◎正当な理由による書き込みの削除について: 生島英之 とみられる方へ:【StableDiffusion】画像生成AI質問スレ5【NovelAI】 YouTube動画>3本 ->画像>37枚
動画、画像抽出 ||
この掲示板へ
類似スレ
掲示板一覧 人気スレ 動画人気順
このスレへの固定リンク: http://5chb.net/r/cg/1680339324/ ヒント: http ://xxxx.5chb .net/xxxx のようにb を入れるだけでここでスレ保存、閲覧できます。
Stable Diffusionをはじめとする画像生成AIに関する質問用のスレッドです。
次スレは>980が立ててください。
テンプレは>2以降に
※前スレ
【StableDiffusion】画像生成AI質問スレ4【NovelAI】
http://2chb.net/r/cg/1678970566/ 【StableDiffusion】画像生成AI質問スレ5【NovelAI】
http://2chb.net/r/cg/1679654631/ ■AUTOMATIC1111/Stable Diffusion WebUI
https://github.com/AUTOMATIC1111/stable-diffusion-webui パソコン上だけで(ローカルで)画像を生成できるプログラムのデファクトスタンダード。実行にはパソコンにNVIDIA製のGPUが必要
導入方法 - NovelAI 5ch Wiki
https://seesaawiki.jp/nai_ch/d/%a5%ed%a1%bc%a5%ab%a5%eb%a4%ce%c6%b3%c6%fe%ca%fd%cb%a1 ■ブラウザなどで画像生成できるサービス
https://novelai.net/ 有料。アニメ、マンガ風のイラストを手軽に生成できる
https://nijijourney.com/ja/ 最初の25枚は無料。特徴は同上
https://memeplex.app/ 日本語プロンプト可。モデルはSD1.5/2.0(2.1ではない)、OpenJourneyなど限られる。学習機能を利用できるなどのサブスクあり
https://www.mage.space/ googleアカウントでログインすればSD2.1も使える。サブスクならWaifuやAnything v3なども使える。生成できる画像はSD2.1でも512x512のみ
https://lexica.art/aperture Lexica Apertureという独自モデル。生成できる画像は正方形だと640×640まで。無料で生成できる枚数は月100枚まで
https://www.stable-diffusion.click/ Waifu1.2/1.3、trinart2を使える
https://page.line.me/877ieiqs LINEから日本語で画像生成。無料だと1日2枚まで。いらすとやとコラボした「いらすとや風スタイル」を選べるのが特徴
■アプリケーションソフトのプラグイン
Photoshop
https://github.com/AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin クリスタ
https://github.com/mika-f/nekodraw blender
https://github.com/carson-katri/dream-textures Krita
https://github.com/Interpause/auto-sd-paint-ext (1111のExtensionからインストール可能)
■画像アップローダーや便利なツール
https://majinai.art/ 生成した画像内の呪文などを抽出して掲載してくれる
https://imgur.com/ 手軽にアップロードできるが画像内のメタデータは削除される。サインインすれば自分が上げた画像の一覧も見られる。複数枚アップロードして1ページで見せることも可能。1枚だけ上げたときは画像ページのURLではなく画像そのもののURLを書き込もう。例:
https://photocombine.net/cb/ 画像を結合できるWebアプリ。文字入れも可能
■関連スレ
【StableDiffusion】AI画像生成技術16【NovelAI】
http://2chb.net/r/cg/1679058984/ 【StableDiffusion】AIエロ画像情報交換16【NovelAI】
https://mercury.bbspink.com/test/read.cgi/erocg/1678056538/ なんJNVA部★168
http://2chb.net/r/liveuranus/1678402781/ ●FAQ
Q:ローカル(パソコンで生成)とGoogle Colaboratoryやpaperspaceなどのクラウド実行環境、どちらがいい?
A:ローカルは時間制限がなくエロも生成し放題だがNVIDIAのグラボが必要。クラウド実行環境はエロ画像でBANされる可能性がある
Q:ローカル環境でパソコンの性能はどのくらいがいい?
A:グラボはなるべく3060 12GBから。VRAM容量が大事。CPUの性能はほどほどでよい。本体メモリは最低限16GB。ストレージはNVMeのような早いものにするとモデルの切り換えにストレスが少ない
Q:NMKDと1111、どちらをインストールしたらいい?
A:NMKDはインストールは楽だが機能とユーザー数が少ない。1111がおすすめ
Q:画像を出力したら色が薄い、または彩度が低い
A:VAEが適用されていない可能性がある。1111なら設定(settings)-UI設定(User Interface)-クイック設定(Quicksettings list)に「, sd_vae」を追加するとVAEの切り換えが楽になる
Q:〔1111〕自分の環境で使える?
A:利用は無料なのでインストールしてみるとよい。省メモリの設定は以下を参照
https://seesaawiki.jp/nai_ch/d/%a5%ed%a1%bc%a5%ab%a5%eb%a4%cewebui-user.bat Q:〔1111〕インストール方法がわからない
A:公式の簡易インストーラ(一部の拡張機能を使うにはPythonの追加インストールが必要かもしれない)
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases 解凍→update.batを実行→run.batを実行でインストールされる。これでSD1.5の学習モデルが自動的にダウンロードされる
Q:〔1111〕起動時の縦横解像度を512以外の数値にするなど、起動時の初期値や数値の増減量を変えたい
A:1111をインストールしたフォルダにある「ui-config.json」を編集
Q:〔1111〕作りすぎたスタイルを整理したい
A:1111をインストールしたフォルダにある「styles.csv」を編集
Q:〔1111〕出力するごとに生成ボタンをクリックするのがわずらわしい
A:生成ボタンを右クリックし「Generate Forever」を選択。バッチと異なり出力中にプロンプトやパラメータを変更可能
Q:〔1111〕アニメ顔を出力したら目鼻がなんか気持ち悪い
A:「顔の修復(restore faces)」をオフにする。「顔の修復」は実写の顔の修復専用
>>4 >Q:〔1111〕出力するごとに生成ボタンをクリックするのがわずらわしい
>A:生成ボタンを右クリックし「Generate Forever」を選択。バッチと異なり出力中にプロンプトやパラメータを変更可能
これ知らなかったわありがてえええええええ、と思ってやってみたけど、変更効かないぞおい
>>6 え、効くでしょ
次に行く前にプロンプト変えて試しまくってる
>>6 プロンプト変えてる間の生成が終わったあと、次のターンから反映される
だから餅つきみたいにササッと変えるんだよw
あんた達さぁ…
>>12 そのまんまjitome、もしくはhalf-closed eyes
お好みで何らかの眉毛系の単語も追加
でも1111を使ってるならCivitaiにあるjitomeLoRAを利用するのがいいんじゃないかな
実写系lora難易度高すぎだろ
人間3人別々のポーズで並べたい時ってどういうpromptにすれば出来やすいですか?
>>16 はっきり言って、プロンプトのみでの複数人制御は成功率が極めて低く、ガチャ沼なので全くおすすめできません。
せめてimg2imgを利用するか、1111ならLatent Couple拡張機能またはControlNet拡張機能を利用しないと、あまりにもきついです。
514×514だとなんとも感じないんだけど、
少ないVRAMでcheckpoint mergerできる方法ないでしょうか。
>>20 OS再起動して、SD関連以外起動せずに実施する。
それまでに起動したいろいろでVRAM占有されてたりすることがある。
>>20 checkpoint mergerではVRAMは使用しません。使用するのはメインメモリの方です。
あらかじめModel Toolkit拡張機能を利用して、
fp16化+Pruning+CLIPの修正+Safetensors化
を施して2GBのモデルにしておくと良いでしょう。
間違っても7GBのままのモデルをマージ材料にしないように。
>>20 マージは読み込むモデル分のメインメモリの空きが必要
モデルによってサイズが違うから、2GBぐらいのモデル同士なら大丈夫なのかも
ID消してるようなのはキチガイだと前スレ最後で証明されたな
OSのスワップ設定してるとRAM少なめでもマージ出来るかもね
つまり
>>10 の質問的には全身精液まみれ派、という事か…
久々に復帰したんですが、AUTOMATIC1111のui-config.jsonって今でもテキストを手動でポチポチ編集ですか?
loraは使いやすいけど学習データに引っ張られるよな
>>27 基本的に勝手に保存されるが、設定で変更出来ない特定の項目いじりたい時は手動
>>28 本来LoRAは学習時に使ったモデルと同じモデルの対して使用するのが前提の学習法
高品質かつ条件が噛み合っているLoRAは良い結果が出ることもある
あとcivitaiは低品質なLoRAが山ほどあるから結局は自分で作ったほうがいい
二個前の板でも全く同じ状況の質問来てて回答来てなかったんで同じ質問したいんだけど、
>>29 今見たら確かにCHECKポイントやVAEとかClip skipは以前のを記憶してますね
たとえばtxt2imgの幅512、高さ512→768のSTEP20→50にして設定でUIリロードしたり、タブ閉じてUI起動したら
512、512、20に戻ってるのはやっぱ設定しないと駄目ってことですか・・最小とかも昔はテキスト編集で512にしてましたが
昔verup時にui-configがだんだん古くなって項目が減って古いのが使えなくなってエラー
そのたびに何回も編集やった記憶が蘇ってきましたよ、うう、面倒だ
なんで手動でいいから記録ボタン作らないんだろう・・
>>32 最近こういう拡張機能が出てきた
UIリロードしても設定維持してくれるよというもの
https://github.com/ilian6806/stable-diffusion-webui-state 俺は試してないから、ブラウザページ閉じた時にも効くのかは知らないけどね…
でも「↙」ボタンや、PNG infoからのSend toで大体の用は足りちゃってる
何かの時にui-config.jsonとconfig.jsonをまっさらに戻してカスタマイズし直すのは
俺も考えたくないなー…気が遠くなる思いだ…
>>33 情報ありがとう・・次入れます、今回はもうやっちゃったので
以下自分のui-config.jsonの変更点
width min 64 -> 512 デフォ512 (最小64とか意味ないだろ!512より左に突き抜ける意味が・・)
height min 64 -> 512 デフォ512 -> 768
sampling steps 20 -> 24
batch count max 100 -> 500 (たった100までか?って昔もみんな言ってました)
hires.fix・・・"txt2img/Hires. fix/value": false -> true (これ一瞬わからなかった、hiresメニュー出すやつ)
Latent -> SwinIR_4x (Swinだろ?って閉じて正式名確認でまた開かされた、ネットでもみんなSwinとしか言ってないし)
DenoisingSTR 0.7 -> 0.55
Variation STR 0 -> 0.01
これがバラバラに飛んで存在するので5分くらいかかる
img2imgは今はもういいや、前は同じようにやってましたが
海外含めみんな何とも思ってないのかなぁ
なお「Hires. fix」のチェックをデフォでONにすると
gitに慣れた人からするとui-configやconfigなんて必要な時に手動でマージすればいいだけの話だからあまり気にならないのかも
自作LoRAが拡張のAdditional Networkでしか効いてくれないのは何が原因なんだろう?
stable-diffusion-webui-images-browserを入れたんだけど
一切見てないけど
めちゃくちゃやる気に満ちたフォーク先があるのでそっちに乗り換えていこう
どうせ1日もしないうちに修正してくれるよこの人なら
https://github.com/AlUlkesh/stable-diffusion-webui-images-browser 何の話かわからんが
うまくいった呪文(1girl)で同じ設定や呪文で(2girl)にすると急に画像が荒くなるですが、
highresするときにTiled VAE使ってるんですけど、彩度が落ちてしまうのって何か設定し忘れているからでしょうか?
>>34 その設定で画像を1枚出すと画像の生成情報が画像の下のボタンの下に出るじゃろ
その3行をプロンプト入力欄に入れてスタイルに登録するんじゃ
次回はそのスタイルをメニューから選んで、クリップボードのボタン(生成ボタンの下のボタンの右から2番目)を押す
するとプロンプト入力欄にさっきの画像の生成情報が入るから、「↙」ボタンを押すと各種の設定がセットされるんじゃ
シード値だけは画像を1枚出したときのものがセットされるから、style.csvを編集しておくといいかもなのじゃ
>33もよさそうじゃが、拡張機能を入れずui-config.jsonもいじらないお手軽な方法もあるのじゃ
>34
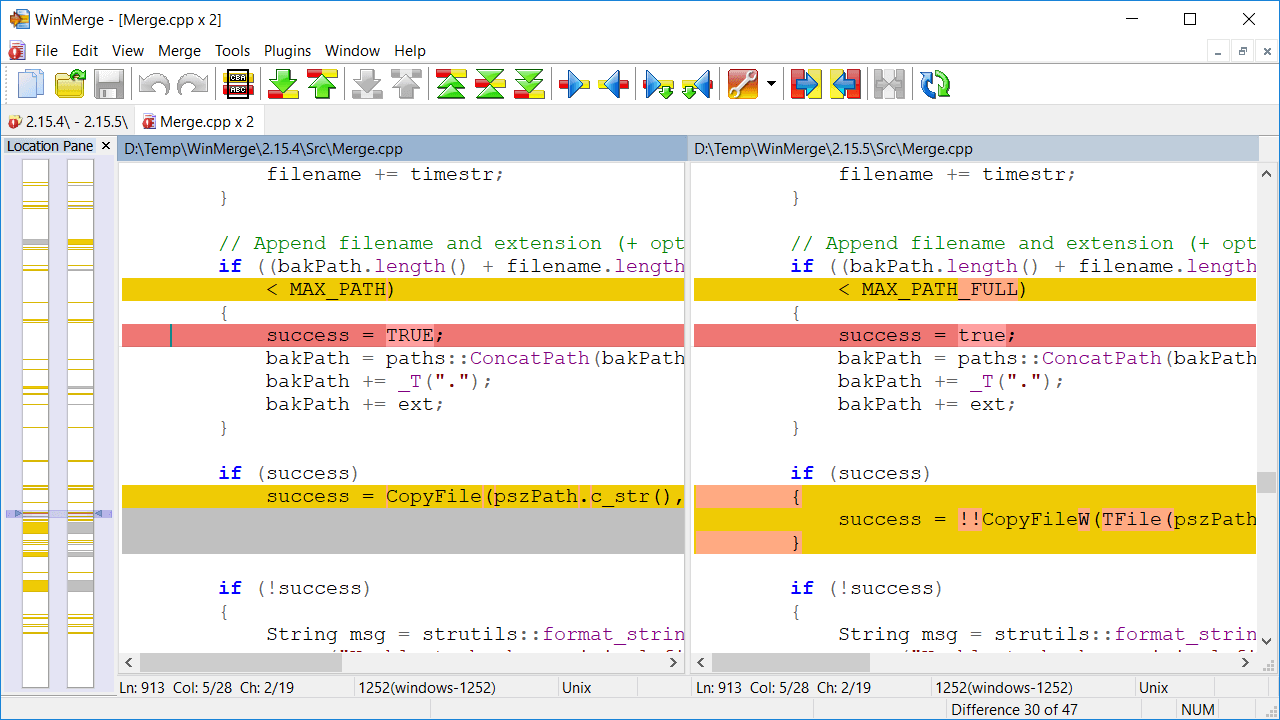
これまでのui-config.jsonと新しいui-config.jsonの違いを確認するには「WinMerge」を使うのがべんりじゃ
https://winmerge.org/?lang=ja 2つのファイルの差分を見つけて、古い内容で新しい内容を上書きする操作も行ごとにワンタッチじゃ
Danbooruって人気順でソートすること出来ますか?
>>47 おお!
通りすがりですがこんな使い方があったのね
ありがとう、さっそく活用します!
>>44 要素を増やしてるからプロンプト全体の累積強度が増している
(プロンプトは無地を強制的に捻じ曲げていると考えると分かりやすいかも)
そして、2girlsって、1girlよりももともとの強度が強いと思われる(1人分じゃなくて2人分を処理するから)
強度の乗算でAIの内部計算の閾値を超え始めると、画像が荒くなる
(PROMPT:30.0)とかのあまりにも強い乗算を行うと画像があっさり破綻するのはそのため
なので・・・
2girlsに変更済みのプロンプトの全体に対して0.7~0.95倍程度の倍率を掛けてみては?
ローカルだと、
((PROMPT:1.4):0.71)
の掛け算で「1.4*0.71=1.0」倍にするという考え方
((A:1.4),B:0.71)で、Aが1.0倍、Bが0.71倍になるはず
((A:1.4),B:0.9)で、Aが1.26倍、Bが0.9倍になるはず
嘘を言っているかもしれないが、お試しあれ
股を開いた構図なんて欲しくないのに必ず大股開きで困ってる
何そのモデル面白い
>>52 spread legをネガティブに入れてみて。
AIイラストの投稿する場合の最王手(一番見る側がいそうなところ)ってどこ? Pixiv?
>>51 アドバイスありがとうございました。
検証してみた結果、AND構文が悪さをしていた見たいです。
要素を減らしたり、全体の累積強度の調整をしても、AND構文を少しでも使っていると駄目でした。
これはLatent Coupleを使った場合でも同じでした。
やはりキャラクターの描き分けは難しいですね・・・
>>54 聞いて驚けファイルを直接弄るんだこれが
styles.csv
>>45 タイルサイズを960から下げると顕著に色薄くなる気がする
1枚数百キロバイトだから仮に1万以上画像生成しても数GB程度なんだろうけど、生成→画像削除繰り返してたらSSDor HDDの樹明消耗やばかったりする?
困っています
>>62 civやまじないの画像見てるだけで相当キャッシュ画像DLしてるから
その程度じゃ壊れない
>>63 一般的に左空けて右に人物を置く構図は多い
そういう画像を学習した結果なので仕方ないといえば仕方ない
512x512でやっているのなら、もう少し解像度大きく設定すると、さらにキャラの周囲が描かれるので見切れる確率は減らせる
>>63 こんな感じでひたすら真ん中に来るような表現探してみるといい感じ
accurately stands centering girl,
ultimate balanced left and right symmetrical
ヒット率はそこそこあると思う
>>63 Tiled DiffusionのRegional Prompt Controlで
人物の配置範囲決めてしまえばマシになるかもしれない
loraで教師データにタグをtxtファイルで置いてキャプション拡張子設定を.txtにして、これでタグは適用されていますか?
