◎正当な理由による書き込みの削除について: 生島英之とみられる方へ:
文字コード総合スレ part15 ->画像>1枚
動画、画像抽出 ||
この掲示板へ
類似スレ
掲示板一覧 人気スレ 動画人気順
このスレへの固定リンク: http://5chb.net/r/tech/1723861080/
ヒント:5chスレのurlに http://xxxx.5chb.net/xxxx のようにbを入れるだけでここでスレ保存、閲覧できます。
前スレ埋まってたので立てといた
テンプレとか過去スレを張るとNGワードで弾かれたので省略した
可能な人がいたら適当に補完しといて
Q. UTF-8にBOMは必要ですか?
A. Unicode規格ではUTF-8にBOMを付けることは非推奨と明記されています
LinuxやMacやInternetの各規格ではUTF-8にBOMをつける文化はありません
Microsoftはかつて技術者向けにBOMを付けることを推奨しておりWindowsのツールはデフォルトでBOMを付加していましたが新しいバージョンではBOMを追加しないよう変更されていっています
現時点でも文字コードの自動判別にBOMを使用しているアプリはあるのでそいうソフトウェアの使用に限って便利なこともあります
UTF8は、BOMは、非推奨の意味は、
1)UTF8はBOMは法的には🈲
2)UTF8はBOMは私的には🈲
3)UTF8はBOMは使っても🆗
4)SHIFT JISにはBOMは使おう
きっと、3)だな
だってBOMっていきなり先頭バイト
からしてUTF8に存在しないよな?
てか、UTF8は🈲にして
UTF16ビッグエディアンのみ🆗とし
ポクの大好きな笑文字☺とかは
第四水準漢字を削除して笑文字に
割当なさーーーーーい。
てか、第3水準とか第2水準の
割当た場所ってグダグダで
変更は無理ぢゃーーーん。
てか、第四水準はスッキリした
とこに割当られてるし
ドンドンサロゲートは廃止し
第四の場所に絵文字🥳とか割り当てて
超新型UTF16 旧UTF16とは、
第四水準と絵文字以外は
相互に完璧互換性在るハズ
俺って極超々天才だろぉーーぅ
ASCII文字以外を使っているならアスキーアートではなく
シフトJISアートやユニコードアートと呼ぶべき
もう丸囲み数字はやめようよ。
日本人はなんで打ちにくい①、②、③を書くのかな?
手間しかかからない。
>>15 かわりに何を書くの?
(1)って打って①に変換するんなら手間は一緒だと思うが
単に使ってる日本語入力環境の問題じゃね?
数字の1を変換したら候補に①はあるから打ちにくいとは思わないな
「いち」の変換の候補は、一、位置、市、イチ、一部、壱、1
、1、Ⅰ、① とかいろいろ、色とりどり、どれにしような
どれを使用しような。
てゆうーーか、「まるいち」って打ち込めば、丸一 だ
ま、「まるいち」って打ち込んでも、候補に①はでるが
単に、「いち」でも①が出てくる。てゆうか、
学習機能により、「いち」と打ち込むだけで
①が2番に出るようになった。ちなみに、第1候補は、
無変換である いち のままだ。学習機能ヤバイ。スゴい。ありえない
①が?に化けちゃってる。
①は使用🈲を推奨を、推奨しようよ
25年以上前からUnicodeに含まれてる文字が化けるソフトを使用禁止にしろよ
すまん5chで文字コードバグが起きてるんだがどういう事態になってんの?
「いち」なんて打たなくても「1」だけで良いんだけどな
UTF-8で見た目が同じものを二重に定義してしまった。
①~⑩までは昔からあるが、丸0と丸11以降を作り出してしまい、環境依存がさらに進んでいる。
IMEで変換する時に環境依存文字と出る文字は
CP932に無い文字ということ?
>①~⑩までは昔からあるが、丸0と丸11以降を作り出してしまい
しかも文字コードで丸内数字の大小比較出来ないんだぜ
大小比較は出来るけど連続性は全く出鱈目
しかもskipしてるし場所もバラバラ
今は標準のフォントで結構文字が入ってない?
そこにNotoあたりでも足せば... No Tofuというぐらいで
市販の日本語フォントはProフォントでも Adobe-Japan1-7 にある文字どまりで2万3千文字程度
Noto も国ごと文字種ごとにファイル分割されているのでフォント切り替えないと全ての文字は表示できない(あと新しく追加された文字はない
いろいろ都合があって一つのフォントファイルに入れるのは最大でも6万字程度に抑えられてるのが実情
なんでたまに中国の漢字が混ざるんかね
普通に使ってても混ざった事ないけど
CJK統合漢字という黒歴史
中国が文句言ったせいで
>>36 囲み文字の話だろこれ。無理に話広げんなっちゅーの
文字列"c9" と"c10" 大小比較考察に、
数値9と10は、後者は、デカい有。さて
文字列のそれは、後者はデカく無アル?
てか、wind○wsは、ファイル名並替順は
ロジックは、意味は、ワカラン有る。
てか、豆腐文字□ぽぃのとか?はやめて、👻
に、豆腐文字ぽぃのは、統一してよ。
文字コードに国境がないと想像してみよう そんなに難しいことじゃない
争いや宗教がなくなり 全世界の人が平和に暮らせる
僕のことを夢想家だと言うかもしれないね
とんでとんでとんでとんで まわってまわってまわってまわる
日本語のソートはJISコード順じゃないと使い物にならないから内部でUnicodeからJISに変換しているという本末転倒感。
何で今までと順番が違うんだとか言われても面倒だからね
文句言う連中は文字コード云々なんて知らないだろうし
今までと違うとか言う以前に、Unicodeのコードポイント順に整列しても意味不明だしね。
はっきり言って使い物にならない。
Unicodeで数字とアルファベットはフォント違いや上付きや下付きの文字があって
丸囲みでもデザインの違いが何種類もあるよね
こういう装飾的な物は文字コードの方でやるのか
HTMLなどの別の規格でやるのかどっちがいいんだろうね
文字コードの方でやるとプレーンテキストでも
文を見やすくできるけど文字の検索がしづらくなるんだよね
>>46 最近は記号や絵文字とかまでを登録するようなってるので普通の文字じゃなかたりするのも多数ある
一見アラビア数字に見えても実際は飾り記号(dingbat)だったり数学記号(math symbol)だったりするのも多い
(フォント違いに見えるのは数学記号)
(同じ丸数字が複数あるように見えるのは修飾数字と飾り記号)
日本からだと全角数字とかフォントによって見かけだけ違うのもあるし
そういやアップル圏のアプリの実装って
濁点半濁点付きの平仮名片仮名はちゃんと表示できてるの?
