◎正当な理由による書き込みの削除について: 生島英之とみられる方へ:
【StableDiffusion】画像生成AI質問スレ12 ->画像>33枚
動画、画像抽出 ||
この掲示板へ
類似スレ
掲示板一覧 人気スレ 動画人気順
このスレへの固定リンク: http://5chb.net/r/cg/1685519479/
ヒント:5chスレのurlに http://xxxx.5chb.net/xxxx のようにbを入れるだけでここでスレ保存、閲覧できます。
Stable Diffusionをはじめとする画像生成AIに関する質問用のスレッドです。
次スレは
>>950が立ててください。
質問する人はなるべく情報開示してください
・使っているアプリケーション(1111ならローカルかcolabか、ローカルならどこから/何を読んでインストールしたか、colabならノートブックの名前かURLも)や使っている学習モデル
・状況の説明は具体的に。「以前と違う画像が出力される」「変になった」では回答しようがない。どう違うのか、どう変なのかを書く
・状況やエラーメッセージを示すキャプチャ画像
・ローカルならマシンの構成(GPUの種類とVRAM容量は必須、本体メモリの容量やCPUもなるべく)
テンプレは>2以降に
※前スレ
【StableDiffusion】画像生成AI質問スレ11【NovelAI】
http://2chb.net/r/cg/1684577410/ ■AUTOMATIC1111/Stable Diffusion WebUI
https://github.com/AUTOMATIC1111/stable-diffusion-webui パソコン上だけで(ローカルで)画像を生成できるプログラムのデファクトスタンダード。実行にはパソコンにNVIDIA製のGPUが必要
導入方法1
https://seesaawiki.jp/nai_ch/d/%a5%ed%a1%bc%a5%ab%a5%eb%a4%ce%c6%b3%c6%fe%ca%fd%cb%a1 導入方法2
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/ からzipをダウンロードし解凍→webui-user.batを実行
■画像アップローダーや便利なツール
https://majinai.art/ 生成した画像内のプロンプトやパラメータを抽出して掲載してくれる
https://imgur.com/ 2023年5月15日以降はエロ画像の投稿禁止。画像内のメタデータは削除される。1枚だけ上げたときは画像ページのURLではなく画像そのもののURLを書き込もう。例:
 https://www.imagevenue.com/
https://www.imagevenue.com/ メタデータが削除されるアップローダー。エロ可だが児童ポルノは禁止
https://catbox.moe メタデータが削除されないアップローダー。エロ可だが児童ポルノ、未成年者の性的描写、性的暴力の画像は禁止
https://photocombine.net/cb/ 画像を結合できるWebアプリ。文字入れも可能
■FAQ
Q1:ローカル(パソコンで生成)とGoogle Colaboratoryやpaperspaceなどのクラウド実行環境、どちらがいい?
A1:ローカルは利用時間の制限がなく、エロも生成し放題だがNVIDIAのグラボが必要。クラウド実行環境はエロ画像(特に幼児)の生成でBANされる可能性がある
Q2:ローカル環境でパソコンの性能はどのくらいがいい?
A2:グラボはなるべく3060 12GBから。VRAMの容量が大事。CPUの性能はほどほどでよい。本体メモリはなるべく32GB以上。学習モデルを置くストレージはNVMe SSDのような早いものにするとモデルの切り換えにストレスが少ない。本体の置き場所と画像の出力先はHDDでもよい
Q3:NMKDと1111、どちらをインストールしたらいい?
A3:NMKDはインストールは楽だが機能とユーザー数が少ない。1111がおすすめ
Q4:画像を出力したら色が薄い、または彩度が低い
A4:VAEが適用されていない可能性がある。1111なら設定(settings)-UI設定(User Interface)-クイック設定(Quicksettings list)に「, sd_vae」を追加するとVAEの切り換えが楽になる
■AUTOMATIC1111版Stable Diffusion WebUIについてのFAQ
Q1:自分の環境で使える?
A1:利用は無料なのでインストールしてみるとよい。インストール方法は>2参照。省メモリの設定は以下を参照
https://seesaawiki.jp/nai_ch/d/%a5%ed%a1%bc%a5%ab%a5%eb%a4%cewebui-user.bat Q2:起動時の初期値や数値の増減量を変えたい
A2:1111をインストールしたフォルダにある「ui-config.json」を編集
Q3:作りすぎたスタイルを整理したい
A3:1111をインストールしたフォルダにある「styles.csv」を編集
Q4:出力するごとに生成ボタンをクリックするのがわずらわしい
A4:生成ボタンを右クリックし「Generate Forever」を選択。バッチと異なり出力中にプロンプトやパラメータを変更可能。止めるには生成ボタンを再度右クリックして止める
Q5:アニメ顔を出力したら目鼻がなんか気持ち悪い
A5:「顔の修復(restore faces)」をオフにする。「顔の修復」は実写の顔の修復専用
Q6:設定を変更したのに反映されない
A6:設定変更後はページトップの「変更を反映(Apply)」ボタンのクリックを忘れずに。「再起動が必要」と書かれていても「UIの再読み込み(Reload UI)」ボタンのクリックですむものも多い
Q7:消去したプロンプトがまだ効いている気がする
A7:報告は多数ありおそらくバグだが、確たる原因や解消方法はわかっていない。影響をなくすにはWebUIの再起動や、まったく別の画像をPNG Infoから読み込んで再生成するなどが提案されている
テンプレは以上です
(Clip Skipのは質問が出たときに書けばよいでしょう)
AI板の設置希望は出ているがどうなるか?
こんな板が欲しい 【新板申請所(正式)】 ★5
http://2chb.net/r/operate/1608946847/145 インストール中ですが、1時間以上たってもここから動かないです
カーソルは点滅してますが、正常なのでしょうか

>>7 そのcmd窓をクリックしてenter押したらどうなる?
健全・微エロまでは綺麗なイラストできるのにR-18イラスト作ると急に破綻するんですけど改善方法ありますか?
モデルごと変えるとかプロンプト変えるとかsampler変えるとかで対処できますか?
>>8 何も変わりません
一回cmd閉じてもう一度bat叩いてみましたがmodel loaded in 3.3sで止まってしまいます
カーソルは点滅してます
LoRaで学習したリアル女完璧に反映できた
これ元々入ってるモデルが凄すぎるって話なんやろな
やりたかったこと2日で終わった
あとは優秀なモデル集めまくってシチュ変えて遊ぶくらいしかないなw
>>11 そんな時間かかるわけないので、×で一旦閉じて
もう一度起動したら、あるものない物ちゃんと区別しながらやり直してくれる
壊れたりしないから心配せずにGO!GO!
ああごめん、ちゃんと読んでなかった・・また止まるのか、上のなし
インストールで詰まるようなところあったっけかな
まじでなにも覚えてない…
もうSDのフォルダできてんじゃない?
意図する画像生成できるようになったし俺もマネタイズしたいなぁ
>>11 今回初インストールなのか久々なのかとか不明だけど
一旦venvフォルダ丸ごと削除して、stable-diffusion-webuiの上でcmd(管理者)立ち上げてgit pull叩いてから起動したらどうなる?
既存のモデルの上に自分の重ねるだけだけどすごいね、あと質感リアルにしていったら本物と見分けつかないやろねこれ
文章の途中にURL出てきたのでやってみたら普通にできました…
なんだったったんだろう
ありがとうございました
VAE初導入したレベルの新人ですがよろしくお願いします
呪文が書かれてるdiscoって、私のような新参でも入れるものなのでしょうか?
chilled remixとreversemixって何が違うんだ?
>>22 何か知らんけどできてよかった・・上のところで止まってたわけじゃないのか
discordってみんなやってるの?知らんけど
呪文はcivitaiのパクるのが一番手軽な気がする
Loraやモデルも転がってる上、嘘偽りやプロンプト情報欠落(隠し)が比較的少ない
例えば
https://civitai.com/models/9942/abyssorangemix3-aom3 このモデルをダウンロードしてmodelのstablediffusionフォルダに突っ込んでwebuiの更新マーク押して選択
好きな画像をPNG Infoにドラッグアンドドロップして、send to txt2img押してgenerateしてほぼ同じのができるか、とか
あとは自分であれこれ変えてみたりして研究していく
あともうやってるかもしれないけど
https://yuuyuublog.org/quicksettings-list/ ここの「Quicksettings list」は必須なんで設定してね
>>25 設定できました!
ありがとうございます!
civitaiも見てみます!
リアルに近い幼女のモデルって、今は何が主流なんですかね?
chilloutmixなのでしょうか?
画風LoRaと二次創作キャラLoRaの作り方の違いはあるのでしょうか?
学習元に同じ画風のキャラ絵を入れていけば画風を再現できるLoRaになって、
画風は違っていても同じ服装・髪型のキャラ絵を学習元に入れていけば、二次創作キャラを再現できるLoRaになると思ってます
31337ってあるのとないのと
クオリティ変わってるのかイマイチわかんないなー
どうなのこれ?
control netでの衣装差分の作り方が乗ってるページとかありませんか?
>>28 ENSDはクオリティには関係ない。サンプラーのシード値。
初期値0でランダムになってると、生成画面で通常のシード値を入れてても微妙に違う画像になる。
31337はNovelAIに合わせてある。
やばい、これハマるな
頑張って好きなグラビアを着せ替え生成したい
ずっと生成してたら勝手に二人描写されるようになってしまった。1girl,solo入れても二人描かれる。
Loraも入れてないし何も設定変えてないんですが原因わかる人いるでしょうか?
プロンプトにblack hairとか適当追加したら変わる場合ある
プロンプトに変化がないとバッファしてるからパラメータいじっても変わらん気がする
チルアウト2
ローラ使ったら簡単にできる
でも服の着せ替えは難易度高い
>>35 本当に設定も生成サイズもいじってないならプロンプトに問題があるだろうとしか言えない
ローラで1人のいろんな表情で学習したら生成化け物になるな…表情はほとんど変わらない方が出力いいね
>>35 512*768比率以上に横幅広いと高確率で複数お生まれになるよ。
Lora使って作成したのを保存
→PNG情報読み込んでシードも変えないで生成
→最初のと構図・絵柄似てるのができる
で、
lyocorisの拡張入れる(safetensorsとかは入れない、ただ拡張機能入れるだけ)
→上と同じことやると構図絵柄全然違うのができる
→拡張を無効にするともとに戻る
これっておま環?原因あったらお教えを・・・
Batch countを変更したいんだけどどこいじったら変わりますか?
一気に1000枚くらい出力したい
>>32 そうなんだ
それじゃ実写系はあまり関係ないかな?
>>42 > lyocorisの拡張入れる(safetensorsとかは入れない、ただ拡張機能入れるだけ)
ちなみになんて名前の拡張?
a1111-sd-webui-loconは最新に対応してなくてぶっ壊れてるので使わない方がいい
a1111-sd-webui-lycorisが後継とのこと
>>43 ui-config.jsonで最大数その他が変えられる
>>47 a1111-sd-webui-locon
a1111-sd-webui-lycoris
両方入れて両方有効にしてた・・・
loconは公式にも使うなって書いてあるんだな。
とりあえずlocon無効のままlycoris有効にしてみるわサンクス
>>44 実写系もアニメ系も関係ないよ。
投稿サイトなどに載せられている呪文やパラメータをコピペして
同じ絵を出したい時にはここの値も相手と同じ値を設定してやらないと全く同じにはならないって事。
自分で好き勝手に生成する場合は意識する必要はない。
解説サイトか動画でここを設定しろと言われたのだろうか?
意図を完全に勘違いしてる。
>>44 ①StableDiffuionは拡散されたノイズからディテールを抽出するソフトウェアで、絵を描いている訳ではない

gigazine.net/news/20220914-stable-diffusion-illustrated/
②seed値は最初に配置するノイズのパターンを指定するID番号でしかなく
③なので品質とは特に関係ない(seed値が同じでもPromptや設定値を変更すると全く違う絵になる)
from belowで、下からのアングルにすると
顔が影になった写真ばかり生成されちゃうんだけど
正面から光を当てるようなプロンプトって無いですかね?モデルは実写系です
front lightとかやってみたけどほとんど効果無し
実際に画像を掲載してここをこうしたい的な相談ができるところってないかな?
アウロリ系統だからTwitterやここじゃ相談しにくい
いいディスコとかないかな
ディスコでなくてもいいんだけど
>>50 理屈はそうだけど成果物としてはやっぱりただの画像ファイルだし絵だよな
Dynamic Promptのwildcardって新しくファイル作ったときにWeb UI再起動しないと反映されないけど、
色々調整しながら毎回再起動するの時間がかかるので何かいい方法ないですか?
wildcard managerで行けそうな気がしてきました
>>52 >>5のエロ2つかな
なんJよりはbbspinkの方が親身になってくれそうな気がする
>>51 今やってみたけど別にならないような・・顔が影になってるって程度も個人差あるだろうし
モデルと顔が影になってる簡単なプロンプトとseedでも上げてくれたら一番回答しやすいと思われる
>>57 自作のLoRA使ってるんでシードとプロンプトを使っても同じにはならないんですよね
プロンプトと出来る画像はこんな感じですが
(masterpiece), (best quality:1.2), (ultra hi-res:1.2), photo realistic, 1girl, (head:1.2), bob cut, short hair, choker, shiny hair, bangs, black eyes, sitting, (face from below),(smile:0.7)<lora:NiceBobCut_V2:0.55> <lora:saturation:0.2> <lora:lit:-0.1>
easynegative, (low resolution:1.2), (worst quality:1.3), (low quality:1.3), normal quality, (pale face:1.2), (head out:1.2), lower eyelashes, DepthField, shiny skin, navel, hip

