予想はできても、結果は神のみぞ知る。
天気予想って
aiていうよりシミュレーションて感じがする
台風のタマゴ、つまり台風が何処にできるかってのを深層学習で見つける、って話もあったな
なんかレントゲン画像から肺がんを見つけるような話だが
数値計算からボトムアップしていくシミュレーション
と
結果画像の確率統計からトップダウンする機械学習
の両方をGANで対戦させれば良さそうですね
>>473 2次元のピクセルだけでなく3次元のボクセルでも同じ事
lightgbmとkerasについてはここで良いのかな?
35とか60とかまとまり毎に意味をなすデータセットなんですが
バッチサイズをそのまとまり毎に指定することはどうやったらできるのでしょうか。
1エポック内で
35→60→45→50→…みたいに変化させていく感じです
>>476 すいません、kerasはfit_generatorで対応しようと考えてるの忘れてましたw
lightgbmも似たようなサンプルどこかに無いですか?
検索ワードだけでも…
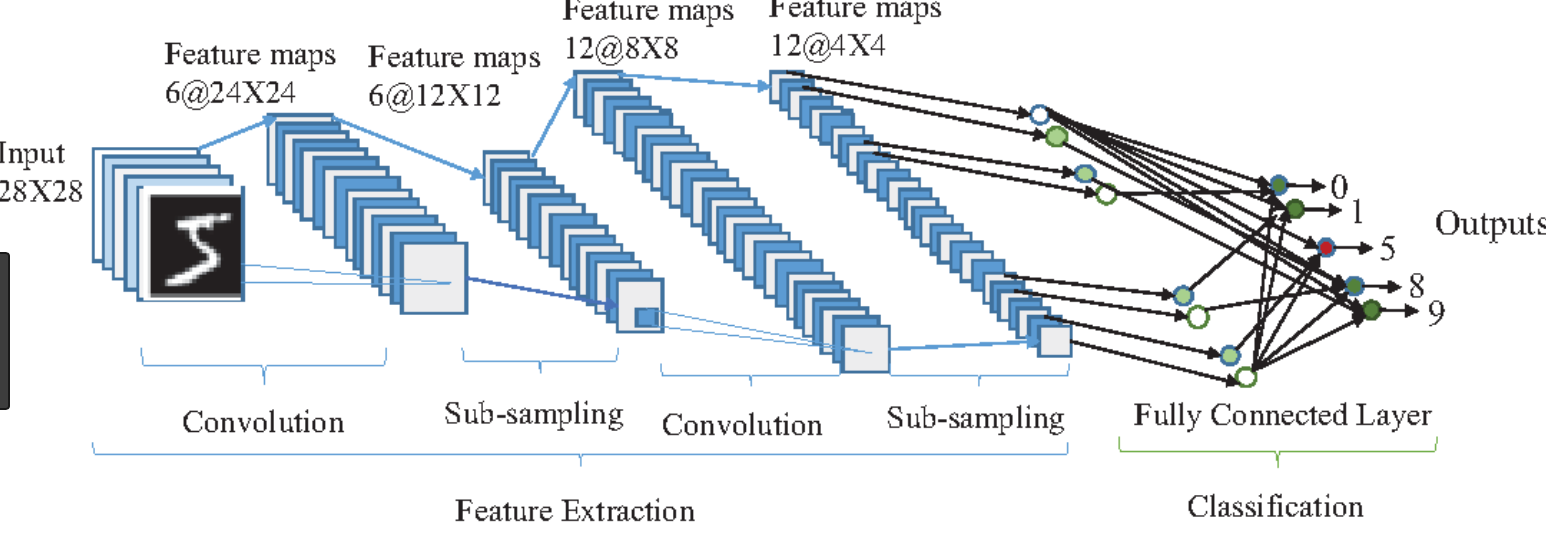
いろいろこの分野を勉強しようと思っているのですが、パソコンのスペックが低いです。
ディープラーニングとかの実習は諦めたほうがいいですか?
Jetson、ゲーミングノート、自作、クラウドの4択やな
google colabは超大変
チュートリアルぱっとやるだけならいいんだけど、googleドライブと連携させるだけでもかなり大変だった
GTX1060でもいいから買ってローカルで遊んだほうが良い
平成30年度 「思考を実現する神経回路機構の解明と人工知能への応用」※昆虫脳
成果報告書
http://www.rist.or.jp/sc/report/h30/h4-2_h30.pdf 
計算性能上、ポスト京(富岳)は詳細モデルレベルで昆虫全脳規模での実時間シミュレーションが可能である。
本提案においては、定位行動を念頭に、昆虫脳の詳細な入力から出力までのリアルタイムシミュレーションと
データ同化を通して昆虫脳の物理的知能的な構造・機能を探る事を目指す。
昆虫脳は原始的ながらも、多種感覚統合、連合学習、顔認識、
空間学習、探索行動など、知能と呼ばれる様々な特性を網羅している。
驚異的な識別率を誇る画像認識を可能にしたCNN(深層学習)は哺乳類脳の視覚系の構造を反映しているが、
行動決定を担うためのRNNの設計にはこれまで決定的な指針が存在していない。
無限定環境で動作させることを要求される人工知能をすみやかに構築するには、
比較的小さな複雑さで構成される脳を参考にすることが有用である。
その際、非線形で複雑な階層性をもつ神経系の働きを深く理解するには、
過度に抽象化されたモデルでは十分ではなく、物理的な構造と現象を再現した詳細モデルから現れる性質をよく観察し、
現実の脳での実験結果と比較することが必要である。
小さくて単純な構造でも、複雑で高度な能力を実現している昆虫脳を調べることで、
”知能”の本質を理解することができる。
また、極めて原始的な意識が発生しているとされる昆虫脳を詳細にシミュレートすることで、
意識の発生条件、意識の神秘を調べることができる。
>>488 昆虫類は、哺乳類とは別の方向に、哺乳類と同じく高度に進化した最終系だから、昆虫を調べても哺乳類のことは何一つわからないような気がします
>>488 もうちょっと説明すると
個体発生時、ある程度細胞が増えた細胞塊はやがて二重の袋状になった胚となり、そして消化管の最初の口=原口が出来る
原口が口となるのが前口動物…昆虫等
原口が肛門となるのが後口動物…哺乳類等
進化系統的にかなり早期に分化した特徴なので…昆虫を調べて哺乳類のことがわかるのか疑問です
昆虫でも、餌の匂いやメスのフェロモンを嗅いだ際、あるいは物体を認識したときに
主観体験(クオリア)が生じていると推測されている。
だが、知能が低くメタ認知が弱いため、意識を感じてることに気付いていない可能性もある。
更に、細かい行動選択をすることから、
内発的動機(自我)が発生してると考えられている。
>>490 あくまでも知能という機能の理解をするために、昆虫脳のシミュレートをします。
人間の脳の神経細胞は、1000億個の神経細胞から成っているといわれるが、
それにくらべると昆虫脳の構成する神経数は 10-100万程度であり非常に少ない。
しかしながら、基本的な分子メカニズム、電気生理メカニズムは昆虫と哺乳類ではほぼ同等である。
知覚・認知・運動・注意・感情・意思決定・思考といった脳の機能を全て説明できる統一理論っぽいものがある
それが「自由エネルギー原理」

自由エネルギー原理では、
外界に関する生成モデルと現在の認識から計算される変分自由エネルギーを最小化するために
1) 脳状態を変えることによって正しい認識に至る過程 (perceptual inference)
2) 行動によって感覚入力を変えることによって曖昧さの低い認識に至る過程 (active inference)
の二つを組み合わせていると考える。
この理論において”意識”とは、
「自由エネルギー原理における推測と生成モデルとを照合するプロセス」そのものであり、
イマココでの外界についての推測と、非明示的な前提条件の集合である生成モデルとが一体になって意識を作り上げている。と考える。
自由エネルギー原理 とはつまり
→「脳内の生成モデルで感覚入力を予測し、実際(外界)との予測誤差を最小にする行為及び現象(意識)」
を説明する数式、および理論のことである
意識が実際に発生しているか、その意識レベルを確認する方法として、
脳内の「統合情報量」を計算する手法がある。