折り返し処理だとかそういう所で
アップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリアップル圏のアプリ
「Unicode 16.0」が公開 ~エジプト象形文字、レガシーコンピューティング記号を大量追加
5,185の新たな文字が追加。総計で154,998文字に
https://forest.watch.impress.co.jp/docs/news/1622857.html Windows環境では〜記号が波ダッシュより全角チルダの方で普及しているからなのか
日本語フォントでもフォントによっては全角チルダは表示できても波ダッシュは表示できなくて
波ダッシュが指定したフォントにならないなんて事がある
>>52 駄目フォントじゃのぉ
全角チルダをちゃんとチルダっぽくして波ダッシュと全角チルダを見た目で区別つくようにして欲しいって言ったら
全角チルダを波ダッシュ代わりにしてるWindowsユーザーからクレームが来るから面倒って言われた記憶
>>51 キャラクタベースの画面でインベーダーやパックマンができるようになるのか、胸熱
しかしこのレガシーコンピューティングの部分の多角形とかって持ってるフォントある?
https://en.wikipedia.org/wiki/Symbols_for_Legacy_Computing 以前アプリを作ってた時にこの手のマークがあるなら是非使いたかったのだが
なさそうだったので自前でアイコンを作って表示した記憶が
>>51 Game spritesやIconsのリファレンス元が知りたい
Symbols for Legacy Computing Supplement
https://www.unicode.org/charts/PDF/Unicode-16.0/U160-1CC00.pdf >>58 インベーダーっぽいのは「ALIEN CRAB」(異星カニ)、パックマンっぽいのは
「SNAKE」(ヘビ)等、固有名を避けあくまでも一般的なものとして逃げようとする
姿勢が見える
ソリッドステートサバイバー + スネークマンショー
横1列のドットパターンでコード割り当てて
合成も拡張して縦に並べられるとええかも
「U+~」の表記法って正式な名称ないの?「Short Identifier」?
>>66 そもそもUTF-8はその表記が正式な表記だから、表記の名称が存在しない。
回答ありがとう。表記法や表現自体には特には名前ないんか。
正規表現のグループに名前を付けようとして
「(?<UnicodeCodePoint>(?<Prefix>U\+)(?<Hex>[0-9A-F]{4,6}))」
みたいにしたんだけど、
「U+HHHH」全体をコードポイントって呼んでいいのか、
「HHHH」部分だけがコードポイントと呼べるものなのか、
っていう疑問が湧いたんだよね。
調べたらすぐ分かるかと思ったら全然分からなくてモヤモヤしてた。
>>70 xxxx がコードポイント(code point)
U+xxxx がコードポイント表記 (code point notation)
とかで良いんじゃね
知らんけど
0xBEEFとBEEFは表現は違うけどどちらも16進表記で指してる値は同じ
10進表記の48879も同じ値を指す
Unicodeのコードポイントってのは値を指してる
だからなんやねんだけど
>>73 コードポイントとエンコードの区別が付かない男の人って
Cスレの通りにやって文字出力したら化けるんだけど、文字コード民的な正しい対処法は?
ちゃんとソースファイルがUTF-8なのは確認した
http://2chb.net/r/tech/1721137434/350 #include <windows.h>
int main(void)
{
LPTSTR lptStr = TEXT("テスト😊");
printf("%s\n", lptStr);
}
win32でのAやW、charとwchar_tの事は分かっていて
Linux他でのクロスコンパイルを考えてwchar_tは使わずにUTF-8 everywhereで通しつつ
puts("テスト😊");
が文字化けしない様にしたい
特定システムロケールは仮定せず
ターミナルではchcp 65001してある
場合です
端末がUTF-8非対応なのはないとして
出力をファイルへリダイレクトするかダンプして
想定どおりのバイト列か確認してみては?
分かってるならなんでLPTSTRから変換せずに使ってんの
>>78-81 ありがとうございます
putsで文字化けしていたのは、コマンドラインでソースutf-8指定したら文字化けは直りました
だけど、引数が受け取れないですね
#include <stdio.h>
int main(int argc, char **argv) {
puts("テスト0😊");
for (int i = 1; i < argc; i++)
puts(argv[i]);
}
$ cl -utf-8 ConsoleApplication1.c
$ ./ConsoleApplication1.exe テスト1😊 テスト2😊
テスト0😊
???1??
???2??
$ ./ConsoleApplication1.exe テスト1😊 テスト2😊 > out.txt
$ cat out.txt
テスト0😊
???1??
???2??
(システムロケールEnglishでの環境です)
デバッグで確認したところ、引数のテスト1😊 テスト2😊は受け取りの時点(argv[i])でアルファベット以外の各コードポイントが?になってます
WindowsTerminal
MSYSTEM=UCRT64のMSYS2 bashです
$ echo テスト1😊 テスト2😊
テスト1😊 テスト2😊
$ gcc ConsoleApplication1.c
$ ./a.exe
テスト0😊
$ ./a.exe テスト1😊 テスト2😊
Error: Command line contains characters that are not supported
in the active code page (1252).
UTF8 everywhereは厳しいですかね?
WindowsでワイドキャラクタってのはUTF16LEのことだよ?
UTF-8 everywhere行けました
$ cat utf8.rc
#include "winuser.h"
CREATEPROCESS_MANIFEST_RESOURCE_ID RT_MANIFEST "utf8.manifest"
$ cat utf8.manifest
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<assembly xmlns="urn:schemas-microsoft-com:asm.v1" manifestVersion="1.0" xmlns:asmv3="urn:schemas-microsoft-com:asm.v3">
<asmv3:application>
<asmv3:windowsSettings xmlns="
http://schemas.microsoft.com/SMI/2019/WindowsSettings";>
<activeCodePage>UTF-8</activeCodePage>
</asmv3:windowsSettings>
</asmv3:application>
</assembly>
$ cl -utf-8 ConsoleApplication1.c
$ mt.exe -nologo -manifest "utf8.manifest" -outputresource:"ConsoleApplication1.exe;#1"
$ ./ConsoleApplication1.exe テスト1😊 テスト2😊
テスト0😊
テスト1😊
テスト2😊
$ windres --input utf8.rc --output utf8.res --output-format=coff
$ gcc ConsoleApplication1.c utf8.res
$ ./a.exe テスト1😊 テスト2😊
テスト0😊
テスト1😊
テスト2😊
はい、検索して適当に拾ってきたのでxmlnsが微妙に違いますが同じことですね
MinGW64ツールチェーンではutf8.rcを経由してマニフェスト埋め込みしてますが
MSVCツールチェーンではその経路だとこうなります
$ rc utf8.rc
$ cl -utf-8 ConsoleApplication1.c utf8.res
ついでにPythonでもやってみました
$ cat ConsoleApplication1.py
import sys
print("テスト0😊")
for s in sys.argv[1:]:
print(s)
$ python313.exe ConsoleApplication1.py テスト1😊 テスト2😊
テスト0😊
テスト1😊
テスト2😊
環境変数がセットされてたので強制的に空にしても問題ないようです
$ PYTHONIOENCODING= PYTHONUTF8= python313.exe ConsoleApplication1.py テスト1😊 テスト2😊
テスト0😊
テスト1😊
テスト2😊
>>90 まあ、あの荒れそうな言語がユニコード引数でエラー出すからな
>>73 コードはユニコード
それをどうエンコーディングするかでUTF8やUTF16やUTF32などがある
ネットの標準がUTF8に統一されてなって
ファイルシステムでもUTF8に統一されつつあり
プログラム内部でもほとんどの用途はそのまま透過的にUTF8が有利に
固定長で扱うUTF32はムダすぎで
可変長のUTF8は後ろからでも切れ目を間違えことなく
表示幅問題はUTF8/UTF32関係なく発生するため
>>92 >ファイルシステムでもUTF8に統一されつつあり
例を挙げてもらえますか?
>>93 Linux distro, MacOS, android, iOS,...
挙げ始めたが最近のリリースだと Windows 以外のメジャーどころは全部じゃね?
UTF-8は世界の誰もが好むわけではない。
どの民族もUTF-8の良いところと悪いところで悩んでいる
>>94 勘違いしているけど、それらの製品でも区別して使う分けている。
>>94 Linux (ext4) は、ファイルシステムとしてはエンコーディングは規定されてないのでは?