あ、モデルはV08aです。正式名称は中国語だと思いますが「?特稀」。これ文字化けしないかな
>>54 「ワイルドカードの管理」タブ、「ワイルドカードの一覧を更新する」で更新できるよ。
・・・と、言って確認しようとしたら、うっかりWebUIアップデートしたからか、
今は一覧すら表示されてねぇw
いやぁ・・・アップデートもう少し待つつもりだったけど、
ひとつ拡張入れてしまったのがまずかった。
すみません誰か教えてください
https://imgur.com/Lh6iSoO こういういわゆるアジア系クール美人を生成したいんだけど
ベースのモデルはChillout系で、LoraはKoreanDollLikenessで方針合ってますか?
どうしても目が切れ長にならなくて困ってます
>>58 Lora全部なしで試したけど、確かに顔が影になりやすいモデルっぽいね
ネガに(backlighting:1.6)とかでどうだろ?
>>61 間違ってる
これは所謂2.5次元系のモデルだ
>>61 画像だけでモデルやLora当てるのは不可能かと・・
実写系モデルにアメリカの有名イラストレーターを混ぜた感じの吊り目に見える
>>62 確認ありがとうです。やっぱりモデルの特性なんですねえ。最近こればっかり使っていたので麻痺してました。
backlightをネガに入れるのもいろいろ数値変えて試してみたんですが影響なかったです。
最終手段として、グラフィックツールで顔に明るいところを塗って、それを元にi2iで出力してみましたが、それでも顔に光が当たらないですねw
どうも教師画像がかなり偏ってるモデルみたい
https://imgur.com/a/1n4exzU >>63 に、一票。マージはしてるかもしれないが、
Chilloutの要素は限りなく薄いと思う。
あー、実写系とイラスト系をマージってそういうやり方もアリなんですね
目から鱗です
それで2.5次元系になるのか
レスありがとうございました
試してみます
ずっと生成してたら勝手に二人描写されるようになってしまった。1girl,solo入れても二人描かれる。
Loraも入れてないし何も設定変えてないんですが原因わかる人いるでしょうか?
anything使い続けているけど
たまに色が抜 モノクロになるけど、唇や乳首が赤いまま残る現象が起きる
VRAM4GBの限界時に発生するのかな?
肌の色を浅黒くしたら服が黒色になるんですけど、
色んな色の服と指定するのは出来ますか?
>>54 Setting -Dynamic Prompts - Automatically purge wildcard cache on every generation.
をチェックでだめ?
三次画像に二次キャラをinpaintで入れるとか難しいのかな
二次キャラを生成して後からコピペで貼り付ける方がマシ?
最近始めたばかりです。
一回の生成で複数枚作るにはどうすればいいですか?
色んな画像を一度にたくさん作りたいです。
そんなレベルの人が見るべきサイトとかも教えてもらえるとすごく助かります
>>76 ママと一緒に生成してみたら上手くいくと思うよ
huggingfaceで検索してるとたまにsafetensorsファイルがないものがあるけどどこにあるのかな?
BRAv5を落とそうと思ったがそれらしいファイルがなかった
解決したならもうURL書かないけど、
初心者はグーグル検索もしないの?名前までわかってるなら一発で出て来るんだが。
あと、まぁCivitai位は知っといた方がいい。
プロンプトってちょっと変更したら
すぐに反映するのとしないのってあるけど
これってモデルによるのかな?
でもしつこく生成してると
だんだんと反映するのって
裏で学習してるもんなの?
この辺りわけわからん
SDで作ったイラストをMajinAi投稿したんだが、以前は投稿できたのにここ数日作ったやつはプロンプトが表示されす非対応で投稿出来なくなったけど何故だろう?以前作ったやつはプロンプト表示されるのに。不思議だ、
>>76 煽りは無視して困ったらまずググれば色々出てくる
初心者向けの解説してるサイトもある
何でも聞けば良いと思うが本当に何でも聞いてはいけないよ
controlnetを導入しようとしているのですがうまくいきません
解説サイトの通りにインストールしようとしてもAssertionError~と表示されて失敗してしまうので何度か再起動→インストールを繰り返していたところ、
いつのまにかInstalledに追加されていたのですがtxt2imgの項目にcontrolnetが表示されません
解決方法を教えていただけないでしょうか
85だけれど、今civitaiに投稿したけど、やっぱり内容情報は表示されない。SD設定の「生成に関するパラメータをpng画像に含める」はチェック✅になってます。
>>87 settingsのcontrolnetの設定で
「Multi ControlNet: Max models amount (requires restart)」
を2にしたままverupして昔そんな感じになった
1に戻してチェック外して再起動してチェック入れて再起動したら治るかも
初LoRaですが、生成したsafetensorsファイルを呪文指定しても学習してるようにみえないです
素材1、バッチ2、エポック10、リピ10設定ですが、皆さんどのくらいの設定でやられてますか?
呪文は花札から生成したものをそのままコピペしてます

controlnetのImageを大きく表示する方法ないですか?
サイズが小さすぎてInpaintで黒く塗りつぶすのが難しいです
>>93 拡張機能にcanvas-zoomというのがあるので
それを入れれば
>>95 あ、ごめん。嘘書きました。
control netには効かないや
>>93 コントロールキー押しながらマウスのホイールぐりぐりするとかは?
モデルデータに「bakedVAE」がつくものがあるけどメリットって何?
あとでVAEの演算をしなくて良い分時間が短縮されるということ?
loraの素材はみなさんおいくつ入れてます?
総ステップ数も目安として教えてもらえると嬉しいです
>>90 ありがとうございます
ただsettingの項目にもcontrolnetがないんですよね…
>>76 ・バッチ回数を増やすとその枚数がまとめて生成される
・バッチサイズを上げてもいいがそのぶんVRAMを食うようになるから2とか3くらいから
1枚あたりの生成時間が少し短くなる
・生成ボタンを右クリックし「generate forever」を選ぶとずっと生成し続ける
生成中にパラメータを変えることもでき、次の生成から反映される
止める時は生成ボタンをもう一度右クリック
解説本も出てるから読んでみるといいよ
>>98 モデルにVAEが含まれているのでわざわざ指定しなくてもいい
でもそうでないモデルと切り替えながら使うと、VAEを指定したり外したりで面倒になりそうだけどどうなんだろうか
>>102 なるほど、初心者の俺は
vae-ft-mse-840000-ema-prunedだけ使ってるからとりあえずこれでいいかな
bakedあるなしでどれくらい速度が変わるんだろうね
>>97 その手のブラウザズーム解決方式でなんとかするわ
ありがとう
>>102 設定に指定のVAEがあるならそっちを優先するみたいな項目無かったっけ
チンポってどうやって安定させるの??変な形ばっかり
初めて3日目の初心者です。
もう少し実写に近づけたいのですが、アドバイスいただけないでしょうか?

BRAv5、84vae、loraで500ステップほど追加学習した画像です。
その質問するならこれも答えろという項目あれば、それも教えてもらえると助かります。
>>98 「bakedVAE」はVAEもモデルとに一緒に入れてあるってこと、つまりVAEを指定しなくても作者指定のVAEを使ってくれる、つまり早くはならない
ちなみにチェックポイントのマージ機能を使えば自分でも好きなVAEを一緒に焼けるよ
ちなみにVAE使わないってのは学習されたVAEを使わないってことでVAE自体は使ってるから
計測したことないけど使わなくてもほとんど早くならないと思うよ
そもそもVAE使わないと最後の段階で2次元画像にデコードされないはずだから
>>108 やってることがどういう意味を持っているか無自覚なアホさを見直してからまた来るといいと思う
AI生成の炉って法に触れるのか?
結局のところ絵だし被写体も実在しないのであれば法的に問題ないのでは?
どういう人生歩んできたら問題ないと思えるのだろう。。。
実在の人物を学習させたAIロリ絵は逮捕される可能性は有る
>>115 法に触れなければ何やってもいいと調子こいてると社会的な死が訪れる
ミクロでは個人
マクロではコンテンツ
現時点で法整備がされてないから今うpしても大丈夫だけど、いずれ法整備来るだろうから今後アップロードはやめといた方がいいね
>>115 法には触れないがやりすぎて法律できる可能性がある
基本的に、「やり過ぎ」→「規制」の文化だから十分にありうる
続けたいならこっそりやるのがいい
4060、どうなんだろう
生成が爆速になるなら検討したい
検証動画まだかな
4060の値段次第だが3060(12GB)で十分だと思われ
4060はなあ
万が一16GB版が出たとしても、128bitなのは不変だわ高くなるわで3060 12GBへの優位点が……
3060使ってる人はLORAファイル作るのにどれくらいかかってるの?
俺1時間くらいかかるんだけど
ロリコンの定義をちゃんと理解せず他者を糾弾するアホが多いこと多いこと
ネトウヨのチョン認定並みにガバガバだな
人間って俺は私は○○が気に入らない!という感情をモラルや倫理というオブラートに包んで正義感ぶりたがるよね
>>125 1つなら30秒かからんだろ
512×512の場合だがw
こっちはテクノロジーに詳しい理系寄りの人がいるからか比較的冷静だな
イラストレーター板とツイッターは感情的になりすぎて頭がおかしくなっている輩が多くて呆れる
己の感情すらコントロールできないアホは心療内科に行け
>>128 最後の行を自分で100ぺん読んでからこのスレに書かなければいけないことだったかを考え直そう
>>129 ちょっとスレチでしたね
すみません自重します
ただ病んでいるほど感情的じゃないですよ
ちょっとどころか完全にスレチ
荒らさないでくれないかな
もうこの話終わりにしよう
>>122 何故4060で爆速になると思ったのか
16GBでも3070程度らしいじゃん
>>131 生成だとそれこそ条件によって全然違う
条件出さないとお話にならない
じゃあ素材3、batch1、エポック20、リピ10で
ここが質問スレであることをわかってないお前も相当アホだからね
SD初めて2ヶ月くらいたったけど未だに同じmodelでの顔の描き分けはできない
Counterfeitやanything系の2次メインだけどつり目やたれ目すら効果が見られない
顔かえるなら強引に生首LoRA使うしかないのかな
上手く描きわけできたっていうブログとかSNSアカあったら教えてください
縦横のサイズを入れ替えるボタンが消えたんだけど
拡張機能だと縦横ボタンでないんだな
どこにあるのかわかる?
hires出力した画像を、縦横に拡大(描画)したいんですが
Controlnet Inpaintとかで一発でやる方法ないですか?
今だと編集ソフトで余白を作ってから、inpaintしないと無理ですよね?
新しい4060(16GB)よりA4000(16GB)の13万でよくね?
アスカで28秒とかだから結構いい感じに見える
>>100 チェック外すんじゃなく、完全に削除して入れ直したらどうなる?
SDフォルダのextensions以下のcontrolから始まるのは一旦全部削除
勘違いしているかわからないけど
LoRAも何も使っていない状態で、modelデータを色々なプロンプトを使って生成しているうちにそのmodelデータは学習して何か変化してるの?
>>145 しない
モデルは出力専用
そんなことで中身変わったら逆に困るわ
4070買うか、7月に出るっていう4060 Ti 16GBが出るまで買うの待つか今めっちゃ悩んでる
3DMarkのスコアとかだと4070のほうがちょっと上ってことになるんんだろうと思うんだけど
画像生成的にVRAMの+4GB分ってどれくらいのアドバンテージになりますか?
>>146 モデルデータと学習という文字がセットでスレ内で出てくる時に、もしかしてそういうのがあるのかなと思ったから安心したわ
LoRA作る時は人物名を姓名で別けてトリガーにするより1ワードにした方が良いのかな?
>>147 何を重視するかによるんじゃない?
VRAMいっぱい使うことしたいなら16GBだし、生成速度重視ならおそらく4070だろうし。
急いでないなら4060出てから考えてもいいのでは。
初心者質問宜しく申し訳ありません。
複数lora入れて生成すると、画像は破綻してしまうのでしょうか?
学習前に単語をプロンプトに入れてみて生成になるべく影響出ないワードにした方が良いんじゃね
>>151 そのまんま複数loraが混ざった画像ができるよ
アニメ絵とリアル絵で回答も変わるのがあるはずなのでどちらか書くべきでは?
姓名くっつけて一塊にすると他と被る可能性も減っていいのかなと思ってる
>>151 別に複数のLoRAを指定しても大丈夫だよ、というかやってみればわかるよ
回答ありがとうございます。
複数入れて生成すると、画像がすべて人物にしろ背景にしろぼやけ気味感じにしかならず背景もネオンの都市みたいな感じになりました。
一個ずつ試したら綺麗に生成されているので、互いに影響する感じなのかな?と思いました。プロンプト変えて色々試してみます。ありがとうございます。
>>157 そういうのはLoRAの数字が合計で1になるようにすると少し良くなるかも
ただしその分各々が薄れるからそこもしっかりやるならBREAK構文を使うregional-prompterとか
>>150 回答あり。わりとすぐ欲しくて今すごい悩んでるのよなw
VRAMいっぱい使うことかぁ
https://chimolog.co/bto-gpu-stable-diffusion-specs/ このブログによると解像度あがったりしてもどうもVRAMでそれほど生成速度変わらなそうということみたいだけど
そもそもどういう処理にVRAMがあると有利なのかってのが画像生成ちょっと試してみましたぐらいな自分の知識だと
わからんのよね。
上のブログで追加学習のベンチマークとかはないようだけど、追加学習とかだとVRAMの差がでてきたりするのかな?
>>159 VRAM足りなくて出来ないことはある
処理速度の差で出来ないことは無い
どっちが良いか選んでどうぞ
しつもんです
webui A1111をローカルで使ってますが、xformersやpytorchを何度アップデートしてもA1111クライアントに反映されません
生成やLoRA試作はできてますが、どうしても気になったので質問します
画像をみてください。この1時間で最インストールと画像を撮りました。全部最新です
webui ロード画面

webui クライアント下部

lama cleaner

reinstall xformers
reinstall torch
2度やりました
chatGPTに聞いて
pip uninstall xformers
pip install xformers==0.0.19
pip uninstall torch
pip install torch==2.0.0
を1か月の間に2-3回試しました
lama cleanerには反映されています
CMD pythonコマンドでも反映されてるっぽいです。どうすればいいでしょうか?