>>68 WebUIのAdditionalNetworkの拡張機能にLoRA読み込ませてみて
右下のトレーニング結果タブとか見てたら何となく分かると思う
>63
アウトペインティングで右方向に絵を追加してから、画像編集ソフトで左側をトリミングする
それか、シードリサイズで横長の画像を出力するのはどうでしょう
https://note.com/baron_marmarade/n/n5f79e1f89ffa >>47 いやもう目から鱗でした
プロンプトだけを記録するものと思い込んでました、一番左の矢印ボタンにこんな用途があったとは
>>48 さっそく入れました、昔と最新のui-config比べたら真っ黄っ黄w
これは画像生成関係なく便利なソフトですね、行内差異もチェック付けたら比較できるのでプロンプト比較にも使えそうです
今まではいちいちこういうところ使ってましたが、ローカルだけで完結できそうです
https://lab.hidetake.org/diff/ そういやこのコミュニティで紹介された絵が学習とかされたら対応するのはゴリラ氏?というかこんなのに転載許可してるってどんな神経してるんだ
http://2chb.net/r/cg/1679931186/350 プロンプトに文字を入力した時に検索候補が出るような機能があるらしいのですが、
>>75 a1111-sd-webui-tagcompleteやな
toolkit使ってBasic、 FP16で保存したんだけど、ジャンクデータが消されただけだから
lora使うと
3060のパソコンで20枚を作ると30分かかるとブログで見ましたが
質問失礼します!
>>83 face shotとか顔にフォーカスが行くプロンプトにしてもいいかも
あとよくあるやつで、下半身や足に関するプロンプト入ってない?
AIくん健気に守ろうとするから足も描いちゃうよ
>>82 生成画像の解像度次第
512x512サイズだとおよそ1枚5秒
4Kサイズを数十枚出そうとすると30分ぐらいはかかるかもしれん
>>83 いわゆるバストショットであれば、
portrait,middle shot,
それと一緒にネガティブに
fullbody,closeup,back,
そして他でも言われてるように下半身の情報は書かないで腰から上の情報だけ書く
>>82 自分は3060で
512x512なら5秒、Hiresで2倍(1024x1024)なら1枚44秒かかります
512x768なら7秒、Hiresで2倍(1024x1536)なら1枚68秒かかります
後者の2倍ならそのblog主さんに近いかもですね(20枚22分)、当然methodやSTEP数やらによりますが
ただ、いい呪文が完成するまでは拡大せずに回すと思いますが
>>81 それ、色々インストールしたせいかうちでも昨日あたりから出てるんよね
SD立ち上げ直すと直ったり直らなかったりイマイチ安定してないけど、それで誤魔化してる
質問だけど、スク水LoRAみたいな「服装」を覚えさせたいとき、教師画像はどう処理してるの?
>>90 確かに再起動で直ったわ
python使っていろいろやった意味無かったわ
lora学習をKohya LoRA Dreamboothでやってるんだけど 何のツール使ってるかによってクオリティって変わりますか?
>>82 それ RTX3060 使ってないだろうね
オンボードのやつを使ってるか CPU で作ってるか
>>91 エロスレの人に聞いたほうが早いような・・今ちょうどまさにそれやってる人がいますし
直接聞くのは気が引けるとかなら仕方ないですが
顔を白く塗りつぶしてたりすると思う
ゾンビから逃げる女性を作りたいんですがzombieのワード入れるだけで女性もゾンビになってしまうのですが良い方法ありますか?
>>91 キャプションで、sukumizu, 1girl, swiming poolとした場合に、顔だけ画像の1girlとプールだけ画像のswiming poolの正則化データを用意してやれば、
正則化データに含まれていない要素だけ、sukumizuとして学習してくれる。
>>82 他の人も言ってる通り、所要時間はGPUだけでなく、
画像サイズ・ステップ数・サンプラー等の設定によっても大きく変わります。
>>100 ありがとうございます!
やはりプロンプトだけでは難しいんですね
wild card managerが4/2にアップデートされてるんですが、このVerまともに機能しますか?
Lora用に配布されてるsafetensorsってmodelsに入れても意味無い?
>>81 それ私も遭遇しました。グラボ交換と同じ時期に起き始めたから古いドライバ削除してぎふはぶにある起動パラメータつけたら大人しくなりました。
ただ収まるまねが何か不自然な挙動だった。
rola選んだ時にno previewって表示されてどれがどういうモノか分からないんだけど、画像表示させる事って出来ない?
a boyと(penis:1.x)(big penis:1.x)を強調しても一本もペニスが出てこないのですがなぜでしょうか?エロ系のモデルを複数マージしてるので学習してないはずがないのですか
>>105 同名の画像ファイルをLoRAと同じ場所に置けばそれが表示される
同名のテキストファイルを置くと中身のテキストも表示される
画像は手で置いてもいいしCivitAI Helperのような拡張機能使ってもいいし
LoRAファイル名のちょっと上の所にreplace previewの表示が出るのでそれ押してGenerateした画像と置き換えてもいい
ただこのreplaceは手軽だがPNGメタデータを消すので残したい場合は別の方法で
>>107 >LoRAファイル名のちょっと上の所にreplace previewの表示が出るのでそれ押してGenerateした画像と置き換えてもいい
>ただこのreplaceは手軽だがPNGメタデータを消すので残したい場合は別の方法で
1週間前の1111本体アプデで修正された
https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/8944 >>106 モデルのせいなのかプロンプトのせいなのかを明確にするために、
まず他のエロ対応モデルで試してみてください。
具体的にはtreebarkとかAbyssOrangeMix2_nsfwとか。
LoRA Block Weightを導入したのですがまったく適用されません…
AUTOMATIC1111でやってるんですが
アプスケするだけならi2iのバッチでいいじゃん
>>112 (3) よさげな画像を指定フォルダに突っ込む
(4) どれでも1枚をPNG Infoに入れて「Send to i2i」(t2iではなく)
(5) img2imgのBatachタブを開く
(6) Input directory欄にさっきのフォルダのパスをコピペ
(7) Resize mode=Just resize (latent upscale) に変更する
(8) 画像サイズを希望の数値に変更する
(9) 「Generate」スタート
注意: フォルダ内の全ての画像に、同一プロンプト+ネガティブが適用されます。
今回の場合は「呪文は同じ」とのことなので問題ありませんが。
>>114 ありがとうございます!さっそくやってみますね
>>81 これ困ってた。SD再起動では治らず
OS再起動で治りました
40xxを買った場合
女性、平らな胸、下着って呪文で男の娘ができちゃう
>>117 4070tiでsd1.5使ってるけどcudnn入れないとハロアス9it/sくらいだった入れたら20it/sくらい
呪文同じなら一括img2img処理簡単だけど
>>119 トンクス
劇的に速いですね!
欲しいなぁ
40xx出た当時は自動で入るCuDNNを最新版にすると速くなった
CUDA 11.8
CUDNN 8.7
Pytorch 2.1
Xformers 0.0.18
4090でこの位だね
面白いのが、mem使用量50%超えると何故かスピードアップするんだよね
理由は知らん
>>126 WSL2 で動かしてますけどWindows ネイティブで動かすより速いですか?
>128
これでtensorRTとかTomなんとかのCFGがなんとかのやつと併用して音速超えてほしい
>>129 うおお、そこまで速いっすか
早速導入してみよう
情報あんがと
>>98 ブレンダーとハニセレで衣装作成してLoRAの学習対象には服着てる画像
正則化には全く同じ画角,ライト,ポーズで裸と背景だけの画像入れてみたけど
衣装学習する前に余計な画風(3Dシェーダー風)を学習しちゃう…
キャプションがマズイのかなぁ、画風まで覚えちゃうのは仕方ないのかなぁ
しかし正則化画像の意義がまた分からなくなったよ
最近始めてcolabでweb UI回してるのですがこの画像の様なかなりリアルな質感出すにはどうすればいいですか?chilloutでkoreandollなど入れて生成してます。
majinaiで似たような質感の画像参考にすればいいんじゃない?
anything4.5のマージモデルって今どうですか?
指先が絡まったり、6本目があったり、剣とか持たせるとちゃんと掴んでくれなかったり、そもそもどこ持ってんの?って事が多いんだけど、解決方法ってあったりする?
>>137 一部はプロンプト、ネガティブプロンプトで調整は効く
あとはDepth map library and poserっていうややトリッキーなヤツもある
sd-webui-train-toolsの導入で躓いています。
empty eyes 最高
一旦退会してまた入会した場合は追加で10ドル払わなきゃダメ?
Lora学習の際 教師画像のbuckets解像度って気にしてますか?
まあスレタイにでかくNovelAIてあるんだから何の話題と断らなくともnaiの話で当然でしょってのもある意味そう
>>141 可愛くてもただの笑顔だと満足しないの人やろ
ワイはあれから更にブチ切れ路線極めたで〜
ポーズをloraで学習させたいのだけど、正則化画像はテイストとか画質も合わせた方がいいですか?
>>149 別に俺はNovelAI使ってねーし、それが有料なのかもしらんし値段も知らねーよ
これモデルの削除ってどうやるの?
俺は普通にゴミ箱に放り投げてる
俺も普通に削除してる
もし全部投げ捨てた場合は起動しない
うんこさせようと思うんだけどどうも液状のものばかりで固形のがうまく出ない
アナルにちんこ入れようとするとうんこになる時がある
前回最後に使ったモデルを捨てると、abc順で最初のモデルを読み込んで起動する
>>153 知らないなら答えるなよ
ここは質問スレだ
わかる人間だけが質問に答えればいい
>>158 専用LoRAも専用モデルもある
複数衣装のlora作成してポーズ取らせた時に1番多い学習衣装に他衣装が引っ張られるのはマルゼン式で学習させれば良くなりますか?
GTX1660superでやったら処理が遅いだけで一応出力出来るかな
さっきまで落ちてたね、今は見れるようになった
>>161 答えさせる気のない糞質問だから言ってやってんだよ
>>163 できるよー
起動オプションに--xformers、--medvramとか-no-half-vaeをつけるとよさそう
civitaiで入手したモデルで生成する時novelAIのhypernetwork入れたままでも特に影響ない?
つかってないけど前に入れたままにしてたのを思い出したんだよな
>>168 >>170 ああ…俺も確認したら昔作った自作のHNがmodels/hypernetworksに入ったままだったよ懐かしいな
でもこれTIと違って起動時に確認されてるわけじゃないから
そのままでも何も影響しないと思うよ
容量次第ではHDDかどっかに移動させてもいいと思うけど
TIはネガティブよく使うような人以外は空にしておいた方がいいわな
majinaiにある画像のプロンプトとか設定とかまんま同じにして生成実行したら全く同じ絵が出来上がる?
>>171 なるほどTIとは違うから特に問題はないのかありがとう
俺は実際の部屋はゴミ溜めだしPCの中も整理されてないから、checkpointとかLoRAとかITに関しては注意しないといけなさそうだな…
>>173 「全く同じ絵」の定義というか程度による
--xformersを有効にしてたらちょびっとは誤差が発生するし
画像のメタデータに含まれない設定もいくつかある
具体的にはVAEと1111のCompatibilityの項目
ちょっとでもクオリティ下がるんなら嫌だなと思って時間は犠牲にしてるんだけど
web uiをchromeで使ってるとたまにバックスペースキーでブラウザバッグが起きるんだけど対策ある?
文字列を範囲選択してdeleteキーで消すのは?めんどいと思うけど
結構昔にchromeでバックスペースによるブラウザバック起きなくなってるけど環境によってはまだあるのか
毎回lora学習のために画像のテキスト出してタグ編集するのが大変なので、
git pullしようとしたら、
>>161 もうあるんだ
見つけられなかったんだけどcivitaiとかにある?
どこ探したら見つかるかヒントだけでも教えて欲しいです
>>183 git pull origin main
でもだめ?
civitai helperのサムネのプロンプトコピペを使うとそれまで入れていたプロンプトが全部消えてしまうのですが設定で変えられますか?
>>184 うんこ
糞
風船
🎈
balloon
でなんUのスレ検索してけばある
>>184 なんJ発のモデルで隠語として風船て呼ばれてる
huggingfaceでBalloonMixで検索
LoRAはcivitaiでもBalloonで検索
>>167 (>163)に追加
GTX16xxで真っ黒の画像しか出ないときは起動オプションに--precision full --no-halfもつけるといいかも
リアル系の画像を生成すると顔だけにピントが合って体がボケる事がよくあるんだけど、全身にピント合わせるプロンプトってある?
>>190 ネガティブに
depth of fieldを強めに
>>181 BooruDatasetTagManagerってのがありますね一応
画像とtxtファイル入ってるフォルダ読み込んで一括or個別に編集できるソフト
AI絵を作るのにパソコン買おうと思います
>>194 概ね良いと思うんだけど、ストレージ容量が不安だね
Windows11やモデルで結構容量を使うので、SSDは1TBほしい
それに加えてHDDを用意して、画像はそこに出力保存するのがおすすめ
>>194 どこのショップから買うのかわからないけど
アマゾンとかのよくわからん出品者ならやめておいた方が良い
LenovoやHPのゲーミングPCを見てみることをおすすめする
>>194 電源を800程度に
メモリ倍盛りの32で
m.2にアプリ入れる想定なら容量倍盛りで評判のいいヒートシンクつける
データ用SSD追加
最低限こんなもん
出来るならマザボは550
冷却ファンてんこ盛り
>>185 fatal: couldn't find remote ref mainって出て無理だった
GPT先生に聞いたら教えてくれて
git pull origin masterでアプデできたわ
ただなんか具合悪いから1111の再インスコするよ
stable diffusion本体は内臓HDDに入れてるんだけどSSDに変えたら出力速度上がったりする?
sd自体hddでやってるんだけどssdと比較してどのぐらい早いもんなの?
>>194 悪いこといわんから、SSDだけは最低1tb以上、欲を言えば2tbにするんだ
500gbなんてすーぐにカツカツになってゲームも入れたいけど…っていう状況になるのがオチ
AI絵を作るのにパソコン買う相談の続きです
2tbはあった方がいいね
>>202 メモリ64GBにして
SSDも2TB増設して
4070までもっていきたいところ
>>202 システムディスクはM.2 NVMe 1TBで、別にM.2 NVMe 1~2TBにソフト入れる
メモリは32GBで良いよ、グラボも3060 12GBで良い4000番台はまだ様子見で良い
>>202 電源は12VHPWR付の850w位にしといた方が良いかも、後々上位のグラボに替える時電源交換しなくて済む
低予算で考えてるだろうに、回答全部乗せたらくそ高くなりそう
>>202 Office: マイクロソフト Office Professional 2021 日本語版 / 永続ライセンス
↑
明らかにあやしいボリュームライセンスなんだが
どこのBTOショップ?
初パソコンならメーカー製を買った方が良いぞ
レノボの回し者じゃ無いけどまんま3060乗せたモデル出してるし
20万ぐらいで買える
延長保証つければちゃんと日本人がサポートしてくれるし
楽天のポイントサイト通せばキャンペーンやってるときは20%ポイントバックが来る
最初のでいい足りなかったら増設すればいいだけだし
sd始めてから明らかにそれまでやってたゲームとかやらなくなって暇あったらずっとsd弄ってるわ
光学ドライブ:DVDスーパーマルチドライブもいらんでしょ
DVDスーパーマルチドライブ外したごときで値段なんてそう変わらんがな
画像生成ではGPUが一番大事なのは確かだけど
>>215 マザボや電源はどのくらいの物を買えば良いんでしょうか?
>>202 SSDが1TBになったのでまずは一安心。
とはいえHDDが無しなので、生成した画像を保存する場所の容量は不安。
この機会にHDDの増設をできるようになれるといいのだが。
とはいえ画像の保存場所は、最悪、USB接続の外付けHDDでも何とかなるだろう。
Officeや光学ドライブは不要なのだが、BTOじゃないっぽいから仕方ないか。
マザボはな…安物と高級品とではまずコンデンサの質が違う。
生成してるとき4Kゲームなみに温度と電力が上がる
>>216 マザボは550 GIGA ASRock MSI ASUSあたりならどれでも
電源はブロンズでいいから850w
OSのM.2は以外のストレージは発熱少ない普通のSATAにしとけ
>>215 >>221 ところどころに安心と余裕が感じられる良いPCだ。
素直に羨ましいぜ。大切にしろよな!
こんなゴミ貯めで聞くよりパーツショップのにーちゃんと話した方が良いと思う。割りとガチで。
>>221 285Wの4070Tiに対して電源容量が大き過ぎだけど普通でしょ
>>219 電気代どのくらい増えました?
1日1000枚くらい量産すると電気代ヤバいでしょうか?
>>221 >画像出力しててなんかヤバい時のサインと対処法とかある?
VRAMの温度に注意したいけど、これは少し面倒なので…
正確さは劣るが、GPU温度に注意しよう。MSI Afterburnerをインストールして表示させるとかね。
あとAI絵においてはGPUをOCする必要が全くない。
むしろPower Limitを70%くらいに下げるのが良い。生成速度が5%程度しか落ちないからだ。
>>225 一般人がゲーミングPCでゲームを毎日稼働すると月にPCだけで電気代は1500円前後増えると言われてるから
生成=ゲームと考えたらそこまで大したことないと思う。廃人は分からん
あといまは政府の電力助成期間中だから電気代は気にしなくていいんじゃない
画像生成に必要なスペックとかはここの人たちの言ってることで正しいと思うけど、個人的にはPCを長生きさせたいならデータの保存場所はOSの入ってるドライブと分けるってのが大事って思ってる
3Dゲームを1日3〜4時間プレイすることに比べたら、
>>224 グラボの性能上がったら電源も大きくした方が良いのかなって思ってたけど買ってから調べたら4070tiって消費電力小さいんだね
でも電源は心臓って言われたから...電源無駄にデカいと電気代高くなるとかある?
>>227 なるほど使用率?の上限を抑えるってのも出来るのか
調べてやってみるありがと
画像のサイズってデフォだと512x512だと思うんだけどこれmaxの2000x2000にしたら画像出てこなくなった
ここのサイズって幾つが良いの?スペックの問題?