この理論は難しくてよくわからない
反実仮想情報生成理論というものもある

>>492 「『昆虫の知能』という機能を理解するため」なら私も理解しますが…
kerasを使ってみました

サンプル触るだけでも面白いのですが、何かもっと面白いものってありますか?
colabは今は割と簡単にGoogleドライブ上のファイルにアクセスできるようになったはず
>>479 tensorflowのチュートリアルとか簡単なものならCPUでも実行可能だった
データ量やモデルの複雑さによる
ReLU関数って原点で微分不可能だけど、こんなものが含まれる関数を偏微分できるの?
>>504 せっかくの偏微分なんだもの
原点を扱わなければよいだけでは。
>>504 正なら1、それ以外は0とかそんな感じでいいんじゃね?
>>知能が意識がどうこういってるおまいら
1嫁
スレチ
(1は人間以外の意識がどーのこーのは想定せずもんごんを書いたのだろうが、
つまり、そういうことだ)
>>507 神経回路を真似して作った、それで知能、意識が実現できるかどうかは別問題
>>508 いよいよあきらメロン
>>509 で、スレチ。
>>498 普通にスケールが、昆虫規模までしか扱えないだけじゃね?
ネズミクラスが可能ならそう言うでしょ
>>512 スケールの問題ではありませんね
昆虫は前口動物
哺乳類は後口動物
そもそも受精した後のわずか数時間で決定的な差が現れていますね、個体発生は系統発生を繰り返すのだから、昆虫の知能の実装方法は哺乳類とは別のものでしょうね
>>515 その後攻動物で、昆虫並のシナプス?数のやつおるの?
昆虫と哺乳類が別物でも神経細胞の連携で情報処理しているという共通点があるなら情報処理の問題としてはその差はないとみなして良いのでは?
抽象化して共通点があればその観点ではそれを同一視して良い
トポロジーで観たら人間もドーナツも同じ
ナマコなんか後口動物で単純な方なんじゃね?
でも昆虫は育てやすいし神経の研究が進んでただろうからシミュレーションもやってみよう、ってことにもなるんでは?
あと、群知能とかの関係とかもわかったら夢も広がりそうだし
前処理大全[データ分析のためのSQL/R/Python実践テクニック
5つ星のうち1.0 「分かった気分」を味わうためだけの典型的な初心者向け詐欺本
2019年5月27日に日本でレビュー済み
Amazonで購入
タイトル以外に書くべきことが無い。
これを「役に立つ」と思った人は、データ分析に致命的に向いていないので諦めた方がいい。
初心者向け本にマウントとって
自分の方がゆうしうと吠えて
何を得たのかなこの人
自己満足?
動植物の生態や構造を再現してみた系の研究や商品ってイマイチなものが多い
それは動植物の再現自体に必死になりすぎて本来あったはずの解決したい課題に対する解決策として
それが最適なのかという視点が抜け落ちていることが多いから
その点ニューラルネットなんかは昔は脳の再現自体を目的にしていたみたいだけど今は脳の働きに全く無関係でも課題解決に繋がるなら取り入れるという意味では健全
そこまで言うなら
ニューラルネットワークωに
ニューラルネットワークが学習に最適かどうかを教えてもらえωωω
でも本だとどんどん情報が更新されてるから時代遅れになっちゃうよね...
tensorflowとかversion1.を載せてる本とかももう今となっては...って感じ
>>517 ホヤと同じげんさくどうぶつのナメクジうお
昆虫をナメクジウオと言い換えた所で研究の方向性に影響あるのかな
>>527 ライブラリを利用するためだけの知識のサイクルが早いのはどの分野でも同じ
web系なんてもっとサイクル早い
tensorflowもkerasも1で書かれたものが2で実行しなくなり変換する必要が出て来たり
説明するのも鬱陶しんで
売ってる本は2が出た頃からPytorch使う本が増えてるんじゃないか
人気も急上昇してたけど
ブームの時に作られたものは基本全部1.0系なんでtensorflow使っている人は
1.0系と2.0系両方入れてるんじゃないの
ディープラーニングってたまたまうまくいっちゃいました。うまく行った理由は説明できませんって感じだよね?
理論なんてない。ただ役に立つだけ。
>>535 理論だけあって役に立たないものもあるからな
役にたつならいいんじゃね?
突き詰めたら物理現象も説明できない事はあるだろうし
物質も素粒子レベルまで突き詰めたらまだ判らないことはあるだろう
十分に汎化性能が高くてこれまで人力でやっていた作業がより高効率に行えるなら必ずしも根拠が説明できる必要はない
これまで人力でやっていた人も説明できていなかったのだから
物理どころか
コンクリがどのようにして固まっていくのか みたいな化学的なところも
まだまだわかってないぞ人類。
物理だと代表的なのは
飛行機の厳密な積載限界量がわかってない
(なにがどうなって飛んでいるのかまだまだ未解明の部分あり)
(クマンバチが飛べてる件とか、
宇宙ステーションでブーメランを投げても、手元に戻ってくる件 とか
けっこう、最近になって更新された知見あり)
そうなんだよね
説明できたから信頼できるし正しいかと言うとそうでもないし
人がやることを神格化しすぎる人がいるね
所詮入力に対して出力するだけの関数でしかないのに
tf2はまだbatchnormalization実装されてないの?
人が経験で取得していることも説明が出来ないんだから
AIだからってハードル上げられてもな
良きAIとは汎化や再現性で在るべきであって、理屈うんぬんはシステムの稟議とかの問題
要するに分野としては工学に属するということですね。
seq2seqで翻訳系をしているナチュラルなサピエンス、居ますか?
C/C++の逆コンパイラ作りたいんだけど、何とかなりませんか?
https://github.com/katahiromz/CodeReverse2 https://github.com/katahiromz/WondersXP 逆アセンブルとAPI関数の列挙まで出来てます。
アセンブリからソースが得られる方法を探してます。
>>549 何で? Python必須だって聞いたよ。
まず、C言語のソースコードを最適化なしでコンパイラに渡すと、素直なx86アセンブリを吐いてくれます。
簡単のために、一つの関数だけを対象とします。コンパイル可能な一つの関数のソースコードを次から次へと生成し、
そのアセンブリを関連付けてseq2seqで学習させると、逆コンパイラができるはずです。
ここまで間違っていませんか? 足りない情報はありませんか?
ハッシュ関数は元の値と変換後の値とが一対一に対応しないのと同じ様に
コンパイルと逆コンパイルで一対一の写像になるかな?
一対一なら機械学習を使わなくて良さそう
一対一でないなら機械学習を使っても上手く行かなそうだけどな
あとリバースエンジニアリングが禁止されている事もあるけど法的にはどうなの?
>>554 コンパイルのときに最適化という変換処理が入ると、関数が複雑になります。
最適化は別の学習が必要になると思います。
ソースコードはすべて自動生成するので、ライセンスの問題はありません。
呼び出す関数の情報と、使用している構造体の情報が重要と思われますが、これをどうやって機械学習に取り込むのかが分かりません。
API関数と構造体の情報は上記のWondersXPにあります。逆アセンブラはCodeReverse2で可能です。
556で問題にしてるところこそがわかんないうちは、むりなんじゃね?
>>558 わかりました。もう少し頑張ります。あなたも頑張って下さい。
おうさ
なお
まほうのじゅもん「マニピュレーション」
金が絡んだプロジェクトのことをここで質問してるとしたらちょっと引く
>>555 逆コンパイルを実現できたとしてそれを利用できるのか?ということ
1ヶ月後に東京がニューヨークののうになっていることを予測するのにAIの力は必要なさそう。
東京だけで済むかな?
せっかく収束しかけてて連休明けとか619とかあと一週間くらい頑張れば良かったのに
拙速で解除なんてするから
東京アラートωとか全く意味無かったし
顔認証調べてって丸投げされて色々見てるんだけどなかなか一から作れるようになる気がしない
githubにあるコード試してわー出来た出来たくらいしかできねぇ。明日の報告どうすりゃいいんだ……
>>569 「特徴点」
ぶっちゃけ
人種差別・年齢差別なくちゃんとやってくれる実用レベルを期待されてるんなら
「わかんない」569が0から頑張るより
出来合いをカネで買ったほうが・・・
>>569 顔認証はDLでいいなら楽勝だろう。速度求めず、既にあるファイルを選り分けるだけなら簡単。
リアルタイムの認証はマジでヤバい。
「顔というものは鼻から上、1/3が暗い」「鼻や唇の端と頬の輪郭線の距離の法則」など完全に顔認証専門のアルゴリズムを知ってないと無理
顔認証のドアシステムを調べてて思ったんですけど、ユーザーが一人二人のときはいいとして、例えば数百人とかになってきたとき一人追加される度にまた全部一から学習してモデル作り直すのって相当大変ではないでしょうか
世の中の顔認証ドアシステムってどうやってんでしょう
>>570-571 会社としてそういう方向に手を伸ばしたいからざっと調査してみたいなふんわりした要求なんで今すぐ実用レベルのアプリよこせとかそういう話ではないです
だからまぁこういうライブラリ使っていけばそれっぽいの出来そうですよみたいな程度で行こうかなと
ただまぁ難しいもんだなと思い始めてます。少なくともうちの会社にゃ無理だろみたいな
少なくとも一回やってみて詐欺みたいな業者を選別できるぐらいの知識は持っておいた方がいいかな
kaggleのテーブルデータコンペが減ったのって勾配ブーストゲーになったから?
テーブルはクラウドでマウスポチポチするだけの自動ソリューションが人間に勝利するのも時間の問題だからね
>>572 >ただまぁ難しいもんだなと思い始めてます。少なくともうちの会社にゃ無理だろみたいな
そりゃ調査を任されたお前が言うんだからきっとそうなんだろうと予測はつく
automlで仕事なくなるとか言ってるのはautomlでできる範囲の仕事しかできていないだけなんだよな
もっと高度なことやってる人からすれば面倒な雑用が自動化されるだけなのでただただ嬉しいこと
リードの距離は人によって異なるにせよ、ツールとのいたちごっこをしてる時点でいずれは抜かれるんだよ
最終的にはビジネスと真面目に向き合わなきゃいけない
コンペ上位見てもautoml系そんないないけど
大体xgboost+NN+RFとかのスタッキングしかいない
データ集め、前処理なんかのkaggleのスコープ外の方が相対的に重要になったということかね
Kaggleって面白いの?
パソコンのスペックは要る?
tensorflow2系けっこうバグ多いな。。
早く2.3出ないかな
>>582 無料出し試してみては?
スペックはそんなにいらないけどグラボなしは実質参加不可能
>>585 LenovoのThinkCentreっていう小型パソコンじゃ無理ですか?
ESC50学習させようとしたらメモリエラーでた
32Gじゃ足りないの?
>>586 無理っす。機械学習はデスクトップじゃないと色々と厳しいよ
>>586 >>589
メモリとHDD気合いで換装すれば
宮廷のスパコン1時間借りてやる計算が
3週間くらいで完走できる こともあった。 >>590 一回の試行錯誤で3週間はさすがに辛いw
仕事しながらだと8時間ぐらいならちょうどいいんだけどね。帰ってきて確認と寝る前にセット
いくらくらいのデスクトップPCを買えばいいんですか?
おすすめのものはありますか?
自作は無理です。
>>591 >8時間ぐらい
プログレス表示の最初のほうをみて
そうおもってしまったことも(最初の1回だけ)ありました・・・
>>592 ネタにあえてマジレスすると
ちょいと一回試すのにひと月かかる のがいやならば
本体代は可能な限り(Python組みとOfficeの基本3アプリだけやれればいいなら、
3萬弱でもいける。ネトゲはじめ、他のことはだいたいできなくなるが!)ケチって
残り7萬でAWSなりなんなり、レンタル型の計算システムを秒単位で借りるがよい
みなさんありがとうございます。
LenovoのThinkCentreでも性能面で全く不満はないんですが、GPUを買うと機械学習以外でもメリットがありますか?
みなさんありがとうございます。
実用に役立てたいとかいう気は毛頭なく、楽しくこの分野を「お勉強」するために実際にプログラミングもしてみたいという気持ちなので、
正直言ってあまりお金をかけたくありません。
>>603 本当に金かけずにやるならgoogle colabか
完全にブラウザだけで動く物だから、1万円ぐらいの中古ノートPCでも行ける
なんだったら漫画喫茶でも可
mnistだけなら数回クリックすればいいぞ
30秒ぐらい待てば0.91とか味気ない数字が出るからそこで終わり
それで「機械学習できたー!」って思えるなら、それでもいいかもな
初心者ですが機械学習に求められるPCスペックってどんなもんなんですか
画像認識に使います
>>608 ちょっと上の現行レスくらい嫁ないと
おまえのスペックが足りないぞ
データサイエンティストに転職したけど
機械学習はド初心者レベルで
記述統計と回帰分析ぐらいしかできません
それでもかなりの給料もらえるので
良い仕事選んだなあ、と自画自賛してたら
NTTデータの社員が
「今はデータ分析バブルだからね。
もうすぐ終わるけどね。」
と言ってたのが気になってます
大手の正社員になれたので
バブル終わってもOKですw
大企業の場合は使い道なくなった部門は丸ごと分社化して捨てられるだけだよ
クビにはならないけど待遇はかなり下がる
大企業ならこれからしばらくは大量採用世代の退職で急速に自然減するから、あえて貴重なIT人材を切ることはしないだろう
まあ仕事はただの社内SEさせられるかもしれないけど
貴重なIT人材なら給料はもっと高くてもいいはずだけどなあ
>>605 colabって無料ですか?無料だとして、どのくらいの計算能力があるんですか?ThinkCentreよりも上ですか?
ど初心者がデータサイエンティストとして働ける 会社だぞ(笑)
お察し
パターン認識と機械学習を読むために必要な確率統計の知識はどの本で得られますか?
『プログラミングのための確率統計』は持っています。
線形代数はGilbert Strangの本(5th Edition)を勉強しています。
>>611 どこの会社?自分も行きたいです
機械学習の単純なものは自動化されてそういう人材は減るだろうね。実際AutoMLとかBIツールとかもうあるしなあ
データサイエンティストという職業がよく解らん
コンサルやSEが兼業するなら解るけど
専門分野を持たない分析屋なんて課題からモデリングする時点で行き詰りそう
×行き詰まる
◎へんな結論orモデルが導き出される
業務知識が無いんじゃ
ろくな結論も出てこないし
できたモデルもろくなもんじゃないだろうね(笑)
>>614 IT人材の中にも貴重なのとそうでないのとがいるというだけのことだよ
>>626 貴重なIT人材と言わずに
貴重な人材といえば済む話だよな
>>623 専門分野を持たない自称データサイエンティストの実態は特徴量エンジニアリング屋やハイパーパラメータ調整屋でしかない
もちろんこれらの仕事はデータサイエンスの本質的な部分ではないし自動化されつつあるので
こういうことしかできない人が「データサイエンティストは近い将来に消滅する」とか騒ぐ
じっさいそんな奴らを絶滅させる為の研究がトレンドだし
>>630 自作PCの板かスレあるはずだけど、好きじゃないならオススメしない
初めてならマウスとかのゲーミングPC買えば多少安上がりだと思う
データの前処理とか
そのテストデータの作り方とか知りたいけど、どうすりゃいいのかさっぱり分からん
>>622 ありがとうございます。その本も持っていますが、そんなにいい本には見えないんですが、いい本なんですか?
>>633 統計の定番、赤本と青門(理系)、君には難しいかもね
>>630 定評ある組み合わせのパーツを買えば難しくない
MBにCPU取り付けるとことだけが難しいといえば難しい
GPUの補助電源供給出来なかったり罠多いと思うけど、最近はそうでもないの
今手元にあるやつだけどこの辺おすすめ