reference only使えばアイコラも楽勝みたいな動画見たけど、全然思い通りにならないな
生首だけなら似た顔作れるけど、それをtaggerとreferenceやopenposeと組み合わせると、出来上がりが全然違う仕上がりで嫌になる
>>163 これ書くのもう何回目かだけど、pipコマンドの手打ちはvenv有効にしてからでないと意味ない
とりあえず、
>>164 の言うように一度venv消せば解決すると思う
あるいは、スクショに書いてある通り、webui.batのコマンドライン引数のとこに--reinstall-torch と書き足して起動する(うまくいったら消しいい)
1111環境で出力ファイル名を「日付-連番-seed名」に変えたいんですが、設定画面では出来ません
設定ファイル編集とかで出来たりしないですか?
>>169 連番をファイル名の途中に入れることはできないんじゃないかなー
環境や目的によるのは承知で聞きたい
みんな素材は何枚使ってる?
キャラloraに公式絵70~100枚
こんなにいるのかは知らんけどまあ満足いく再現度にはなってる
>>169 [seed](.png|.jpg|.webp) -> YYYYMMDD-4桁連番-[seed](.png|.jpg|.webp)
1. ファイル名設定を[seed]にしてAI生成する。
2. スクリプトを画像のあるフォルダーにいれる。
3. スクリプトを実行する。
バグがあるかもしれないのでバックアップを取ってから試すこと。
https://2dat.net/5ch/ai/pnginfo/static/date_seq_seed.zip >>170 やっぱ無理なんだ、ありがとー
>>173 ありがたいけど、それならファイルリネームソフト使います
data-set-tagediterという拡張機能がタブから消えました…
解決方法はありますか?
再インストールしても表示されず困っています
>>176 StableDiffusionがVer1.3に上がったらエラー出るようになったぽい
配布元でも不具合出てるって話が上がってて原因特定をユーザー間でやってる感じだけど、製作者さんの反応はまだ無さそうかな?
自分は幸いStableDiffusionの古いバージョンが残ってたからそっちで騙し騙しでやってる
スタンドアロン版っていうのを使えればStableDiffusionのバージョンに影響されないそうだけど、使い方がよくわからないから自己責任になってしまう
>>177 不具合ですか、ありがとうございます
これないとタグ編集できないので古いバージョンに戻すしかなさそうですね…
>>176 data-set-tagediterはpull requestsに修正されたのがあるとかなんとか言ってた
キャラローラ作ってるんだけど色々なポーズとか
表情を
学習させた方が良い?バトルで負けた時の破れ衣装なんかも一緒に学習
させても良いものなのかな?
自分で作った経験上はポーズも表情も学習させてなくてもプロンプトでちゃんと変えられたからなくても大丈夫だと思うけど
学習素材があるなら学習させたほうがいいんじゃないかな
これから、1からAI画像生成を始めたいです。
既に亡くなっている好きな漫画家の方がおり、その方の1話完結の短編集が好きで、
その漫画を学習させ、その作風で新たなエピソードを作成したいです。
勿論、一切営利目的には使わず、他者への公表もしません。自分で楽しむだけです。
上記の目的に合うソフトがありましたら、ご教示下さいm(_ _)m
>>183 エピソードとか無理だよ
今は画風しか学習できない
エピソードを考えさせるならChatGPTの領分だな
まだAGIとかいうのは完成してない
>>183 Stable Diffusion 2.0なんてどうだろう
>>183 釣りかもしれないが現時点でそんな高性能なAIは存在しない
50年ぐらい経てばできるかも
regional prompterの使い方を勉強してみようと試したが異形しか生まれないw
なかなか難しい
>>182 なるほど。もう一ついいかな?
装飾品とかは遠景で詳しく描写されてないものも
逐一学習させた方が良い?それともアップで
詳細まで
描写されてるものを厳選して学習させた方が良い?
エピソードなんかとっくに出来てるじゃん
著名作家風に、といえば出来るよ
>>183 現時点の技術では画風を似せる事は出来ても破綻があって
漫画レベルの細かい構図を狙って出す事は不可能
とりあえず手直し出来る画力とガチャに膨大な時間を掛けないと漫画は無理
自分で描いた方が早いと野暮な事は言わないとすると
まずはloraを作成してみようか
エピソードやセリフはChatGPTで考えて、コマ割りとラフは自力+ChatGPT
最終的にモノクロのloraで仕上げならわりと出来そうではあるが
てかサイバーパンク桃太郎はもう売ってるけど作り方それに近くなかったっけ
出来の良い画像をほかの部分を一切変えずに微調整を繰り返すことは可能?
例えば可愛い女の子ができて、手の姿勢だけ変えたいみたいな場合よ
しかも後ろの背景に関して変わるようなことがあれば補完するとする
>>194 img2imgのinpaintでええんちゃうか
183です。
皆様ありがとうございます。無知すぎて申し訳ないです。
ストーリーをチャットGPT、各コマの絵をStable Diffusion 2.0で(lora適用)、ちょっと考えてみようと思います。
>>195 リアル調の絵でもできる?アニメ絵は興味なくてね......
ドラえもんのまんが製造箱みたいなものもそのうち出来そうな気はするが、今は無いな
t2cやt2fもそう遠い未来ではないんだろうなとは感じる
やりたいのこれっす
微調整を繰り返し勝手にやってくれてそれっぽいアニメーションになる
手の動きも細かい制限かける
腰より上にあがらない、手のひらき具合は60度とか
>>190 検証したことはないけど学習させるものが小さいと良くないみたいな話は聞いたことはある
アップで詳細に書かれているものを厳選した方が再現度はあがると思うわ
>>197 >>200 アニメ絵でも実写でも関係なくできるけど、
特にその動画レベルの話はいろいろ段階を踏まないといけないから
多分ここでそうやって1から聞いてるレベルじゃ理解できないと思う。
動画にかぶせるんじゃなくゼロからアニメーションさせるなら、まずアニメーション学ばないとな・・