ディストロやユーザーがUTF-8を使ったりするのは自由だが
よってAndroidも同様
なんだAppleだけじゃんw
>>97 そんなこと言いだしたら APFS も NTFS も単にバイト列を記録してるのに過ぎない。
それをOSやライブラリとしてどう解釈するかがファイルシステムの文字列。
だから linux kernel でなくて linux distro の問題。
(もっとも最近の Linux kernel はデフォルトで UTF-8 を指定するABIとかあって文字コードの変換したりするけど。別問題)
>>98 >そんなこと言いだしたら APFS も NTFS も単にバイト列を記録してるのに過ぎない。
いいえ
UTF8を推しているのは形を変えたASCII信者の老害。
刷新できていない古いシステムを除くと
文字コードはユニコードになったね
エンコーディングはネット上がUTF8なので
それをそのまま扱うのが一般的となったね
UTF-8 より完璧な文字コードって何だい?
ASCII と SJIS と UTF-8 はいいねしたい
元のユニコードがクソだからなあ
結局どうにもならなくなって異体字セレクタとか出てくるし
ishの出力ってSJISが標準?
utf-8板のish欲しいと思ったけど
-Dutf8付けてコンパイルしても結局SJIS出力だった
バイトデータで出力してるだけでエンコーディング関係ないような
UTF-8対応してもバイト単位でみたら7ビットしか情報持てないから損
効率気にしないならコード変換したらいい
半角カナが3バイトになるけどエラー訂正なんかは使える
たまたまSJISでデコードしたら人間に読める(かもしれない)ってだけで
只のバイナリデータだよね
ファイル名がユニコードだと、
例えば2つのファイル名が同一かどうかの判定は、2つのユニコード列が同一かどうかの
判定をしなくてはならない。この場合の同一とはなんだろう。めんどくさい
>>111 「ユニコード列」みたいな曖昧な用語で考えると曖昧な結果にしかならなんわな
「ファイル名」という用語に限ってもOSごとに異なる意味をもち、「バイト列/コードポイント表現」(Linux/Windows)と「 unicode 正規化表現」(MacOS)のどっちのやり方もあるし unicode の正規化には複数の種類がある
>>103 ネットはJISもあるから、そう簡単な話ではない。
EメールだとまだJISが主流。
>>113 Macのせいで記号や改行コードの解釈がめちゃくちゃになった。
>>111はあえて雑に書いてあるんだが(めんどくさいからw)
>>113は「曖昧じゃない」んだ?
ハンカクカタカナ.txtと
ハンカクカタカナ.txtは
区別されると困るか区別して欲しいかは個人の好みだな
>>111,118
主観と好みの問題だから、現状がそれを孕んでいるかどうか心配ならNKFCで突合チェックしたら良いだけかな
>>118 自分はまったく別物だろうという考えだが、逆にそれを同じと思う人がいるというのに驚きだ
MacOS/iOS だと OS 的にファイル名はNFD強制なのでその2つ区別できないのが普通だな
Macユーザーは「半角カナはファイル名には使えない」という言い方してることが多いけど
Windowsは大文字小文字の区別を付けないのがデフォルトなんだけど、
WSL内からアクセスする兼ね合いで区別設定できる(fsutil)
>>121 Macにも同様の理由でNFD強制解除の設定があるのでは?
>>122 強制解除とかはなかったと思うが古い HFS+ と違って新しい APFS では論理的には書き込み可能なはず
一方でライブラリで、ファイルオープンする時にファイル名が強制的にNFD変換されるので通常のプログラムでは全部NFDになるのは避けられない
Macが一番遅れているのは意外だな
> Mac で NAS (SMB) のファイルが見えない問題を Unicode 正規化方式を変えて解決
> Unicode 正規化方式として NFD を採用しているのは Mac なのに,SMB (NAS) を介してみると当の Mac だけがそういったファイルを認識できない(ことがある)というのはなんとも皮肉な結果ですね...。
>>124 Mac はローカルファイルは NFD (っぽい独自仕様)で正規化されてる前提で、リモートのSMBの先は NFC (っぽい独自仕様)で正規化されている前提で動作するという謎仕様なので
Lunux は基本的に正規化されずに全部別の文字扱いで unicode の全文字が使える
Windows も基本的には正規化を前提にしていないが独自仕様の使えない文字がある
わかりやすいようにたとえで説明するとさ、
オマエんちに人を招待したら、土足のまま上がってきた
オマエはイラっとするんじゃね? はいオマエ遅れてる~
服装カジュアルな場所でも常にスーツ着てきてスーツ着てないやつは家族だろうと友人だろうと全員無視するのが Mac 仕草
その上、自宅用と訪問用に別の種類のスーツを使い分けてて同じ種類のスーツ着てないと相手してくれない
UnicodeはUnicodeで様々な言語の様々な表現ができるようにするなかで一意性についても
用途や目的によって方法は異なるとしているわけで、そもそもファイルをファイル名で特定するという
昔ながらのやり方との齟齬が出てきているのかもね。
使うなら使うでファイルシステムに用いる正規化ルールなどを定めなければならないんだろう。
同一性やコロケーション問題として
path-win-ntfs、path-linux-ext4のようにunicodeでpath-localeを定めてicu実装されたら良いのにと思った事はあったけど、
それで他の方法が駆逐されるわけじゃなく新たなバリエーションを増やすだけだから、今は余計な事するなと思うよ
>>128 ファイル名はOS的には単なる識別子なのでバイト列一致で良い
それを文字コードと絡めて正規化しようとするのがそもそもの間違い
バイト列をどのように解釈するかは別のレイヤーの問題
FSとしてならそれでいい
OSをどの層までとするかでも変わってくるけど
マウント時に変換かけてOS間の相互運用気にしてほしい
ネットワーク透過考えるとパスはURIで扱いたいしね
>>131 基本的にはアプリ側のライブラリ層でやるべきこと
OS標準ライブラリかユーザ追加ライブラリかはOSの思想によるし Linux とかだとOS標準ライブラリという考え方は縁遠いけど
マウントの時にファイルシステムで文字コード変換するのも否定しないけど、あくまで代替手段なので、固定ではなくオプションや設定で利用者で任意に変更できるべきもの
>他の方法が駆逐されるわけじゃなく新たなバリエーションを増やすだけ
ほんそれ
ファイル名にはASCIIにある文字しか使わないようにすれば解決
>>136 ASCII のバックスラッシュが円記号になってしまう OS がるらしい
>>136 じゃあまずはASCII以外でここに書き込むのやめろよ
>>138 ここにファイル名を書いてる人あまりいないと思うんだけど?
JISで全角チルダ定義したのがアレだよな
全角しか表示できない場面のためだろうけど
>>141 JIS は全角と半角とか定義してない(定期
>>142 えー、をMSIMEで変換したら
全角チルダ(U+FF5E)でした
抑揚のある伸ばし棒はこれが正解ですか?