黒木学の数理統計学は初版だからだけどミス多かったから改訂版まった方がいいかも
>>634 なんか松原望っていう人の本ってろくなのがないように思うんですが、『統計学入門』は例外なんですか?
『統計学入門』をパラパラ見ていますが、なんか単に結果をまとめた本にすぎないように思います。
深く考察しているような本ではないように見えますが、間違っていますか?
海外のよい統計の本ってないですか?
>>639 ありがとうございます。稲垣っていう人の本は裳華房というまともな数学書をたくさん出版している出版社ですし、「数理」統計学というタイトルなので、
ちゃんと理由なども説明してありそうですね。
『自然科学の統計学』と『統計学入門』の内容面での違いはなんですか?
『自然科学の統計学』のほうも松原さんが執筆しているんですか?
プログラミングのための確率統計という本は特色のあるいい本だと思いました。
海外の1000ページを超えるような本でいい本はないんですかね?
各統計分布についての説明が深く詳しいものが希望です。
鷲尾泰俊著『日常のなかの統計学』という本は、高校生向けの本ですが、なぜそのような統計分布になるのかの説明がしてあります。
フィールズ賞受賞者である数学者が書いた以下の本を読んだ人いますか?いい本ですか?
どうも参考文献にも載っているのも見たことがありませんし、どうなんですか?
Pattern Theory: The Stochastic Analysis of Real-World Signals (Applying Mathematics) (英語) ハードカバー ? 2010/8/9
David Mumford (著), Agnes Desolneux (著)
頭の良さで言えば、Geoffrey Hinton教授よりもDavid Mumfordのほうがずっと上だと思いますが、影響力は逆のようです。
東大出版の『統計学入門』をパラパラ見ていますが、「待ち時間は指数分布に従う」と結果しか述べていません。
どこがいい本なんですか?鷲尾の本には理由が書いてあります。
>>640 電源使い回そうとしたら、田のピンが無くて、電源も替えることになったことが
どの業界でも同じで
仕事は道具で決まるようなところがある
リモートワークの時代に突入した今
自作PC持ってないとか
「私は仕事が出来ません」と言っているようなもんだろう
性能はもちろんのことモニター、キーボード、マウス、デスクチェアに至るまで納得いく製品を使ってこそ一流
大体どの業界も一流は一流の道具を使いこなしている
うちの会社はPC支給だから自作PCなんて関係ないが
そういう会社は社風に習って管理されたノートPCでゆっくりやればいいんじゃないか
https://www.itmedia.co.jp/news/articles/2007/16/news080.html 日本はもう他国についていけてないんで
新興企業が少なすぎてヤバイってことでいろいろやっているけど
https://www.jiji.com/jc/article?k=2020071401008&;g=eco
年功序列の日本で新しいことにチャレンジする奴が出てくる訳も無く
終わっていく一方なんで
会社支給のPCだとUSBをさすと部長に警告のメールが飛ぶソフトが入ってるだろw
データサイエンティストには誰でもなれる
データ分析は結局アイデアだから
目的を達成するために分析するのであって
モデリングするためじゃないから。
方法と目的を取り違えている人多杉
誰が最初に言い出した?データサイエンティスト(笑)
必要なのはデータ活用コンサルタントとデータエンジニア
中途半端にコンサルでもエンジニアでもない意味不明な呼称こそが諸悪の根源かもな
とはいえサイエンスというよりエンジニアリングなので
ソフトウェアエンジニアの人達が自身のことをエンジニアと呼称するのに違和感感じる
単に「エンジニア」と言ったら機械系の技術者をイメージする
>>662 データサイエンティストは
典型的なバズワードデスネ
ビッグデータ、
データサイエンティスト、
AI、
この3つのバズワードは素人をダマすときだけ
使うべきと思うけど、
かなり広まってしまったから
仕方なく使うようになった。
ビッグデータ=いろいろなデータ
データサイエンティスト=データ分析する人、
AI=機械学習などの分析方法
と、読み替えて使ってます。
というのでOK?
>>668の読み替えにわかりみw
>>667は 化石化がはじまってんよ(´・ω・`)
>>658 >年功序列の日本で新しいことにチャレンジする奴が出てくる訳も無く終わっていく一方なんで
+1
他国に抜かれるばかり
4-7819-0980-9
978-4-7980-5072-0
978-4-7980-5073-7
>>667 ソフトウェア工学とか情報工学と言う言葉はある
工学→エンジニアなのでは?
>>668 ビッグデータは種類だけではなくて量も多いイメージ
AIは各手法で実現された人工知能の事じゃないかな
手法はいろいろあって人間の知識や手法をヒアリングして作った普通のソフトウェアも含む概念だと思う
僕くらいになるとデータファンタジスタって呼ばれるんだけどな
>>673 というか火中の栗を拾おうというのに、リワードゼロというのは嫌ですよね
大手に入って喜んでいる人も居るみたいだが現実はこれだろう
https://dot.asahi.com/wa/2020052600043.html?page=1 田原総一朗「日本の大企業は10年ももたない。危惧するこれだけの理由」
ここでお馴染みの松尾豊さんのコメントも出てるけど
年功序列と中抜き大好きJAPANだからな
もう一昔前の大きい会社に入りさえすれば、、、、
っていう時代はとっくの昔に終わっている
>>679 田原総一朗氏は言っていることを見る限りボケてきているようですから(その内容はゴーストライター製じゃないかな?)
もう引退したほうがいいでしょう
欧米並みの雇用規制の緩和・金銭解雇解禁と「それとセットでの」再就職支援・生涯学習機械創出の同時保障による人材流動化を打ち出せない限りもうだめでしょう
日本の左翼も都合のいいところしか言わなくなりましたね…
企業でデータサイエンスやってるけどディープラーニングとかGBDTとかは使えて当たり前で
むしろモデルの精度よりも背景分布の推定や解釈性、因果推論の方が圧倒的に重要
GBDTの重要度を顧客に出したところでなぜそうなのかを説明できないといけない
>>683 とても矛盾した仕事ですね
DL はあくまでも、客観的な相関関係を求めるものなのに
それに対して主観的な因果関係を付加するのですか?
>>684 因果推論の「推論」を主観的に想像することだと思ってる?w
データから相関関係はわかっても、どちらが原因でどちらが結果かはわからないよね。
>>686 そもそも因果関係の認定は主観的なもの、というのが私の感覚です
だから最近のペーパーは相関関係(これは客観的なもの)だけ示して、それでペーパーになる、という体たらくまでに落ちぶれたと思っています
>>689 だから~の件が意味不
昔のペーパーは因果関係まで客観的に示してたの?主観的なものなのに?