FHDの1920x1080くらいは普通なのかと思ったがこのサイズもエラー?で出てこなかった
てかこのサイズってのはイコール解像度なの?512ってクソ画質過ぎん?
実際出力された画像開いてもそんな低解像度には見えないけどさ(なんでだろ?)
>>231 横からだけど
そこは最大対応ワット数なんで電気代はほぼ変わんないよ
昔ちょっと増えるって聞いたけど誤差レベルだった。
今はもう差が無いとかかもしれない。
>>221 >電源無駄にデカいと電気代高くなるとかある?
ないので安心していいよ。
>>233 >>234 そっか安心したありがとー
電気代なんて殆どがお湯とエアコンが占めてると思ってたけどもしかしてPCでゲームばっかしてんのも結構電気代かかってるのか...?
>>232 画像サイズを大きな値に設定すると、より多くのVRAMが必要になる。だからグラボ次第。
でもHires.fixかimg2imgを使わない限り、いきなり1280x1280とか出しても、
人体が崩れたり分身しまくったりで、良い結果にはならない。
低解像度に見えるかどうかは、画像ビューワーとかによる。
拡大表示する際に補正処理を行って、より綺麗に見せてる画像ビューワーもあるからだ。
>>236 なるほどやはりスペック次第なのか
高画質にしたかったら別のAIに高画質化してもうのがいいのかな
VRAMって大事なんだなぁ(´・ω・`)
>>235 画像生成は電気代かかるよ・・・
例えばうちのPCの場合
ブラウジングとかYoutubeなんてほぼアイドルだから1時間20Wくらいでタダみたいなもんだけど
画像生成は1時間400W行く(震え声
24時間ぶん回して大量生成遊びをしてると・・・
400*24*30=288000
ばぶばぶあばばばばば
グーグルコラボ無料でステーブル回してる雑魚だけど
昨日まで動いてたのに今日から
RuntimeError: Detected that PyTorch and torchvision were compiled with different CUDA versions. PyTorch has CUDA Version=11.7 and torchvision has CUDA Version=11.8. Please reinstall the torchvision that matches your PyTorch install.
というerrorがでるようになってウェイブUIが立ち上がらなくなった
誰か助けて
使ってるコードとやり方は
おっさんゲームブログとかいうそこそこ有名そうなやり方を参考に自分の使いたいモデルを書き換えたやつ
これで昨日までは動いていたんだけど…脳死でコード入れてるだけの雑魚なので何のerrorかすらもわからない
有識者さんどうかお助けお願いします
!git clone
https://github.com/AUTOMATIC1111/stable-diffusion-webui %cd /content/stable-diffusion-webui
!wget
https://civitai.com/api/download/models/19084 -O /content/stable-diffusion-webui/models/Stable-diffusion/perfectWorld_v2Baked.safetensors
!wget
https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.safetensors -O /content/stable-diffusion-webui/models/VAE/vae-ft-mse-840000-ema-pruned.safetensors
!wget
https://huggingface.co/datasets/gsdf/EasyNegative/resolve/main/EasyNegative.safetensors -O /content/stable-diffusion-webui/embeddings/EasyNegative.safetensors
!python launch.py --share --xformers --enable-insecure-extension-access
>>231 電気代高くなるとかないよ。
2倍推奨なのは使用電力が電源容量の50%あたりが電源効率がほんのちょっと良いってなだけであって
果たして高い金出して容量高めの電源を買う価値があるかは疑問
俺なら750Wゴールド買うかな
>>240 1660super使ってた時も800Wの電源選んでたし心配症過ぎたか
750で足りるのかー計算出来たら良いんだろうけど次からもう少し考えてみよう
ありがとー
>>238 288000Wを1W=0.027円で計算すると7776円だってさ
ひぇ
>>239 colabのtorchのバージョンが自動的に変わったから
Xformera切ればいいとかなんとか
知識あんまり無いから聞きたいんだけど、購入5年前位
寝てる間にとか皆やってるのか
>>245 心配ならafterburner入れて設定下げて回せばいい
>>246 最初心配で寝てるのに頭は起きてる状態で6時間経ってたわ
>>247 グラボ温度は90度以上にならなければ基本的には問題無いって書いてたんだけどさ
普段は50度とか60度で生成する時に84度まで上がるんだよね
アフターバーナー調べたけどocはよくわかってないからパス
>>221 自慢キタ━(゚∀゚)━!
羨ましい
5ねんはかいかえなくてよさげ
>>248 オーバークロックでじゃなくてアンダークロックしろってことだよ
指定の温度設定になるようにクロック下げられる
あとファン回転数とかも手動で変更出来る
>>245 おれ、RTX3080に4750G
アフターバーナーいれて
70%に出力絞りシステム合計で336w程度
これで7秒に1枚くらい
>>243 コラボのバージョンが11.8になったから11.7にしろ見たいなエラーなのは何となくわかったけど
Xformeraを切る?とかいうのがさっぱりわからんわ
とりあえず返信ありがとう
あきらめるしかないのか…俺のズリねたディフュージョンおわた
>>238 パソコンで大量生成って不向きなんですね
皆さんは、目当てのイラストを生成するのに何千枚くらい生成していますか?
>>254 そもそも1日1000枚作ると電気代どうなると言われても答えようがねえっす
1枚何秒かかるかは解像度諸々の設定によるので
昔のグラボならいいけど保証期間が残ってるグラボに外部ツールでクロックの上げ下げしたら保証なくなるから注意
>>255 俺はガチャるよりも自分の所有してるエロゲやネットの画像、情報からキャラデザや構図、要素を研究して
それをLoraやDB、controlnet、LatentCoupleに落とし込めないか試行錯誤してる
奇跡の一枚より意図した一枚に重きを置くようになった。再現性を高めていきたい
>>259 俺は逆
呪文緩め { | } を活用して
1晩かけて当たりというか
ヌケる画像引くガチャのほうが楽しい
将来に向けてAIを使いこなせる能力もつけていきたいからね、GPTも含めて
>>250 もっかい調べた。アフターバーナー自体はDLしてちょこっとメーター触るだけの簡単なものなんだな。やってみるよ。
もっと難しいものだと勝手にイメージしてたわ
>>251 消費電力てどうやって調べてんの
>>223 パーツショップのにーちゃんでも画像生成aiについてはよく知らん奴多いからここで聞くのもありだぞ
そもそもグラボの消費電力はモニターするツールあるだろ
>>243 横からですがxformerの切り方教えてください
今の生成画像が実写と変わらない描写にするにはVRAM800GBと人体工学を学ばせたアルゴリズムファイルが不可欠とある
https://www.pixiv.net/users/91527524 この人みたいなアニメそっくりに生成できるモデル教えていただけませんか?
>>265 うおー
あきらめかけていたずりネタディフュージョンライフが帰って来た!
とりあえず貼ってくれたパーフェクトワールドのコードで起動できたよ
本当にありがとう!
なんでこのコードだと起動できるのかさっぱりわからんが
前使ってたのより動作も安定している気がするよ
感謝!
聞いて見るもんだな、5ch民あったけえ…
lora学習の過学習の症状って ノイズが乗る で合ってますか?
>>269 ColabはGoogleが用意した環境なので、動作に必要なパッケージが放っておくと最新版に更新されちゃうんだけど、
SDを動かす場合には必ずしも最新がいいわけではないので、「正常に動くバージョンのパッケージ」をノートの
先頭の方で指定していたりするみたいよ。
StableDiffusion起動時の画像サイズやプロンプトを設定する方法ないでしょうか?
>>272 Generateボタンの近くにある「↙」ボタンを押すと、
最後に生成した時の内容が自動的に呼び出される。
「その一手間が面倒くさい」ってんならui-config.jsonを編集することになるが…
>>266 ですがググったらxformer切り方わかりましたありがとうございます。
無事に起動もできました
自分も
>>269 さんみたいにコード分からないので、えぬの備忘録で紹介されてたやつが便利だから使ってたんですが
やっぱ今回みたいなエラー出たとき弱いですね
>>274 エラーでたらchatGPTにそのままコピペして解決するコード書いてもらえばよい
Gptが2023年に対応すればSDのあれこれも聞けるようになるな
キャラクターのLora作る時に、キャラ全体/顔のパーツ(鼻)/衣装を3つに分けて覚えさせたいんですけど、keep tokenで先頭3つを保持して、キャラの特徴をこの3つのタグに振りあてればうまく行きそうですか?
>>262 無停電電源に繋いでるから
液晶に表示されるんよ
マイニングと違って
AIは電力70%まで絞っても
生成速度10%も落ちないよう
majinaiにある画像開くとimpressionsってあるけどこれは何の値?
「Eta noise seed delta」(1111ではsampler palameters)に
ああ、乱数のseedがらみってのは当然理解してます
>>279 表示回数
てか、majinaiって日本語表示できるよ
もう一つ
>>282 検索して表示される回数ってことか
viewとは別の意味なのかなと思ってしまった
viewはクリックして詳細表示された回数かな
ありがと
最終的にLIVE2Dに使いたいです。
AIで書いたものを手直ししてそれをコントロールネットのopenposeを使って
いろいろな恰好をさせて差分を作りたいのですが、うまくいきません。
今までやったことはi2iでDenoising strengthを0.01~0.2くらいまでで書き直させて
PNG infoでseed値(一式もためした)をとってi2iにseed値いれてopenposeで
ポーズ変更差分を作ろうとしてるんだけど、うまくいかない、
Denoising strengthを0.9とかにするとうまく行くんだけど、それだとまったく別の
絵になる。
PNG infoの段階のseed値がt2iで作ったものじゃないから適当なものになっている
のが原因かなとおもうのですが、私がやりたいことをできそうな方法ご存じの方が
いらっしゃれば教えていただきたいです。
VIDEO こことか参考にしてます。
またレイヤー分けも自動でやる方法(レイヤーディバイダーはあまり使い物になりません
でした)などありましたら教えていただきたいです。
よろしくお願いします。
ポーズはデザインドールとかMagicposer使っては
初音ミク指定して何枚も生成してたら飽きたから違うキャラ指定してもミクになるんだけどなんでだ?
なんかprompt変えても以前の画像の構図を引きずってる時あるよね
>>287 勝手に学習してると思う
同じようなモデルが続くのはみんな体験してると思うよ
エロ画じゃないのにAV女優の深田なんとかに似た女が続くのも勘弁して欲しい、萎えるわ
>>286 ドールはないので、Magicposer使ってみましたが、同じでした。
やってほしいポーズの他画像をコントロールネットにいれてもおなじでした。
Denoising strengthを7とかまであげるとポーズ変わるのですが、まったく違う画像に
なります。
i2iでポーズを変える解説や動画が先ほどの参考のくらいしか見当たらず、難しい
のかなとはおもうのですが、openposeなどでもi2iに飛ばす設定とかあるのでできる
とはおもうのですが。
SEED値は結構ネックだとおもうのですが、i2iで作った画像のSEED値が意味ないのか
使い方が違うのかもさっぱりわからない状態です。
そりゃseedでしょ
>>280 NovelAIのサンプラーのシード値の設定
なのでNovelAIを完璧に再現したいわけじゃないならなんでもいい
>>283 仕様
基本的にキャラも背景もセット
もしかすると階層適用でLoRAの適用範囲を詳細に指定すれば改善出来るかもしれないが…
難易度は高い
https://seesaawiki.jp/nai_ch/d/LoRA%B3%AC%C1%D8 >>287 いわゆるバグ
>>289 勝手に学習はしない
そういうシステムではない
まず同一モデル同一promptで再現できるか?
各プロンプトの重さやパラメータをランダムに変えることってできない?
>>296 extensionにdynamic promptというのがあるので導入
使い方はぐぐればすぐ出る
>>293 バグ...なのか
再起動したら治るかな?
hiresfixのノイズ除去強度ってコントロールネット使う場合は高くしないとなかなか顔が綺麗にならないですよね?でもちょっと数値上げるだけで乳首増えたりするんですけどなんかいい方法ないですか
もうみんなLoRA学習はsd-webui-train-toolsに移行してる?
またもや質問です
高速化が期待できそうなのでpytorchを2.0.0にしてみようと
https://economylife.net/spda-pytorch2-cuda118-install/ あたりを参考に古いvenvフォルダを退避して新しい「venv」に入れたつもりなんですが
1111のwebuiの下の表示が
「torch: 1.13.1+cu117」のままでどうも更新が認識されてないようです
NovelAI 5ch Wikiでは
> 一番下に"torch: 2.0.0+cu118"と記載があれば成功
とのことで失敗してるようです
CUDAは11.8を入れて(ついでにcudnnも突っ込んでpath通し)
pip3 install torch torchvision torchaudio --index-url
https://download.pytorch.org/whl/cu118 をvenvで叩いて、「Successfully installed torch-2.0.0+cu118 torchvision-0.15.1+cu118」で完了
pip listではちゃんと「torch 2.0.0+cu118」になっています
ただ入れただけでwebuiから認識されてないような・・
何か原因考えられますでしょうか?Pythonは3.10.6です
>>268 ぱっと見た感じAnimelike_2D_Pruend_fp16を使っているんだと思う
作者が生成した画像を売るな!と言ってcivitaiから消した
今は
https://arca.live/b/aiart/72288379 からリンクしている(一番上)
QW5pbWVsaWtlXzJEX1BydWVuZF9mcDE2をbase64デコードするとファイル名が出てくるよ
sd_vaeを設定から追加したのですが、SD VAEの右側に重さの数字を設定する方法があったはずなのですが、設定のどこになりますか?
kohya ss webuiでloconはどう使うんですか?
>>304 Quicksettingsの話だろう? 君が旧環境でVAEの右側に
何を設定していたかなんて、エスパーでもなきゃわかるわけない。
「重さの数字」じゃわからん。もっとよく思い出せ。
CLIP_stop_at_last_layers,か、sd_hypernetwork_strengths,か…
後者はもう死んでextra_networks_default_multipliers,になったけどな。
>>305 学習の話じゃなくて画像生成にLoConを使いたいってことか?
もうちっとまともに質問できないのか?
https://github.com/kohya-ss/sd-webui-additional-networks このページ内を「LoCon」で検索してみたか?
controlnetの生成の発色が暗かったので調べてみたら
>>307 >>308 すみません言葉足らずでした 使用方法では無くkohya ss webuiでlocon学習のやり方が分からないと言う話です
>>289 やっぱり
何で前のプロンプトの指示が出るんだ!
と思ってたらそういうことか
sweatって書いたのになんでcum on bodyと同じ描写やねん!っていうのはある
>>311 そんなわけねーだろオカルト主張やめろ
>>293 で言われてる通りだ
PC再起動後にPNG InfoからSend toして
同一seed同一プロンプトで再現できるかどうかで検証できる
何ならメタデータ込みでmajinaiにでもアップロードしてみろ
>>309 まず、そういう質問の際はURLを貼れ。
そしてその質問は、そのブログのコメント欄に書け。
それとよく読め。その人は1111ユーザーじゃなくてDiffusers民だから、その必要があってそうしている。
1111民はCounterfeit-V2.5の配布元で公開されてるVAEを普通に利用すればいい。
でもあれリネームされてるだけで、中身は要するにアレなんだよなあ…。容量もハッシュ値もまんま。
>>314 そもそも前提から勘違いしてたのか
すいませんでした
例のあれ使っても背景暗いがしたけど設定が悪いだけだったか
>>315 VAEを指定してもなお背景が淡い色合いのモデル…という印象は俺も抱いてる。
でもそれは空気遠近法的なもので、遠くのものほど淡くなってるし、配布元のサンプル画像を見てもやはりそう思う。
ただ好みの問題はあるだろうから、もう少し彩度が強めの、他のVAEを利用してもいい。
具体的にはkl-f8-animeとか。ほんとに「お好みで」としか言いようがないけどね。
>>306 ありがとうございます!
clipのことです!
おかげで思い出せました!
垂直に脚を上げる呪文を教えて頂けるでしょうか
バレエみたいな片足上げるやつ?それとも仰向けの状態から両足上げる感じ?
足上げる系は現状txtだけじゃ難しそう
>>318 split, standing split, leg lift, leg up,とかいくつかあるので、
強調したり併用したりしながら試してください。
プロンプト内の位置にもよるので先頭近くにすると効きが良くなります。
1111ユーザーならCivitaiにあるsplitのLoRAを利用すると、安定性がより増します。
ただし画風への影響が強いLoRAなので、0.5とか0.3みたいな軽めの強度で利用することをおすすめします。
衣装再現loraは、服着てるキャラを学習元にしたときは、
>>302 報告ですが
ネットで検索して出てきたよくわからないコマンドで「torch: 1.13.1+cu117」のアンインストールが何やら成功して
下に「2.0.0+cu118」と出るようになりました
ただしVAE有効時にHires.Fixやると高確率(100%ではない謎)で真っ黒な画像が出る不具合に遭遇して格闘中です
--no-half-vae入れても真っ黒になりますが、VAEの種類によるかもしれません
どうもorangemix.vaeと相性が悪いようです
なお、速度はtorch1.13かつ--xformersと全然変わりませんでした・・
使えなくなった--xformersと相殺ですね
>>322 アドバイスありがとうございました
自分環境ではleg upが一番効果がありそうな感じでした
少しずつ強度を調整して最適なところを探してみます。
>>324 orangemix.vaeもCounterfeit-V2.5のVAEと全く同じで
>でもあれリネームされてるだけで、中身は要するにアレなんだよなあ…。容量もハッシュ値もまんま。
あと君が睨んでる通り、そのVAEは黒画像を誘発しやすい。
>>324 xformeesは生成のたびに細部に違いが出てしまうので、無しで高速化出来るならそのほうがいい
数日前に神レベルが生成出来たけどプロンプト登録し忘れたんだけど所持してる画像を使ってほぼ全く同じような画像(プロンプト登録)を抽出って出来る?
orangemix.vaeが黒画像出やすいの気のせいじゃなかったんか
>>329-330 ありがとう!編集で反転させたかもでワンチャン無理かもだけど帰ったら試してみるよ
すいません、速度ですが、torch1の頃とごちゃまぜで
set COMMANDLINE_ARGS=--opt-sdp-attention --no-half-vae --medvram --opt-split-attention
としてたのがいけなかったようです
set COMMANDLINE_ARGS=--opt-sdp-no-mem-attention --no-half-vae
で速度19%もアップかつ(3060なんで知れてますが)
VAEありでも黒もでなくなり安定してきました・・かな(またなんかの拍子におかしくなりそうで断定したくない)
「--opt-sdp-attention」は自分の環境ではあまり早くならないようです
>>326 やっぱそうなんですかw
>>327 速さと引き換えなのか、全く同じseedで結構変わるんですよね
>>333 案の定反転してたみたいだったけど無事再生成出来た!
orangemixで黒画像出るの俺だけじゃなかったんだなw
SD
どうにも自分の力量ではエラーを解決させることができないので質問させてください。
Loraの学習の実行時にこういったエラーが出て先に進めません。
解決方法を教えてください。よろしくお願いします。
>>337 構図を工夫するとかで少しは減らせる
ducth angleで斜めにして一人の占める画面面積を増やすとか、
sceneryやlandscape、cityscape等の背景を主役にする構図でキャラへの注目度を下げるとか
それでも分裂中の単細胞生物みたいのが湧いて出ることはあるが…
描画人数を完璧にコントロールするのはまだ無理やね
ファン頑張って回ってる原因わかったわ
>>339 ありがとう
なるほど構図と注目度か
「1人だけ」という考えに囚われてて目からウロコ
試してみます
Txtじゃ限界ありそう
やはり、AI生成でグラボぶん回すのは負担かかって寿命減るのかな?