>>143 知らん
MS が決めたことは MS に聞け
全角とか半角とか関係ない
この板には表層的にMSを持ち出すだけで思考停止する若干一名がいるね
>>145 シフトJISの「波ダーシ」を unicode の「全角チルダ」にマッピングする CP932 を規定したのはマイクロソフト
マイクロソフト以外の Linux とか MacOS とかその他の各社OSではそうなっていない
マイクロソフトが何でこんなマッピングにしたのかは専門家でも分かんない謎
unicode がまだドラフトの時代にあわてて作業したのでミスっただけの可能性も指摘されてるが、一度決めたものは互換性のために変えられないのだろう点は理解できる
マイクロソフトの場合親の敵の可能性があるから俺は許すね
気の済むまでじゃんじゃんやっといてくれ
unicode 規格が最初に作られた時サイトに参考情報として JIS と unicode のマッピング表が置いてあった
Linux も Mac も商用Unixもこの表に従ってJISの波ダーシを unicode の wave dash にマッピングした。さらに JISの規格書にもこのマッピングで記載された
ただ Microsoft 1社だけは JIS の波ダーシを unicode の fullwidth tilde にマッピングした
こんなんマイクロソフトの中の人以外に理由が分かるわけねーだろ
初期のUnicode仕様書の文字の形がおかしかったのがそもそもの原因なんだけどね
いまの仕様書では、〜(U+301C、波ダッシュ)は、~(U+FF5E、全角チルダ)と同じ字形だけど、
古いものは、上下反転した存在しない文字の形だったので、どちらに合わせるかを決める時点で、
MSは形の相似した全角チルダのU+FF5Eを、その他は仕様どおりの波ダッシュのU+301Cを割り当てた
更にMacは仕様書を無視して字形を変更し、現在の仕様書と同じようにU+301Cに本来の波ダッシュの形を割り当てた
ただ、上下反転した字形は、縦書きの際の全角チルダ(左右の順)文字を横書きにしたために紛れ込んだとも言われているので、
仕様書制定の段階で縦書きのある日本語を理解した人が加わっていなかったのだろうな
まぁ、仕様書の字形がおかしかったことがそもそもの原因ではあるけれど、
これの対応を話し合いをすることなく各社で独自に行なってしまったというのが一番大きいな
結局、日本語が軽んじられていたんだろうけど、なんとも間抜けな話
>>150 仕様書も文字の形がおかしかったはネットの素人が勝手に推測した迷信、文字形は規定していない
文字コード的にはフォントで変わる文字の形は意味がない
unicode の wave dash は JIS 第一水準の波ダージなどに対応する文字として準備された
unicode の互換領域の fullwidth tilde は EUC-JP とかで使用されいたJIS補助漢字のチルダをマッピングするために準備された
EUC-JP では ASCII の1バイト文字のチルダと補助漢字の2倍と文字のチルダに両方が使われていたので互換領域が必要だった
CP65001で緩和可能ってことであってるよね?
超ヤバげなんでageるよ
>>153 あってる
MSYS2を使ってれば2,3ヶ月前には対策の副作用があったから知ってたよ
メディアはもっとこれを大きく報じてユーザー環境にもUTF8ロケールが広まって欲しい
とうとう Windows の Best-Fit-Conversion が槍玉にあげられたか
これって多数の個別アプリの問題に矮小化されてきたけどどう考えてもOSの設計ミスにしかみえない
件のBestFit機能のせいで、
windowsバッチでフルパスが半角スペースなし全角スペースありだと、
どのようにクォーティングをしようともまともに動かなくなったわけか
システム設定でUTF8にするとメモ帳でSJISテキストファイルが文字化けする訳だけど
この特需で伸ばす代替エディタは何か?
場合によっては情シスがSJISテキストファイルリストアップツールを用意する事になりそう
UTF-8に設定すると、JaneStyleは今度こそ本当に使えなくなるんだよな
ファイル名に禁則文字を増やしても避けられないのだろうか?
これを機に932以外では文字化けするレガシーアプリは駆逐されれば良い
>>161 ファイル名の禁則レベルでは無理
Unicode の一部の文字がバックスラッシュとか空白とかクォートとかの区切り文字や特殊処理する文字に化けるので、これを利用して入力を誤魔化せるという技
どう化けるかはコードページ次第
全部のアプリがユニコード対応になるか Windows が BestFit やめない限りは多くのアプリで同様の問題が量産される(オープンソース系のアプリはこれはOSの仕様のせいでアプリのバグじゃないので直すつもりはないとか言ってる)
UTF-8だとBestFit使われないので Windows 12 とかで SJIS とか Win-1521 とか捨ててデフォルトが UTF-8 になれば解決するけど
システムをUTF-8に設定した上で、
CP932なアプリについて、個別のマニフェストの"activeCodePage"を"CP932"することで使えるようにならないんだろうか?
>>164 今のところできないし、できたとしてもその cp932 に設定したプログラムで BestFit による抜け穴が使われるリスクがある
ファイル名に英数字以外禁止したら何とかなりそうな気はした
>>166 ファイル名だけじゃないから
コマンドのオプションスイッチとか、URL とか、環境変数とか、レジストリとか、とにかくプログラムの入力全部
Windows全然詳しくないんだけど、Windows APIのANSI APIとUnicode APIとの違いって
標準Cライブラリの文字出力で言えばprintfとwprintfとの違いってことだよね?
世の中のOSSのほとんどはwprintf等のワイド文字関数なんて使っていないんだから
OSSをWindowsで動かした場合ほぼ全部WorstFitの影響を受けることになるはず
今後基本的にワイド文字関数で書くべきってなると、Hello Worldは
#include <stdio.h>
#include <locale.h>
#include <wchar.h>
int main(int argc, char **argv)
{
setlocale(LC_ALL, "");
wprintf(L"こんにちは世界\n");
}
こうすべきってこと?
あ、
int main(int argc, char **argv)
エントリーポイントの時点で引数がワイド文字じゃないから脆弱性の影響を受ける可能性があるのか
wmainがあるのはそういう理由なのね
MS的には「いまだにワイド文字列使ってないアプリが悪い」なんだよな
>>170 最近は ANSI は UTF-8 に固定しろとか言い出してる
>>160 Jane大好きマウイ君がウォームアップしてそう
ああ見えてフッ軽だから今度はflutterで作ったりしてなw
初めから文字列はUTF-8と言語仕様&標準ライブラリで決めてあるRustが楽でいいね
もちろん必要ならUTF-8以外も読み書き可
RustがWindowsでファイル名を扱う時のWTF-8、あれ脆弱性の元な気がするんだよな…
WTF-8状態でサロゲートペアの前後を結合してしまうとUTF-8のとはまた別の冗長表現が導入されてしまう
>>177 気のせいじゃない?
規格どおり実装されてればUTF-8にサロゲートなんて概念は存在しない
最短表記のみが正式なので冗長性はないよ
>>178 UTF-8では違反なサロゲートの片方だけを許すのがWTF-8なので
正常なサロゲートペアをUTF-8に変換したときの4~6バイト表現に対して
WTF-8ではペアの片割れを別々に変換して結合した3バイトのサロゲート片☓2な別表現が存在できてしまうでしょ
これらはUTF-16に戻したら同じ文字列になってしまうので
WTF-8で比較等の処理をしてUTF-16に戻すと脆弱性になっちゃう
>>179 色々間違えてる
UTF-8では片側だろうと両方だろうとサロゲート領域のコードは許されてない。あったらUTF-8じゃない
サロゲート導入前の古いUTF-8規格を参照してるアホがいるだけ
UTF-8は最大長で1文字4バイト、それ以上長いのは今のUTF-8では許されない
ましてWTF-8とか名前変えてもユニコード規格の対象外、UTF-8ではない
>>180 最初っからWTF-8って言ってるじゃん
Windowsのファイルシステムでは文字コードとしては不正なバイト列がファイル名として存在できる
それを8バイト文字列で無理やり扱うためRustではWTF-8という本来エラーになる表現も許容した規格違反UTF-8を使っている
OK?