 @YouTube
@YouTube このスピーチも6年前でAIブームの火付け役になった猫認識の1年、2年後だが
いい感じに当ててるよね
>>1989年、時価総額で世界のトップ50社の中に、
>>日本企業は32社入っていた。ところが2018年には、
>>残っているのはトヨタ1社のみで、ほかはすべて落ちてしまった
>>って書いてあるけど
トヨタも自動運転の時代に突入するとヤバイだろうって言われているもんな
>>689 因果関係はあくまで数学的なものであって主観を含まない
時系列ならGranger因果解析、未観測交絡因子がない前提の下ならLiNGAMを使えば統計的に因果関係を求めることができる
因果関係は実験できるなら原因と考えること要素を変化させて結果と考えられる要素を測定して変化が想定通りか確認したらいいんじゃね?
LとRの発音の違いが瞳孔の開き具合で判別出来るのか
おもろいな
>>因果関係は実験できるなら
実験できないことが多いから困ってんだろ。
>>693 いいえ、因果関係の認定には大きく主観が作用します
因果関係こそ主観的であると思います
>>697 その阻害要因を取り除くことが不可能かどうか個別に違うだろうけどな
>>696 相関関係があるなら判別できるんじゃないかな?
ある特定の個人には当てはまるかもしれないし
ある病気や遺伝子を持つ限定した人達には当てはまるかもしれない
それが分かれば瞳孔と発音の相関関係から病気の診断や予測に応用できるかも
深層学習やるにも超高性能なパソコンが必要か。
むずい。
必要なのはグラボだけやぞ
1060ぐらいあれば遊ぶには十分。同じぐらいの値段で売れるしそこまで損もしない
適当にデータ突っ込んで大規模なネットワークで学習させれば結果がでるなんて単純なものではないから
「よく分からないけどどんなスペックが必要?」のレベルならGPUに金使う前にまず勉強からスタート
>>705 p100ってteslaやろ、んなもん素人が持ってても使いにくいだけだぞ
型落ちしたteslaなんて普通のグラボよりコスパ悪いし
ゲームに流用できないのももったいないし、いいところがマジで無い
スパコンやマイニングでもするなら止めはせんけどw
だからgcpかaws使えよ。。少しいじったら飽きるからそれで十分。
>>695 現実の世界は、その要素が無数にあって相互に作用するカオスな世界だから。
ある要素の変化は別の要素を変化させ、それが回り回って元の要素を変化させる永遠の連鎖作用だから。
単純に原因と結果とか言えない。
>>708 直接ではなくても原因をコントロールする事で結果を望む形にできたら利用価値はある
>>709 一つの要素の同一の変化でも、他の無数にある条件の1つのわずかな違いによって、結果は180度変わることもある。
微小な変化が結果を左右する予想不可能な世界が現実。
気象学がいくら発達しても1年後の天気予報はできない。
>>712 今はVBすげー進化してるぞ。昔から使って極めているならアリ
新規でVBを選ぶ理由はないけど
いまどき業務用アプリ以外で、Windows上でしか動かないディスクトップアプリに何の価値があるのか?
現実的には再現性が一定以上なら
相関関係であっても有益であるしコントロール可能
元の
>>683は、顧客に説得できる根拠となるかなんで、
んな高次な概念を詰めて勝負したところで、カラフルなパワポの資料に負けたりする
このスレを見ててもやっぱり因果と相関の違いをちゃんと説明する必要があると思った
まず天気予報は予測の問題だから因果推論ではない。天気予報で問題になるカオスと因果推論で問題になる交絡因子は別物
因果推論の方法は大きく分けて2つある
1つは無作為割り当て。医療研究なんかで使われる手法。
>>695はその事を言ってるのだと思う。この方法は金と時間がかかる
もう一つは大量の因子を取ってきて回帰分析なんかを使って条件付き共分散を計算して因果を推察する方法
この結果は交絡因子が問題になるから科学的な根拠に乏しくなる
>>714 そのアプリが有用ならWindows買ってきて使えばいいし有用でないなら使わなければいいだけなのに何を怒っているのか理解できない
>>714 windows捨ててlinux使おうぜ。ナカーマ
>>714 ディスクトップに保存しておいてって上司に言われたことがあるのを思い出した。
ディスクトップ
ディスクトップはディスクのトップと思われがちだが、
ディス クトップ(dis cu-top)の意味である
つまり
>>711 ケースバイケース
利用できるものもあるしまだ難しいものもあるというだけ
全か無かではない
windowsにubuntuとか仮想マシンを入れられるよな
WSLとかVirtualBoxとか
>>725 入れれるけどパフォーマンス激減するのがネック
英米ではLの発音を叩き込まれるらしい。その恐怖心が目に現れるんじゃね。
LとRの区別はだいじだ
>>696 口元の力み具合で、じゃんけんのどの手を出そうと考えてるかわかるとかわかんないとか
>>OS論争してるおまいら
それぞれのOSのユーザーが他OSユーザーをどういう風に見ているか みたいな画像な↓
https://images.app.goo.gl/swhhKQS39hg885vt9 あと、
>>677に1票w
>>723 デスクトップです。はいはい、すみません。揚げ足取りご苦労さま。
>>733 そいつぁタダの英単語だろ
敢えて「ポエマー」を最上級に活用するところが、みそだろ
>>732 最上級は -est であって -ist とは違うのでは?
>677はpoemyという新しい単語を作り出すほどクリエイティビティスト
>>735 だから「たぶん最上級」なんだろw
>>736 いやツッコミ待ち?というか、DQN的なジャーゴンというか、スラングというか、だと思うぞw
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
Pythonさえろくにできないバカチョンのくせに
できるとほざくクソチョンw
日本で強姦と窃盗を繰り返す
犯罪者在日のクソチョンw
【脱税】中国人男性、競馬の予想ソフトで的中させた当たり馬券の利益18億円を申告せず、名古屋国税が所得隠し指摘→すでに上海へ高飛びか
http://2chb.net/r/newsplus/1595301945/ AIで犯罪プロファイリングしてるとかいうけど、どんなかんじなんだろうな
統計学を勉強しようとおもうんだけど、東京大学工学教程の確率・統計I、IIってどうですか?
図書館とか行って複数の本をみた方が良い
同じ事を違う表現で説明してあるから
自分にとって判りやすい解釈しやすいものを見つけたら良い
大まかに理解した後で別の本をみたら
最初は理解できなかったものも理解し易くなる
機械学習で株式リターンの予測を試みるDiscordコミュニティ作成しました
興味のある方がいたらぜひとも参加お願いします
https://discord.gg/ny366we 第6世代移動通信システム
第五世代コンピューター
インダストリー4.0
三本の矢
選択する未来2.0
VR元年
原発ゼロ年代
アンドロイド南極28号がオランダで活躍してるんだって、NHK-BSでやってた
視界の中央が黒くなる病気には網膜LSIを使って視界を回復するとか
フィードフォワードネットワークとマルチレイヤーパーセプトロンの違いってなに?
>>759 バックプロパゲーションがあるか無いかの違いです
>>759 フィードフォワードはデータの方向に着目した分類の仕方でパーセプトロンも含む概念だと思う
ニューロンの結合の仕方やデータの流れる方向による分類
層構造とか網構造とか双方向にデータが流れるとか
なかなか論文からすぐにプログラムを作れるようになれないよう😭
言い方違うけど一緒な話はこの業界ではよくある。
weight decayもl2 reguralizationも一緒。
新しい方法に見せたいっていうだけの話。
胡散臭い分野。
それもあるだろうけど、ただ単にまとまりなくバラバラに動いてるだけってのもある。
自由に競争した方がその分野の発展にはいいかもしれない
但し結果を公開して同じ失敗とかをしないような仕組みがあった方が無駄が少なくなると思う
統制するとモチベーション維持とかやらされてる感とかの問題出そうだし
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
Pythonさえろくにできないバカチョンのくせに
できるとほざくクソチョンw
日本で強姦と窃盗を繰り返す
犯罪者在日のクソチョンw
統計学の教科書は最後の補足も含めて全部見ておくべき.
データサイエンスといえば確率統計、確率統計と言えばデータサイエンス
AIやらpythonやらsqlは統計学のオマケ
>>773 入門書レベルの人は
ベイズなんて全く気にしなくていい
「おれさあ、ベイズわかってんだよね!」などと言って
自慢したいんだろうがやめておけ。
統計学にて自慢は大ケガのもとだ
初心者は初心者らしくしてればよい