>>200 おじさんが自分の手を撮影してごにょごにょやってたの思い出した
>>195 が書いてくれてるのに、
>>196 の返答って
デフォで入ってる inpaint も知らない位、まともに触ってないのわかるじゃん。
じゃ、Controlnetとか話してわかるのか?って話よ。
NovelAIじゃあるまいし、プロンプト、コピペしてクリック一発でできるような事は何もないよ。
目的を高く持つのは大事だけど、自分の能力考えてから言いなさいよ。
できるけど、君には無理。以上。
気持ちよく謎マウント取ってるとこ悪いけどそれ別の人じゃね?
>>204 え・・?
ちょっと聞きたいんだけど、そもそもSD触ったことある?
>>197 「stable diffusion inpaint」でgoogle検索してみよう
>>200に関しては
「stable diffusion ボーン」で検索するとおそらくお目当ての情報が出てくるよ
>>204 マジレスするとプロンプトだけでできるよ
がんばれ
>>194 ぶっちゃけ現状では手書きで修正したほうが手っ取り早い
>>208 レス先間違えてるだけ。
流れ見たらわかるだろうとわざわざ訂正してない。
マウントも何も何で逆ギレされないかんのだ。
LoRaの素材ファイル、例えばキャラlora呪文だけ事前に決めたワードをまとめて自動で消す方法ってないかな?
毎回ブラックヘアー消すの面倒になってきた
>>214 タガーで作った複数のtxtファイルから一気に決められたタグ消したいってことでいいんだよね?
PoweShell使っていいなら、親フォルダに例えば extags.txt とか作って消したいタグをカンマ区切りで1行で書いて
ls *.txt | %{$e=((cat ..\extags.txt) -split "\s*,\s*")}{((cat $_.Name) -split "\s*,\s*" | ?{!$e.Contains($_)}) -join ", " > ("__" + $_.Name)}; ls *.txt | ?{$_.Name -match "^__"} | %{mv -Force $_.Name ($_.Name -replace "^__","")}
これコピペして素材フォルダ(タガーで作ったtxtファイルあるフォルダ)でPoweShell立ち上げて打ち込めば消してくれるはず(__で始まるファイル名使ってない前提)
あってると思うけど違ってたらすまん
イメージブラウザが1ヶ月以上動作してないんだけど、誰も使ってない?
そのうちバージョン噛み合って動くかと思ってたけどタブから消えてそのまんま
似たようなextensionないかな
>>216 ちょいちょい使ってるけど動くよ
https://github.com/AlUlkesh/stable-diffusion-webui-images-browser.git 初回はなんかリロードアイコン?みたいなの押さないと画像読み込まれないけど押してる?
ただ、使い勝手悪いからEagle使ってる
>>217 設定で「Preload images at startup for first tab」にチェック入れれば最初から読み込んでくれる
>>216 infinity image browseのほうが俺は使い勝手いいから乗り換えた
>>217-218 なるほどサンクス
試してみますわ
>>179 pull requestsを覗いてみて、最新版でもdata-set-tagediterが動くようになった!ありがとう!
https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor/pull/80 scriptsの中にある「ui」フォルダが干渉してるらしいから、リネームしてねって事みたいだね
scripts/main.pyファイルの中で「import scripts.ui as ui」→「import scripts.tag_editor_ui as ui」に修正
scripts/uiiフォルダを「tag_editor_ui」にリネーム
って手順で治った
手動修正だから自己責任だし、製作者が最新版を配布したら入れ直さないといけないかもだから注意かな
>>207 お前は1秒ちょっと前の他の人へのレス読んで理解して返答まで出来ると思ってるのか?
しかも4時間経ってレス先間違えてるとか謎な話してるし訂正してないなら間違って無いんじゃないか
しかも指摘を逆ギレと勘違い
凄いよ
まぁ今絶賛センシティブな分野の関連スレだしみんな殺気立ってても仕方ない気はするよ・・・
昨夜鉛筆で描いた自作絵をi2iでアプデして
reference onlyで変化させたら
崩れたものばかり生成されたけど
これ上手く表情変化させることできる方法あるの?
モデルもアニメ寄りじゃないとダメなのかな
想像してたAI補助とはだいぶかけ離れたんだが
>>223 表情だけならADetailerの方が安定するかも
顔と認識した部分にしか影響しない
Kドライブ直下にpythonをインストールしちゃったのでwebui-user.batの記述を
set PYTHON= K:\python.exe
としたのですが認識してくれないのか
exit code: 1
stderr:
K:\python.exe: No module named pip
Launch unsuccessful. Exiting.
続行するには何かキーを押してください . . .
とのエラーが出ます。記述違いであったり、まだDLが必要なファイルがあったりするのでしょうか?
>>225 「K:\python.exe」を
「K:/python.exe」にするのじゃ
たぶん
Pythonなら他でも使うこと多いし環境変数でpath通しといてもいいかもね
LORAを整理してるんですが、花札の表示について質問です
例えば、「アニメ」フォルダ内に「女性キャラ名」フォルダを用意すると、「アニメ/」タブと「アニメ/女性キャラ名/」タブが表示されます
「アニメ/」タブだけ表示させるような表示制御って可能でしょうか
本当にK直下にpython実行ファイルをインストールしてるなら
再インストールを薦めるんだが
>>225 >>230 の言うようにK直下にPythonを入れるのはだいぶ違和感があるが
まあとりあえずで言うなら、バックスラッシュは問題ないけど、「=」の後のスペースがまずいんじゃない?
自分の環境でやってみたが「/」でも「\」でも「\\」でも「頭にスペース」でも動く
本当にK直下にpython.exeがある?
>>232 確かに普通にインストールしたらいきなり直下にexeあるとは思えんな
AIの進化ってもっと早くても良いと思うんだがどう?
今でも動画作れるんだろうけど
生み出した絵ベースで人間含め全て小物が動くみたいなとこまで行って欲しい
それも短時間で作れるようになってほしい
そうなるには後何年くらい?
>>234 本当の現場は凄いことになってるけど俺とかお前の庶民のラインには届いてないだけだよ
>>235 本当に?それなら映画とかでお披露目されんじゃないの?
>>234 今こんな感じ
すごい時代がきた 「おっさんの映像をリアルタイムで美女に変換する」AI技術が予想のはるか上行くクオリティー - ねとらぼ
https://nlab.itmedia.co.jp/nl/spv/2306/01/news116_0.html >>237 一応補足しとくけど、4kサイズとか出す場合はADetailerは切るんやで
奇形化を加速させてしまう
この拡張は小さいサイズ用と思うべき
なら小さいサイズなら毎回採用したい所・・・・だけど生成時間が伸びるからガチャるときは切った方がいいやろね
すごい効果のある素晴らしい拡張なんだけどデメリットもあるってことで
>>238 ちょっとしたスクリプト書いてマシンパワーあれば
俺らがやってることの延長線上でできちゃうんだもんな
>>225 Pythonが入っても、なぜか pip が入っていないときがある。
(あるいはpython.exe だけコピーしたとか?)
python -m pip uninstall pip
python -m pip install -U pip
あたりでどうだろうか。
現在使ってるモデルの絵柄はかなり好みなんですが、効きにくいプロンプトやLoraがあって悩んでます
他のモデルとマージして絵柄はそのままでプロンプトやLoraを効きやすくしたい場合のマージ方法、比率でいいの無いですか?
内閣府の方針でAI学習の絵柄学習は禁句ワードになりそうやで
自分で使わなくてもバラまけば犯罪ほう助だな
>>242 どういう要素を残したいかにもよるが階層マージとかで試行錯誤するしかないんじゃないか?
プロンプト効きにくいのはネガティブプロンプトが原因のこともあるからその辺もチェックした方がいいかもな
精液の生成が間に合いません
どうすればいいでしょうか
>>246 どうしようもない
俺はマルチビタミン飲んで生産増大させたけど供給が追いついていない
ローラの最適なステップ数を教えてくれ
2500くらいか?
いまいち原理がわかんねんだけどloraって用意した素材を学習してんのになんで元モデルを指定する必要あんの?
元モデルの何かを利用してるわけ?
>>249 「教師画像(教師データ)」と「モデルが作る画像」の差異を特徴として学習してる
用意した絵を直に覚えてるわけじゃないから素材って考え方してるとこの部分を誤解しやすい
なんだか言葉遊びみたいだけどこの部分の理解はLoRAの仕上がりを良くしようと思ったら重要になるよ
初歩的な質問で悪いけど
Stable Diffusion(AUTOMATIC1111)でローカル導入してから
モデルやらインスコしてないのに描画繰り返してるだけでゴリゴリSSDの容量減るんだけど
画像以外でどこで容量食ってるんだろう?
Dドラ に移してDドラからStable Diffusion起動してもなぜかSSDも毎日1G単位で減る
1日100枚くらいしか生成してないんだけどなぁ
>>251 面倒だけどSDフォルダの容量確認→下位フォルダの容量確認で絞っていく
>>251 設定の一番上のAlways save all generated imagesにチェックが入ってるなら作成した画像は自動で保存される
デフォルトではstable-diffusion-webuiのoutputsの中
Windowsなら%TMP%とか%TEMP%の下にも大量に何か作るって聞いたことあるけどCドライブならそれじゃないかな
>>251 どこの容量が増えているのか知りたかったらWizTreeとかで見てみたら
やけに大きくなっているフォルダとかあるかも
起動ドライブのUsers-ユーザー名-AppData-Local-Tempが怪しい
そしてPCを再起動したら空き容量は元に戻るかもしれない
>>252 あーなるほど
アナログだけどそれが分かりやすいかも?
今21Gだからここが増えてるか増えてないかで判断します
>>253 outputsの中見てみたけどまだ初めて5日くらいだから700MBくらいしかなかった
>>254 見てみます
>>251 フォルダの容量表示出来るようにしてスクショでも撮って前後で比較してみれば?
PytorchをアップデートしてUIには
python: 3.10.6 torch: 2.0.0+cu118
と出るようになりました。
ただ起動オプションに
--opt-split-attention
を指定すると
unrecgnized arguments --opt-sdp-attention
と怒られてしまいます。対処法がわかる方はいらっしゃるでしょうか?
ID変わってるかもですが再起で無事に容量戻りました
レスくれた方々さんくすです
>>251 デフォルトですべての画像を保存するようになってるはず それだよきっと
おれも2万枚も溜まるまで気づかなかった・・・
>>260 グリッド画像まで保存するのは余計なお世話だよな
>>258 --opt-split-attentionはデフォルトでONだから書かなくていいと思う
ページングファイルの書き込みかもしれんぞ
これはRAM容量が不足するより前に確保し始められるから
>>250 例えば「バナナを持ってる女の子」を覚えさせたい場合、
「バナナを持ってる女の子」の素材画像を注ぎ込んで覚えさせようとしても、
ベースモデルが、元々「バナナを持ってる女の子」を学んでいなければ覚えないって事?
趣味で絵を描いてるが
クソド下手なので、それをAIでリファインしたらどうなるか試していってる
楽しい
このTinpo-Resurrection-v62_0014というモデルどこで配布してるか分かる人いない?
huggingfaceとcivitai探したけど見つからず
https://majinai.art/i/SQRVM_A >>264 むしろ女の子の絵柄を変えないのであれば
・「モデルの女の子」(基準点となるモデル)に
・「バナナというobjectを持っているというpose」(という追加要素)を差分としてパターン記録しているのがLoRA
という感じ
>>266 自作モデルだと思うわ
他にも似たようなモデル名でepochってついてるしテスト投稿してるんじゃね
Tinpo-Resurrection-SD15-epoch0030
Tinpo-Resurrection-SD15-epoch0070
質問です。PixAI.ArtでモデルをWhimsicalが好みなのですが足がむっちりし過ぎるの、何とかならんでしょうか?
https://imepic.jp/20230604/725760 プロンプト
masterpiece,girl,leotard(white blue),fox ear,fox tail,big breasts,chest opened
ネガティブ(まんまデフォルト)
worst quality, large head, low quality, extra digits, bad eyes, EasyNegativeV2, ng_deepnegative_v1_75t
サンプリングメソッド:DPM++ 2S a Karras
>>268 なるほど・・・コス系で綺麗だから使ってみようかと思ったんだけど配布してないモデルかぁ
他のモデル探してみる
VRAM12GBでも足りないほうなん?
RTX3060 12GB(普通のRAMが96GB/DDR4、Ryzen9 3900XT)で動かしてるけど、
512x768px,SamplingStep50,Upscale by 1.5,Hires step50,Denoising strength0.6,CFG Scale8
の設定だとバッチサイズ1でも10回に1回ぐらいVRAMの容量不足で落ちたり、VAE関連で落ちたりするわ……
Wikiや各種サイトに掲載してるようなVRAM軽減策(コマンドライン引数)
(set COMMANDLINE_ARGS=--no-half-vae --opt-channelslast --opt-sdp-attention --disable-nan-check --opt-sdp-no-mem-attention)
やTiled VAEを導入してもそこまで変わらなかった...orz
CLIP changerとかガチりだすと24GBでも足らんというから技術にハードが追いついてない感
>>262 すみません、
--opt-sdp-attention
の間違えでした。どなたかヘルプを、、、
大きなお乳の谷間に顔をうずめたいのですが
よいプロンプトかステキなロウラはありますでしょうか?
お下品な質問で心苦しいのですが紳士の回答お待ちしております
>>274 batの書き方がおかしいとかじゃ?
batのオプションのとこ丸ごとコピペで書いてみて
牛丼を食べさせたいのですが何か良いプロンプトやlora有ったりしますか?
というか食べ物系難しいのかな?
>>272 --no-half-vae がいらないというか邪魔してる
--xformersを有効化したらかなり快適になった。(それでもエラーは出るけど)
RTX3000台ってπタッチ使えなかったんやね。
>>272 step50って無駄に時間かかるだけだと思うけど
>>272 3060の6GBだけど落ちた事無いぞ
lora3つに512×768の2倍アプスケでずっとガチャしてるが今日1日やっても問題無い
--medvramも入れてみたら?
最初はステップ数こだわりまくったけどスクリプトで色々試して比較して今は15から20で落ち着いたな
>>278 >>281 ちょっと試してみる。
>>280 最初の頃に比較したら、40〜50がいい感じに思えたんや……
Hiers stepsの方を20、30ぐらいに下げてみるわ。
生成60%まではぼやけながらも追加学習通りの凄く良い結果にみえるんだけど、70%超えたあたりからいきなり崩れてしまう
これはLORAが悪いのかな?それとも呪文?設定?
原因にもいろいろありすぎて…
majinaiに画像アップしてリンク貼るとかした方がアドバイスもらえるんじゃない?
便利なサイトがあるんですね
https://majinai.art/ja/i/NZtnQvC 念のため悩みをここにも書いときます
・ポケモンのミミロップ(ピンクの色違い、エロなし)に忠実に近づけたいのですが、人に近づくか、体がばらばらになってしまいます。生成70%まではミミロップlora(outputs)によるミミロップの形が保たれてるのですが、70%以降は保たれません。
・右のモフモフを消す方法
・体の色にあったパンツをはかせる方法
>>286 Denoiseが高い、0.35でいい
アップスケールしてるのにアップスケーラーを使ってないのはなぜ?
Latent系以外でDenoise小さかったら崩れないので試して
これらを先にやってそれでも崩れるようなら2つのLoRAの強度を合計1にする(0.6と0.4みたいに)
>>286 いきなり同時にLora適用させるんじゃなくてまずoutputsでミミロップの特徴出してから少ない値でpopのLora適用させていったら?
popのLoraが悪さしてる場合もあるから
prompt editingで体型に関するプロンプトを管理するのも一つの手だな
基本的に人間の体から学習してるからどんどん人間に寄っていく
爆乳銅像作らせようとしたらおっぱいが常に肌色になって困ったものだったわ
エロ画像だけど見た目が良いのにヘソやマンコが2つになる時が良くあるんだが、どんな対策してる?
その上、マンコの中も変だし
くぱぁとかは指が奇麗に出たのにマンコの中が変とか最悪
どんな呪文使えば奇形じゃなく出来る?
速さ出したいなら1080tiライザーで8枚回しとか駄目なの?
4060なんかより全然早いと思う
拾い画で生成したらアウトだと思うけど知り合いで生成してもアウト?
これで組むだけでけっこう速そう
昔1080tiだけで64枚持ってたな、なつかしい

xformersを有効化になっているか確認できる項目とかありますでしょうか?
一枚の生成時間余り変わっていないんです。。
グラボは3060です。
なんぼタグ付けで残しても(=覚えるなって言っても)、できあがったLoraでは同じデザインのシャツが出まくるんだけど、何が悪いのか・・・
・過学習(顔は大丈夫)
・タグ付けでの表現が悪い、足りない(shirt,collared shirt,jacketとか並べまくってもダメ)
達人ニキたのんます
実行したいプロンプトが溜まってるんだけどいちいち作成完了してからGenerate押すのしんどくて…
複数のプロンプトだけ入れといて自動予約で連続生成してくれる方法ってあるか知りませんか?
prompt s/rにプロンプト全文ぶちこんでgenerate forever
>>299 複数タブを開いておいて、それぞれにプロンプト(それぞれ違ってていい)入力、生成。
いま走ってるやつが終わるまで待って動き始める
メインメモリとか次第だがタブは3-4位までかな
>>300 >>301 おお、ありがとうございます!早速やってみます
>>290 ヘソが2つになる現象はよくあるね ChillOutMix作者のタスクさんも言ってたぞ
ネガティヴに double navel で蹴っとけ
質問です。こういうスタートアップ企業のWebサイトに載ってそうな画風のデータを生成したいんだけど、参考になりそうなLoRAやプロンプトって知ってる?
添付の画像はLexicaで作ったんだけど、もっと自由に大量に作りたくて・・・
https://imgur.com/Uy8jzwx Latent Couple extension入れて、複数人のプロンプト作ってるんだけど、AND を使うと絵が崩壊するんだけど、どうしたらええのん?

>>298 シャツのデザインって柄?形?
同じシャツの教師画像多いとか?
>>307 アスペクト比変えたりしてしばらく回して様子見る
なかなか思ったようにはいかないみたい
このスレで使いこなしてる人
どれくらいで使いこなせるようになった?3ヶ月くらい?
>>291 エロスレなんて有ったんだ?
そっちで聞いてみるよ
>>303 ChillOutMix作者も言ってたのかw
ヘソピはネガティブに入れてたけどDouble Navelも入れてみるよ
ありがとう
>>306 midjourney思い出す絵柄と色だね
https://civitai.com/models/46898/niji3dstyle のモデルと
https://civitai.com/models/57750/tech-startup-illustration-lora のLoraで
women,glasses,reading,books,tech startup illustration,<lora:tech_startup_illustration_v1:1>
ネガ:EasyNegative,blurry
で

さすがにそこまで綺麗にならない・・プロンプトを研究・工夫してくだされ
リアル系でアップスケールすると顔が外人になるんですが
書き込みを増やしつつ日本人顔をキープするにはいい方法はありますか?
Denoising strengthを上げたいのでtileを使っています
花札マーク押したら
AttributeError: 'ExtraNetworksPageLyCORIS' object has no attribute 'get_sort_keys'
こんなん言われても馬鹿にはわからん
どうしたらいいか教えてエロい人
>>304 ぶっちゃけエロ画像ガチャやって
気がついたら英語力が上がっていたら
それだけで儲けものだろう
めちゃくちゃ初歩的な質問なんですが…
lora学習で出てきたエポックごとのファイルってepoch-000001とか000002って数字ついてると思うんですが大きい方が学習強度高いって認識で合ってます?
>>319 そりゃそうですよね
ありがとうございます
自作で数字小さい方が再現性高い時あって混乱してたんですが気のせいですね
来年頃には最大1000くらいの設定を同時にできてそれらが矛盾無いように構成されて
頭の中にある絵そのものが出来るなんてサービスできてほしいな
いいもの作れるとはいえプロンプトとかの知識はだるい
>>310 使いこなすってどこまでのこと?
恐らく入れた時点である程度サイト見ながらやってたらできる気がするけども
>>320 エポック増やしすぎると今度は過学習になって絵が崩れるからその認識は合ってるよ
ちょうどいいエポック数は出力しながら自分で探るしかない
>>287 >>288 ありがとうございます
denoise0.35で落ち着きました
https://majinai.art/ja/i/Ty1DajJ そのような素材入れてないのに、どうしても耳部分のもふもふが肥大化してしまう
元と同じようにするにはどうすれば良いでしょうか。
ちなみに元はコレです
https://gamepedia.jp/pokemon-bdsp/monsters/1023/shiny >>324 学習時のタグが悪いとか?
自動で付けたものそのままでやってない?
>>325 batch from directoryで生成されるファイルですか?
であれば、素材1枚1枚、残したいタグを削除してます。
>>312 横だけどいいね
作例もかわいい
>
https://civitai.com/models/57750/tech-startup-illustration-lora のTech Startup Illustrationってまさに>306のことで笑ってしまった
下はLoRAの作例と同じモデル(SD1.5)、1枚目のプロンプトで1024×1024にhires.fixしたもの