だから WTF-8 は UTF-8 とは違う
別物なんだから混同しなければ脆弱性にはならない
Rustではファイル名をWTF-8で扱うけどWTF-8で文字列処理すると危なくね?ってそれだけの話だよ
UTF-8の話と混同して絡んできたのはあんたじゃね
WTF-8 の文字列を UTF-8 の比較関数とかで処理しようとしてもうまくいかない → 当たり前
これは脆弱性ではないし、冗長性も関係ない
ここまでは理解できてるんだよな?
WTF-8 が別規格なんだからそれ専用の処理コードが必要ってだけだろ
UTF-8ではないので混同するなって話
もう自分が何書いてるかもわかってなさそう
もう一度読んで?
横通ります
Rustではディレクトリを開いてスキャンしたら各ファイル名はWTF-8とやらのスライスなのか?
それとLinuxのファイルシステム自体もUTF-8文字コードを外れてもOKだから、Windowsに限った話ではないかと
LTF-8もあるのか?
>>188-189 型としてはOsStringとしてラップされてて、中身を取り出したらWindowsではWTF-8
不正な文字コードが入りうるのはどのOSでも同じだけどバイト列そのままな他OSと異なりWindowsだとUTF-16との変換も挟まって危なそうだなあって
(ちなmacOSやあとBSDのzfsなんかだと不正な文字コードは最初から入らないらしい?)
>>190 なるほどね納得
不正な文字コードに遭遇したら処理を進めないで即座にエラーにするが良さそう
問題は処理系がちゃんと不正な文字コードを感知するかどうかだけど、
WindowsでA系APIを使っていれば(RawワイドストリングのUTF-16解釈が試みられて)
不正なパラメータエラーとかで(ディレクトリスキャン時などの)早期に発見できそうな気がする
なんだろうな?
UTF-8: 片サロゲートも両サロゲートも不可
WTF-8: 片サロゲートのみ可、両サロゲートは不可
CESU-8: サロゲート展開必須
という区別がちゃんとついてるんだろうかという疑問、これら混ぜれば冗長だが…
単独で冗長と言われても具体性がない
勘違いしてる人がいるため正しい情報
まずRustの文字列つまりstr型とString型はvalidなUTF-8のみであることが必ず保証されている
そこには当然サロゲートもなければinvalidなUTF-8もないため問題は一切起きない
そこにWTF-8など他のものが混ざることも絶対にない
つまりどんな文字列操作をしても冗長表現のない
validなUTF-8となる安全が保証されている
つづく
次に言語とは関係ない話
validなUTF-16は必ずサロゲートがペアとして対応するが
それに対してWindowsのUTF-16パス名などあちこちの環境でinvalidなUTF-16が使われている
つまり単なる16bitコード列として任意のものが通るinvalidなUTF-16を名付けてWTF-16と呼ぶ
UTFを擬してWTFはWobbly Transformation Formatの略である
集合としてはinvalidなものを含む分だけ大きくてWTF-16⊃UTF-16となる
つづく
UTF-16⇔UTF-8は常に可逆に変換できる
前述のWTF-16に対しても同様に可逆となるものとしてWTF-8が考えられる
つまりWTF-16⇔WTF-8は常に可逆に変換できる
前述のWTF-16⊃UTF-16と同様に
WTF-8⊃UTF-8となる
このWTF-8はあくまでもWTF-16との可逆を保証するための内部表現であり外で使われることはない
つづく
このWTF-8には以下の利点がある
・WTF-16(=任意の16bit列)と可逆に1対1に変換できる
・元のWTF-16がUTF-16のみの場合は対応するWTF-8はUTF-8のみとなる
・特に元がアスキー文字のみならば対応するWTF-8は7bitアスキー文字となる
集合関係はWTF-8⊃UTF-8⊃7bitアスキー文字となる
つまり内部表現として非常に使い勝手が良いものとなっている
つづく
そしてようやく再びRustの話
Rustでは言語の外の世界とをつなぐFFI (Foreign Function Initerface)の一つとして
OS環境依存の文字列型としてOsString型とOsStr型がある
これはvalidなUTF-8文字列型であるString型とstr型にそれぞれ対応する
集合的にはOsString⊃StringとOsStr⊃strとなりinvalidなUTF-8を含む分だけ大きな集合を表す
Windows環境ではこの内部表現として前述のWTF-8が使われている
つづく
>>177 >>190 WTF-8を新たに作り出すにはvalidなUTF-8から作るか
あるいは16bit列から作るかのどちらかしか手段がない
つまり必ずWTF-16(=任意の16bit列)⇔WTF-8は1対1に対応する
したがってあなたが主張する
「別の冗長表現」は生じることはなく危険なことは絶対に起こらない
utf8とutf8を結合しても必ずutf8となるように
wtf8とwtf8を結合しても必ずwtf8だね
何を問題視しているのかな
何度も書いてるじゃないですか
サロゲートの片方だけなWTF-8同士を結合するとサロゲートペアが揃ってしまって本来あるべき形の別表現となるでしょ
その状態で比較等をすると狂いが生じる話
>>202 wtf16の1文字(16bit値)とwtf8の1文字が可逆対応だよ
それぞれ結合してN文字同士になっても可逆対応だよ
別表現なし
何を問題視しているのかな
WTF-8 どうしを結合するときは終端処理をしてサロゲートの変換をしないといけない
UTF-8 のように単純に結合することできない
両サロゲートが含まれてるものはWTF-8ではない
>>204 そうそうそれそれ。ようやく話が通じそうな人が来てくれた
で、現実には?と
>>205 片サロゲートはユニコード的には文字コードではないので片サロゲートの結合をどう処理するかは実装依存
捨てる、未定義文字に置き変える、文字だったことにしてUTF-8変換する、なんかのセパレータを挟むとかできるかもしれない
でも一般的と思われるのは結合処理自体をエラーで失敗させる
WTF-8 にも UTF-8 にも冗長性はない、WTF-8 を UTF-8 と同じように使ってはいけないだけ、両者は別物
>>204 そこで問題は生じない
WTF-8の2つの文字(列)の結合は
個別にWTF-16へ変換してからWTF-16として結合してそれをWTF-8へ変換したもの
と同等になるように処理が定義されている
つまり結合後も必ずWTF-8とWTF-16は1対1に対応する
WTF-8の2つの文字(列)をAとBとし結合を+で表すと
A + B ≡ to-WTF-8(to-WTF-16(A) + to-WTF-16(B))
が常に成り立ち1対1に可逆が保証される
別の冗長表現は生じない
>>206 一応補足しておくと、エラーなどの処理するのは結合時点でなくて、それを何か使おうとしたり、他の文字コードに変換しようとした時点とすることもできる
Invalid な WTF-8 のチェックをどの時点でするかだけの問題
>>206 OSがファイル名として扱えるバイナリ列を作れないのはむしろそちらのほうが問題になるので
失敗させるのはナシでは
>>206-207 で、今ソースを追いかけていてpushに関しては