ベイズ統計を分布の話から理解しようとしたら無限次元正規分布(ガウス過程)とカーネル法の理解が必要
ベイズ統計は本当に何にも知らないか、頻度論を十分に理解している必要がある
776はナンセンスだが
めんどくさいから条件付確率で計算するっていえばいいよ。
ベイズじゃないと解けない、あるいは解くのが困難な問題ってどんなのがあるの?
プログラム的にはベイズ対応することでパラメータチューニングなど速くなるよね。
>>779 lasso回帰はラプラス分布の事前分布だぞ
そういう意味ではDLなど正則化付きのあらゆる分析はベイズ的と言える
つまり正則化付きモデルの予測分布を解析的に知りたければベイズが必ず必要になると思う。違ったらスマン
他には経験ベイズでハイパーパラメーター無くしたいとかの動機もある
ノンパラベイズ使って辞書なしで単語分割してくれる技術がある。最近だとDLでも出来るみたいだがベイズで発明された上でDL化してるわけだからベイズの知識を持ってないとそのDLの発明は出来ないわな。全く同じものじゃないだろうし
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
Pythonさえろくにできないバカチョンのくせに
できるとほざくクソチョンw
日本で強姦と窃盗を繰り返す
犯罪者在日のクソチョンw
ベイズベイズ別に要らんし。
カルマンフィルタとカーネル法理解していたら十分。
>>786 それはカルマンフィルタはベイズだろっていうツッコミ待ちかい?
>>787 歴史的にはカルマンフィルタ=ベイズではない。
そもそもカルマンフィルタの3つある証明の簡単なやつにベイズの方法があるだけであってカルマンフィルタ=ベイズではない。
カルマンフィルタは最尤推定だよw
しかし確率モデルで正則化しようと思えばベイズを使うのが普通だから実質「ベイズ要らない」=「確率モデル要らない」になるんだか...
まず、ノンパラで因果推論はだめぽと思うからその分野で何のモデルが使えるか考える
条件付き混合モデルのような確率モデルで因果推論が出来るとしてそのモデルで正則化しようと思えばベイズ推定が必要になる
(セミパラで因果推論が正しく出来るか証明してないから検証は必要だが)
あと、「ベイズいらね」って言ってる香具師はDL含めて普通の回帰分析はめちゃくちゃ強い仮定に基づいて計算してるの知ってるのかな?
一つ例を挙げると
説明変数に誤差がある→それ用の確率モデルで尤度方程式を導出→いやいや、この場合最尤推定はあまり良くない→確率分布のリーマン空間を考えてベストな推定を獲得する
ベイズを否定する=確率モデルを否定する=この流れを否定する
ということになるが
>>792 正則化する理由、目的はなに?
正則化しなくても良いんじゃないの?
ベイズ的に解釈するかどうかでしょ
ベイズか否かなどという議論はナンセンス
こんなスレでステマって…と思ったがこの手のスレとしてはにぎわってるほうか
ニュートンのベイズ特集は表紙にベイズ統計と書いておきながらベイズ統計とは無関係なベイズの定理でひたすら計算しまくっていたり
未だに事前分布のことを主観分布と言っていたり色々と問題ありだわ
ニュートンの記事読んでないが、別に誤ったこと言ってないように思うが
ベイズの定理は条件付き確率の定義に従って導出される単なる事実でしかなくベイズ的な考え方をしようが頻度論だろうが常に成り立つ
別にベイズ統計の本質でもなければ根幹を成すものでもない
ベイズの定理で計算しまくる能力が必要とされる場面は確かにあるだろうがそれは「ベイズ統計入門」ではない
ベイズつってもどうせMAP推定するならメタパラありの最尤推定といっしょだろ。
流れと関係なくて申し訳ないんだけど
学習済みの重みを利用して、出力側から入力側に逆方向に演算して入力データを復元するって原理的可能?
MNISTだったら10個の確率値から手書き数字の画像を復元する、みたいな
ベイズ統計の根幹としてレンニの公理や交換可能性をあげる人もいるが、
別にベイズの定理をベイズ統計の基礎という主張もなんの間違いもないぞ
>>792 確率微分方程式からの視点を知らないね。
あとは射影によるリースの表現定理からの議論が全くない。
知ったかもいいとこ。
>>805 面白いね
原理的には情報量的に不可能だが、近似的には確率値から復元するデコーダーを、学習出来る可能性は有る
>>806 それは「掛け算はベイズ統計の基礎」、「積分はベイズ統計の基礎」とか言うようなレベルかと
ベイズの定理は単に式変形でよく使う計算ツールでしかない
>>809 >>810 君、なんの話をしているか分かってないね?
知ってる一番難しい言葉を並べてるだけだと思う
知ったかもいいとこ。
もしそうじゃないと言うなら"測定誤差問題"がリースの表現定理とどう結びつくのか説明してくれるか?
念のため言っておくが、今「カーネル法」の話も「確率微分方程式」の話も"全く"してないぞ
99.99%このレスはスルーされると思ってる
>>805>>807
Google の猫みたいなことならできるでしょ
データの復元とはちょっと違うけど、その出力を得る理想的な入力の逆算はできる・・・場合もある
ネットワークが複雑になっちゃうと無理だろうけどね
たとえば Attention なんかがはさまるとできそうな気がしない
>>805です。皆さんありがとうございます。
完全な復元は難しいですが、学習を通じた近似的手法、あるいは理想解に近づけるための模索といった方法なら可能なのですね。
情報理論などについてもう少し勉強してみようと思います。
いい加減な知識しかないので
ちゃんとしたいとは思ってるけど。。。
>>813 カルマンフィルタ=ベイズという意見があり、ベイズが必須というわかった口した発言(>>ID:lImhU2CT0)があったので反論したまで。
ところでカルマンフィルタ=ベイズとは何が背景でのべているかな?
>>813 あと…、まさかカーネル法ごときも理解せず反論してるわけじゃないですよね?
>>820 ではカルマンフィルタ=ベイズではない話と確率微分方程式とリースの表現定理がどう関わってくるのか聞こうか
そして、
>>792でカルマンフィルタは最尤推定だと言ってるんだが、何の話をしてるんだ?
>>791がこっちの意図まで分かるように詳しく説明してくれていてそれを認めているのは明らかだが
>>824 まずカルマンフィルタは最尤推定ではない。
いったいどの定義からその話になるんだ?
>>826 MAP推定が最尤推定+ノルム正則化と見做せるのは有名な話だが
>>827 それが真だとしても
同じ対象の見方を変える事ができるだけのような気がする
等しいというのは何?
どんな問題にも全く同じ結果を得ることができて計算量も同じとか?
PRML13章
状態空間モデルのうち、
・潜在変数(カルマンフィルタ):最小平均二乗誤差推定
・モデルパラメーター(EMアルゴリズム等):最尤推定
モデルパラメーターは変分ベイズでも推定可能
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
Pythonさえろくにできないバカチョンのくせに
できるとほざくクソチョンw
日本で強姦と窃盗を繰り返す
犯罪者在日のクソチョンw
>>824 まあ、ついででいうとまるで人(俺)が理解してないことを前提にしてる点でお話にならないと思う。
ただただ難しい話をしてるわけじゃなく、ベイズベイズ拘るのは世界を知らないと同じ。
あと
ID:F4yFaW3g0=ID:F4yFaW3g0=ID:CwJFfZdJHな
カルマンフィルタて大学で習ったかなあ
記憶にない(笑)
>>831 全然議論になってなくて草
アンチベイズならその理由を言えばいいのに
唐突に確率微分方程式やリースの表現定理を出して支離滅裂な発言を繰り返すのは理解していない証拠
カルマンフィルタなんか数時間で勉強出来るからそれを知ってるぐらいで天狗にならずに情報幾何学ぐらいは勉強するべき
ただわめき散らすだけじゃなく論理で反論しないとな
「なぜベイズは要らないのか」今その話をしているのだから余計な話はしなくて結構
PRMLは避けて通れないのかに
難しいっちゅうんで後回しにしてる
>>835 英語が得意だったらPRMLの英語版のPDFが無料で公開してくれてるよ
PRMLを読みやすくしてくれる同人誌も無料で公開してくれてるよ
PRML読みやすいわけでもないけど、ある程度まとまったものってなるとどうしてもあれすすめることになるわな。
>>834 勝手に断言すなばーか。
情報幾何も習得済みだよ。
ところで…
カルマンフィルタを最適推定と勘違いしていた>>ID:pFzGbS6W0さんはなぜベイズだけが問題解決に必須だと断言するの?
んな議論に終止符を打ちたいAutoML-Zero君
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
Pythonさえろくにできないバカチョンのくせに
できるとほざくクソチョンw
日本で強姦と窃盗を繰り返す
犯罪者在日のクソチョンw
クラスターのクラスター分析新説