>>326 それなら試しに消したタグを付けて出力してみたら?
耳がおかしいなら消した耳の部分のタグとか
どなたかPostprocess upscaleのやり方分かる人いないでしょうか
R-ESRGAN 4x+ Anime6B二重掛けみたいなことをしているアニメ絵があってすごいきれい
普通にTwitterに黙々と上げてて意図しないものがリツイートされまくって広がって、AIだからAIタグつけろとかチートだとか言われると何かやってて良いのかなと思ってしまったなあ。
>>295 複数枚グラボつけてもSLIしないと意味ないんじゃないかな。
恐らく複数webui立ち上げてそれぞれ別のグラボに割り当てれば同時に使えるってだけで。俺も合計7枚くらいあるけど使い捨て感覚で使う気で1枚しか使ってない。
知らなかったがHOT SPOTが上限まで熱くなってた
105度はやばすぎてファン全開にした
グラボ短期間に壊れたら立ち直れないよまじで
俺はここで伝えられたとおりアフターバーナーでHOT SPOTが80度くらいになるまで落としたよ。
半導体自体の寿命が80度以上越えると劣化加速するから落とした。
安定して出力できた方がいいよね。
>>327 こっちのがたぶん306氏が求めてるのに近いね
これをもうちょっと美麗っぽくブラッシュアップしたらいいのか
標準モデル最近使ってなくてコピーするの面倒だからそれっぽいので代用しちゃったよ
10万以上とかのグラボ買う人はケースとファンにも予算さいた方がいいと思う
電解コンデンサーの寿命は温度で大きく変わるから60度とかで回してるのと80度超えで回してるのじゃ寿命かなり変わると思う
>>333 一回外してグリス塗り直したら?だいぶ変わるよ
遅レスですみません。
launch.py: error: unrecognized arguments: --opt-sdp-attention
と怒られると書いたものです。
webui-user.batの記述は以下の通りです。
----
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--autolaunch --opt-sdp-attention
call webui.bat
---
エラーの原因、何かわかるでしょうか...?
全くAI関係ない質問で申し訳ないんだけど
こんな感じで


線を認識してその外側だけ削除する、外側に向かってシュリンク選択して削除する、選択した色の範囲を認識してそこだけ削除する、みたいな事できるお絵描きor画像編集ツールない?
Kritaもgimpも効果テキスト欄や、ババアの髪色まで消したがるし切り抜きも雑で使い物にならないから
最新の技術とハイスペPCで生成した画像をクラウドに上げなおして
https://play.google.com/store/apps/details?id=jp.co.magichour.android.st 10年前のいにしえのアプリを使ってカスみたいなスペックのスマホで切り抜きしてるの滑稽すぎるからどうにかしたい
>>340 Windows10標準搭載のペイント3Dのマジック選択じゃ駄目なん?
誇張無しで10秒くらいで出来るけど

>>339 あれ?なんでエラーなんだろ
torchは2.0.0?「--opt-sdp-attention」を抜いたら動く?
クリスタとかフォトショとか大体のソフトには
自動選択か色で範囲選択する機能ついてないか
ハイスペPCを買えるならPhotoshopぐらい買えばいい
無料ソフトとは機能はともかく速度と快適性が段違い
>>328 いっそタグそのままにしてLORA作ったらある程度整いました
https://majinai.art/ja/i/MYDylTs 髪質というかピンクの毛の部分と、肌をなめらかにするにはどうすればいいでしょうか?
>>345 1から10まで説明するのは面倒だからヒントだけ置いとくとまず色違いミミロップにどういうタグが付けられてるかちゃんと確認したらいいと思う
その上で学習に含めるのかプロンプトに書くのかは任せる
https://gelbooru.com/index.php?page=post&s=view&id=7235189&tags=lopunny+ >>346 文章抜けてましたが耳に関する部分は元々消してたので、それを再度付け直してます
認識齟齬ありましたら教示いただけますでしょうか
確かに今回の場合は色指定の色覚をずらすバッチを作れば1分で終わる内容だけど
SDを手なづけたい気持ちはわかる
どのプロンプトがどの程度影響してるのか視覚的に確認できる拡張機能あるじゃん。お前らあれでいちいち確認してんの?
>>298 試しにそのタグをプロンプトに入力してt2iで生成してみたらいいよ
それでできた画像と教師画像を見比べて、異なる部分があればそこが学習されるということだから、プロンプトを修正してみる
他にも構図やポーズなんかを教師画像に寄せるよう工夫すれば、クオリティアップに繋がる
>>339 git cloneしたの元URLはどこでバージョンは?
>>298 あとは教師画像を加工する方法もある
顔(正確には首あるいは肩から上)だけ切り抜いて保存
その画像のタグ付けにはportraitを追記
そうすれば顔だけ学習してくれる
>>340 iPhoneなら「写真」アプリで人物を長押しすればそこだけ切り抜いてくれるよ

Stable Diffusionだったらrembgの拡張機能を使ってみては
>>340 人物を切り抜きたいわけじゃないのか
Keitaの色域選択の精度が低いのは意外だな
有料だけどPhotoshopよりずっと安くて買い切りのAffinity Photoなら、色の範囲を選択するツールは普通に使えてるよ
キャラのLoraをワイルドカード指定して、できたキャラごとにフォルダを分けるってことは可能でしょうか?今はstyleで保存したloraの名前でフォルダ分けしてます…
smooth skinの呪文設定以外で、皮膚を滑らかにする方法って何があるかな?
>>357 promptの先頭などの一部だけをフォルダ名にできるということでしょうか。
それなら可能そうですね、ありがとうやってみます。
キャラlora学習でちょうどいい塩梅のを探すのってもしかしなくてもエポック数多めで全部保存しといて、繰り返し回数は最低限にするのが鉄板?
繰り返し×エポック数って1×20だろうが20×1だろうが結果は同じなんよね?
なぜ俺はあんな無駄な時間を…
>>358 ごめんやってみたけどプロンプト内のLora記述は無視されて次のプロンプトがフォルダ名になっちゃった
でもなんか方法はありそうだけど
[prompt_hash]ならLora関係なしに最初の8文字のハッシュ値で一応振り分けはしてくれるな
でもなんかスッキリしない方法だ
これだと行けるかも
単純にテキストだけで処理してるっぽい
[hasprompt<※Lora名1|※付けたいフォルダ名1><※Lora名2|※付けたいフォルダ名2>]
これを設定→ディレクトリへの保存→ディレクトリ名のパターンに設定する
>>359 エポック1か2ごとに保存する設定にして探っていくのがいいと思う
あまりにもステップ数が少なすぎるとエポックごとの変化も少なかったりするけどまぁ根気さえあればいい塩梅が見つかる
ちなみに数を反転しても結果は同じにならない
>>363 同じ結果にならないのか…
脳死で繰り返し最小限にするのも良くないんだな
ちょっと違うけど同じ画像のコピペで枚数を倍にするのと画像枚数そのままで繰り返し回数2倍にするのも結果は違う…?
>>362 とっても助かります、ありがとう!
帰ったら試してみます。
>>308 亀すまん
色と形だね。プロンプト無視して色が出る。
教師の中で画像数多いってことなのかな。
>>350 >>352 ありがと
生成した時に一覧がタイル状に出るけど
奇形もあるので、選別したものをタイル状に出したい場合はどうしたら良い?
実際のサイズを指定した横数で並べて縦方向へ流し込んで連結して生成するオススメのフリーウェアとかある?
>>366 shirtタグ付けて学習させてるからshirt含むタグ全体に影響出てるんじゃねえかな
例えば青いシャツとかならblue shirtだけとかピンポイントでタグ指定して学習させた方がいい
そんで生成時にはblue shirtをネガティブで弾く
Extrasでアップスケールしたいんですが
GFPGAN visibilityを0以上にするとランタイムエラーが出てアップスケールできません
どうすればよいでしょうか?
RuntimeError: unexpected EOF, expected 8041966 more bytes. The file might be corrupted.
Time taken:2.72sTorch active/reserved: 2257/2266 MiB, Sys VRAM: 4295/12288 MiB (34.95%)
同じやつだ
単純にメモリエラー
12GBじゃ最大値が足りないみたい
>>372 SDで生成した画像でも、そうじゃない画像でもエラーになります
>>373 そうかぁ
まあExtrasのアップスケーラーでいいということなら、わざわざSD使わなくてもいくらでも転がってるアップスケーラーで
品質変わらないから他のアップスケーラー使えばいい気がする
なるほど
あまり絵を変えたくないのでExtrasを使っていたんですが確かにSDに拘る必要はないのかもしれませんね
とはいえ手軽にやりたいので解決したいです
12GBでは足りないとのことですが
12GB以下でGFPGAN visibilityを利用できている人はいないんでしょうか
Extrasは使ったことないけど
絵を変えずにアップスケールならUltimate SD Upscale使ってみたら?速いよ
>>378 ありがとうございます。今試していますがいい感じですね
へそピアス?みたいなの入ること多いんですが対策ありますか?
ネガティブプロンプトにnavel piercingとかpiercingとか入れてるけどあんま効果ないみたいです
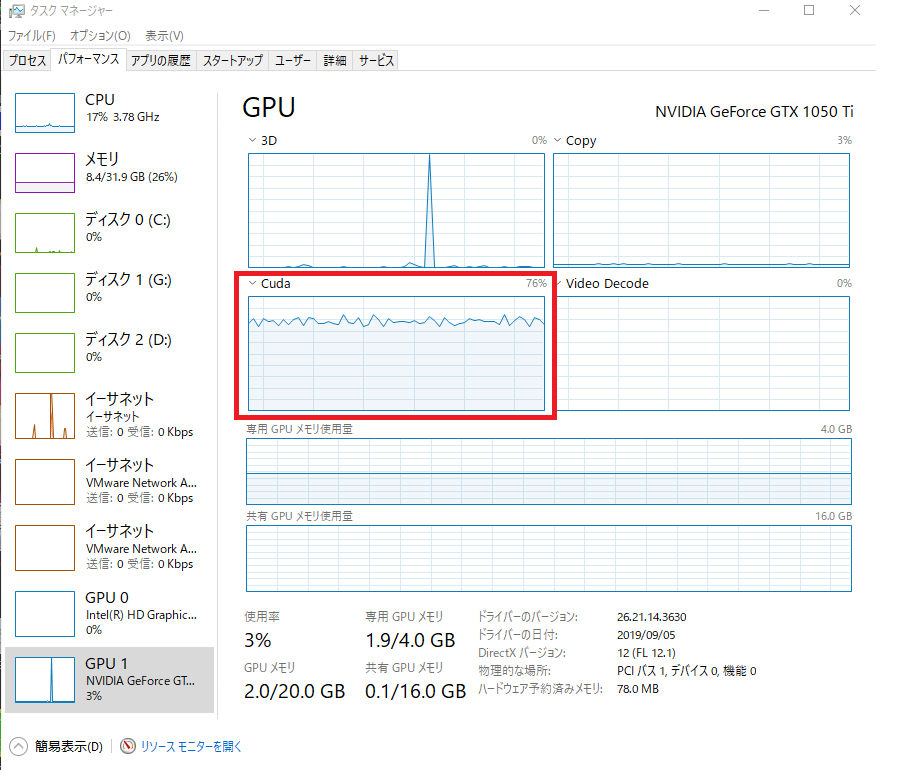
無理難題なのは承知の上で申し訳ないんだが
これは拾いものなんだが、使用しているモデル(もしくはLoRA)を推測できる人いませんかね?