https://stdrs.dev/nightly/x86_64-pc-windows-gnu/src/std/sys_common/wtf8.rs.html#337-359 で
>>204の処理がなされてるのを確認しました
つまりpushに関しては俺の杞憂でした(もちろん他の処理は別)
>>208 他言語のStringBuilder等ならそうだけど
OsStringには直接の比較関数等もあるので結合時点以外に選択肢は無いと思う
>>209 それは任意の16bit列に対応するWTF-8を作れるようになっているのでその場合も対応できて大丈夫
use std::os::windows::ffi::OsStringExt
OsString::from_wide(wide: &[u16])
つまりWTF-16⇔WTF-8は必ず1対1に対応するため別の冗長表現は生じず問題は起こらない
つまり話をまとめると
WTF-8の新規生成はUTF-8もしくはWTF-16(=任意の16bit列)からのみ生成できるため常にWTF-16と1対1に対応する
WTF-8の結合は個別にWTF-16にしてから結合してWTF-8に戻した処理と同等と定義されているため常にWTF-16と1対1に対応する
したがって問題が発生する箇所はない
>>212 異論というわけじゃないが、そもそもWTF-16どうしをそのまま結合して良いかというと必ずしもそうではない
WTF-16をそのまま結合して許される条件下まらWTF-8の結合を終端でサロゲートが並んだらUTF-8変換するというのは間違ってないけど
まあどっちにしろ正しく処理すれば冗長性はない
ファイル名に文字ではないゴミが含まれている → 実際に含まれているだから仕方ないOSの問題
ゴミとゴミをくっつけると文字になる → OSの問題でも文字コードの問題でもない、許すかどうかはアプリの問題
ゴミの結合をして文字になることを許すと冗長性とは別のセキュリティホールになることがある
文字のフィルターとかで文字列Aにも文字列Bにも含まれてないことを確認した文字が A+B に含まれるかもしれない
これは最近に始まったことではなくて SJIS
とか EUC-JP とかでもあった問題で、セキュリティ要件ではゴミの単純な結合は許さないのがベスト・プラクティス
いずれにせよRustの文字列処理には何ら問題なくて
WTF-8の処理にも何ら問題ないことがわかったのだから
最初の書き込みのこの人が間違っていたな
>>177 >>RustがWindowsでファイル名を扱う時のWTF-8、あれ脆弱性の元な気がするんだよな…
WTF-8で脆弱性が引き起こされないことも今回はっきりした
あとはもし何かあるとすればWindows側の問題のみ
Rustは何も解決してないのにWTF-8型で解決したかの様な振る舞い勘違いが一番質が悪い
その意味で
>>177は的を射ている
>>216は>いずれにせよ..., で誤魔化さないでまき散らした勘違いを訂正しないとな
例えば
>>195 > WTF-8⊃UTF-8となる
など
>>217 ウソはいかんよ
Rustは正しく解決している
>>177氏は冗長表現ができると勘違いしていた
冗長表現は原理的に不可能だ
そして誰もその生成プログラム例を示せなかった
WTF-8⊃UTF-8は定義から当たり前の話であるとともに
この性質によりUTF-8からWTF-8へはエラーなく常に変換できる
まあ抽象的なコードポイントの話じゃなくて、エンコーディングの話、例えば
> WTF-16(=任意の16bit列)
と言ってるから
> WTF-8⊃UTF-8となる
も8bit列を意図してるのなら、成り立たないな。
WTF-8に関しては、WTF-8(=任意の16bit列)ではなくて、
絵文字などをUTF-8エンコードした8bit列は、WTF-8では不正な8bit列となる。
訂正
WTF-8に関しては、WTF-8(=任意の8bit列)ではなくて、
>>219 >>絵文字などをUTF-8エンコードした8bit列は、WTF-8では不正な8bit列となる。
それは君が勘違いしてるよ
UTF-8エンコードした8bit列は必ず有効なWTF-8になるが正しい
反論があるならUTF-8がWTF-8とならない場合のプログラム例を出そう
>>221 それを含めた時が冗長性誕生の瞬間である
>>222 冗長表現となる事例とその生成プログラム例を出そうよ
世界中で誰も示せていないよ
WTF-8 は定義からして冗長性はない、プログラム以前の問題
WTF-8 は UTF-8 に加えて片サロゲートをUTF-8変換したものが含まれているだけ
サロゲート前半とサロゲート後半の連続も許されてない
それが混じったらWTF-8じゃない
WTF-8∋UTF-8 → ✕
WTF-8⊃UTF-8 → ○
任意の16bit列 = WTF-16 → ○ (未定義文字などを許す前提)
任意の8bit列 = WTF-8 → ✕
WTF-16 と WTF-8 は冗長性なく1対1対応 → ○
基本が分かってないやつがいるので議論が噛み合ってないだけのようだ
>>224 > 基本が分かってないやつ
ごめんごめんWTF-8の定義見て来た。
あと
>>209見て明らかな脆弱性はないと納得した。
pushでsurrogate pairになってもself.is_known_utf8 = falseにしてるんだな。
WTF-8に冗長表現は起きず脆弱性はないね
冗長が起きると書き込んでる人は、理解できずに間違った思い込みをしているのか、悔しくてデマを繰り返してるのか、わからんけどさ
冗長表現を生成する具体例を一つ示せば済むのに、ここまで来ても一つも示せていない
>>215の言うAにもBにも含まれない「文字」がA+Bに含まれるかもしれない問題、
処理の正しさの観点では(脆弱性の話は置いておいて)
NFC/NFDやIVS/IVD/ZWJ絡みで(well formed UTF-8同士の範囲でも)発生する気がするけど
実際にA+Bを作ってからチェックするのが鉄則なのか?
「文字」じゃなくて「文字列」ならA+Bを作るのが普通と思う
(それと正規表現なら部分マッチが出来たりする)
>>228 結合文字とか変種指定は機能性の問題なのでさらに一段回上のレイヤーの要件だな
「が」と「か+結合濁点」を同じとみなすか別とみなすかは目的による(文字コード的にはどちらもありえる
そんなの要件定義考慮漏れで溢れかえってる
何かあったら現状を仕様にする
ライブラリ側に問題がないとはいえ過信はよろしくない
OsStringでは機能が足りず中身を取り出しての直接処理はよくやられてるし
余計な変換をかましてるせいで考慮することが増えてしまってる一方でアプリ側にはWindowsの特殊事情なんて考慮してないコードも山ほどあろう
>>231 だから最初から WTF-8 は UTF-8 とは別物
混同したら問題、混同しなければ問題はない
UTF-8 ではサロゲート断片は許されない
WTF-8 ではサロゲートの片側だけ許されるがそのせいで追加の処理が必要
冗長性うんぬんを言い出すのはこの違いが分かってないやつという話題だろ
Windowsも対応しているRipGrepの場合、OsStringのまま処理してるけど
ユーザーアプリレベルでWTF-8は必要なのか?
(すぐにpub fn into_string(self) -> Result<String, OsString>してる気がする)
10年以上経ってv0.1.0な時点でネタライブラリでは
>>233 OsStringとWTF-8は別物だと理解できてる?