>>842 わらわら。
まあ、本人も言ってる通り客観的な定義かあやしそうだから数式で示してよ。
LiNGAMの説明で軸を入れ換えただけで非対称性があるから因果推論可能という説明を見ますが
具体的にどうやってそれをモデルに組み込んでるんですか?
論文は読んでません
図解・ベイズ統計「超」入門 (サイエンス・アイ新書) 、という本で
学習しようと思うのだけれどこれは絵本 かな?
今までになかった画期的な自然言語処理だね。
人間と同じだ。
人間と同じ能力があるなら、善悪や美醜のような判断もできるかも。
本当に発見したなら論文あげるなり実装あげるなりすればええやん
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
Pythonさえろくにできないバカチョンのくせに
できるとほざくクソチョンw
日本で強姦と窃盗を繰り返す
犯罪者在日のクソチョンw
基本的な質問で申し訳ないんですけど、そもそも分類器(で良いんですかね)って何なんでしょう
例えばタイタニックのデータを使って学習するとか、顔写真いっぱい読ませて顔検出させるとか、学習の結果何らかの「判断基準」が生成されるという認識なんですけど
この基準の実体って一体どういうものなんでしょうか。いや中に小人さんがいるわけでもないわけですし
何かしらの新規データが投入されて、その基準と「照らし合わせて」、「判定する」っていうのが色々説明読んでも概念的というか実際どういうことしてるのかと
opencvの顔認識見てるんですけど分類器のコンストラクタでなんかぐちゃぐちゃ数値書いてるxmlを読み込んでてこれどういうこと?ってなって不思議に思ったんです
>>873 ある空間を〇と×に分ける境界線や境界面
>>875 正確には超平面
座標変換した超空間でもっともうまく分類する
超平面を決定する問題
超平面ググッてみましたけど、つまり二次元のグラフで最小二乗法で近似直線の方程式出すみたいに、入力データに上手く合致する方程式が生成されるってことでいいんですかね。平面って方程式の形で扱うことになりますよね
方程式を保存というのもあれですから、a1x1+a2x2+......+anxn=0 としたらa1~axのリストが分類器として外部ファイルに保存されるとかそんな感じでしょうか
判定する新規入力データに関しては各特徴量と係数をそれぞれ掛け合わせて総和を取ってみたいな
>>877 2次元平面でならExcelの散布図に散らばった
データ点同士が似ているなら近傍に偏りがあるはず
と言うことにして境界線を求める
その境界線が求まればそれ以上以下、内部外部などで判定出来るようになるということ
その軸(パラメーター)がxyの2つではなく
gpt-3 だと1750億パラメーターつまり1750億次元の散布図の境界を超平面で分割する事
ありがとうございます。
ただ知りたいのはそういう概念的なところでなくて、プログラムの中でそれがどういう数値データになっているのか
判定ってどういうアルゴリズムでされているのか、そういう次元のことでして
>>879 >>877の通り
数式の係数を保存している
>>879 アルゴリズムはいろいろSVMとかDTとかKmeansとか
機械学習のプログラミングスクールに行こうと思ってるけど直前で悩みだした
70万が半分になるけどやっぱり高いし、とはいっても独習だと学んだ証明が得られないし
>>885 すいませんけど一応理由欲しいです。背中を押して欲しくて
子どもチャレンジや学研やらリモートの独学に向いてない人は一定数いる
コロナ禍で美術大の学生さんとかは気の毒で仕方ない
ん十万円も払ってモニター画面だけでは満足出来ない
環境に身を置かないと学習出来ないという体質なら
通える環境がある所に行くべき
通える環境あるのはやっぱりいいですよね
ほんとはキカガクってスクールが第一希望でしたがコロナでオンライン授業になったみたいなので
やめとこーってなりました
まずは統計検定3級を狙ってみたら?
実務だと2級~1級の人が多い印象だけど。
講義とか研修とか同じ内容でも受ける人によってその価値は違うだろう
内容を理解できるか、既に知っていた事か、自分の興味と合っているか、実践する機会があるかとか人によって違うし
>>892 転職かスキルアップかな
>>893 統計2級はなんとか取りました
あとはudemyやyoutubeでチュートリアル的なものは出来るようになったけど
理論面はちょっと厳しい
>>895 2級持ってるなら、社内プロジェクトに参加させてもらってデータ分析の実務経験を積んだらいいんじゃない?
プライベートで本読んだりコンペに参加したりしつつ。
会社でそう出来れば一番いいですが難しいので外で学んでくるかってとこですね
>>894の人の言う通りですし、金額に見合うかは分かりませんが得るものはやっぱりあると思うので
スクールで頑張ってみます
自分みたいに基礎だけ勉強して
すぐコンペに参加するタイプの人は少なそうだな
コンペで上を目指すということは
その問題に対しての基礎知識を知らなければならないということであり
今、何が最新なのかを探すことになる
上にいる奴等の手法を逸早くパクるっていう
一番重要なことは勉強で学ぶことが出来ない
と言っても自分ももう参加してないんで今はどうなっているのか知らないが、、、
自動化が進んでるんだろうな
今アンサンブル時代って聞いた
即興でチーム作ってアンサンブル学習で多数決で勝負らしい
JAZZかよ
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
Pythonさえろくにできないバカチョンのくせに
できるとほざくクソチョンw
日本で強姦と窃盗を繰り返す
犯罪者在日のクソチョンw
gpt3の日本語版、 NTT 当たりが作らないかな
スクールとかいって活躍した人知らないからやめときな
ぶっちゃけこの分野はみんな独学だよ
基本を学んだ証明が欲しいならコンペや自作プロダクトでいくらでも証明できるからな
>>906 コンペって参加すれば何人中何位とかランク付けされるんですか?
それとも、例えば、トップ3だけ表彰されるとかそんな感じですか?
もし、10000人参加して全員の順位が出るのならば、1000位くらいでも結構勉強しているという証明になりますよね。
そもそもコンペというのは人間が評価はしないんですか?単に、認識率が高ければ高いほどいいAIというような評価なんですか?
もし後者だとすると10000人参加しても1位から10000位まで簡単にランク付けできますね。
>>907 Kaggleという有名なコンペがあるから調べてみるといいよ。
実務だと与えられたデータで予測精度を競うというより、データそのものを適切に抽出する実験計画の能力の方が求められたりするけど。
>>901 xgboost一強になってしまってから知らないんだけど
トレンド変わったのかな
>>902 ある意味パワー勝負みたいなところあるからね
そんな感じになってるんか
>>910 テーブルデータ以外でも
無理矢理xgb使ってみるといい数値が出る
ってことも結構あるしな
文部科学省が公開した新学習指導要領に対応した高校の「情報」の教員研修用教材で
kaggleのタイタニックや黒魔術が載ってたんだな、、、
非力なPCでも動くってことでtinyYOLOなんだろうか?
あのダークな感じがマニアックだと思ってたけど
そんなちゃんとした資料に出て来るようになってるんだ、、、
kaggleは精度求めること以外脳がない人が多いよ
実務ではデータ理解の方が重要なのにkaggleのディスカッションだとホストに対してラベルの付け方よこせとかそんなのばっかり
>>915 データ理解って解釈するって事だから解釈する人次第で変わるんじゃないか?
つまり人によって違う
機械学習なのに形式的に扱えないとそのメリットの一部が損なわれるように思う
「よくわからんけど予測精度は高い」ようなモデルを運用してる会社ってあるのかな?
顧客への説明とか、leakageのような落とし穴を回避するためにも、ある程度は人間が理解可能なものを運用してるんじゃないかな。
実データには多重共線性があるので、実際には理解した気になってるだけかもしれないけど。
温暖化仮説を信じ込んで対策に無駄な金使ってる企業はいっぱいある
人間が理解可能=機械学習良く分からない人にも人間の言語で説明できる、という意味ならそれは必須ではないし、必須とするなら機械学習の適用範囲を自ら制限することになる
モデルの良さを客観的な数学的指標に基づいて検証している(その数学的意味を理解できない人には意味不明)、という意味なら当然必須だろう
人に説明できるって言うのは モデルに要求されるひとつの機能ではあるけれど必須でもない気がする
将棋や囲碁で人が理解できない手を 打っていても人より強いわけで
馬鹿には理解出来ないってだけで
理解出来る人間もいる
法的責任が発生する場合には責任者は人間なので理解できないと不味いでしょうね
>>917 自社で使う分には内部で合意できたらいいんじゃないの?
>>917 DLは内部の処理は説明できないんじゃないかな?
それでも使われている所はあるんだろう
>>919 モデルの良さって汎化誤差とか正確率とか混合行列とかで計算する値の事を指している?
>>922 それも事前のテストでこんな結果が出ていたから使った
でいいんじゃないのかな?
人間に任せていても突然の病気とかで想定外の事が起きたりする