>>343 マイニングみたいに酷使すればそりゃな
ひとまずafterburner入れてクロック落とせ
ていうかその前にファンの掃除ぐらいしろよ
>>338 4GBは流石にグラボがカス過ぎるんじゃないの?
微妙な差分でもいいからt2iで同じキャラを複数枚作る
>>343 4K144でAPEXやってるけどそれとAI生成してるときの電力は同じくらいだったわ
俺もコイル鳴きしてたけど、グラボを外して付けたりして共鳴しないポジション見つけたら鳴らなくったわ
>>337 横長というのはアス比だけの話です。
768x432も1920x1080も16:9という点ではですが、
AI絵の生成過程においては天地の違いがあります。
そこは質問の際に数値を具体的に言及してください。
「1girl,soloを強調」についても同様、数値を具体的に。
その上でsoloを強調するのと、ducth angleが有効なのには俺も同意します。
loraでタグ付け学習する時ってそのキャラを特徴づける衣装も全部削除
>>338 4G のGPUで学習ってそもそもできるの?
>>351 衣装着てて欲しいなら裸要素はキーワードに含めないようにしよう
裸体にも対応したいならキーワードを分けて学習データも分別するといい
裸の画像なんかないぞということなら、頭部だけのLoRA作って裸体画像たくさん生成してそれを学習データにする
>>338 雑魚扱いのRTXの8GBは最低でも拾ってこないと(金出すなら12GB以上じゃないとこの世界辛いよ)
財布がきついなら新品RTX3060-12GBが5万切ってるからそのあたりがおすすめだよ
RTX3050でスケール上げると
コラボでimg2imgを出力すると、画像二枚程度で
>>355 スケールって何だ…1111のCFG Scaleならデフォルトでも7だし
使用VRAM量には影響しないが
>>355 別スレから誘導されてきたなら○○スレから誘導されたと書くこと
スケールとはどのスケールを指しているのか
CFGスケールか、解像度のことか、他
使用してるのはAutomaticなのかNMKDなのか
『ネットで言われてること』とはどれなのか
そもそも何をしようとしたのか、何がしたいのか
具体的に書かないと無駄なやり取りが増えるだけ
【StableDiffusion】画像生成AI質問スレ4【NovelAI】 から誘導され来ました。
>>355 です
1111のアップスケールのことでした
1024x512でアップスケール2以上くらいにになると生成が止まります
試したのはwebui.batの書き換えで
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6, max_split_size_mb:128
にするとかです。
スレとかは見てなくてひたすらgoogleで検索してました。
https://imgur.com/3OA6CB1 https://imgur.com/iWdrB2A 自前Loraとpromptで好みの体型にできたんだけど
これを30枚ほど用意してLORAに学習させても何故か体型を覚えてくれないんですが
体型って無理なんですかね
Stable Diffusion XL良さそうだね
>>365 たぶんExtrasタブのResize=2ではなく、Hires.fixのUpscale by=2.0の話なんだろうけど、
質問の際には正式な機能・項目名を用いること。紛らわしくてたまらん。
1111の日本語UIですら「高解像度補助」「アップスケール倍率」って項目名になってるぞ。
--medvramや--lowvramで解決できる可能性は一応あるが、
「設定次第でどんなサイズでも出せる」わけでは決してないぞ…。限界はある。
>>368 回答どうも
--medvramや--lowvramもだめでした
情報少ないのは3050くらいの環境でやってる人が少ないからですかね
グラボかPC変更検討してみます
>>355 仮に6倍ってことは、縦6倍、横6倍で、
総画素数を36倍にするよってことなんですけど…。
>>369 情報が少ないんじゃなくて単に質問の仕方と調べ方が悪いだけじゃないかな
高解像度にしたいとして、いったいどのぐらいの解像度が欲しいのかとか
アップスケーラーだって色んな手法や方法があるのに
>>369 8GBあるんで画像サイズなら拡張無くても512x768のHiresで2倍の1024x1536あたりまではそのオプション付ければ出せるよ
6倍サイズを扱うのは4090でも実用的ではないな
自分の欲しいサイズと技術をちゃんと精査したほうがいいよ
VRAM12GB程度じゃ全く足りないことしようとしてる風に見えるぞ…
web uiでeasy prompt selectorの英語版みたいな拡張ってありませんか?
ブラウザでcivitaiを開いている時だけPCの消費電力が20~50wくらい上昇するのですが
chromiumでcivitai開くととんでもないことになりますね、なんだろう
>>374 あれ自分で編集できるんだから好きなように登録すればいいじゃないか
今日立ち上げたら複数枚&Hires. fixでは生成出来なくなってたんだけどどういう事か分かる人おる?
>>360 です。
今のところchill outを使っています。
リアル寄りなCG絵を作りたいものですが、colabだと規制対象という噂や規制に合うと言いますよね。
呪文やレシピを調べながら似たようには設定してますがなかなかうまくいかないです。
質問なのですが、画像を何枚も作っているうちに前のプロンプトに引っ張られて
RTX 4070
9万円くらい?
>>31 C:\Users\<自分のユーザ名>/.cache\huggingface\accelerate\default_config.yaml
というファイルに
downcase_fp16: 'NO'
という一文があるからそいつを削除したら多分動く。
なんで動くのかわからないし,本当にそれで正しいかもわからないけど。
いろいろな画像生成AIサービスが出てきてるけど、
colabってnsfwロリ絵を作ったらバンされる危険性ないの?
最近novelaiにcontrolnetが導入されたから構図も解消されつつあるやろ
あ、やっぱバンされるのねというか海外ならタイーホ案件でもあるっしょ
NovelAIも技術導入は進んだし立派だと思うけど従量課金だしな
>>394 構図の方は状況変わってきてんのか
あんがと
日本語化はしない方が良いと思う
お前らむちゃくそ綺麗な瞳孔表現したい時ってどんなプロンプトにしてる?
>>393 基盤はどこもnsfw禁止前提で使った方がいい。
Anything4.5やRealDosMixなどで、VAEを使っても画像が白く色あせた感じになってしまって困っています。
>>399 ultra-detailed eyes,ultra-detailed cg eyes,evil eye,でどうや?
>>399 shinning blue eye とdynamic lightingで
顔が大きいと大体目に光が入る
>>402 >>403 Ultra Detailed Evil Pupil with Shining Blue,dynamic lighting
でかなり良い感じのお目目になったわ
colabPROってユニット数が無くなったら使えなくなります?
>>406 無料版に落とされるって意味じゃ無いかな
>>401 それはVAEを使っている「つもり」なだけで、VAEを指定できていません。
あなたのそれは、モデルに内蔵されているVAEが使用されている状態特有の現象です。
SD VAEの指定がAutomaticまたはNoneになっていると思われるので、他の任意のVAEを指定してください。
>>407 少し前にcolabPRO使った時はユニット数が無くなったら使えなくなりました
最近は知らないですが
>>406 ユニット0でもまだ使えるけど、いつ接続切られるかわからん。
有料版は課金が切れると、ユニット数制限以前の従来方式に戻る
GFPGANって無意味?
>>412 2.5Dどころか気分的に2.8Dクラスでも効かないよ
ほぼ実写じゃないと効果が無いどころか、逆に崩れることもある
koreandoll japanesedollで涙袋ぷっくりさせるプロンプトとかあるんですかね??
>>413 逆に実写クラスだと効くのか
てっきりアニメ調のためのものだと思ってた
今から導入しようとしてるのですがエロ絵の生成ではなくて
>>415 実写風でやっても、崩れた顔が「滑らかな崩れ顔」になる程度でCG味が増すのでオススメはできないな
顔補正はDetection Detailerでやったほうがいいと思う
txt2imgで使うと、画像を生成した後に勝手に顔を検知して補正してくれる
>>416 >こういった人物以外が得意なモデルデータっていうものは存在するのでしょうか?
Yes。何かに特化したモデルデータ、LoRA、TI等も存在します。
LoRAやTIは、モデルと組み合わせて利用する、学習データ差分みたいなものです。ゲームにおけるDLCとか。
モデル、LoRA、TI等を探す場所はCivitaiがダントツで良いです。サムネ画像があるしね。
まあ需要の都合上、キャラLoRAが圧倒的に多いのですが…。
陰部にモザイクってai側でやってくれませんかね?
>>419 動画にも適用出来たらAV業界で重宝されそうだな
>>420 というかモザイク付AVをAIにリペイントしてもらって無修正の写実的2次エロアニメに変換出来ないかなw
すんごい初歩的な質問で申し訳ないのですがwikiのローカルの導入手順でwebui-user.batを実行するところで躓きました
イラストを実写化するのってi2iでやると思うんだけどここまで綺麗に再現できる?俺がやると構図が崩れるかどうしてもイラストくささが抜けないんだけど
>>422 「ダブルクリックでbatファイルが実行されない」
「簡易インストールのupdate.batも同様に実行できない」
この時にどんなメッセージが表示されるか、そこに問題解決の糸口がありそう。
それとwikiの「エラーが出て困ったときは?」のページが参考になるかも。
>422
モデル・LoRA・プロンプト・設定次第で可能な範疇だと思うよ
今みんながチャレンジしてる姿がみえる
i2iじゃなくて…何だっけあれ、あれ使えば
現場猫、ご飯がススム君とかを実写にして遊んだ時は大変だったけど
あ、一発で作成は多分無理。少しずつモデルも変えて変換するんや。
「Lora easy training script」で自炊Loraを作ってみています。lora自体は生成できるようになったんですが、実際に1111で使ってもほとんど機能していないように感じます。
>>423 髪の毛気持ち悪過ぎてワロタ
でも凄えなこれ
Controlnetの cannyちゃん使ったら構図なんて崩れなくないか
Batch count と Batch size について質問なんだが
>>439 どの程度「違う」と感じてる?
3〜5%程度の違いならたぶん--xformersによるゆらぎ幅。
でもサンプラーと1111のバージョンと設定によっては
100%全然違う構図とポーズになるとも聞いている。
DPM++ SDEかな? SettingsのCompatibilityに関連する設定項目がある。
>>440 使ってるのはこんな感じ
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8.5, Seed: 1864670707, Size: 480x560, Model hash: fc2511737a, Model: chilloutmix_NiPrunedFp32Fix, Clip skip: 2
画像は構図から何もかも別物
GPTに聞いたらわかったような気がした。
すげーシステム的な話のようでした。
レスありがとう。
気をつけろ
同じ画像にならんとダメなのにGPTちゃんは違って当たり前とか言い出すからな
>>435 枚数は10枚でなんとかなると思うが学習パラメータ次第でもある
繰り返し回数や学習率、dimとかalphaの値も書き出してみて
自分はそのツールを使ってないのでこの辺のパラメータがなかったらごめんだけど
lr超高めに設定してstep数めっちゃ減らして3秒で出来上がるLoRAを適用して無事崩壊するか見よう(適当)
アプデしたらモデル変更とか他の拡張機能に不具合出た(commit hash 22bcc7be…のやつ)
>>444 レスありがとうございます。
繰り返し回数5、素材画像10枚、25エポック、学習率0.0001、dim110、alpha55で、アニメイラスト系の学習を行っています。
>>194 電源が心もとない
SSDはそれの倍以上がいいよ
>>446 えづくり研究会のtwitterにあるa927fみたいなハッシュのやつを新しく入れ直しとけ
>>401 興味本位で実験
プロンプトは適当に綺麗にするなんたらかんたらからで調べてた時コピペしたヤーツ
civitaiで割と多いのが、(monochrome, grayscale:1.4)
monochromeも1.4でマシマシに、(((monochrome:1.4, grayscale:1.4)))で更に倍プッシュ
>>447 数値的には十分に見える
dimとかalphaは大きく感じるくらい 繰り返しとエポックは逆でもいいかも
あとは学習データのキャプション整理をしてるかどうかもあるんじゃないかな
インスタンスプロンプトがトリガーとして機能してないのかも
>>414 aegyo sal (エギョサル / 愛嬌肉)
>>449 ,451
サンクス。a9fed‥のやつにしたら不具合直った
最新のやつはモデルを変更しようとしたら秒数カウントが出ていつまで経っても変更出来なかった
>>452 ありがとうございます。繰り返しとエポックを入れ替えてみて、キャプションも見直してみます
AI生成されてない普通の画像からプロンプトを予測してくれるツールなんてない?
()の数増やすのと:1.xの値増やすのって効果違うの?
interrogate clipじゃなくその下にあるinterrogate DeepBooruの方だった
画面半分以上を顔面が埋める絵の
>>456 waifu1.4 taggerのconv2 v2かswin2 v2
あとdeepdanbooruとBLIP2
deepdanbooruはclip interrogaterの下にあるやつ押せばいい
wd14 taggerはExtension
BLIP2もExtensionが出てる
wd14 taggerはdanbooruの画像を中心に学習してるモデルなのでイラストで言えば多分一番制度が良い
BLIPは多分実写
deepdanbooruは、うん……
img2imgのCLIPとかdeepbooruのタグ解析について
>>457 サービスによってどの括弧を使うかが違う
サービスが違うと無視される
括弧の数を増やすのと数字を同じ値に増やすのは同じ意味らしいけど
確認したことは無い
ただし括弧を重ねると1.1ずつべき乗されるので入力がめんどいことがある
そこまでこだわる人はそこそこ稀だが
>>461 ある
CLIPはCLIP front
Deepdanbooruやwd14taggerのモデルは多分danbooru2021か2022というクソでかいデータセットをある程度間引いて学習してる(モデルカードでそう言ってる)
>>463 thxやっぱどこかに送ってるんか
でもそれってcolaboとwebui問わずなの?
webuiは基本的にlocal完結と言われてるけど外部に画像うpしてるなら罠だな
>>462 なるほど?stable diffusionは()で良いんだよね?
>>425 >>427 ありがとうございます
「& の使い方が誤っています。」webuiというエラーが出るのでwebui-user.batの中、および中で呼び出されているwebui.batの中を検索しましたが&は見つかりませんでした
このエラーに関してはパスの問題である場合があるということなのでディレクトリを移動して直接batファイルを実行
しかしPowerShellはカレントディレクトリからファイルを読み取れないので.\webui-user.batを実行しろとのサジェッション
これを実行すると再び「&の使い方〜」の堂々巡りになってしまいます
先輩方はイラストを見ただけで、大体なんのモデルを使用してるかわかったりしますか!?
もしわかったらこのイラストのモデルを教えてほしいです
一生のお願い!
WebUIではないことに100ペリカ
急にボケた抽象画みたいな画像ばかりになりました
holalaって課金しないと1日4枚しか生成出来ないらしいじゃん
>>462 式が難解すぎるんだよねぇ
一応ここに分かりやすいのがあるんだけどさ
https://dskjal.com/deeplearning/automatic1111.html#prompt hage:100 ← カッコがないと重みは無視される hage 重み1と同じ
(hage) と (hage:1.1) が同じ ※1*1.1=1.1
((hage)) と (hage:1.21) が同じ ※1*1.1*1.1=1.21
(((hage))) と (hage:1.331) が同じ ※1*1.1*1.1*1.1=1.331
で厄介なのが
((hage:1.4)) と (hage:1.54) が同じ ※1.4*1.1=1.54
(((hage:1.4))) と (hage:1.694) が同じ ※1.4*1.1*1.1=1.694
※(単語:重み)を指定すると最初のカッコが値の設定に使われて、
残りで1.1倍する謎仕様が頭がこんがらがる
こんなん分かる訳ないって
>>472 たまにある
こっちはテキストエンコーダーかVAEか何かがおかしくなった時
別のモデルを読み込んでまた元のモデル読みこみなおせばもどる
こっちは2.0とかでyamlファイルの設定をミスった時とかに
1.x向けのExtensionや設定が2.xのモデルに使われてたり、その逆だったりする時に起きた気がする
1111について言えば(hogehoge:1.x) のxの数字を調節するだけでいい
>>474 なるほど...
:で指定した方が楽だし分かりやすいか
しかし()で囲まないと意味ないのか昨日囲まずに数値上げて変わらんなー言ってたわ
ありがとー
>>477 ワイもよくやる。あれ?なんで?ってなる。
grayscaleとか色の濃さに関係するのは分かりやすかったんで
それで確かみてみた。お陰で少しすっきりしたよ
[zentangle background :({1girl sitting chair, :3, (pastel\(medium\):1.2)}) :10], [:masterpiece:10],
[::整数]で書くヤツは頭おかしい。少数にしろボケカス。
>>480 色移り対策とかだと1ステップ単位で厳密に指定するんだが?
>>300 >sd-webui-train-tools
これ入れてみたけど延々ロード中で一向に始まらない
最新版には対応してないってこと?