OsStringは元が正規ユニコードならUTF-8となり、異なるならUTF-8を含む拡大集合になる、という抽象的な型
たまたまWindows環境の時は内部がWTF-8になるかもしれないがそんなことを意識せずに使えるところがカギ
自分の管轄範囲を処理する多くのアプリでは元がユニコードでなければエラーとして無視できる
そのためto_string()で文字列すなわちUTF-8へ変換するがそこで実際に変換する必要がなく変換コストはゼロとなる点が実際の目的
このような特性を備えつつUTF-8にできない場合も元の情報を保つ抽象的な型がOsString
そしてWindowsの場合はその内部実装をWTF-8にすると上述の特性群を満たせるというだけの話
Rust の OsString という基準だと Linux とかだと任意のバイト列なんでそっちがもともとの形だな
たまたま Windows 版で効率考えて WTF-8 変換したものを使ってるだけ
rgは凄く効率を重視してるけどOsStringで扱うしかなくてロスが発生してる
(各ファイルを開くのにWTF-16名に戻す処理が必要)
OsStringは異なる環境で統一的に容易にStringと相互変換して扱えるための標準ライブラリ機能
些細なロスすら深刻な影響が出る用途がもし存在するのならば
特定環境に特化した専用のライブラリを用意すればよいだけ
必要な条件を満たすライブラリが既に存在しているかどうかは各自の用途で調べて
>>209 今の正しいソースはこっちな
githubcom/rust-lang/rust/blob/master/library/std/src/sys_common/wtf8.rs#L357
>>228 結果的にWTF-8でA+B問題は起きるな
>>239 WTF-8自体を自在に改変するインターフェイスが全くないため、WTF-8独自の問題は発生しない。
WTF-8はWTF-16と1対1に可逆なので、WTF-16で起こる問題は当然WTF-8でも起きる。
WTF-16とはWindows OSが許容している拡張UTF-16、すなわち本来のUTF-16とは異なる16bit列も許す。
したがって、WTF-8を用いて起こる問題は、Windows OSが許容してる範囲内の問題のみであり、新たな問題を持ち込むことはない。
>>240 なんでもOSのせいにするのは良くないぞ
Windows は片サロゲートどうしを連結することを前提にしてはいない
あくまでも連結してるのはアプリの問題
WTF-8 の連結もアプリの問題OSとは独立
>>241 もちろんその通りで
当たり前の三つの同値
WTF-8で起こりうること = WTF-16で起こりうること = Windowsで起こりうること
これだけの話だな
それを理解できずにWTF-8で新たな問題が生じると勘違いしているバカがWTF-8を批判していた
>>242 いや
WTF-8 で起こりうること = WTF-16 で起こりうることは定義上正しいけど
= Windows で起こりうること、は正しくないだろという指摘だぞ
>>243 意図的にUTF-16から逸脱したコードを生成するアプリ次第でWindows上で起こりうるから全く同じ
もし違うというならばその差分となる具体例を出してください
>>244 Linux とかでも意図的に逸脱したコード書けば起きるだろ
違うってなんら Windows 固有にコード示したら?
>>245 それも正しい
WindowsもLinuxも正しいユニコード以外を許容している
だからUTF-16やUTF-8を前提としてはいけない
そのためWTF-16やWTF-8あるいは何らか他の枠組みの導入でようやく対応できる
その時に当たり前の三つの同値
WTF-8で起こりうること = WTF-16で起こりうること = Windowsで起こりうること
この事実を理解できるかどうか
これを理解できずにWTF-8で新たな問題が生じると勘違いしているバカがWTF-8を批判していた
>>246 = Windows で起こりうることに拘るのは何でだ?
UTF-8 と WTF-8 は別物なのに同じように扱ったら問題が起きる可能性がある OS とは独立
>>247 どのOSも正しいユニコード以外を許容している
したがってUTF-8/16以外も扱えなければならない
そして非UTF-8/16があった時にそれを認識して区別して扱えなければならない
その区別ができないと既存のUTF-8/16部分にもうっかり混入させて汚染を広げてしまう
この重要性が理解できるかね?
RustではUTF-8とWTF-8(など非ユニコード)は明確に別の型となっているため安全性が保証される
両者を扱えつつ型システムにより必ず区別できる
>>248 だからOSとは独立の文字コードの扱いの問題
もっといえば文字コードを正しく扱えないアプリの問題
OSのせいにするな
>>249 どちらのOSも自由を許容している
そのため非ユニコードが混入しうる
OSは歯止めにならない
だからRustのように型で明確に区別できる言語を用いてアプリを作ればよい
非ユニコードが他へ波及することを防ぎつつ安全に扱うことができる
from_encoded_bytes_uncheckedにoverlong UTF-8をブチ込んでinto_stringしたらOk返ってきちゃった
StringまたはWTF-16から変換されること以外は無い前提でチェックは最低限にされてるみたい
unsafe contractを破った俺が悪いのはそうなんだが、これを「WTF-8文字列コンテナ型」だと思ってたらまあまあ死にそう
バイト列からの変換にcheckedな版が無いのも、一応エンコーディング未規定なんだから好き勝手なバイト列から作るもんじゃねーよバーカってことだな
同じことをLinuxでもやったらこっちはinto_stringの時点でErrが返ってくる
OsStringの内部のバッファの不変条件としても違いがあって、Windows以外では任意のバイト列でいいけど、Windowsでは常にWTF-8でなくてはならないようだ
WTF-8それ自体が脆弱性の根源になることはなくても、こうしたややこしさが誤った使い方、ひいては脆弱性を生むことはあるかもしれないとは思った
>>251 そのunsafe fn from_encoded_bytes_unchecked(byres: Vec<u8>)は安全性の対象外と明示されているね
unsafeとはC言語と同じようにプログラマーの責任で安全性を保証しなければならない
それを理解しない者や扱う技術を持たない者がunsafeを使ってはいけない
それ以前にRustは今回の件も自動的に安全性が保証されるコードを(unsafeを使わずに)書くことができる
>>252 その通り、だからunsafe contractを破った俺が悪いと書いた
しかしぶっ壊すことで得られる学びは多い
というかもうWTF-8の話じゃなくてRustの話になりつつあるしこの辺で終わっとこうぜ
続きがやりたければRust本スレで
Macの濁点半濁点問題ってUTF-8の正規化とやらの範疇に入るのかな
文字構成の解釈の仕方の問題だから正規化を実装する人の思想に強く依存してしまうと思うけど
日本人からすると濁点半濁点の違うMacうぜーとなるけど
欧州でもdiacriticsがあるから同じくMacうぜーだろうな
>>257 このスレにいるなら文字コードとエンコーディングの区別を理解しよう
UTF-8はエンコーディング方法なので
そこでの正規化は冗長表現の排除やサロゲートペアの排除を指す
一方濁点半濁点の話は文字コードであるUnicodeの正規化の話であってUTF-8は一切関係がない
>>257 Unicode の正規化は規格で決まっている
基本的に実装者の自由にやってはいけない
・複数の正規化が規定されてるのでそのうちの1つに過ぎない
・MacOSの正規化は一部規格から外れてる
という問題はある
Macの濁点半濁点問題はEBCDICのカナ(半角カタカナ)をきれいに表示する努力をした結果なのだろうか?
ファイル名は正規化するべきなのかするべきでないのか、という問題があり
Macは正規化する派
正規化するとした場合、どういう正規化がいいか、それが次の問題
日本語のフォントを外国人が作っているせいで日本語の記号の見た目がおかしくなった
>>262 Macのアップル社もGoogle社も改行コードに対しては意地悪すぎだろ
Apple の改行コードはCRだったものがMac OS X でLFになったのを意地悪と言っているのだろうか?
>>265 WindowsのCRLFをどちらも改行と見做すところ
どう考えても1つの改行なのにEメールなどでは2つの改行として送り返してくる
CR=改行(Macのみ)
CRLF=改行(WindowsやRFC)
LF=改行(Unix)
>>266 それはアプリのバグ
>>267 いろいろ間違えてるぞ
正確さが足りない
ワシの霊感では、
CR LF → LF 変換 は無理
CR LF → CR 変換 も無理
その逆、は可能、スナワチ
LF → CR LF 変換等は、可能
なんでかって❓ 霊感的には、
それが可能と仮定すれば、そのような問題は解決済
しかし未だに未解決の模様なので、
では、霊感的にではなく、数学的にはどうなのか
吟味しようかな。てか不可能が証明されても
その証明は、闇に葬る必要があるよな
by 💃🥳🤔
とにかく、アプリの改行バグなくせぇーー
by 👤🤡
RFCもいまどき入力は寛容にとは書いてないんだっけか
CRの直後にLFが現れたなら、改行2つではないとわかる。
それなのに改行2つと解釈するのは悪意でしかないり
>>260 NFD、NFC等を名乗るならそうだが最初からmodified NFD言ってるしなあ
当時は異体字セレクタなどなく、ただのNFDで字形まで変えるUnicodeの定義のほうがおかしかった
>>274 みんながみんな勝手に modified NFD とか作り始めたら互換性とか規格とか何の意味もなくなる
勝手なオレオレ基準は非難されるべき
単に古い規格準拠というだけなら許されるが Apple のはそうじゃない
そもそも正規化自体は都合に合わせて勝手にやるもんだぜ?