完璧はコストとかの制約の中で難しいだろうし
普通のプログラムでも使用結果は免責だろう、ものによるとは思うけど
結局googleとか自社サービスで使う以外はほぼ無理だろ。もめごとの種にしかならん。
>>929 責任取らずに物だけ作ればいいと思ってんのが日本的発想だっつーの。
そんなだからSIerに牛耳られるわけだ。
もろだけ作ってればいいとは思ってないけど
便利なものは率先してなるべく早く 市場に流そうっていう意気込みが見られるのは 中国米国だね
プログラムならすぐアップデートすりゃいいけど、形ある商品だと止めてほしい
だいたい日本の製造業は責任取るから動作検証とかでコスト掛かって余計に負けていったけど、
買う方からすると高くても壊れないほうがいいわ、自分は。
飛行機とか車とかその仕組みを詳しく知らなくても利用してるんじゃないかな
故障発生率とか燃費とか事故時の被害の程度とかテストや実際の結果を数値化して判断しているだろう
突き詰めて行ったらエンジン内部の酸素やガソリンなどの分子や粒子の細かい動きがどうなっているかは判らない事もあるんじゃないの?必要性が高くなければその解明の優先順位は低くなる
飛行機の限界積載重量って相変わらず「だいたいこのくらいなら安全じゃろー」程度しかわかってないよな
自動運転当たりのaiなら
治験みたいに
承認受けられるようにしたら?
>>935 そういうことにはならないだろうなぁ
例えば、物にもよるだろうけど俺が知ってるディープフェイクは口元に物を持っていくとそこ周辺が完全にぼやけるんだよね
飛行機や車とは違ってありとあらゆる映像を想定して評価するなんて不可能に近いと思う
したがって定量的な評価だけじゃなく意味を正しく捕らえられているかの定性的な評価が求められると思う
さらに言えば定量的な評価にはトレンドやら空間的自己相関によるランダムネスやらの問題が出てくる
専門的な言葉を使えば、評価に使ったサンプルは独立かつ同分布の両方を満たすことはあんまりないってことさ
無作為割り当て以外の因果推論ならなおさら定性的な評価が求められる
え?無作為割り当て以外の因果推論なんて不可能だって?
全くもって同意。俺の上司に言ってやってくれ
ユーザーの行動ログを利用した強調フィルタリングによるレコメンデーションとか何言ってんの?って
>>937 死亡事故が発生したら誰がどう責任を負うの?
>>936 軽過ぎても危険だから
ダミーの荷物載せて調節するんだよな
>>940 船もそうだな
>>938 > ディープフェイクは口元に物を持っていくとそこ周辺が完全にぼやける
ホッホー(・∀・)
>924
重みw行列のi,j成分の大きさでこの項目は考慮されているとかやってるみたいよ
>>942 w[i,j] != 0の有意差検定とかできるのかしら
> お前は毎朝起きるたびに俺に負けたことを思い出すよ^^
あー、ホンッとに思い出すなあ(笑)
キチガイの嘘つきの低レベルFランの、
朝鮮ゴキブリBot君は、
チョン独特の「なにもできないけど俺のほうがジャップより偉い!」的な
ことはよーくわかったよ。
ホントなにもできない朝鮮ゴキブリBot君!
クソチョンw
Pythonさえろくにできないバカチョンのくせに
できるとほざくクソチョンw
日本で強姦と窃盗を繰り返す
犯罪者在日のクソチョンw
需給予測のこと?
会計とかposシステムとか作ってる会社が既存品の新サービスとして開発してるよ
人間が運転するよりAI運転の方が事故率や損害が小さければ使われるだろう
自家用なら個人が乗って緊急時は自分で運転することにして責任を負うとか
メーカーは販売会社が保険を掛けておくとか(その分販売価格に上乗せされるだろう)
社用車ならその会社やメーカーは販売会社が保険を掛けておく
人間が事故を起こしても元どおりにする事はできないし結局はお金で解決するくらいしかできない
事故が起きたら起きないように改善したらその後の車に反映されて更に事故率は下がる
個人に依存していたら改善は個人単位でしかない
>>938 何を言いたいのかよく判らないけど
意味を捉えるって猫とかの判別はある程度できているし
物体の切り出しもある程度できているだろう
ディープフェイクの例は個別に作り出してから組み合わせる処理をするべきところで
複数の物体を同時に作り出しているからってだけだろう
>>942 リバースエンジニアリングみたいな事はできるだろうね
出来上がったものを分解して調べる
ここを少し変えたら結果がこう変わったとかを調べていけば出来上がったものについて少しは判るかもしれない
そのコストをかけて説明するだけだとコスパ悪いと思うけど
>>950 >猫とかの判別はある程度できている
(-ω- ?)はて?この根拠はどこにあるのだろう?
人類は過去に一度でも猫判別の精度を測れたことがあるのだろうか?(=゚ω゚=)ニャー
夕暮れ時の逆光やレア猫種の微妙な角度などあらゆる場合を想定したデータセットなど用意出きるのだろうか?
やっぱり人の主観によるモデル評価が必要になりそうだ(゜-゜)(。_。)ウンウン
(ΦДΦ) <ギギギ…ボクハニンゲンニナレルノ?
■ディープラーニングの判断根拠を理解する手法
https://qiita.com/icoxfog417/items/8689f943fd1225e24358 無作為割り当て以外の因果推論の場合、残差と説明変数に相互情報量がどのくらい残っているかとか色んな角度で妥当性を検証するからもっと大変だ(゚A゚;)
xvideosかpornhub辺りで学習させると、顔見ただけで女性器の色と形を類推する「omamco generator」は作れますか?
猫かどうかの判断は主観でええやろ
どうせラベル付いてんだろうし
教師なしのモデル評価になるとまた変わるか
>>957 違う!
かわいいアイドルの顔を読ませて女性器を生成したいの!
鼻がデカい男はイチモツがデカいとか、見えない相関関係があるでしょ?
女性器にも相関関係があると思うの。
唇の色が〇〇なら…的な。
>>952 人間でも難しいものはそもそも判別する情報が不足しているから判別不明だろう
機械学習は人間にできない事も必ず出来るようになるものではないだろう
遺伝的アルゴリズムについての良い参考書ありますか?言語はPythonです。
ディープラーニングの勉強してて画像処理のところに入ったんですけど突然ネットワークの図が板を重ねたようなものになって困惑しています
こういうやつです。特徴量の数だけ入力層のノードがあってそれが接続されていて重みがあって活性化関数があって……という感じで理解していたのですが
ノードはどこへ行ったのでしょうか
>>963 いままで一次元に並んでいたノードを並べ替えただけ
一枚の板にはノードが二次元に並んでいる
板が何枚も並んでいるので三次元になってると思えばいい
>>962 遺伝的アルゴリズムは仕組みだけの事だから
どんな本でも良いと思う
1.遺伝子に相当するデータを持たせて
2.環境暴露で評価をソートして選別淘汰
3.ランダムに掛け合わせて子孫生成
4.1からやり直し
AWS lambdaかazure functionsでtensorflow-gpu使ったモデルの推論結果を返す関数作りたいんだけどどっち使うのが楽かな?
なんかAWSはpip使えないみたいだしazure の方が良さげ?
>>966 Azure FunctionsはC#/Windowsランタイム以外は使い物にならないゴミなんで手を出しちゃダメ
コンテナにしてFargateとかGCPのCloud Runとかにしたら
>ディープラーニングの本質は、n次元ベクトル空間の点集合を超平面で仕切ってみせることである。
こう書かれてた
>>969 沢山あるものを分類することを数学的に表現したって事でディープラーニングに限った事ではないような
実現方法の1つにディープラーニングがあるけど学習の計算量で比べると他のSVMとかのアルゴリズムの方が良いんじゃないか?
いろんな視点でどの方法が自分の問題に適しているかを考える必要があるだろう
1つの決定的なアルゴリズムや方法が見つかれば良いけど
>>969 でーぷらーにんぐじゃなくて単なる分類問題のことやでそれ
「カブトムシの本質は、6本脚で歩くことなのである」みたいなちぐはぐな主張
言葉の定義について質問です。
1,予測アルゴリズム (e.g. y = a0 + a1 * x1 + ... + an * xn)
2,予測アルゴリズムのパラメータ(で合ってます?)を求める学習(?)アルゴリズ
ム(e.g. 最小二乗法)
3,求められたa0~an
基本的にデータに対して2を適用して、3を求めて、1と3で予測するっていう流れだと
理解しています
で、「機械学習のアルゴリズム」って言ったときの「アルゴリズム」って1でしょう
か2でしょうか、それとも両方でしょうか
それと「モデル」とは3だけのことを指すのでしょうか、それとも1と3でしょうか、
もしくは全部でしょうか
scikit-learnだとアルゴリズム名のオブジェクト作ってそれにfitしてpredictしてみ
たいにやれちゃうのでちょっと混乱しています
よろしくおねがいします
>>972 両方を指すのが普通じゃないかな
こういうのって必ずしも正確な言葉の定義が決まってるわけじゃないから人によって違いそう
もし誰か正確な定義知ってる人がいたら教えてくれ
>>972 1がモデル
2が学習アルゴリズム
3はパラメータ
2の学習アルゴリズムもパラメータがあってハイパーパラメータと言われていると思う