[red:blue]hair と
>>477 手入力する必要はない
目的のタグを選択し、左コントロールキーを押したまま矢印キー↑↓で簡単に入力できる
ていうかたいして知らんのに質問に答えるヤツらは何考えてん
>>460 wd14 tagger使ってみたけどまあまあ使えそう
教えてくれてありがとう
>>481 ごめん。罵倒しておいてアレだけど自分も微調整は整数指定しちゃう。
>>484 それさっきのURLで見て目から鱗だわありがと
>>401 と少し関係するけど最近ネガティブプロンプトにmonochromeを入れてるのを見かける
確かにこれをEasyNegativeと一緒に入れると更に色鮮やかになる
色が薄くねと思ったら入れてみては
>>401 setting→User interface→Quicksettings listの中にあるcheckpointの横に「, sd_vae」を加えて
モデル選択の横からVAEを手動適用できるようにしていろいろ入れ替えて試してみれば
>>485 >多重カッコ強調は旧式の方法で今は使われん
質問に答えてる訳じゃないし雑談のつもりだったんだがな
ソースがあるなら教えて頂けると幸いです
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features wikiには
"a (((farm))), daytime" は "a farm daytime" が同じになるとは書いてある
また
a ((word)) - increase attention to word by a factor of 1.21 (= 1.1 * 1.1)
とあり多重カッコを使うなとは書いてないので該当箇所が分からないです
>>485 今多重カッコ使えなかったの知らんかった
あんな見難い記述未だにやってるアホはもうおらんだろうけど
過去プロンプト使えなくするとは勇気あるな。
というか、そんな調整するなら正式コメントアウトはよ。
((()))方式は今は昔とは聞いたな確かに
>>491 あった
https://github.com/AUTOMATIC1111/stable-diffusion-webui/blob/master/modules/shared.py#L337 use_old_emphasis_implementationがその古いやつを使うかどうかのフラグなんだけど
初期値がfalseで立ってるっぽい
多分これがそのままの値でconfig_ui.jsonみたいなファイルが自動生成されるんだと思う
1111のsettingでImages filename patternにclip skip数を組み込む場合、なんというタグを使えば良いのでしょうか?
>>494 ありがとー。1週間くらい前に入れなおしたばっかでコンフィグも引き継いでないのに
旧が有効なままって事かな? 解せぬ
>>491 >>494 そう、その設定がsettingのcompatibilityにある
config.json覗いてみたら"use_old_emphasis_implementation": falseのままだな
trueだと旧型式有効でfalseで無効だよね?
>>495 自己責任でお願いだけどどうぞ
これやったらこの先必ず起こる事として
git pullした時に
webui/なんたらかんたら/images.py
が原因でgit pull出来ませーんwwwwww
みたいなのが起きると思うんだけど
git checkout webui/なんたらかんたら/images.py
で治るのでやる場合はこれごとわかりやすいところにメモしておいて欲しい
いまいち仕組みがまだよくわからないんだけど、これって同じ条件で同じprompt入れたら時間やパソコンが違くても同じイラストって出るの?
グラボとかドライバー周り依存で変わるらしいけど
多重括弧強調((()))は今でもデフォルト設定のままで利用可能。
ただし利用する人は少数派ではある。単純に数値指定やCtrl+↑↓の方が利便性が高いからだ。
>>508 良い検証だけど
use_old_emphasis_implementationは?
そこ大事
>On 2022-09-29, a new implementation was added that supports escape characters and numerical weights.
>>509 俺は自分が知ってることしか回答しないよ
自分で検証してくれ
>>485 >ていうかたいして知らんのに質問に答えるヤツらは何考えてん
>そもそもAutomaticでの多重カッコ強調は旧式の方法で今は使われん
>それを使うためには設定を旧式変更する必要がある
みんな聞いたな?
皆さんに質問なのですが、生成された画像からメタデータを削除しJPEG等に変換した場合、その画像から使用モデルを判別することはできますか?
RGBの値いじって何かしら情報を埋め込まない限りは出来ないんじゃないかなあ
>>511 検証になってねええええええゴミクソ低能じゃねーか
511のゴミカスが役に立たないから試したぞ。
"use_old_emphasis_implementation": false
多重カッコ().(()),((()))
どれも効く!以上!
ドヤ顔で恥ずかしい間違いした485より511みたいなカスが一番腹立つ
use oldなんたらが分からんから
>>511 が叩かれる理由がわからんちん
結果一緒やし
>>518 "use_old_emphasis_implementation": false
で今はデフォで古い記述が無効になってる。
それが多重カッコを含むかどうかはソースが無かったんで検証大事。そこ有能。
でも
「デフォルトで使える!設定は知らん。」
とかおま環すぎてなんの役にもたたん。クソゴミノイズ。
>>519 古い環境使ってる方がおま環なんじゃないのか
よう分からん
口が悪い小学生なのはその通りなんで何も言えない。
>>521 そうそう。その通り。
ここ最近のバージョンで環境構築したヤツで試したって補足するだけで完璧
なのに511みたいに手間かけさせようとするヤツ大嫌い
あっ大丈夫です。嫁からもっときつい罵倒が、日常的に飛んで来てるので慣れてます。
>>522 今でも って言ってるし現行バージョンでの環境使ってると読み取ったがなるほどこういう世界はもう少し明確に記載するのがベストなのかな
電気代って1時間でどのくらい増えますか?
生成してる時としてない時の消費電力で計算したらええんちゃうの
>>525 わいだと340ー350wと表示されとるね
340w/1000*24h*\27yen=220.32円/1日
今は政府の電力支援があるからもう少し安いだろう
デスヨネー
両手を合わせた祈りのポーズ出すとほぼ指がぐちゃるんですけどやっぱりきれいに出すのは厳しいですかね?
>>532 Depth map library使ってみたら
>>533 これ素晴らしいんだけどバリエーション少ないのどうにかなんないかな
オッケーサインやハートマークみたいな複雑な形状も作りたいわ
まだsd始めて1週間経たないのにここ見てるだけで新機能紹介してくれるからめちゃありがたい
>>535 公式に「extensions/sd-webui-depth-lib/maps/<category>」に独自の手を入れろって書いてあるし
フォルダーの中みると手の画像があるから自分で書いてここに於けばバリエーションできるんじゃ?
sd webui train toolsをインストールしてもタブに表示されなくて、思い当たる原因として昔にsd webuiの入ったフォルダーをまるごとcドライブから別のドライブにまるごと移したことがあるんだけどこれのせいだったりします?webuiのバージョンは最新です
AI繋がりで思い出したんだけど、
Colab版だとプロンプト入力画面でアルファベットを入力するとその頭文字のプロンプトを予測変換してくれたんですが、ローカルだとでません
チビタイのr18サムネを一々クリックしないで常に表示させる方法ありませんか?
この8年前の650w中古パソコンに、同じ型の1000w電源を中古2000円で買って
http://faq.epsondirect.co.jp/faq/edc/app/servlet/qadoc?26493 3060が快適に動いてたんで、中古で3090を買って刺してみたんですけど、
画像生成するとシャットダウンしてしまいます。
全般動作も遅くなって変な感じです。
afterburnerで50%にしたら1枚だけ生成出来ましたが落ちます。
古い+全部中古なのでどれが悪いのか分からないんですが、電源でしょうか?
8ピンx2で理論上足りてるとは思うのですがちゃんと供給されてるかは分からず。
8ピンは5本ありますが、どれ刺しても良いんでしょうか
電源ユニットって実は磁気ディスクハードドライブより寿命短いからな、意外に思うかもしれないけど
>>548 cpu8ピンはcpuって書かれてるはず
グラボ用の8ピンは6+2に分かれてたと思う
電源の中古とか論外でしょ
depth libにオリジナルの手を追加するときってどういうやり方が効率的だろう?
lora学習用に画像から顔だけ検出してトリミングする方法探してます
>>548 本当に1000Wなんか?
850W使ってたが3070→4080→4090で普通に動いてた600Wいっても大丈夫だった
CPUは100Wくらい消費なので低目
ケーブルがかさばるのが嫌だったからATX3.0の1200W買ってしまったが動作変わらずだ
どのモデルもフトモモがムチムチになっちゃうのなんとかならないの?
ワンタッチのAutomatic1111でやってるけどxformers動かん
>>549-552 >>555 レスどうもです
書き方悪かったですが6+2ピンx2でした
やっぱ電源が怪しいですかね
パワーリミットで80%以下にして、650w電源で使ってみます
>>556 スカートはかせると足の太さが更に大きくなるよね
>>360 ロリやりたいなら自分で調べろ
それも出来ないやつはどうせクラウド流出とかして死ぬ
初事例になって人生終わらしたいのか
>>555 なにそのブルジョア
石油でも掘り当てたのか?
11111なんですがLoraってどこからインストールすればよいのでしょうか?
>>562 civitaiとかからダウンロードして「stable-diffusion-webui\models\Lora」フォルダに入れる
>>548 タコ足配線してるとコンセントからの電圧下がるので可能なら本体だけ直刺しがいい
モニタとかはタコ足しても関係ない
あと一般家庭の配線は何系統かあるらしくて(2~3系統?)別の部屋で
電気食うものと同じ系統を引くとやっぱ電圧が下がる
コンセントが2か所4口くらいあるなら幾つか入れ替えてみるとケロっと直る事もあるかも知れない
中古で傷んでる電源と言っても容量の目減りは7~8割くらいらしいから
700~800Wくらいは耐える筈なんだけどな
昔無停電電源装置入れてたけどコンセントの電圧からPCの消費電力がモニタリング出来て
電圧下がったら勝手にバッテリーから補ってくれるので、昇圧装置が手に入らない時の代替になるよ
2000円の電源だとジャンク品扱いでしょ
>>564 なるほど、タコ足まで考えてませんでした
冷蔵庫とか一緒に刺さってたので変えときます
ひとまず650wに戻して70%に押さえてみたけど
3060の倍ぐらいit/s出たので、やっぱ電源ですね
まあ明らかにホコリだらけでポンコツだし・・
金ないんでしばらくは650wで祈りながら使います
さらっと見てみたらEPSONってDellとか富士通みたいなマザボが特殊なOEMタイプで
ATX電源使えない系のカスタム電源なんね
他に全く流用効かない専用品だと激安バーゲンセールにもなるカモヨー
>>566 おうふ。何か使える電源見つかるといいですね
>>567 ありがとうございます
というか3090以外がポンコツすぎますね
元々3060セットで8万だったので・・早めにグラボ以外を買い揃えます
一時期Dell安かったから考えたんだけど、電源の型番調べて
>>283 の件ですが、
>>293 さんの
>もしかすると階層適用でLoRAの適用範囲を詳細に指定すれば改善出来るかもしれないが…
これで行けました!そのwikiでのNPってのをキャラのLoraに適用するだけでした
セルルックキャラにめっちゃ美麗背景が引き構図でほぼ違和感なく完璧に出て涙出ます、ありがとうございました
INやOUTって単語とか細かい意味は分かってない上、自分で重み調査したりは難しくてできませんが
そんなギャンブルしなくても
メーカー製のOEMマザーはコネクタがATXじゃない専用品が使われてる事があってね
スマン、読み違えてた
マウスとかは市販パーツと変わらないのでマザー&電源が変態って事はないみたい
質問です
ノートでcivitaiのデータ落としてフォルダー共有しとけば?
>>575 3060ですが全然そんなことないですよ
もしかしてcivitai見てるとかでは?
>>375 あのサイトは試行錯誤中っぽくてなんか色々問題あるような
自分はfirefoxで問題ないです
メインメモリ不足で遅くなるなら分かるけど
多分GPU関係ないと思う
>>401 です。
生成される画像が白っぽく、色褪せたようになると書き込んだ者です。
説明不足でした。
SettingでのVAE指定はすでにやっています。
それでも白っぽく色褪せたようになってしまうので、解決策が見つからずここに来てみた次第です。
他に何か原因は考えられないでしょうか?
>>575 生成中にCPUの使用量見て余裕があるようだったら
ChromeのHWレンダリング切ってしまうとかは?
「設定」-「システム」-「ハードウェア アクセラレーションが使用可能な場合は使用する」
>>578 civitaiは閲覧するだけでGPU使用率エグイ使うで
やってみ
>>580 loraに引っ張られて画質落ちたり色調が変わった事があったような
一杯つけてるなら1つづつ<lora:0>にするとかでアタリは付けられるんじゃないかな?
>>580 設定でVAEを選んでるけど設定の適用をしてないってレスあったけどホントにapplyした?
ロリ画像ってAIでもあかんの?なんかそういうのよく分かんないんだけど、てかロリって何歳以下がとか定義あんの?
>>543 それそれ!やっぱり別物だったか笑
情報ありがとう!
>>545 久しぶりにサイト行ったら、おわり ってなってて選択すらできなかったわ。
>>554 deepfake関連で調べれば見つかるかも
大体輪郭は含まれなさそうだけど
取り敢えずパソコン買うところから考えてるんだが
>>554 GIMPっていうフリーソフトにファジー選択って機能がある
使い方のサイトをよく読んで使えば切り抜きは出来ると思う
ただそこまでしなくても証明写真みたいに顔だけの画像(背景があってもOK)でも学習できる
>>590 コスパで考えたら3060の12GBが圧倒的だし向いてるね
>>580 SettingsのUser InterfaceのQuicksettings list内を
sd_model_checkpointをsd_model_checkpoint,sd_vaeにした上でApply settingsしてUIをリロードしたら
txt2imgとかの上にSD VAEのコンボボックスが出てますか?
で、それをNoneと使いたいVAEで切り替えたときにCUI窓で英語で切り替えましたよみたいなメッセージ出てますか?
>>499 どうもです、直接リファレンス見たほうが早かったですね…
自分の用途では結構重要なパラなんですが、現状ないのは残念です
>>589 ,591
レスありがとう自分で調べてなんとかなった
pythonとかopenCVとか色々難しすぎて死にそうになったけど
1111のgitとかも初めて触ったけどみんなプログラムとか当たり前のようにできるの?
>>540 ダウングレードしようとしてもそのハッシュのバージョンがgit logに出てこないのですがどうすればいいですか
>>540 そのリンクから飛んでそのバージョン見つけろってことですねクソゴミカス脳みそでごめんなさい
>>596 ここにいるほとんどの人がプログラムのプも知らない人たち
理解してる人はほとんどこのスレから去ってるし
ここはビギナーがビギナーを教える場所
ControlNetでラフ→線画→着色する方法、もっと簡単なわかりやすいサイトとかないですか?
>>540 できましたありがとう!ここからタグ付けだの学習強度だのの沼が始まるのか
>>600 最初に線画で出力して、それを更にControlNETで使いたいってこと?
それならAnime LineartってLoRA使えば大丈夫だと思うけど
それともControlNETのPreprocessorに「canny」、モデルに「control_canny-fp16」を指定する方法のことだろうか
エロさのない普通の絵を出力したいのに、やたらエロ目なのが出て困ってます。
質問させていただきます。
>>605 念のため確認したいことがあります。使用しているモデルのハッシュ値を教えてください。
1111のブラウザページの一番下に「checkpoint: ○○○○」と表示されているので、それをコピペして教えてください。
あ、ごめんアンカー間違った。
>>606 は
>>604 宛ての内容です。
>>604 モデルによってはエロいのを別の関係ないワードに絡めてるのもあるからなぁ…まあ、意図的じゃ無いんだろうがそう学習しちゃったんだろw
>>604 >スカートもごく普通のにしたいのですが、ほぼ全てエロエロな超ミニになります。
これはプロンプトのスペルミスが多少影響していると思います。
× long sukirt,
○ long skirt,
>>604 モデルを
abyssOrangeMix2じゃなくて
abyssOrangeMix2_sfwに変えてみたらどう?
あと、詳しくないけど例のwikiには
> anything v4 (公開日: 2023/1/12)
> 二次元・綺麗絵に特化したモデル。エロ方面は苦手。
> v4に上がってるので多分すごい。知らんけど。
> v4.5はv3とv4の中間みたいな絵柄が出る気がする。
> anything v3 (公開日: 2022/11/8)
> エロ方面を捨てた代わりに二次元・綺麗絵に特化したモデル。
ってありますね
出てくれない!ってのは
>>604 さんには結構いいのでは
>>613 おーありがとー
家帰ったら試してみるわー
ありがとー
>>611 俺はそのwikiの編集もしてるし、その箇所の文言も一部書いてる
トップページの赤字内容をよく読め
転載は二度としないでくれ
みなさん、ありがとうございます。
モデルがエロ方面で学習してしまってるんですかね。
モデルを変えればよいのですね。
一応AOM3や7thanime v1.1も試したのですがあまり変わりませんでした。
abyssOrangeMix2_sfwを試してみます。
>>606 ,607
ハッシュ値は以下でした。
0873291ac5
>>611 なるほど、最初からエロじゃないという特徴のモデルもあるのなら、それはよさそうですね。
>>609 あ、お恥ずかしい。ありがとうございます。
>>616 ハッシュ値の回答ありがとう。値に基づくとそれは5.57GBのAbyssOrangeMix2_nsfw.safetensorsだね。
https://huggingface.co/WarriorMama777/OrangeMixs/blob/main/Models/AbyssOrangeMix2/AbyssOrangeMix2_nsfw.safetensors NSFW用のモデルだから、エロが得意な反面、頼んでなくてもエロ要素が出てしまいやすい、という特徴もある。
SFW用モデルやanything系列を試してみるのが良いと俺も思うよ。
colabでやってるんですがopenposeが生成画像に反映されません
>>618 >NSFW用のモデルだから
あ、そうだったのですね。
なるほど、それはすごい納得です。
ありがとうございます。
画像生成した後にその生成された画像のシード値って見る方法無いですか?
anything v4 にして、プロンプトでロングスカートをかなり強調したら、エロくなくなりました。
opne poseの美味しいポーズjsonをまとめてDLできる所ありますか?
>>621 1111ならデフォでファイル名になってませんか?