>>381 エロスレがあるからそこでやれ
このスレ全員エロ生成してると思うなよ、9.9割はしてると思うけど
>>381 Photorealistic Womb Tattoos
あとはサキュバスみたいなワードで出るんじゃね?
>>382 スレ間違えた
すまん
>>383 ありがとう
塗りと絵柄が中々再現できなくて。。。
肌がガビガビになるんだけど、プラスチックというかPVC製っぽくするにはなんて呪文入れればいいかな?
>>381 そんなクリーチャーでちんぽしごいてんのかよ草
uiのプロンプト数ってどういう数え方?
1word 1個かなと思ったら2個増えるしよくわからん
>>377 田口ゆかりと見間違えて、昭和かよ!って思った人、他にもいる説
初めてloraをサイトからダウンロードして導入してみたんですが、サンプルにあるような絵柄で出てこないんですが(トリガーやプロンプト、モデルは入れてる)、どうしたらいいんでしょうか。
地道に何度も生成していくとサンプルに近づいていくもんなんでしょうか?
大抵はウェイトを下げて使う
ウェイトの指定が無いなら0.5とかで試してみる
よくあるのがLoraそのもののバージョン違い
PNG Infoにぶち込んでも名前違いで効いてなかったりする
みんなありがとう
0.5にしたら大分マシになったよ
でも、バージョン違いなんてあるのね、知らんかったよ…
ウェイト高すぎる、モデル違う、ポーズや体位系など2つ以上入れてる
大抵この3つ
>>389 > 地道に何度も生成していくとサンプルに近づいていくもんなんでしょうか?
これはない
前回の生成が次の生成に影響することはないから
(プロンプトを変えても影響が残るという報告は多数あるが本来想定された動作ではない)
作者が使ってるプロントもよく見ないでコピペするとリアルスキンだのリアルプッシーだの入ってたりする
リアル系出したいならいいけど二次元絵には向かない
マンコが変なのになる
あと作者の説明文に本作のLora以外に2、3個違うのつかってる場合もある
その場合キャラクターは0.7で使ってと指定されててももっと下げないと駄目な場合も多い
>>164>>167
1週間近くの亀レスになります。遅くなって本当すいません
SDと関係なく、体調不良で数日間録にご飯も食べれず家族と横になってスマホもテレビも風呂も入れない状態でした(結構本当の本当に)
昨晩力が戻ってきたので試した所
venvの削除をためした所「見当たらなかった」ので
venvの再構築し、
(venv)状態でtorchとxformersを再インストールしましたが、再起動しても認知されませんでした
最終手段で起動のbatchの過去のパラメーターをremで退避させておきながら、--reinstall-torchしてみた所
webuiが起動しなくなりました