Windowsの.で終わるファイル名を拡張子なしと同一視するのも正規化だし
掲示板への書き込みで行頭のスペースが消えるのも正規化だ
Unicodeで定義されたやつだけが正規化ではないというのは大前提として
字形を変えない範囲で厄介な合成分解で別ファイル扱いになるのを避けたい
というのは他の文字コードからUnicodeへの過渡期では当然の要求だろう
他のOSとのやりとりでトラブルが起きるようになったのはもっと考えるべきだったとは思うが
>>276 それは違う
Apple はユニコード・コンソーシアムの設立からのメンバー
技術的に規格に問題があるののならそれを変えればいい、それをやらなければいけない立場
中核メンバーが自分たちが作った規格を勝手に無視してたら、規格の意味なんてない
この件はどう言い訳しても Apple はクソという結論にしかならない
>>277 Appleは提案したが通らなかったってどっかで見たぞ
>>278 どこで見たんだ?
技術的に変な提案したら通らないだろうが、それが規格を無視して良い理由にはならない
それを理由に脱退したんなら一理あるけど
規格があるのにそれを使わない分野なんて沢山ありそうだが
実際のところ金を出せて声がでかければ規格なんていくらでも通せるんだから
>>282 www
一部除外したら一貫性が無くなって正規化が 正規化じゃなくなるから勝手な除外は駄目って明確に指摘されてるな
なんで実装したんだろう? いやVFとか使いたくなかったんだろうけど、
どうしてもやりたければ任意の除外ではなく VF のみ除外みたいなので再提案すべきだったのでは
>>285 なるほどね
Unicodeはそのうちオーディオブック用やa11yで読み上げ音声用のVSが定義されそう
MSOfiiceでIME入力がphoneticsとして保存されてて読み仮名表示出来るのは、他に広まっても良いのにな
>>286 なるほどね
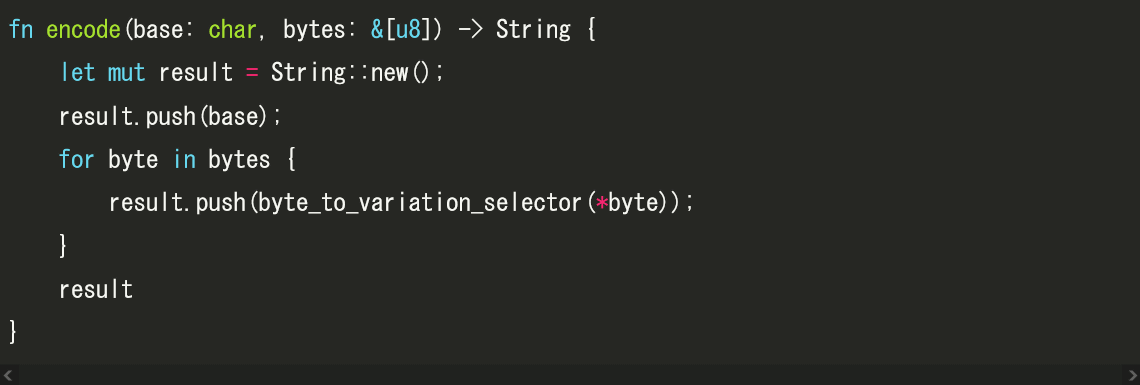
fn byte_to_variation_selector(byte: u8) -> char {
if byte < 16 {
char::from_u32(0xFE00 + byte as u32).unwrap()
} else {
char::from_u32(0xE0110 + (byte - 16) as u32).unwrap()
}
}
fn byte_to_variation_selector(byte: u8) -> Option<char> {
if byte < 16 {
char::from_u32(0xFE00 + byte as u32)
} else {
char::from_u32(0xE0110 + (byte - 16) as u32)
}
}
lud20250321161642このスレへの固定リンク: http://5chb.net/r/tech/1723861080/
ヒント:5chスレのurlに http://xxxx.5chb.net/xxxx のようにbを入れるだけでここでスレ保存、閲覧できます。
TOPへ TOPへ
全掲示板一覧 この掲示板へ 人気スレ |
Youtube 動画
>50
>100
>200
>300
>500
>1000枚
新着画像
↓「文字コード総合スレ part15 ->画像>1枚 」を見た人も見ています:
・文字コード総合スレ Part10
・文字コード総合スレ Part12
・ホロライブ総合スレ #60765どんぐりと数字コジキマグロ死ね部
・地銀カード総合スレ
・地銀カード総合スレ
・地銀カード総合スレ
・地銀カード総合スレ
・キーボード総合スレ
・マツダエチュード総合スレ
・キーボード総合スレ Part3
・声優アワード総合スレ88
・キーボード総合スレ Part6
・キーボード総合スレ Part8
・声優アワード総合スレ93
・声優アワード総合スレ79
・ANAカード総合スレ part 168
・声優アワード総合スレ53
・ビリヤード 総合スレ★18
・ビリヤード 総合スレ★13
・キーボード総合スレ Part5
・キーボード総合スレ Part10
・キーボード総合スレ Part11
・声優アワード総合スレ55
・声優アワード総合スレ65
・アンバスケード総合スレ4
・声優アワード総合スレ78
・声優アワード総合スレ86
・声優アワード総合スレ56
・デビットカード総合スレ58
・キーボード総合スレ Part7
・キーボード総合スレ Part4
・【Ford】フォード総合スレ 14
・キーボード総合スレ Part9
・ビリヤード 総合スレ★12
・ハードボイルド総合スレ Part3
・声優アワード総合スレ59
・声優アワード総合スレ60
・声優アワード総合スレ64
・声優アワード総合スレ108
・声優アワード総合スレ52
・ビリヤード 総合スレ★7
・QSLカード総合スレ その1
・声優アワード総合スレ109
・声優アワード総合スレ48
・デビットカード総合スレ55
・ナゴムレコード総合スレ Part2
・サイクリングロード総合スレ
・AGPビデオカード総合スレ Part32
・ビリヤード 総合スレ★11
・【金】有料ゴールドカード総合スレ
・【Ford】フォード総合スレ 15
・オフロード用品総合スレ 31
・中古レコード・CD 総合スレ
・ナゴムレコード総合スレ Part3
・鉄道系クレジットカード総合スレ
・ハードボイルド総合スレ Part2
・ポップンカード総合スレ 第29弾
・オフロード用品総合スレ 38
・【】モタード総合スレ その13【】
・AGPビデオカード総合スレ Part33
・中古レコード・CD 総合スレ9
・【Ford】フォード総合スレ 13
・ハードウェア総合質問スレ 28GHz
・ポップンカード総合スレ 第30弾
09:14:46 up 64 days, 10:13, 0 users, load average: 10.86, 9.32, 9.06
in 2.6300799846649 sec
@2.6300799846649@0b7 on 062022

|