あと画像をPNG Infoに突っ込んでSend toしたら勝手に入れてくれます
>>602 あまりURL貼るのもあれだと思うんですがラフから線画にするのを説明してるサイトがここしかなかったので…
https://kurokumasoft.com/2023/03/10/colorize-drawings-with-controlnet/ ラフ(荒い線画)→線画(清書済み)→塗り
みたいな感じで使いたかったんです、普通に絵描く感じの流れで
scribbleで清書する方法が全く上手く動作しないので困ってます。
LoRAっていうのはよくわかんないので少し調べて使ってみようと思います。
wildcardってXYplotのようなもので掛け算して出た分の絵が出てくるの?
>>623 anythingも別に非エロじゃないよ
ちょっと苦手なだけ
>>626 あーファイル名ってシード値だったのか...
ありがとうございます
>>628 25にしたら全部でるかわからないけど
これチェックしたら一枚にしてても全通り出るはず
やっぱり説明サイト通りやってみてるんですがうまくいきません・・・・
Anime LineartっていうLoRAも使ってみましたが、その場合は白黒にはなるんですが相変わらず灰色になります。
インストール時にエラーが起きて、調べたらwikiにupdate.batをしてから~って書いてあったので、それをしたせいでアップデートで不具合が出てるんでしょうか?
設定はこんな感じです(殆ど初期設定の状態、解説サイト通りの設定)
やっぱりアニメのキャラクターを出力しようとすると、輪郭線が強めになるものなのでしょうか?
>>628 その例で言う所だと{__hair__}{__color__}の記述で
>>631 じゃなかったかな
その上でdynamic prompt内の1つ目の項目が
0=全組み合わせ(5*5=25枚)
1=ランダム組み合わせ1枚
2=ランダム組み合わせ2枚
・・・
25=ランダム25枚
2つ目の項目がそれを何周(上25でコレが2→25*2)
これが大元のbatch countの1周分だったと思う
>>635 追記、dynamic prompt使わない__hair__ __color__だと都度選出だから
バッチカウントが2でも被る時は被る
SSD Cドライブにstable diffusionをインストールしたのですが生成した画像をハードディスクDドライブに変更することって出来ますか?
stable diffusionの保存場所を変えたんですけど切り取りペーストするだけで大丈夫?
>>633 面白そうなので、全く同じ設定で
ちょいちょい色もありますし、背景もグレー化しますが
真ん中とかいい感じです
しかしこのやり方凄いですね
試しに自分の絵でやったら、こんなの一生描けないってのがいくらでも出てきました
>>640 ディスクに余裕があるなら切り取らずに丸ごと新しくコピーして、元のフォルダの名前を変なのに変えて
新しいやつで動くか試したらいいんじゃないですか?駄目なら消して変えたのを元に戻せば元通り
>>641 真ん中のように殆ど白っぽい背景にどうしてもならないです。
インストールが失敗して不具合出てるっぽいので、インストールからやり直してみます
>>632 自分で塗る場合、薄いグレーを気にしてガチャ回すより普通にお絵かきソフトで線画抽出した方が早い
cannyで生成させる場合、線画抽出されるのだから薄いグレーは無視していい
>>644 ああ、自分もVAEをNONEにしたら確かに軒並みグレーです
AOM3+orangeのvaeでたまたま上手くいってるのかも
Civitaiにあるようなオリジナルモデルを作ってる人いる?
>>647 civitaiにあるのはほぼ9割ぐらいは単なるマージモデル
もしくは既存のモデルに簡単な追加学習を施しただけのもの
LoRAはそもそも元のモデルありきのシステムなので、どのモデルでも同じように出来るLoRAというのは事実上不可能
現状、出したい画風やキャラによってモデルも使い分けるしかない
ちまちま画像掃除するくらいならゴミモデル消せよと思うわ
メインは2次元調(2.5D)なんだけど質感はリアル(ツヤツヤテカテカヌレヌレ)みたいなモデルって何がおすすめですか?
なんかstable diffusionのバージョンが1.xと最新の2.1?があって、2.1はLoraが使えないけどRTX40シリーズのcuDNNを最新にバージョンアップすると高速化すると動画手を齧ったんだけど、みんなどんな環境でやってる?
モデルを使いまわせないせいで、みんな1で足踏みしてるの草
実写系です
>>651 SDのバージョンてのはあくまでもモデルのバージョンのことで、2.1系はエロもないしほぼ使われてない
みんなも、そして君も使っているのはほぼ1.5系のモデルだと思う
>>651 Stable Diffusionの公式モデルには1.x(最新は1.5)と2.x(最新は2.1)があります
1.5は512×512で学習していて、2.1は768×768で学習しています
2.1はバージョンが新しいからいいというわけでもなく、ベース解像度が768×768であるため512×512が前提の多くのembeddingsやLoRAが使えません
ベース解像度が低い1.5でも今はアップスケールのノウハウが多くあるので不利ではないと感じます
>>650 AOM3でrealistic,shinyskinを強調して入れるだけでもだいぶ変わる
>654
3060のグラボ値下げすると思いますか?
LORAの有効範囲を顔、髪だけに限定する事はできないでしょうか?
>>654 アップスケールしたときに顔が似たり寄ったりになるってのは
実写っぽいのじゃないときにはすごい感じてたわ
>>658 たまたまじゃなく高解像度になると低解像度時にあった顔の多様性が収斂しちゃう
non-latentでノイズ除去強度を下げるのは元絵に単純にupscaleかけてるようなもんなので意味ないかなー
>>661 アニメ系でも同じ傾向あるんだ
自分はアニメやらんので知らんかった
>>654 について考えられる仮説としては
低解像度の素材は低容量な故にmodelの中に大量の材料があるので多様性があるが
高解像度の素材になればなるほど数が減る→学習データの多様性が減る→収斂しがち
みたいな感じかなと思ってるんだけどどうだろう
>>587 18未満は児ポの対象
高校生も含まれる
リアル系は写真を学習しているので販売や一般公開はしないほうがいい
ローカルで作成して自分で楽しむ分には多分大丈夫
>>640 フォルダー移動すると拡張機能を追加するときにエラー出てくる可能性があるからできるだけ移動させないほうがいい
俺はそれで再インストールした
>>659 3060 12GBは在庫限りで8GBにシフトしてくから上がると思う
3000番のグラボはもう枯渇気味ってどっかで見たから
>>648 最初pastelモデル見た時わりと感動したんよね
そうするとmimicは需要あるなあ
数枚しか画像を用意できないマイナーな二次元キャラのLora作成で
>>664 なるほど、リアル系はダメな感じなんだ
2.5次元みたいなのはセーフなんよね?pixivとかでよく見る
civitaiのchilloutmixとかfp16よりfp32の方が需要があるっぽい(サンプル数が多い)のはなんでなん?
>>667 新しく1111をインストールして拡張機能を丸ごと移したらいろいろエラー出たわ
面倒でも拡張機能は一つずつ再DLしなきゃならん
>>672 個人で楽しむだけなら自由にどうぞ。ローカルSDで思う存分生成すればいい。
Colabとかのパブリッククラウドで生成したり、公開するのは止めておけ。
チキンレースをするべきではない。人生棒に振るぞ。
ようやくLora学習デビューしたけど、Loraってハイパーネットワークみたいに途中経過画像出力はできないの?
>>671 やりかた次第ではいける
顔のみ素材たったひとつだけを水増ししてそこそこの制度のLoRAを作ってる人とかいる
>>676 Epochごとに保存は出来る
またその続きからも出来る
>>580 です。
Applyのボタンに気がついていませんでした!
これを押さないとダメなんですね……
初歩的な質問に付き合っていただいてありがとうございます。
ガンガン作るぞーーーーー
>>672 どこからリアル3次元かという基準は人によって違うのでなんとも言えないが
サムネでみても人間に見えないくらいなら2次元なのでセーフ
サムネにした時に写真で見える2.5次元はアウトと考えたほうがいいよ
txt2imgで構図が気に入った絵が出来ても元画の彩度が淡くて引っ張られてしまうのですが、VAEでも元画よりは彩度上げるのは無理ですか?
それはもうwindowsの画像ビューアで修正したほうが早い
>>682 全く色を変えたいならControlNETの素体にするという手もある
意地でもAIだけでやろうとしないというのは大事よな
やはり別途レタッチソフトですね。
ガッツリ編集する時はGIMPですが軽くトリムや背景白塗りはペイントの起動速度が嬉しい
>>682 ネガティブでモノクロとグレイスケール入れる
>>680 二次元絵なら大丈夫と思ってたらそうでもないぞ
わいせつな二次元絵で逮捕者がいるから
>>691 >公式グッズと混同されかねないもの…については、「海賊版」とみなされ
つまり非公式ってことを全ページに書いておくとかしないと、
AI絵は似すぎてるから危ないかもね
t2iで生成した物をi2iに送って同じプロンプト送り続けるとどうなるんですか?
>>693 t2iで作った画像を大きく進展させることはできない
i2iベース画像に強いプロンプト要素が残った状態からスタートするので、相乗効果で却って破綻しやすくなる
指が破綻したイラストをペイントで修整してたら手を自然と描けるようになっててわろた
生成せずともあれだけで抜けるようになるまで繰り返しましょう
ロリ画像ってエロじゃなければ別に良いんじゃないの?
エロ同人と同じような感じの絵ならロリエロだろうがOKだろ
>>681 いやCPU全然関係ない
読み込みはSSDじゃないとかなりストレスたまるので速いSSDを買うのは大正解
SSDに本体を保存したいけど、outputとか無限に増えていくものはHDDに指定したい
SSDはモデル切り替えとか効果あるけど
実写的なのはNGだけどアニメやゲームなどの想像上なのはセーフって書いてるね
kohya‗ss‗webuiでの導入で行き詰ってしまいました
>>673 そりゃ容量大きい方がお得感あるからでしょ
いまどき別にケチるようなものではないし
webuiをcolabで起動させた場合、
BTO購入で悩んでいます
確かに低いほど良いけどね
グラボだけ買い替えればいいような
>>711 A構成は流石にメモリ足りなすぎだろ
画像生成AIしなくてもウェブブラウジングしてるだけでもタブを多めに開いていると露骨に動作が遅くなるレベル
最低16、モデルのマージを行うなら最低32GB必要。
SSDも500GBだとシステムファイル系統だけであっという間に無くなるわ
出力画像を外部ストレージに退避させるんでも、モデルやLoraだとかは高速ストレージの方に入れとかないとストレスだし
最低でも1TB、できれば2TB
あと値段とどこのショップで買うのか書けや
良構成でも糞ショップのぼったくり価格だったらそれだけでアウトだろ
ありがとうございます
>>715 GTX1660sのBTO(Lenovo特殊電源)の電源が海外BTOにありがちな
低容量(380W/80PLUS PLATINUM)+LenovoのPCはATXではなくTFX規格(pin数も違う)
bbs.kakaku.com/bbs/K0001164365/SortID=23659016/
とのことでGPUだけ変更は考えていなかったのですが
型番でググってみたら同じ電源容量でRTX3060搭載モデルもあるんですね…怖いけれど安く上がるなら悩ましい
lenovo.com/jp/ja/p/desktops/ideacentre/ideacentre-gaming-5-series/ideacentre-5-gaming-gen-6-(amd)/wmd00000495
自作する場合必要なのはグラボ・ATX電源・ケース・マザボ(B550)でしょうか
Ryzen4600Gも余っているのでRAMとCPU・OS用ストレージとモデルを入れておくNVMeSSD・保存用HDDは流用できそうです
フォトリアルにすると背景がボヤけてしまうのなんとかなりませんか?
ネガにdepth of fieldとbokehとblur background入れるんじゃ駄目なんか?
実在の人物をadafacterでローラ学習させて それなりに似てきたなって段階でノイズ走るようになってきたんだけど
>>706 だな
以前からNVIDIAのグラボはビデオメモリが少ないと言われていたが
AIでCGを作るようになってそれが深刻な問題になってきた
>>713 だな
コンシューマ用のグラボに搭載されてるGDDR6メモリは低コストだが発熱が大きく
消費電力が大きいハイエンドモデルはメモリが熱で壊れてお釈迦になりやすいのだ
法人用のサーバーで使うグラボに搭載されるHDM2メモリはコストが高いが発熱が低く
低消費電力でデータセンターで24時間使い続ける目的に合ってる
その代わり個人ではとても買えない高級品
DDR4 32Gで6980とか見た
メモリ32GB積んで8GBをRAMドライブに回して画像出力先にしてる
セックスしてところを出そうとしたんですが後背位でやってみたら
モデルはAOM2_nsfwで解像度はw768*h512です
>>724 >>725 >男の方はチンポすら出てきてくれません
>モデルはAOM2_nsfwで
答え出てるじゃないか
NSFW用のモデルで「セックスしてところを出そうと」するな…
後背位ってアングルまちまちだからか出づらい印象
申し訳ないので試してきた
>>724 1girl, 1boy, mature male, (doggy style:1.2), sex, penis,
これでだいぶ改善されます 色々コツがありますが
成人男性を出したければ俺の経験では1manより1boy, mature male,の方がベター
強調1.4はちょっと過激で崩れがちかなあという印象
今回は明確に性交シーンが目的なので体位だけでなくsex,も含めます
もしかすると(on all fours:1.4)より(all fours:1.2)の方がベターかもしれません
danbooruのタグ的にはall fours,だからです
https://danbooru.donmai.us/wiki_pages/all_fours?z=2 またdoggy styleにより女の子に犬耳が誘発されてしまうので
ネガティブに(dog ears:1.2), をおすすめします
【StableDiffusion】AIエロ画像情報交換20【NovelAI】
https://mercury.bbspink.com/test/read.cgi/erocg/1680682937/ エロは内容的にこっちでやったほうがいいのでは・・
というか一緒に見てるのでスレどっちか間違える
>>703 むしろ本体もHDDに入れてる
Stable Diffusion関係でSSDに入れてるのはモデルだけ
>>710 それどころかコードセルを実行すらしていなくても、ランタイムを接続している間はGPUリソースを食っている
なのでGoogle Colabだと起動したらやりたいことをサクサクすませないと気が気でない
Colabの無料は3時間ほどGPUを使うとリソース切れになるらしいので、よほど大量の画像を生成したいとかでなければあまり神経質にならなくてもいいかもしれんけどね
>>717 LenovoはTXF電源に似た物らしいけど、メーカー製PCは起動シーケンスや電源オン信号が特殊なものがあり
ATX/TXFと完全に互換なのか分からないです。
起動シーケンスが特殊なのが分かっているのはDellとかで、その手のタイプは変換ケーブルの間に
黒い熱収縮チューブに包まれた電源&マザーを騙す怪しい基盤がついてます。
Lenovoの電源コネクタはATX24ピンではなく、14ピンや10ピンなどモノによって違っていて変換ケーブルはあることはあるようで。
アマゾンで 「lenovo 変換ケーブル 電源 ピン」 といれると600~1000円くらいのものが出てきます。
基盤などは途中に付いていないようなので、変換ケーブルだけでいけるのかもしれない。
https://ecco.work/lenovo-8 一応Lenovo製品を24ピン14ピン変換ケーブル+汎用TXF電源と交換したというブログはあることはありますね。
ただネジ穴が互換かどうかは書いてないので、入るだけ入るのかちゃんとネジが止まるのかは分からない。
電源外置きむき出しを許容できるなら、変換ケーブル+中古ATX電源550~600Wや格安の玄人志向の新品が
使える可能性があります。
手持ちのATX電源があるならゲーブルだけテストして動作したら、電源購入を検討するのが良いかもしれません。
3090 なのに ハローアスカ 9 it/sしか出なくて悩んでます
チルミ+jdlで就活生の生成を頑張ってますが
>>736 1111のブラウザページ(
http://127.0.0.1:7860 )の下端に
torch: ○○○○ xformers: ×××× とか表示されてるので確認してみてね
1980×1080で壁紙作ろうとしたら横に広げた分同じ人物生成されちゃうんですが、指定した場所に指定した人数置きたい場合ってどうしたらいいんですか?
>>738 おおっ、全部入ってたみたいサンクス!
python: 3.10.6 torch: 1.13.1+cu117 xformers: 0.0.16rc425
だとしたら遅い理由が検討も付かないんですが
なにか無いでしょうか
>>730 動画じゃないから必要無いと思ってpenisは書かなかったんですけど
セックスの時には書いた方がいいとことですかね
男一人だから1manだろうと思ったんですが属性的な記述も書いた方が
良さそうという事でしょうか
Lora使わないと駄目なのかと思ってたけど出やすくなった感じがします
ありがとうございました
>>739 そもそも仕様としてSDモデルは512x512~768x768で学習されてるので通常は高解像度に対応しておらず、縦長や横長にすると人が分裂したり融合して生成されたりしてしまう
基本的に1000以上の大きさで破綻せずに出力したい場合はhiresを使用する
そのうえで、複数人を想定した位置に配置したい場合は機能拡張のcontrolnetを導入するほかない
4070Tiか4080か迷ってたらここ2~3日で4080が全体に2万ぐらい上がっとる…
>>740 (1) 俺は10xx民なので30xxについてはあまり助言できないけど…
1111起動時にコマンドプロンプトに表示されている、
「Launching Web UI with arguments〜」の行を、省略せずに丸々貼ってほしい。ここも肝心なところ。
例) Launching Web UI with arguments: --xformers --no-half-vae
(2) それとit/sではハローアスカのページで大変比較しづらいので、具体的な秒数でお願いします。
3090ならおおよそ18〜23秒くらいが一般的な範囲かな。
(3) 画像生成中のプレビュー機能は無効化していますか?
1111のデフォルトではONですが、生成速度が大なり小なり落ちるので注意してください。
>>741 「男の方はチンポすら出てきてくれません」と言っていたので、
ちんこも描写してほしいのかな?と思い、penis,を書き足しただけです。
性交描写の有無には必ずしも影響しないと思うので、純粋にお好みでどうぞ。
個人的な経験では1man,より1boy,の方がよく効くように思います。
ただこの単語のみでは竿役が少年になる可能性もあるため、mature male,も足しました。これもお好み次第。
男の娘(身体の大きさにあってないちんこやふたなりじゃなければ見た目がっつり女でもok)生成したいんだけどおすすめモデルVAEloraプロンプトなんかあれば教えて欲しいです
>>744 ありがとうございます!