起動batchの過去の状態にしても駄目だったので、いい機会なので、A1111の再インストールを試みたいと思います
webuiのinstallerは2種類試し、最初のでは数日間どうやってもうまくいかなくて2つ目で偶然上手くいったので復帰できるかは運のような気もしますが。
LoRAとかextentionとかの今残すべきデータを退避させつつ、いらないものは消している所です
再install時には(venv)に気を付けつつ、installするtorchやxformersのバージョンには気を使ってみようと思います
アドバイスありがとうございました。直接の解決にはなりませんでしたが、
この知識は次回にいかし、2歩進む為にあえて1歩引いてみようかと思います
長文失礼。それでは・・・・・・・・
作ったLoraで裸に剥いても必ず左肩あたりに細いタオルやら太いストラップみたいのが出る。
元画像にはそれっぽいのなくて、せいぜいたすき掛けにした小さめバッグのストラップがあるくらい。
細くて黒いストラップだから black strap on shoulder とかタグ付けしたけどダメ・・・
そんな細かいところだけ拾うかね。
1週間ほど触ってみたんだが昔ちょっとやってたボカロを思い出した
あれも音程を打ち込んでってやるんだが調教上手いやつとかは抑揚とかを波形で編集出来る画面があってそこでガシガシ波形を書いていく
これもプロンプト打ち込んでガチャ回して神待ちってのはいわゆるベタ打ちレベルであって、上手い奴はペイントソフトと行き来して積極的にガンガン介入していくやつだなと思った
>>387 0/75の数字はトークンといいます
内部で処理できる単語の語彙に依存するので、1語1トークンとは限りません
>>399 sdの機能でその行き来って完結させられないかね?
inpaint?
>>401 拡張ならphotpea stable diffusionってのがあるよ
レタッチやInpaint使いこなせる人はloraが無い時から複数人絡ませる絵とか作ってるしな
<チラ裏>
1111 SDwebUI最新にしてむちゃんこ快適になった。
RTX3070Tiに4月末頃当時最新で導入したバージョン不明のSDwebUIを使ってたんだが、
昨日最新版を別フォルダで新規インスコしてSPDAで立ち上げた。
今までPytorch2.0で--lowvram 512*512 バッチサイズ2でVRAMオーバーしてたんだが、
--lowvram無しの512*768 バッチサイズ8でも生成できるようになっとる…
前環境でどっかしら導入でコケてたのかもしらんが、もっと早く更新しておけば良かった。
</チラ裏>
>>404 マジか。家帰ったら試してみる。ありがとう。
>>404 3070TiはVRAM8GBだぞ。。。
>>406 xformersなら特に不自由なく使えてたんだけど
>>406 やっぱり前の初導入でミスってたってことかねぇ
ワンチャンVRAM効率良くなったりしたのかな?と思ったけども
どっちにせよ、まぁえがった
version: v1.3.2 • python: 3.10.6 • torch: 2.0.0+cu118 • xformers: N/A • gradio: 3.32.0 • checkpoint: ecefb796ff
set COMMANDLINE_ARGS=--opt-sdp-no-mem-attention --opt-channelslast --autolaunch
512*768 バッチサイズ8 20/20 [00:19<00:00, 1.05it/s]
Time taken: 24.96sTorch active/reserved: 3707/4502 MiB, Sys VRAM: 6723/8192 MiB (82.07%)
512*768 バッチサイズ1 20/20 [00:02<00:00, 8.16it/s]
Time taken: 3.09sTorch active/reserved: 2790/3418 MiB, Sys VRAM: 5581/8192 MiB (68.13%)
--lowvramじゃなくて--medvramだったは
頭冷やしに出かけてくる
不具合多いらしいからギップルってやつ控えてたけど
そんなに有効なものなのか
8ギガの控えめvramの生成能力を少しでも上げるために
そろそろチャレンジするかな
large breastsっていれると後ろの竿役が巨乳になるの何とかできませんか?
>>400 なるほど、モデルデータ内のキーワードみたいなものなのね
1単語で3トークンぐらい消費するものとかあるのかな
>>410 control netでもxformers要らんようになった。
ちゃんとインストール出来てたら元々要らんかったんかも知らんが。
>>413 うろ覚えだが以前どこかで「100」と「hundred」で消費が違うみたいな書き込みがあったな
もっといいモデルを探しなさい
そうすれば良い絵が出るから
3090積んでるからAIイラストやってみたが、夢中になって夕方になってた。
下手なゲームよりおもろい。
1050ti積んでるからAIイラストやってみたが、夢中になって夕方になってた。
下手なゲームよりおもろい。
>>418>>419
LoRaに手出して沼にでもはまってろ
ソシャゲからガチャだけ抜いて持ってきた感はあるよね
楽しい
1060積んでるからAIイラストやってみたが、気づいたら3060になってた。
下手なゲームよりおもろい。
4060Ti16GBを待つのです…といいたいところだけど、9万円くらいになりそうで震える
自分の好きなように絵が作れるんだもんなあ
ある意味、夢のソフトやね
>>423 公式ページで16GBは88,800円よりってなってるから、その辺りだろうね
モデルの絵柄に似せたキャラlora作りたいんだけど
1つ目のlora作成して影響度下げつつ何枚か出力、
出力した画像でlora作成してっていうのを繰り返せば元モデルの絵柄近づく?
それともこの考えは間違っている?
つかLORAは適度に、controlnetをマスターした方が手っ取り早くないかこれ?
4060が5万台になるまで2年くらいかかるかな
奇跡の円高になれ
人間が絵を描くってとにかく時間がかかるからなぁ
上手くなるまでに途方も無い時間がかかるし
上手くなったところでちゃんとした作品を作るには時間がかかる
AIはこんな絵が欲しいと指示するだけで自分の想像以上のものが数分で何枚も出来る
しかもPC環境さえ作れば無料でできる環境というのが凄い
既に自分の満足のいく壁紙を何枚も作れているし
高解像度化してみたらモンスターになる。ちょっと吹いた
口を開けたときの歯がぐちゃぐちゃなのが嫌なんだけど補正できるLORAとかない?
皆さんはLORAの管理ってどーやってる?
ワールドトリガーとか覚えてられないしトリガー被って別のLORA有効になったり
色々面倒なことになってきた
>>439 ultra detailed teethは試してみた?
>>430 Loraは素のモデルで出る絵と対象の画像の差分を学習してるから
そのやり方だと回数重ねるほど元のモデルに近づいて何にも学習しなくなるよ
bmaltais/kohya_ssの新規インスコしてるんだけど
前略)/kohya_ss/tools/../cudnn_windows" could not be found.
って出て進まないんだけど、どうすれば解決できるの??
cudnn_windowsってフォルダー用意したけどコレじゃないみたいだ。
LyCORiSファイルを使いたくて拡張機能a-1111-sd-webui-lycorisをダウンロードしたんですが🎴マークを押してもLycorisのタブが出てきません。
インストール済みには入っていて チェックマークもあり、再起動もしたんですけど他になにか考えられる原因ありますか?
>>439 https://www6.notion.site/8f106cd02e08459d8b2afb3f6e8df2f3 ここの「civitaiダウンロード支援」が便利かも
難しかったら拡張機能のcivitai helperを入れるだけでもいい
AttributeError: 'Namespace' object has no attribute 'lyco_dir' ってつまりどういう事?
できた。
解答して出来たcudnn_windowsはtoolフォルダじゃなくてkohya_ssフォルダに置くのね…
あと、最新版は↓のエラーが発生中
https://github.com/kohya-ss/sd-scripts/issues/563 回避法のレスあり
i2iタブのinpaintってどういう仕組みで動いてますか?
i2iは画像を潜在空間に落としてノイズ足してノイズ除去してるのは分かったんですがinpaintはよく分からないです
web ui の日本語化入れるとさ
sd-civitai-browserのフォルダ名に含まれる単語とかもたまに翻訳されてエラーになるんだけど
SD初心者ながらこことかサイト見て生成しているのですが、起動時文字流れて、python: 3.10.6 の項目のあと、二つほど項目が不明?って感じで文字が流れあとはきちんと起動準備まで行きます。その後URLブラウザ起動しています。
これってSDインストール時何か失敗してるんでしょうか?
自分も
Version: <none>
Commit hash: <none>
だわ
動いてるから別に気にしてないけど、なんか問題あるんだっけ?w
loraを複数適用させると、画質が下がるんだけど、改善策ってありますか?
気になったからvenv削除して入れ直したらverやhashは出るようになったけど
全く同じ条件での生成絵柄がガビガビになるようになってしまった、絵は全く同じなのになんでだ
LoraBlockWeightその他のextensionもちゃんとverupしたのに
重みが合計1を超えないようにってよく見るけど複数lora使う前提なら1でちょうどいいloraにするより少し過学習気味にして弱めて使うようにした方がいいって事なんだろうか
調べたらLoraBlockWeightが追い付いてない模様
https://github.com/hako-mikan/sd-webui-lora-block-weight/issues/67 1111の1.3.xからHires.Fixで効かなくなってるとかなんとか・・1.2.xに戻すしかないか
あるモデルを読み込んだら延々とダウンロードしてるんだけど、自動更新してるのかな?
>>458 Clip SkipとかVAE設定とか前と同じか確認した?
パソコン買うんだけとグラボnvidia4060でもノートパソコンだとスムーズにできないかな?
みんなが上げてる画像見ててキャラの服まんまの人居るけど
どうしたらキャラ通りの服に出来るの?
あと、服を脱がせた下は公式にないパターンがほとんどだからAIに生成というかコラだと思ってもらえばOK
俺も特定のデザインの服着せたくて思案中
多分rola学習だと思って、環境までは整ったんだけど
「out of memory」のエラーでrolaファイルをアウトプット出来ない
グラボはRTX2060 6GBなんだけどやっぱRTX3060に替えた方がいいですか?
無修正もそうだけどウマ娘なんて完全アウトじゃないの
ノート用とデスク用は同名GPUでも別物だから注意必要ではある
4060laptopはデスク版3060とほぼ同等性能
>>468 RTX2060 6GBなら全然作れるよ
バッチとか値を減らせば
ローラなんだけどタガーで自動で作った
キャプションファイルにプロンプトを付け足す
のって意味あるの?
>>466 LORAで服も作れるんだ
自作できる人は楽しそうや
colabで、毎回インストールやモデルやcontrolnetのDL不要な方法、というか一番簡単なノートは無いですか?
>>464 前ここでグラボ次第で出力結果が変わるみたいな書き込み見たんで、もしそうなら妥協できないけど
学習は時間かかるだけですよね?
>>471 バッチサイズ変更って「commandline.txt」内の設定でしょうか?
下記パワーシェル結果は「1」になってました
> num batches per epoch / 1epochのバッチ数: 2
> num epochs / epoch数: 5
> batch size per device / バッチサイズ: 1
他にも設定が・・?
ここのサイト見てもall.fhd_painted.configってファイルがよくわかりません
https://misoji-engineer.com/archives/gpu-memory-shortage.html >>476 あ、このサイトはLORAと関係ない設定みたいですね
失礼しました
loraでキャラ固定はいいんだけど、総じて画質がかなり下がる気がするなあ
モデルキャラの質が低いとそうなるのかな?
>>469 日本国外の人間にはそんなことどうでも良いことなのよ
>>476 >
>>471 > > num batches per epoch / 1epochのバッチ数: 2
これ1でやってみればどうでしょ
>>478 Loraの出来によるね
上手い作り方してるやつは大抵何もしなくてもそれなりの出てくれるけど
適当に作ったやつは、関係ない服が残ったり、手がガビガビになったりする
かといって単純に比率減らしたら当然顔がかけ離れていくので意味ないし
自分はLoraBlockWeightで駄目な部分を探ってから削って使ってる
半分ぐらいの確率で出て欲しい場合は (hoge:0.5)と書くのが正解?
{0.5 :: hoge}のほうが良い?
>>480 やってみました。
素材枚数2→1にして、
かつ、「commandline.txt」内の--max_train_epochs=5→1
にしたら下記の結果になり、一応アウトプット出来ました。
これでちょっと様子見してみます、ありがとうございました。
>override steps. steps for 5 epochs is / 指定エポックまでのステップ数: 1
> num batches per epoch / 1epochのバッチ数: 1
>steps: 100%|
>>483 ちょっと訂正
誤:>override steps. steps for 5 epochs is / 指定エポックまでのステップ数: 1
正:>override steps. steps for 1 epochs is / 指定エポックまでのステップ数: 1
>>481 なるほど、loraといえど質が低いと弊害があるんだなあ
サンクス
>>457 lora併用でポーズ関係のloraだと、1より下げるとほとんど表示しなくなるんだよなあ
絵の質は諦めるしかないかなあ…
>>486 場合に依るけどLoraの重みは下げつつポーズを指定してるプロンプトの方の重みを上げたりで多少改善する場合もあるよ
>>487 あ~、下げることばっか考えてて、上げることしてなかったわ。
やってみるわサンクス。
でも、他のひとはlora併用とかしてないんかな
固定キャラありきでやったら、併用は必要になると思うんだがな~
482だけど、1つトークン要素を50%の確率で出す方法ありませんか?
確率というのがよくわからん
2回に1回適応したいのか半分の重みで適応したいのか
SDってさ、学習能力はなくてプロンプトの指示が全てだよね?
同じ指示でも日によって色彩が微妙に違う時とかあるけどなんでだろ?(モデルは同じ)
>>494 2回に1回ね。
long hair, ponytailならロングポニーができるけど
ロングヘアーとロングポニーが半分の確率なら {long | long ponytail} hairしか方法は無い?
ponytailだけに括弧で装飾して調整できるのかなと
>>441 >>446 ありがとう
試してみるよ!
>>496 long hair, {ponytail|}とかでいいんでないの
二次イラストを作成しています
ツリ目がどうしても出せないのですが、良いプロンプトはありますか?
narrow eyes とかsharp eyesとかやってみましたが、
細いというよりもほんの少し目を閉じている感じです
openpose使おうとしてるんだけど最初っから参考ポーズをガン無視した画像が作られる
chilledremixと相性が悪い?実写系でポーズ指定する方法ないですかね
>>498 へ?そんなので良いの?
一度やってみます
ツリ目とかタレ目で目を区別してるのって日本だけっぽいから、これを区別して学習させてるモデルがない
danbooruのタグにはtaremeとかtsurimeがあるようだけど、ついてない絵のほうが遥かに多いからかあんまり効き目がない
>>501 ガン無視はねーんじゃない
なんか設定間違えてないかい
>>504 cannyは多少うまくいくんだけどopenposeはまるでポーズを参考にしてると思えない画像ばかりになる
みんなこんなもんなのかなって諦めてたけどやっぱりそうではないのかな
例えば棒人間で頭を右にして寝そべらせて全身を写すポーズを取らせたいのに最初から頭が左になったり奇形になったり
立った姿になったりとなぁ
SDのversionを1.3.2にしたらLORAが使えんくなっちゃった
1.2.1にしたいがコミットハッシュとやらが分からん・・・
誰か教えてください〜
>>506 1.3.2でlora使えないのは不具合?仕様?
>>503 逆に言えばそこを突き詰めれば和製二次AIの強みになると思うんだけどなぁ
smallでは物足りない、midiumでは盛り過ぎる、無いんだけど良い形
そういう微妙な所をあやふやな日本語で指定できるAIが欲しい
質問書き込んで自己解決した人は何が原因だったのか書いておくんだぜ
今日webUI起動したら、コントロールネットのパネルに
「1UNIT」って緑色で強調されて書かれてるんだけど、これってなんだろ?
>>501 imageは棒人間でプリプロセッサにopenpose指定してない?この場合はプリプロセッサはnoneにする
違ったらゴメン
>>512 複数使用してるときにどれが有効になってるか目視でわかる
>>505 プロンプトで補強、マルチで掛ける(棒と深度)。。いろいろあるけど
コントロールネットをもっても、寝そべらせて全身を写すポーズは破断しやすいよな、特に顔はモデルによって顕著にでるし
>>515 なるほど。ありがとう
CN2つ使う事って滅多に無いからわからんかった
綺麗になるほど髪がウェーブがかるのなんとかなりませんかね
hpのセール安いな
4070Tiに13700で24万って飛びぬけて安い
フロンティアも相手にならん
>>518 Straight hairプロンプトにセットして
ネガティブに(waby hair:1.4), (messy hair:1.4)とか入れればいい
>>519 4070Tiなんて13万くらいまで落ちてきてるだろ
自作できる世界から見たら、まだまだぼったくり価格だよ
AI優先の自作なら18万で作れるな
20万なら大満足で行ける
>>519 それケースがクソなんよ
12cmの吸気ファンと9cmの排気ファンだけで増設不可
トップはメッシュに見えるけど塞がってる
ケース交換前提じゃないと怖くて使えない
CPUってどれぐらいの使ってる?
i5-9500だけど変更する理由が特になくてずっと使ってる
新規AI特化で組むとするなら、Alder i3でもCPUパワーは十分過ぎるからグラボと高効率電源に全ツッパやな
もし中古ならAM4 CPUがクッソ強い(3700Xで20kとか)
>>527 i7 4790K 3060だけど普通に生成してるよ
ありがとう
やっぱりCPUってそこまでいらんよね
電源は俺もスーパーフラワーの800Wかなんかにしてた
CPUが足りてるかどうかは、そのグラボのベンチマークがちもろぐの生成結果一覧と比較して極端に遅いかどうかを基準にしたらいいよ
体感速度なんて何の意味もないし、動くか動かないかで言うなら極論ウィンドウズが動くならなんでも良いってことになるけど
まあ仮にそのグラボがCPUボトルネックで6割の性能しか出てなかったとしても、気がつかなければ使ってる本人は不幸にはならんけどな
CPUがゴミなんだけど大丈夫か?っていう類の質問は時々見る光景だけれども
おそらく聞いてる本人も真実が知りたいのではなく、不安を取り除けるような他者の意見が欲しいだけな気がする
交換しなくても良いよって言葉が欲しいんだろう
ちゃんと確認したいならベンチマーク取ればすぐわかる話だしね
3090ti~4090とかだと「遅すぎる」CPUはボトルネックになるらしい
アスカの結果サイトでそういうデータがある
ゲームのFPSと一緒でCPU側の作業が遅れてGPUが待つ感じになると顕在化する
受け渡しがちゃんと間に合うとそれ以上はCPUがいくら早くても変わらなくなる
3060あたりだと10年前のCPUでも間に合っちゃうので変わらない
3060、余っていたH81(PCIe Gen2接続)で試したけどi7 4770でCPU持て余しまくりだった(生成中は使用率4割以下くらい)
ガチでi5 2400くらいでもなんとか足りそうで草
>>536 モデルとかVAEでも読み込んでおけば?
持て余してると言ってる人はちゃんと全コア見てる?
あと、100%行ってないから余裕があると思ったら大間違いだぞ
俺もそう思ってたんだが、性能が足りないから本気出してないだけだった
全コア余裕ぶってたのに、良いのに変えたらむしろ3コアぐらいが100%近く行ってブンブンしてる
もちろん生成は超早くなった
i5の2400はゲームと機械学習はまだいいんだけど、
ブラウジングがカクつき始める。スプレッドシートもちょっと重いものだとストレスが溜まりまくった
こないだまで使ってたけど、通常戦が厳しかった
なんで処理速度の指標になるベンチマークを試さずに使用率がどうとか言ってるんだ?
確認出来るほどCPU使用率上がってたら確実にそこでボトルネックになってるよ
生成始めたら一瞬だけシングルコアが100%に上がってすぐ3%くらいに落ちるのがボトルネックを起こしてない状態
>>539 全コア均等割か精鋭少数コア極振りかは世代による
前作った時と同じ設定なのに全然違う画像が生成されて、これが噂のやつか!?となったんだがloding LoraでAssertionErrorが出てた
Loraが何故かエラーで読み込まれず反映されてなかったみたい
Loraのファイルが壊れたのか??
気になったんで俺もアスカベンチ
ivy i5-3750k 3.4GHzでRTX3060 12GBの--xformers
time taken: 43.17s 生成速度7.2it/s くらい
CPU使用率は45%から60%を行ったり来たり
結果はもちログと比較して大差無しって感じだね
3060だと10年前のCPUで全く問題無しですわ
ずっとabyssorange系使ってたんですけどこれ以外にアニメ系でアダルトに強いモデルありませんか?
1111に最近追加のoptimize使ってる人いる?
設定はどんなもん?
Kドライブ直下野郎です
やはりKドライブ直下にpythonをインストールしていたのが原因だったらしく新たにフォルダを追加して作業しなおした所、無事に終わりました
昔CD媒体からゲームをインストールしようとして、D:\Gameにいれたろ → D:\Game\メーカー名\Games\ソフト名 ウワァァァァ! なんて事があったのでドライブ直下にインストールする癖が・・・
ルートディレクトリに直は日本語ディレクトリ名並みにトラブル要因だと思う
>>546 2,03,03,03固定で使ってるわ
20%早くなるし差も感じない
複数Loraだとweightの合計が1になるようにした方が良いっぽいけどLora+hypernetでも同じなのかな
キャラloraは0.4以下にすると別人になって色彩、画質等はSD本来の質に戻る感じ
1以上にするとキャラの再現度は高いが全体的な質が下がる感じ
俺的に
サブに4060Ti 16GB良さげ。7月発売でしたっけ。
3060の12gで問題なく作れるよ。
短時間で大量に生産したいという気の短い人は4070tiから上のGPUが選択肢に入るんだろうけど。
まずは道具より技術を磨いたほうがいいと思う。
いいPC使ってるからいいものが作れるとは限らないからな。
>>559 ほんとそれw
30万のPCでブタみたいなクリーチャー作って
どうすんのって話
他人が開発したAIで技術イキりとかやめてくれよ
自分が好きなものを生成出来るのが良いんであって、他人の褌で他人と競うもんじゃねーだろ
やってる感じではサブPCで生成しつつ。メインで作業が効率いい。サブ欲しいなサブに3060 12GB買うかと思ったけど、やっぱ4060Ti 16GBにする。メインで3090 24GB使ってるしね。
お前の自作のAIプログラムはさぞかし高性能なんだろうな
馬鹿がw
>他人が開発したAIで
オープンソースだと誰も何も言えなくなるなw
エアプのひまわり学級だったか
>>564 ?だから手を動かしてる人に俺の技術が~なんてイキってるガイジなんか居ない
>他人が開発したAI
これ言い出すとほぼ全員がって返すと荒れるからやめような
>>564 リーナス・トーバルズもLinuxに何も言えないな
デフォルメキャラ生成してるがなかなかうまくいかんねえ
デフォルメはデザインの中でも最も難しい部類の一つだ
質問なんですが、商用利用禁止などが付与されてるLORAでも、異なる権限を与えるという表記がないものは、マージしてしまえば商用利用してもいいってことなんでしょうか?
>>571 現実を受け入れないほど事実を突きつけられて悔しかったのかww
いや、実際にモデルに商用利用禁止のLORAマージして商用オッケーで公開してる人いますけど?
異なる権限を与えることを禁止してないってことはしてもいいってことでしょ?
というかそもそも元ネタを自分で作ってないLoRaを使って商用利用なんぞやるもんじゃない
なんでダメなのかの理由はとくにないから問題ないみたいですね。
ありがとうございました。
感情論以外の規約上の理由があるか確かめただけで変なの扱いは草
キミらが脊髄反射でお気持ちしちゃっただけじゃん
>>581 NGに決まっているだろう
ライセンスってのはどんどん厳しさが継承される。
それがライセンスって物で、規約に書こうが書くまいが関係ない
webサービスに、一つでも小さいプラグインに商用NGライセンスがあると、そのサイトやアプリは商用NGになる
こういうのをライセンス汚染って言って大型のプロジェクトになるとめちゃくちゃめんどくさくなる
知らずに使った場合、法的にどうなるかは裁判所次第
ってかこいういう事をする場合、守るか守るまいかは別として知識として知っておかないと危険だぞ
>>583 触る価値もないキチガイに何長文書いちゃってるの
どう見ても釣りじゃん
お前みたいな馬鹿が釣れるから
>>581みたいなキッズが荒らすんだぞ
少しは頭使って考えようよ
>>543 俺もLORAがなぜか突然効かなくなってもだえ苦しんだ。やっと見つけた解決策は↓
LyCORIS(a1111-sd-webui-locon)がインストールされている下記フォルダを消す、又はデスクトップなどに移動させて、webuiを再起動することで元に戻りました。
\stable-diffusion-webui\extensions\a1111-sd-webui-locon
メタデータ削除した画像から
どのモデルで作ったかって判別する方法あるの?
無きゃよっぽど個性強いモデルじゃなきゃ
ライセンス明記とか商用不可とか意味なさそう
>>47にも書いたけどloconはもう使ったら駄目状態というか、存在してるだけで害悪
> この拡張機能は基本的に非推奨であり、正式な更新はまったくありません
> 代わりに a1111-sd-webui-lycoris を使用することを検討してください
> (ただし、新しい PR がある場合は受け入れます)
> この拡張機能の使用中に問題やエラーが発生した場合は、それを削除して lycoris 拡張機能をインストールすることを検討してください
なんかずっとつけててだんだん生成速度遅くなって最終的に1枚出すのに5時間掛かった
元画500x500をサンプ50アップスケ2倍+顔と手の修正だけなのに
おかしいから再起する
>>589 意味ないやろ
商用不可は何か著作権的な問題起きても当方は関係ないので自己責任でやってくれって意思表示の解釈でいいと思う
>>590 locon使用時と生成結果が変わりそうでまだloconを書き換えて使用中……
変わらんのかな?
locon消すとcivitai helper使えなくならない?
そっちの方が不便だから以前の環境に戻したし
hpの奴スレチだけど
リーベで10%楽天payで3%帰ってくるからめちゃ安いわ
ちょっとだけ話がそれて申し訳ないが
最近下痢が止まらん、胃腸薬や整腸剤飲んでも治らん
どうしたらいいだろうか…
食べても全部下痢なのかな?とりあえず一度絶食か野菜ジュースで様子見。
>>597 普通に病院いったほうがいいと思うけど、
運動してないなら絶対にしたほうがいい
プランクおすすめ。ネットしながらできる
病院行く暇ないならとりあえず絶食
腹減ったら塩なめるかポカリ飲んどけ
>>597 薬飲んで治らない時点で今すぐ病院いけ
素人意見を聞いて安心するなよ
俺の場合は下痢と嘔吐が止まらなくて病院に行ったら花粉症の超酷い版だった
一日回しっぱなしにしてると、
たまに解像度めちゃ低い画像ができあがるんだけど、
そういう症状でる?
放置してたら直る
ワイルドカードでランダムにいろいろな表情を出したいのでおすすめの表情有ったら教えて
普通の喜怒哀楽ぐらいなら入れてる
素人だけど、リアル系は笑顔以外ってあんまりうまく出ない気がする
怒り顔とか泣き顔とか思った通りに出ないもんなのかな?
colab民。ボーナスで10年以上振り自作予定。嫁さん説得材料として、たれぱんだのキャラ画像作るも難しい。実際のパンダは作れるのに。
>>612 まぁ全体を見るとドラム缶だけどな
それは良いとして、txt2imgファイルの出力はモデルごとに出していたんだけど
extraで画像作ると、settingで指定したディレクトリの出力が無視されるのは仕様?
webUI 1.3.0です
リアル泣き顔とか元になるデータ少なさそうだしね
スマホのアプリで生成してるとたった一つの着せ替えワードで見た目が劇的に良くなったりして、出てくるイラスト見てるとウ○娘とか艦○れとかアズ○ンとかのデータを喰いまくってるんだろうなぁと感じることがある
>>613 cryじゃなくてteardropかtearsにするとええで
生成した画像を効率よく厳選する方法ご存知ですか?
SDのWeb UIでアップスケール無しで1000枚くらい画像生成してから、厳選作業にInfinite image browsingというextention使って、気に入った画像をsavedフォルダに送ってるのですが、皆さんどうやってます?
先日SDを知ってgtx1650でがんばってるけど、ぼくは本当に心から有難うという気持ちでいっぱいです
bmaltais/kohya_ssでLoRAやLoConのsafetensors既存ファイルに学習の続きをさせたいんですが、
どう設定すればよいですか?
>>621 わかるぞ同士よ
下取り出して3060,12GBに変えてみろ、飛ぶぞ
>>618 まぁまぁ
興奮しなさんなwwwwwww
>>616 ありがとう
0.8とかsmileと合わせるとか色々試して変顔なってたw
3060 12GBはAI生成に関して基本的人権レベルかもしれん
でも1650,6GBの時の方がカワイイ画像多いんだよな
setting
Extra Networks
When adding to prompt, refer to Lora by
Alias from file --> Filename
これでLora 使えるような情報どっかで見たような気がする
始めて3日目、1080&8GBで十分満足してるんだけど、何をしようとするとそんなに必要になるのかな?
>>619 仕分けは以前教えてもらったphotoSiftだな
キーボードワンクリックで分けられる
仕分先間違えた時も無限Undoて復元できる
1000番代をって生成時間がとんでもないなん
待ってる時間が無駄だとは思わないのかね
3090だけど、生成してる時の待ち時間はこの世で最も無駄な時間だと思う
4090に早く変えたいけど良くて半分とかそれでもキツいな
待ってる間に別のことしてるから全く苦にならない
もう少し時間の使い方を見直した方がいいんじゃないかな
1070の時は寝る前と仕事前にbatch count100にして生成してたな
家にいる時はゲームもできなくなるから、筋トレしたり料理の勉強したり、瞑想していた
近所の掃除もしてたな
待ち時間の使い方って聞こえはいいけど
その待ち時間が自体がないほうが良いに決まってるからな
あー
>>647でネタだとわかった
次もっと頭使ってネタ考えてきてね
おやすみ
QRコードの生成300回やってやっとできた
死ぬかと思った
>>655 いやわかるだろ
表になってるだけじゃん
>>657 Lora Detail
Lora Photo
Embedding NEGATIVE
が全部同じ効果なの?