普通モデルって言ったら1と3のセットを指すことが多くね?
確かに1だけのことをモデルって呼んでるのも見るけど
モデル、ネットワーク、
目的関数、損失関数、
バッチ、ミニバッチ、オンライン
オプティマイザ、最適化アルゴリズム、
パラメータ、ハイパーパラメータ、
過学習、過剰適合とか
似てるようで同じだったり違ったりする用語が
結構あるからなー
>>972 1、モデル
2、アルゴリズム
3、パラメータ
です。
世の中的には、AIと機械学習と深層学習が同じだと思われているからな
機械学習で得られるものに君が知能を感じるならそれは人工知能だし知能を感じないなら人工知能ではない
それぐらいに人工知能とは曖昧な言葉なので真面目に論じること自体がおかしい
stackoverflowとかquora とか見た感じモデルは予測アルゴリズムにデータから得られたパラメータ入れたもののようだね
要は予測に使うものそのものってことでまぁイメージ通りではある
少なくともパラメータ単独のことをモデルとは言わない模様
単純な計算式を予測アルゴリズムって言うのは気持ち悪い
単にモデルだろ
派遣屋って独自サービス作ろうとして失敗した会社の残骸だったりするんだよな
派遣屋は利益が出ている分野に必ず常駐している寄生虫だろう
半導体とかIT系とか新しいサービスとか
蔓延している分野は確実に成長しない
昔ながらの業種には寄生出来なかったのか派遣がはびこっていない
つまり人が居なくなると高い金を払って直接人を集めないといけないんだな
爺さんでも自営でほんのり稼いでいる人が多い分野になる
人手不足の所に労働力を紹介するのは悪くないだろ
ピンハネ率が低ければ
アメリカも多分中国もそうだったと思うが
派遣社員の給料は正社員より高いからな
プロフェッショナルが対応をするイメージになる
それだったら問題は無いんだろう
アメリカで派遣がどうこうと言われてないだろう
米国googleには非正規雇用社員が半分近くいて、正社員と仕事内容が大差ないのに、待遇格差があるって問題になってた気がするぞ
このスレッドは1000を超えました。
新しいスレッドを立ててください。
life time: 111日 15時間 1分 7秒
5ちゃんねるの運営はプレミアム会員の皆さまに支えられています。
運営にご協力お願いいたします。
───────────────────
《プレミアム会員の主な特典》
★ 5ちゃんねる専用ブラウザからの広告除去
★ 5ちゃんねるの過去ログを取得
★ 書き込み規制の緩和
───────────────────
会員登録には個人情報は一切必要ありません。
月300円から匿名でご購入いただけます。
▼ プレミアム会員登録はこちら ▼
https://premium.5ch.net/ ▼ 浪人ログインはこちら ▼
https://login.5ch.net/login.php
lud20250212010914caこのスレへの固定リンク: http://5chb.net/r/tech/1588293154/
ヒント:5chスレのurlに http://xxxx.5chb.net/xxxx のようにbを入れるだけでここでスレ保存、閲覧できます。
TOPへ TOPへ
全掲示板一覧 この掲示板へ 人気スレ |
Youtube 動画
>50
>100
>200
>300
>500
>1000枚
新着画像
↓「【統計分析】機械学習・データマイニング28 YouTube動画>12本 ->画像>12枚 」を見た人も見ています:
・【統計分析】機械学習・データマイニング24
・【統計分析】機械学習・データマイニング30
・【統計分析】機械学習・データマイニング16
・人工知能ディープラーニング機械学習の数学 ★3
・人工知能ディープラーニング機械学習の数学 ★2
・【機械学習】Airbnbが社内にデータサイエンス大学を開校、非技術系一般社員も対象
・【IT】AWS、機械学習機能を活用したデータセキュリティサービス「Macie」発表
・【GPU】AI・機械学習がGPUの新たな巨大市場をつくりだす - ARM GPU部門のトップ、ジェム・デイヴィス氏
・機械学習とかやってる大学生なんだけど
・【IT】機械学習の波、メモリーへも
・【Tesla】 機械学習用レンタルサーバスレ【Titan】
・【技術】AIが衰退期に 機械学習エンジニアが職を失う ★2 [雷★]
・【IT】統計学と機械学習を支える数学が、 「全く一緒」と言えるわけ
・【脳科学】脳活動の全体像把握、機械学習は強力なツールになり得る [すらいむ★]
・Pythonで機械学習してるやつって"浅い"よな ライブラリ頼みで本質を理解してない
・【敵対的機械学習】カラープリントした紙で「AIの監視」から逃れる方法[04/29]
・Googleが機械学習用に作ったTPUマシン、うっかりスパコン「京」を超えてしまう
・【IT】Google、プログラミング不要で“機械学習”試せるサイト公開
・【機械工学】〈動画〉「学習をほとんど必要としない」義手が開発される[05/30]
・【Google】グーグルでは機械学習を用いることで、ネトウヨを排除するシステム作りに力を入れている
・【朗報】God of War Ragnarok CS初の機械学習アプコンによりとんでもない画質を達成する
・XboxGameStudioの機械学習アプスケ技術の次世代感すごい。レイトレよりこれを推せば良いのに
・声優の声で歌わせられるフリーソフトがすごすぎると話題に i☆Ris茜屋日海夏の歌声を機械学習したもの
・【解説/ハードウェア】ハードディスクに障害が発生する可能性を機械学習で予測する研究 [すらいむ★]
・【PC】米AMDがGPUボード「Radeon Vega Frontier Edition」発表、機械学習でも性能発揮
・【計算科学】機械学習で作った簡易的な人工知能で界面の構造を予測 22かかる計算を3時間で/東京大生産技術研究所
・【ハードウェア】機械学習に最適とされる「NVIDIA H100」の代替になり得る「NVIDIA L40S」の性能とは? [すらいむ★]
・【IT】「TensorFlow.js」公開、Webブラウザ上で機械学習の開発、学習、実行が可能に。WebGL経由でGPUも活用
・【素材】機械学習とナノ3Dプリンターで「鋼の強度と発泡スチロールの軽さを兼ね備えた新素材」の開発に成功 [すらいむ★]
・【IT】Amazon Web Services、機械学習モデルのためのフルマネージドサービス「Amazon SageMaker」を東京リージョンで
・【AI】「AI多すぎ、何使えばいいか分からない……」を解決するAI「HuggingGPT」 文章入力だけで、適切な機械学習モデルを自動選択 [すらいむ★]
・【岐阜・高山】学習塾生104人がホテルで食中毒「カンピロバクター」
・【マイナンバー】小中学生の学習履歴やテストの成績をマイナンバーにひも付けオンラインで管理。政府、2023年にも試行★3 [記憶たどり。★]
・DeepSeek、ChatGPTに質問した結果を学習データに使用か
・【AI】学習データ争奪戦、「廃れたSNS」のコンテンツに群がる生成AI企業 [すらいむ★]
・化粧品製造ライン機械オペレーターが良さそう 正社員で経験学歴資格不問 結婚する気ないからこう言う仕事がいい
・機械保全技能士 part18
・ADHD、LD等の子供たちの学習と生活-28
・機械式腕時計が価値が高いという風潮48
・【速報】無双8 鈴木P「1人あたりのプレイ時間は1~2時間。バグ取りは機械に任せてます(笑)」
・機械の力を借りたい
・学習院大復活
・学習マラソン
・スマホで英語学習
・こんな舗装機械はいやだ
・機械翻訳された日本語もどき
・機械に生命はあるのか?
・英語学習における最大の間違い
・機械保全技能士 part20
・自転車乗りの機械式腕時計
・T.K.K.(東北機械化学)
・成蹊学習院~大東亜帝国までって
・機械式時計は全て故障品です。
・機械設計で使えるフリーソフト
・自慢の機械式腕時計見せてー
・【お題】PHP学習課題スレ【出せや】
・大学で学習相談のバイトしてるけど…
・【一号警備】機械警備に転職 2
・[ADHD]学習障害(LD)併発者[ASD]
・国立大卒だけど英語学習の質問のるぞ!
・【ムラ】村田機械【テック】2
・親には頼らない、機械に頼る料理の実践
・機械関連株 日本製造業を支える勇者達
・そろそろ学習院大学の需要出てくる頃か?
・無垢な猫からの手紙を届ける機械仕掛けの鐘
・第一種・第二種・第三種冷凍機械責任者 その135
23:10:01 up 67 days, 8 min, 1 user, load average: 8.50, 8.13, 8.32
in 1.4730517864227 sec
@1.4730517864227@0b7 on 062312

|



 @YouTube
@YouTube



 @YouTube
@YouTube


 @YouTube
@YouTube


 @YouTube
@YouTube


 @YouTube
@YouTube


 @YouTube
@YouTube


 @YouTube
@YouTube


 @YouTube
@YouTube


 @YouTube
@YouTube


 @YouTube
@YouTube


 @YouTube
@YouTube