プレビューオフにしたらとりあえず、10枚45秒から33秒ぐらいになりました。
まさかこんなに影響するとは
でもまだ遅いですね
Launching Web UI with arguments: --xformers
で終わりで行が変わってLoading weights〜となっています
cuDNNがインストールされてない?(SDフォルダにはあるのに)
関係ないかもしれませんがその辺ググっています
>>747 なるほど、
>>740 の情報と合わせて、xformersを利用できていることが確認できました。
とはいえ、他の3090ユーザーのハローアスカ報告例から考えると、せめて25秒くらいにはなっていい気がしますね。
やはりローカル高速化メモのページにある通り、webui-user.batの内容を編集したり、
各種ライブラリのバージョンを上げて試すことかなあと思います。もう読んでらっしゃる様子ですが。
>>736 これは1111の仮想環境の外(venvの外)でpip show〜を実行したからです。
1111のディレクトリで「venv\Scripts\activate」を実行することで1111のvenvに入れるので、
その後でpip show〜等を実行するわけです。
1111に使用する各種ライブラリのバージョンを上げたい時も同様です。
>>748-749 ありがとうございます試してみます
今更ですがCPUがi7-6700k、本体も当時のものと3090以外かなり古いので
それで5秒以上ロスしてるかもしれません
cuDNNファイルを最新にしてみたけど変わらずでしたが
お話統合して、その他の要素で積み重ねで通常になるのかもしれませんね
多分致命的な間違いは無いと思いますので解決しました
ありがとうございました!
>>743 >ちくしょうもう人生が台無しだ
大げさだよ
たかがグラボだ
2年後には5080が出てるし
AIも今より進化してるだろう
つまり今よりもずっとよくなる未来しかないのだ
半導体産業は完全にブレイクスルーが起きたな
>>743 ちょっと待って売れば良かったわ
17万で手放してもうた
欲しいと思った時が買い時や
エロpromptに忠実なリアル系アジアモデルってあります?
これbatch countで複数枚出力する時と1枚1枚出力して複数枚作るのって負荷同じなの?
ChromeのGPUアクセラレーションだか切ったら
>>756 ああいうのが簡単に可愛い女の子を出せるのはそういう学習をしてるからであって、それは自由度とトレードオフ
だから自分の望むシチュを出すにあたってプロンプトだけじゃ弱いならモデルを変えるのではなくてloraを使うのが良い
>>735 ありがとうございます
LenovoのPCは複数買っていて
[a] IdeaCentre Gaming 560
Ryzen5600G RAM32GBx2 GTX1660s 380w
[b] V55t
Ryzen4600G RAM16GBx2 180w
[a]のゲーミングから[b]のオンボード機に電源とグラボを移植して
[a]に新しく800W Goldあたりの電源とRTX3060を付ければ安く上げられるし無駄も少なさそうではありますね
(変換は /dp/B096TS4X63 が使えそうかな?)
考えてみると自作ならOSも新たに買う必要がありましたし
>>711 のBTO以上に高く付いていたかもしれません
>>762 LoRAは追加学習ファイル
controlnetは説明長くなるからぐぐれ
ていうかそのぐらいはさすがに調べろ
>>744 > (3) 画像生成中のプレビュー機能は無効化していますか?
> 1111のデフォルトではONですが、生成速度が大なり小なり落ちるので注意してください。
そうだっけ?ってライブプレビューをOFFと1STEP毎で試したけどほとんど差がないような
計算そのものに時間食うけど、内部で持ってるものを表示するだけはハイスペックGPUでは誤差レベルかと
1111で生成した複数のPNGやJPGの生成情報をまとめて書き出す方法はあるでしょうか
その質問をChatGPTに放り込むといい
linuxならシェルで
civitaiのコメント欄に全く同じ画像は生成出来ない←わかる
>>769 ハローアスカでみんな試してたんだから、んなわけない
--xformersやその他のオプションの有無とかでもいうほど変わらない
モデルやプロンプト以外にも、そもそもLoraのバージョン違いに気付いてないだけでは?
具体的に当該URL貼ってみて
>>759 横からだけど下のモデル見逃してたわ
かなりいいねこれ
>>763 10ピンの方は幾つかシャットダウンさせても、電源のFANが回りっぱなしで完全に落ちない不具合があるようで
毎回電源ボタンで切らなければならないのが面倒であるというレビューが付いていました。
ちょっとお高い転売っぽい10ピンのものにも
>注意: コンピューターがシャットダウンしても電源がオンになります。 この場合、メインの電源スイッチ(パソコンの背面)でオフにする必要があります。
と書いてあるので、10ピンのものはシャットダウンしても電源が落ちない不具合がある可能性があります。
lenovo デスクトップPC総合 Part10には
2chb.net/r/pc/1444022960/650
>Q.電源と変換ケーブル用意して使う必要ある?
>A.ない
とバッサリなので、
電源ボタンを押す代わりに、サンワサプライの TAP-B7-1N のようなオフスイッチ付きの延長ケーブルを使うとか、
美観を損なう状態での運用になるかも知れませんね。
うーん、なかなか難しいですね。ぬか喜びさせてしまって申し訳ないです。
>>766 設定変更してテキストで出すようにすれば少しはラクになるかな
そこからさらにそのテキストを比較するアプリをGPTにでも作ってもらう
>>769 >>770 GPU1000番台とそれ以降では結果が違うしCPU生成でも変わる
現在はハローアスカチェックもやらない人のほうが多い
CPUて・・
Lenovoは5年保証つけて買った方が安心
Nvidiaでも3000/4000番台とそれ以前で絵が違うよ
eleganceが Ngirls, side by side で綺麗に並んでくれ易いと思うんですが、顔は極力外して
>>770 その頃はあまり細部に目が向いてなかったってわけでも無いの?
画像コンペアして完全一致するか確認してたわけじゃないよね?
>>708 学習させてるの忘れてて1111で生成しようとしたら似たようなエラーが出たので、なんかvram関係じゃないのか
普段は自作板の住人だけど、AIやるのにコスパ考えると4090一択なんだよなぁ
超高画質AI画像生成しまくりたいけどPC自作とか全くした事ないワイみたいな素人人間にも出来るもんなんやろか?
>>783 ハードなんてBTOで注文するだけじゃん
ソフト動かすほうが大変よ
それも先達の努力によってかなり簡単になってるけど
デカいケースのクッソ安いBTOパソコン用意
ケースはやっぱり後々換装することも考えて大きい方が良いですかね
>>772 とんでもない自作経験も乏しく独りで不安だったのでありがたいです!
基本的にRyzen4xxx番台以降は付けっぱなしでも大してアイドル電力を必要としないので
常時ON運用にする予定でした
個人的に怖いのは
別商品 /dp/B09H5PVRXK のレビューにある不良品で電源とCPUが破損になったパターンですね
(成功例の方のレビューも載っているのでほとんどの品は正常作動しているとは思うのですが…)
電気系統は間に入る部品点数が増えるとどうしても不具合のリスクが高くなってしまうので
飛び込んでみる勇気が必要なのが難しい所です
civitaiにあるzposeの5番目の尻突き上げるやつが実写系モデルで奇形ばっか生成されるんだけどみなさんはどうですか
>>788 IBMの頃からひいきにさせていただいています
こういう解像度高くてクオリティの高いイラストってどういう風に生成しているんでしょうか。
公式アニメを学習に使った自作loraを使っているくらいしか思いつかないのですが、他に再現できそうな方法はありますか?
https://twitter.com/asterass_pixiv/status/1644354856029929472?s=46&t=-Nrs7msB6ZF3WtXeikcirA https://twitter.com/5chan_nel (5ch newer account)
VAEって名前をcheckpointと同じにしていることが大事であって、VAEフォルダに置こうがmodelsフォルダに置こうが関係ない?
>>786 ケースは好みだと思いますが普通にミドルタワー/フルタワーの安物でよいと思いますよ
>不良品で電源とCPUが破損になったパターンですね
どういう状況なのか詳細がないので、ちょっと分からないですがギョッとしますね。うーん
調べてみるとideacentre RTX3060搭載の型番は 90RW002PJP になるようです。
90RW002QJPと90rw002mjpは1650sで構成の違いはよく分からないです。
で、驚きの新事実が・・・。
https://p3-ofp.static.pub/ShareResource/JPCatalog/210727-ic560gaming-rt.pdf 90RW002PJP(3060)と90RW002QJP(1650s)の電源構成は380Wのまま共通なようです。
まじでかorz パワーリミット掛けてるのかな?
Youtuberあたりがそのまま3060ぶっ差して動作させてたら安心できるんだけど・・・
魔改造した事例はあるのですが・・・
・Lenovo Ryzen IdeaCentre 5 電源の交換
VIDEO YoutubeにIdeaCentre系(詳細は不明)に電源+変換ケーブル+3060tiを押し込んだ変態がいました
シルバーストンの600Wはちょっと高そうですが魔改造してケースに詰め込まれています(怖
googlecolab課金額が1万超えたんで初自作PCを考えてるんだけどこんな感じで問題無いかな?
ほぼ画像生成専用pcの予定なんだけど、もし+3万予算があるならどこを変えたり足したりした方が良いとかある?
すまん誰かddeairerが正しく動いてるひとvenv/Lib/mmcv/Untilsファイルのデータくれませんか
ファイルのデータくれませんかってそれ質問じゃないじゃん よそ行きなよ
>>795 ケチくせーこと言うなよ
くれないなら黙ってろカス
>>776 STDと録画用に一台買ったけどOSに変なサービスやら裏で走らせてるらしく激重だよあれ
録画失敗しまくるので変だなと思ってチューニングしたけどおかしくて
結局OSを新規に入れ直したら普通のpcになったのでサービスにでない変なもんいれてるよレノボのWindows OS
hiresでupscaleを2倍を上回る設定で生成すると、完成直前で絵が消えるんだけどこれGPUのメモリ不足なのかしら
>>793 今から3060 12gbは茨の道だなと思う
今更ちまちまプロンプトの確認してると、そのモデルデータにあまり含まれていないワードを強調し過ぎると、
>>793 colab使いまくるような人なら尚更、俺なら4万ちょい足して
中古3090と電源を850w〜にしますね
上を狙う気がないなら、それ以上足さない方が良いかと
俺はもう3060には戻れない…
>>793 長く使う気ならCPUとマザーはPCIe4.0対応にする
電源を1ランクアップ(Gold)
倉庫用HDD
ファン追加
CPUクーラー(後から交換は面倒)
全部やっても3万いかないと思う
処理速度?がxformers有効にして2it/s程度なんだけど
こんな感じ
こんなもん?もっと早いもん?
メモリ32GB
Core i7-12700F
4070ti
スペックはこんなもんなんだけど
他の全てを最低限のゴミにしてでもちょっとでも良いグラボにしとけって少し前の俺に言いたい気分になってる今の俺
Hiresやりたかったら24GBにしとけ
良いグラボ使ってても他の全てが最低限だとパフォーマンス発揮できんでしょ
だから グラボの VRAM が全てだと言っているだろう
うちのマシン
>>793 今の PCがミドルタワーのデスクトップならば、それに挿せるグラボ全力ブッパがいいと思う
型落ち狙うならryzenよりもIntel系の方が安いことが多い
RTX4070が4月中、4060Tが5月と予
予告されてるので、待てるなら発売待ってから型落ちを狙う
あと決済方法をヤフショや楽天、NTTXなんかのセールで狙うと幸せになるけど一式揃えるなら PCショップのセール品でもいい
頻繁に切り替えると地味にストレージ速度が必要だったりするからhiksemiのNVME もHOT
LORA学習でもRTX4080よりも VRAMある3090の方が速かったりするけど
>>793 だけど色んな意見ありがとう
色々とグレードアップするかグラボ一択か迷う感じか
型落ち待ちはcolabのpro+を一週間ほどで使い切ってしまうからそこも悩みどころ
パーツ交換するかも知れないならOSはリテール版一択
RTX4xxx番台はL2cacheが大増量したのが生成速度に寄与しているんですかね
(RTX3090 6MB -> RTX4080 64MB)
>>792 調べてまでいただきありがとうございます
今更気付いてしまったのですが自分が今使っているideacentre560のGTX1660sがシングルファンで
おそらく市販のRTX3060を換装しようとすると(GPUを入れ替える両PCとも)ケースを外す必要が出てきそうですね
(さすがに2万円近くかかるライザーケーブルまでは必須でないと願いたい)
1660sとTFX電源を移植する予定のV55tは(激安で出ただけあって)ケース換装で先駆者の方が居られました
VIDEO NVMeSSDだけ元々ケースからはみ出す形で実装されているので
SATAにするかテープで貼り付ける必要がありそうです
>>817 キャッシュよりも単純な計算速度かな
3090tiに比べて4080はcudaコアの数が1割減ってるけどコアクロックが1.4倍
プロセスルールの進歩でcuda1コアあたりの処理速度自体も上がってる
キャッシュヒットはあんま関係ないような気がしないでもない
>>804 it/s は生成サイズやステップやサンプラーで全然変わるから
それだけ見せられてもわからんで
アスカベンチとかの512x512なら4090で35it/sはでる
>>812 変にワット数高いと変換効率悪くて余計に電気食うよ
これ見ると3090と4090の速度差は2倍
3090と4080でも1.5倍も違う
VRAMは12あればだいたいの事は出来るが
生成速度の差はどうやっても埋まらないから
俺は速度優先すべきと思う
服の上から乳首が立ってるようにわかるようにするpromptってある?
>>822 Pokieや
Loraもちゃんとあるで
>>821 生成速度優先!→最速のRTX4090
学習もやりたい!→VRAM24GBのRTX4090
ガチクリエイターです→RTX A6000(48GB) 60万円
石油王です→Tesla H100(80GB) 440万円(8台でlink可能)
inpaintの画像が小さくて見辛いのだけど拡大できますか?
俺もやり方知らないのでctrl+上スクロールで全てを巨大化させてる・・・
>>828 いいですねそれ、ありがとうございます♪
4090ほしいけど水冷+ケースを新調しないといけないからなぁ
>>826 60万のa6000cudaコア10000程度のゴミや
150万のa6000 ada が4090超えの本命やで
普通に生成して良いの出たからシード値固定して高解像度補助して2倍スケールアップしたら絵が崩れ始めるんだけどなんでや
>>794 最新版だと問題起こすみたいね
俺は導入してないからあげれないけど
>>832 デノイズ下げればおk
モデルによって推奨デノイズ違うからきをつけてめ
MultiDiffusionのNoise Inversionってどういう機能なんですかね?
>>834 なるほどってかモデル毎にそんなのどうやって把握すればええん
配布ページに書いてあったのかな
https://rentry.org/lora-tag-faq ここに書いてる
>似たようなタグで重複している場合はどうでしょう。panties, white panties, frilled panties,
もし統合したいのであれば、これらのタグの中から最も近いものを選び、常にそのタグだけを使用するようにしてください。
例えば、3つのタグをすべて "frilled panties "に置き換えるだけです。
ってよくわからないのですが似たタグを全部同じタグ名にして残すってことですか?覚えさせたいタグは消すのでは?
>>836 アップスケーラーはLatentの有無で仕上がりがかなり変わるから、そこもいろいろ試してみて
>>836 配布ページにだいたい書いてある
書いてなかったり複数のマージモデルの場合はとりあえず0.3くらいにしておけば綺麗にもならないけど破綻もしない
>>837 タグ消すか残すかは
常に履いてると覚えさせたいなら消せばいい。nudeと入れても履いてたりする
タグ残すと脱がしやすいが履かせるのにpanties要るかもしれない
タグまとめる件は
上の例でタグ3つ並べるよりひとつで良くなる
>>817 3060(12BG)ショートで170mmのものがあるけど一部通販サイトで在庫切れを起こしてるのが悩ましい所ですね。
あとは200~245mmのツインファンは割とありますが。ツクモex通販は複数ショートの在庫があるぽいです。
arkやパソコン工房、ドスパラも数点ショート扱っているようです。
マザーはMicroATX(244mm×244mm)のように見受けられます
ATXは244mm×305mmで縦長なので60mmくらい下に突き出してても
ATXが入るケースならSSDは干渉しないと思われますがブラケットや固定ネジが移設できないと
プラプラになってしまいますね
一応、M.2 NVMe SSDの延長ケーブル自体は存在しているようですが
https://www.century.co.jp/pc_solution/topics/m2.html M.2は切り欠きの位置でB Key、M Key、B&M Keyの以下の3種類あって
違うと動かなくなるとか面倒な事になってるので、慎重に選定する必要がありますのでお気を付けください。
M.2→SATA変換アダプタも同様にKeyの問題があるので気を付けて。
8GBのモデルファイル生成するのに
>>841 あーそっかタグが付いててもそのモノ自体は覚えるんですね
タグ付けたやつはプロンプトで書けばいいのか
それで似たようなタグは一つだけ残すと
ありがとうございます
>>831 ちなみに生成速度は4090と比較してどうなんだ?
RTX系以外のものについてVRAM以外の恩恵にあんまり詳しくなくて知らないんだが
ってRTX6000 adaなんかい
ゲームはやらんからPC新調してもグラボは毎回弱いんだよなぁ・・・
>>845 a6000の生成ベンチなんて見たことない
ここで聞くような事じゃないかもなんだけど
>>842 245mmのを買う予定だったのですが
内寸を測ってみてギリギリかな…?と不安になったので
確実に余裕のありそうな212×115×43mmツインファンの12GB版を注文しました!
グラボは製品によって大きさが全然違うんですね
GPU単体購入は初めてで「?」「??」「???」状態だったので助かりました!
ご親切にありがとうございます
ファンの数が少ないほど冷却性能低いのでうるさいよ
4070tiと3060 12GBって生成速度が2.8倍差があって
3060買ったけど少し待って4070買えば良かっちゃ
>852
RTX4070は実質3060のアップグレード版ですよね
>>850 お疲れさまでした。何事もなく交換出来て電源君も踏ん張ってくれることを祈っています。
グッドラック!!
無料のモザイク加工ツールを教えてください。ペイントでやるのは疲れました
ってああ自動でやって欲しいわけじゃなく代替の無料のソフトを探してたのかすまん
>>826 >>826 >>860 >>857 inputに送って修正するところをマスクしてCFGを右にめいっぱい振って
promptになんかはいってれば謎のにじみになるだろ
最終段でガバッとエフェクトかかるのってVAEなのかモデルなのかどれなんだろ外したいときもあるんだけど
そもそも生成中のプレビューはあんまり正確じゃないよ
>>831 そうそう
RTX 6000 Adaが本命だよな
>>845 >>848 RTX 6000 Adaは
RTX 4090とほぼ同性能だが決定的な違いがある
VRAMのクロックスピードが8倍速い
4090のVRAMのクロックは2.1GB/sだが
6000Adaは16 GB/s
あと違うのは
4090のTDPは450 Watt
6000Adaは300 Watt
ワッパが良い
ありがとう
>>853 逆に考えるんだ
12GBでどこまで出来るかの練習台に出来たんだと
>>866 AWSやAzureとかのクラウドで使えると良いよね
月額2000円程度で提供してほしい
GoogleはAmpere世代(RTX3000番台)のA100を
Colab Pro/プレミアムで月額1000円で提供してる
これでStable diffusion使ってみた記事も上がってる
↓
pc.watch.impress.co.jp/docs/column/nishikawa/1485422.html
torchリビルドして3,4割早くなったが
最近Loraで学習をやり始めたばかりなんですが、学習素材に文字、枠、マーク等が入ってる場合は
あと一枚の画像に学習させたい人物(一人だけ)が色々な角度で複数写っている素材がある場合は1画像1素材として切り取ったほうがいいのか
モデルやloraは共有するかたちで拡張機能を含むwebuiを複数環境用意したいのですが何かいい方法ありませんか?
そもそも使い方がわかりません
>>872 そりゃあもちろんシンボリックリンクでモデルフォルダやLoRAフォルダを共有することだ
>>870 出来れば消したほうがいい
人物も一人一人で分かれてるほうがもちろん精度は高くなる
教師画像は量も大事だが、それ以上に1枚1枚の質のほうが重要
>>872 フォルダ名を変えて別途インストールして、モデル類やLoRAはシンボリックリンクにして別フォルダや別ドライブに指定して共有させることは可能
>>875 ありがとうございます。
消してやってみます!
パンストの色が黒か白しか出ないんだが
>>854 3060でもhires2.0は連続でできるくない?
3.0とかでのクオリティの差はどんなものなのよ
stable diffusionの技術的違いについて知りたいです。
stability aiが倒産したらバージョンアップが無くなってパラメータの更新がされないとAI絵の表現力が上がらない事に繋がるって認識はあってますか?
white serafukuとblue pleated skirtを組み合わせると結構な頻度でセーラー服も青色になるんだが原因分かる?
>>886 既に試してる通りなんだが、やはり呪文の位置・強度・カットオフ等が有効だ。
付け加えるとBREAK構文も有効。それとポジティブにwhite shirt、強度は1.0〜1.2くらい。
ネガティブにblue shirtを1.0〜1.2くらいで入れる。
襟色の好みは分からんが、○○ sailor collarで指定してくれ。white sailor collarとかそんな感じ。
>>883 人参とナスなら入るけど大根は入らないから使えないだろうw
>>887 この文章を見るだけでコメントした人が
相当な熟達者ということがわかる
白セーラー服に紺ハイソも簡単そうで出ないぞ
そういうの領域別プロンプトで大体解決するイメージ
>>887 BREAK構文( ..)φメモメモ
どれも有効なテクニック
ありがとう色々試してみる
>>891 領域別プロンプトとは?これも初めて知った
ググってもヒットしなかったんだが拡張機能か何かだろうか
>>893 latent couple とかregional prompterとか
画面を分割して領域ごとにプロンプトを設定できる
領域ごとに色指定を変えれば色移りはほぼ回避できる
>>894 なるほど。早速入れた
説明書読んでイジってみる
情報ありがとう
(girl:1.0)と強調無しのgirlって同じだよね?
黒とか白以外でパンストの色出すプロンプト
Latent CoupleでComposable LoRA使ってもLoraが混じるどころか
:1.1は単語への注目度を1.1倍するの意味のはずだから1.0に下げれば注目度1倍=変わらない という認識だったんだけど違うの?
同じだと思うけど
>>823 乳首ポチの単語なんてあったんだww
あいつらもhentaiだな
>>896 のちのち何か出物見つけて4070tiとかに買い替える様な事があった時の事を妄想して
>>899 最新版のWebUIではComposableLoraが機能しないらしいよ
機能してればきっちり完全に分けられる
openposeeditorにはundoや一体だけ削除の様なショートカットは無いのでしょうか
>>906 まじか。じゃあしばらく使うのやめとくか
>>908 オンオフで何も変化が無いわけじゃなく、変化はあるなら違うのかも
compatibilities
--always-batch-cond-uncond must be enabled with --medvram or --lowvram
ここら辺は大丈夫なの
みんな修飾語って何使ってる?
WSL2 で Stable Diffusion WebUI を実行しようとして
>>910 やるな
ならばスカートは紺でできるかな?
これがまた難しいんだ
>>914 (master piece),1 girl,solo,contrapposto,wide shot,([white::0.2] sailor suit:1.2),(blue skirt:1.2),(blue socks:1.2),shoes
ネガlowres,(worst quality, low quality:1.4)
で9枚出してみた
靴下が紺というか水色だけど、適当に調整して・・
白セーラーをSTEP全体の0.2の位置で打ち切ってソックスとスカートへの白色移りを防御
帽子はセーラー=水兵だから出ちゃうのか
civitai helperでいつの間にかファルダ分けしたloraタブが横並びになったんだが上並びにする方法ある?
プロンプトとか保存出来るけど保存したやつ消すのはどうすればいいの
>>918 promptの内容は生成物に埋め込まれてるやろ
呼び出したい時は生成物をinfoに入れてt2iやi2iにsendすれば良いだけ
>>918 プリセット?を消すのはどうすればいいんだろう
古いのが残ってるの気持ち悪い
BreakDroの人のプロンプトが独特だ
>>923 さんきゅ
みんな英語のままで使ってるのかな
日本語に変換して使ってると他の人の言ってる単語や参考資料が何を指してるのか分からなくて少し手間取るわ
英語アレルギー爆発して使えないよりはマシだけど英語よくわかんない程度なら我慢して使って慣れた方が絶対便利になる
英語じゃないと検索で掛からなくなるんだよね・・解説系の日本人もほぼ英語の方で説明してる
目玉を超綺麗で詳細に表現したい時って瞳孔か虹彩どっちをメイン呪文にしてる?
ControlNetが全く反映されなくて困ってます
以前は使えてたんですが、webuiを再インスコして全部入れ直したところControlNetが反映されなくなってしまいました
何故だかわかりますでしょうか?
>>917 「loraタブが横並び」と言っているのはフォルダを選択するボタンがサンプル画面一覧の中央部ぐらいに移動していることでしょうか?
この現象であればうちでも発生しました。 うちの場合はcivitai helperではなくashen-sensored/stable-diffusion-webui-two-shotが原因でした。
ashen-sensored/stable-diffusion-webui-two-shotを入れていませんか?
もしも入れているようならtwo-shotのstyle.cssを編集すれば解決する可能性があります。
style.cssから下の部分を削除したらうちでは解決しました。
.output-html{
display: flex;
justify-content: center;
align-items: center;
}
副作用があるかもしれないので編集する場合は自己責任でお願いします。
webuiってバージョンの概念は無いんですか?コミットとか言われても
数分置きにモデルを自動的にチェンジしてくれる機能って無いですか?
>>934 gitの管理の仕組みを知ってもらうのが一番なんだけど、すごく端的に言うとバージョンの代わりにコミットハッシュがある。
webui-user.batの起動時に最初に表示される「Commit hash」のところがそれ。
githubのページにアクセスしたときに時計マークの隣に「XXXX commits」って書いてあるところをクリックすると、過去のバージョンのようなものが一覧で出ている。
今表示出来る最新で「22bcc7b」って表示されているところが、「Commit hash」の上7桁なので、それで識別出来る。
>>913 ド定番だけど、WSL2の最新化、WSL2環境の再起動、パッケージ最新化、WSL2用のCUDAインストール、この辺は全部やった?
clip skipって何?
もしかしてstable diffusionってGPUをフル活用する前にCPUのシングルコア性能で律速してるの?
3060のパソコン買ってAI絵の生成に飽きた場合
>>942 機械学習ってのはこの先も続くから
そっちの分野に興味があるんだったらそのまま使える
>>942 本来の用途はゲーム用や。本来用途に使ってやれ。
エロ用途なら超解像度やモザイク除去(GAN)あたりか。
【CLIP設定ってどうしたらいい?】
児ポ販売はこれくらいなら大丈夫が通じんぞ
>>940 自分も全く知らないけどどうやらCLIPはトークンごとに分割された文字列をEmbeddingなる高次元のベクトルにするものらしくて
最終層の全結合だけやらずにKsamplerにぶち込むのがClip skip2なんじゃないですかね
ほんとに何も知らないで適当言ってるので識者求む
>>938 ありがとうございます
a9fed7c364061ae6efb37f797b6b522cb3cf7aa2ですが割と安定版のようですね
何故バージョンの概念でないのか分かりませんがアプデせず引っ張ろうと思います
NovelAIに課金しようか悩んでるんですが
>>950 お、まさかのうちと同じcommitだわw
端的に言うと、バージョンの概念のひとつ手前の段階なのよgitで管理しているモノは。
開発中でまだバージョン番号を付けるにも至っていないファイルをそのままダウンロードして使っているのが現状。
動いている限りは基本そのままでいいと思うよ。
>>952 課金していないけど、ハロアス見る限り版権絵自体厳しそうじゃないか?
ローカルなりクラウドなりでSD走らせて著作権上等なモデル使った方がいいと思う。
>>952 NovelAIは基本的に女性キャラのほうが優遇されてるので男性キャラメインで遊びたいのであればあまりオススメは出来ない
あと、わりと有名な既存キャラもそれっぽいのは出るけど大抵は完全再現出来ないので『ある程度似てる』ぐらいでも許せるぐらいじゃないとダメかな
もしもキャラを完全に再現したうえで色々遊びたいのであればそれ相応のPC環境を用意してローカルでやるしかない
>>951 >>953 なるほど‥結局本来は一般人が使えないような小難しいものを天才達のご厚意で使えてるだけって感じかな
1円も払ってないし作者が誰なのから分からないし、動く事にただ感謝するか‥
CHILLOUTってマリファナ吸いながら作った逸話が笑える
>>952 鬼滅の刃、竈門炭治郎、でやってみたけどしのぶとピンクが混ざったような女の子しか出なかった
boyにしてネガティブでgirlにしてみたら、男まさりな女が出てきた
男は無理っぽい
ここは裕福な人多いのかな
どうだろう
泣きぼくろと足裏をうまく出すにはどうしたらいいですか?
sd-webui-train-toolsで自炊Loraを作ってみたのですが
>>435 と同じように機能しません
プロンプトの文章に <lora:出来上がったファイル名:1>を追記してもしなくても変化が無いです
>>452 のレスから繰り返し回数や学習率、dimとかalphaの値も同じような値にして
作ったりしてみたのですが変わりません
トリガーワードが必要なようなのですがこれを何処で指定すれば良いのでしょうか?
web UIを使用しててmainted akaibuを、使っています
>>964 俺の場合は黒い画面の方をよく見てみるとエラーが出ていて学習自体が上手く行ってなかった
結局kohya’s guiに乗り換えたけど、こっちのが簡単だし最初からこっちにすればよかったと思ってる
https://github.com/shirayu/sd-webui-enable-checker これ入れたんだけど、ControlNetだけ色がつかない・・なんでだ
それぞれ外したり入れたりしてみたが変わらず
controlnetをsettingsからマルチ(2つ)にしたら色ついたわ
StableDiffusion本が出たみたいですが買った方いますか?
この時代にそんなもん買うやつおらんやろ...
>>972 どんな時代にも「何も分からんし調べるのも嫌だけどとにかく使いたい」って輩は一定数いるんやで。
あの手の本の主な客層は、本に慣れ親しんだ年寄世代か自分で情報収集するのはダルいんで金払って他人にまとめてもらうつもりの層じゃね
>>959 グラボの価値をどう見るかは人それぞれ
ゲームをやらない人にはPS5だって無駄に高く感じるもの
趣味にかけるお金ってのはそういうもんよ
>>965 ここで聞くよりmaintained by Akaibuで検索したほうが早い
ゲームって今後どんどん重くなってグラボの要求値も上がっていくだろうけどAIはどうなんだろう軽量化されていくのかな重くなるのかな
Windows95の頃はメモリ何の位だったと思う?
>>973 カモだな
しかしそんなカモでサブスクとか成り立ってるからな
よくある読んで何もしないもしくは買って積んでるだけ層
パンティを出そうとしたら、みんなやたらローライズかつ布面積の小さいものになってしまいます。
https://shop.lambdalabs.com/gpu-workstations/vector/customize こういう商品でよくRTX A6000 ada x2みたいなの見るんだけど
別にVRAMが48GBあるみたいに使えるってわけじゃないんだよね?
2つ使って同時に別々の学習ができる程度のものって認識でいいのかな
あーでもtaggerとかを2つ同時に回せる(?)のかな
>>981 jyojipan LoRAくらいがちょうどいいよね
あとundie undiesとかいう魔法のワード
モデルマージしようとしたら利用可能メモリ24GBでも足りなくてわろたわ
>>857 1111で完結させたいならimg2imgのインペイントへ送って隠したいところを塗って
インペイントを行う領域…マスクのみ(こうすると幅や高さの指定によらず出力画像がリサイズされない)
にしてステップ数を1とかに思い切り下げて生成すればマスクされる
無料のペイントソフトを使うならKritaでもGimpでもPaint.netでもご自由に
>>981 既に狙ってる構図があるなら、パンツにしたい部分をベタっと塗った下絵を食わせてやればゴールに近づきませんかね。
プロンプトだけで狙った絵を作って行くのはかなり難しいですよね。
>>990 いや普通の自作WindowsPC
今でも5万あればDDR5 16GB*4本で64GBは簡単にできるよ
>>981 cotton panties
とかどうでしょう
はいどうぞ
【StableDiffusion】画像生成AI質問スレ7【NovelAI】
http://2chb.net/r/cg/1681091799/ テンプレ載せたら「鍵が無効です」で書き込めなくなっちゃった
このスレへの固定リンク: http://5chb.net/r/cg/1680339324/ ヒント: http ://xxxx.5chb .net/xxxx のようにb を入れるだけでここでスレ保存、閲覧できます。TOPへ TOPへ
全掲示板一覧 この掲示板へ 人気スレ |
Youtube 動画
>50
>100
>200
>300
>500
>1000枚
新着画像 ↓「【StableDiffusion】画像生成AI質問スレ5【NovelAI】 YouTube動画>3本 ->画像>37枚 」 を見た人も見ています:・Blender 初心者質問スレッド Part24 【液タブ】海外製ペンタブレット総合 25【板タブ】 Blender Part66 【仮想空間から】立体出力 総合スレ2【現実世界へ】 【3D彫刻】ZBrush質問・雑談スレ28【3Dペイント】 ▼△▼Autodesk Maya専用質問スレッドPart26▼△▼ 【SFM】Source FilmMaker 【3DCG動画】 さるちん デジタルフロンティアについて 【スカルプト】3D-Coat 7層目【3Dペイント】 pixiv 底辺卒業スレ part128 トミーウォーカー アトリエ★143個 俺の自主制作アニメスレ Painter総合スレ 58筆目 Shade 相談/質問スレッド Ver.41.0 在宅でCG・漫画描いて小遣い稼ごうぜ DL数5 Windowsタブで絵を描きたい人のスレ Part.6 ※絵OK 弟1次液晶タブレット自作・改造技術交換スレッド Expressionの話をしよう part6 【Acrylic】 【目指せ】絵描き初心者スレ【神の一絵】 【専門学校NG】3DCG系の専門スクールってどうなの? Daz Studioスレッド Part23 パククネと安倍昭恵 フォトショ加工しても価値ない おまいら、MacromediaFireworksってどーよ? 【トミー】審査落ちた人かも〜ん50【OMC】 【3Dデッサン人形】 デザインドール 9体目 Blender 初心者質問スレッド Part35 絵描きのtwitterスレ Cintiq】WACOM 液晶ペンタブレットPart105【DT】 Blender Part59 【Midjourney】 AI画像生成 【DALLE】 Terragen ナムコの鉄拳CG>>スクウェアFFのCG そろそろLinuxでCGやろうぜ 6角大王って最強だよな 【StableDiffusion】AI画像生成技術8【Midjourney】 【3D彫刻】ZBrush質問・雑談スレ43【3Dペイント】 MOTIONBUILDER 総合スレッド Part2 3DCG屋による雑談スレ Part27 CG作成依頼スレ pixiv奈落底辺スレ Part77 タブレットで絵を描きたい人のスレ PBWイラスト総合スレ Part2 【賃上げ要求】スト起こさないか?【労働時間短縮】 POV-Ray頑張れ!! トミーウォーカー アトリエ★136個目 ©2ch.net 絵描きのTwitterスレ8 Google SketchUpで作ってみるスレ 4 【在宅】女性誌漫画アシスタント交流スレ【通い】1 絵描きのTwitterスレ3 【pixiv】二次小説スレpart41【novel】 【液タブ】海外製ペンタブレット総合 13【板タブ】 あぁ!?じゃあ一生キーフレーム打っとけっていうのか!? CGソフト セール&お買得情報総合 CG屋がこの先生きのこるには? Daz Studioスレッド Part29 【PMD】MikuMikuDanceモデリングスレ【PMX】 Blender 初心者質問スレッド Part29 トミーウォーカー アトリエ★152 【Maya】Autodesk Maya質問・雑談総合スレPart4 nijijourney使おうかと思ってるんだが 【浜島広平】株式会社イクリエを語ろう【原型制作】 pixiv 底辺卒業スレ Part98 CGの非常勤講師 【セルシス】CLIP/クリップ22 【iPad用】CLIP STUDIO PAINT part3
11:08:15 up 14 days, 12:11, 1 user, load average: 7.48, 8.45, 9.09
in 0.02108907699585 sec
@0.02108907699585@0b7 on 012801