生成に時間かかるって上で話題になってるけど
生成よりも手の修正とかアップスケールの方がめっちゃ時間かからん?
hiresで2倍にするだけで、修正とか一度もやった事ないわ
人に見せるためじゃないし気にした事ないな
プロンプトとか調整してガチャの繰り返し
できの良い絵がでけると人に見せたくなるよな
完成度高いローラ作ると下手したら公式絵すら
凌駕してくるからやめられない
ツイッターにあげる分には問題ないのかな
見せたくなるのは分かるが出来が良ければ良いほど問題になるから辞めとけとしか言えん
マスク処理のパラメータ処理は先人の知恵が無いとむずいのう
ほんとローラって文字見た瞬間、毎回「アハハ、オッケー」って頭で鳴るわ・・・疲れてるんだろうな俺
3090なら一つの絵なら一瞬で終わるぞ。うん百枚と生成したら長いけども。
一つの絵でう○こしてまだ終わらないとかやる価値ないわ
今のPCが1660でかなり無理があるので4070で新しく組もうと思ってるのですが、適正なCPUやメモリってどのくらいでしょうか?
あとCPUはやはりintelが良いのでしょうか?
intel以外ない
CPUは機械学習関係なしに11世代以降買っといた方がいい
4070ならCore i5-13600KかRyzen 7 7700
メモリなら24GB
gen4のNVMe 1TB以上の人でweb-ui何秒ぐらいで起動する?
モデルデータの読み込みはこの時点でしてなかったっけ?
t2iで2880*1920作ってi2iで拡大しようとしたら1.1倍の3168*2112でも
Out Of Memoryのメッセージすら出ないで生成中断されるんだけど
VRAM12GBは2800*2800辺りが限界なのか?
>>673 Ubuntu22.04だと初回起動15sくらい
SSDはキオクシアのEXCERIA 1TB、CPUは7950X、メモリはDDR5-4800で128GB
基本的に速度を求めるならLinuxだと思う
>>676 仕事はLinuxの鯖管でCUIしか使えないけど
webUI使いたいならgnomeやKDE使うことになるよね?
生成までの速度が、whndowsより速いの?
アスカベンチとかもwinより速いの?
>>677 --listenオプション付けてGradio起動したらFirewallとか設定してなかったら
Windowsの外部PCからWebブラウザからアクセスできるからCUIだけで基本可能かと
生成は4090でアスカベンチなら38-39it/secで10枚8秒強
WSL2だと9秒台、Windowsだと10秒くらいかな
>>675 3060/12GBで4kサイズを出してる人はなんJNVA部で複数見てるよ
tileのパラメータを調整するとかじゃなかったかな
>>679 そうか、winでもlocalhostで通信してるから
サーバをlinuxにしてwindowsがクライアントにすればcuiでセットアップしてサービス開始すれば良いね
>>675 > t2iで2880*1920作って
> VRAM12GB
そんな大きいの12GBで行ける?
3060で4Kを1枚生成してどれだけ時間かかるか…
>>680 Tiled DiffusionなのかTiled VAEのどっちなんや
>>682 t2iでもTiled DiffusionとTiled VAEを有効にしていけたけど
xformersも有効にしているおかげかは知らん
>>684 ああtiled diffusionは盲点だった・・i2iで使うものって頭が割り切ってた
まぁ結局i2iするなら同じだろうけど
VRAM大事なんや?そしたら3090の24Gのほうが4080(16G)より尊いこともある?
>>661 むしろ逆だな
素晴らしいのは秘蔵したい
公開するにしても技術的な試験、研究の意味合いを持たせれば……
単なる二次創作よりは良いかも?
>>671 今のタイミングならEコアで水増しなIntelよりRyzenじゃないの?
全コア使うような計算をやらず画像生成専業なら良いかもだけど
サイズが大きければ大きいほどVRAM肝心になるんで、結局欲しくなるのが24GBだよ
4060の16Gより買えるなら3090更に買えるなら4090って感じ
最近、薄い本に興味が無くなってしまったw
エロさは負けるけど自分で生成する方が楽しい
>>684 どっちも使うんやで
両方のパラメータを調整することで4kどころか8kも16kも可能
16kx16kすら不可能ではない
微妙な調整が必要で少しミスるとエラー吐きまくるけど
高さを小さくすれば横32kとか64kも普通に出せる
100kもやれた
VRAM24GBあれば200k出せるんだろうか
高解像度補助使うとか12GBとか16GBは1枚で何時間かかるねんって話になる。
3060 12GBで普段950x550ぐらい(適当)をHiresで1.5倍にしてi2iで4倍にしてるけど(6Kぐらい)
Tiled Diffusionで書き込みを増やす方法だと10分かかる
>>692 4kなら8分くらいで終わるやん
8kは40~50分かかるけど
幅と高さ上がれば上がるほどVRAM使って時間短縮
更に高解像度補助を上げれば上げるほどVRAM使って時間短縮
こんな感じかな?
VRAM多いほうがいいな
そしたら4060の24G版とか安価に出たりしないのかなあ
>>675 2070S 8GBでも500x800ベースでHires fixでx4、i2iでx2とかで4Kx6K位まではいける
10分ぐらい掛かるからあんまりやらんけど
最近あんまりOut Of Memory見てないな
Tiled Diffusion with Tiled VAE今まで知らなかったんだけど、
t2iでフルHDすら出力できないrx6800 with directmlでもHires.FixでフルHD出力通ったわ
たまに一部グレーアウトするのと絶望的な糞遅さだけど良いこと知った
>>700 ついでにUltimate SD upscaleも入れよう
こいつも時間と引き換えにVRAM不足を補って大きな画像が出せる
無印のSD upscaleの方が手軽なんだけど今でも落とせるのかな
Tiled Diffusion with Tiled VAEでフルHD出力できたと思ったが、気のせいだった
出力まで行くことは行くんだがHiresじゃなくてtile側の解像度拡張でも、
なんならi2iでも画像左下が常時グレーアウトする
diffusionとvaeの設定下げまくっても無駄だったから、
やはりwin+ラデのAI絵環境は紛うことなきゴミオブゴミらしい
ROCmはよ
PC音痴なんですけどwiki見ながらLORA入れようとおもってるんですけどよくわかりません
sd-scriptsのところに書いてあるコード?をコマンドプロンプトにコピペしてエンターを押せばいいんでしょうか?
>>703 LoRAはそれ用のフォルダがあるからそこにファイルを入れて、
あとは生成ボタン下にある花札みたいな色合いの月と山のボタン押したらLoRAのタブが表示されるからLoRAのタブを開く。
LoRAがずらーっと一覧表示されるんでそこから選択するとプロンプトにこのLoRAを使いますよって記述がされるんであとはその記述の影響度の部分を調整して生成すればOK
>>703 追記。Web UI起動中にLoRAファイルをフォルダに入れた場合はLoRAタブ辺りに更新ボタンがあるからそれで新しいファイルを認識させられる。
>>705 うまくいきました!めっちゃ助かりました
LoRA作成ってCPUパワーも必要なん?
アホみたいに時間かかるな
Lora学習する際、DreamBoothタグのPretrainedPretrained model name or pathで、ベースモデルを選択すると思います。
このベースモデルは、イラスト生成で使用するモデルと同じモデルを使用するべきですか?
それとも、例えば背景Loraを作る場合だったら、背景に特化したモデルを別途用意して使用するべきでしょうか?
これGPUの負担ってどのくらい掛かってるの?
MMDの動画出力とか動画エンコードやBlenderよりかは負担ない認識でええか
>>699 6480*4320で34分も掛かってたわ4070Tiで
3060 なら1時間半以上掛かってたんかな
くろくま参考にしてInversion stepsを30したNoise Inversionを
有効にしたらなんか画像が白っぽい感じがする
AMD-Matrox派の俺は草葉の陰から見物
RADEONで戦えるようになったら本気出す
4090搭載PC買った途端飽きそうで手が出ない、3D系のゲームはやらないし
案外生成スピードが遅いからこそ続いてるのではないかと思ってる
俺は3080tiのデスクあるけど生成し続けたら部屋暑すぎるから、3070tiのゲーミングノートでやってるわ、遅いけど…
>>710 CUDAは100%まで行くかと
メモリはやる事次第
それ以外の項目は全然
タスクマネージャー見る機会増えたけど
1650superだと、35%あたりが上限に張り付く感じ
16GB内でメモリ圧縮が頻繁に行われてるメモリ圧縮をオフにしてた時はすぐに処理が止まってたな
まさかメモリ圧縮をSDのためにオフにする時が来るとは思わんかった
>>710 アフターバーナーで出力70%にしてるから100%と30%を激しく行ったり来たりしてる
>>711 そのサイズだと40~70分て所かなあ
90分逝くのは8k超えた辺りから
まあパラメータ次第だけど
一度設定失敗して1枚出力するのに19時間かかった事あるし
寝る前に始めて、寝てるときも出勤中もずっとグラボ回ってて、帰ってきてもまだ終わってなかったというね
質問だけど、モデルデータが4GBぐらいある場合はfp32と考えて良い?
そのページに書いてると思う
でもとりあえず全部fp16でもほとんど変わんないよ
なんだったらwebuiはfp16しか対応してない
あら、そうなのね
自分が持っているfp16がほとんど2082MBだったので、そういうものかと思ってたわ
>>633 よし そのレベルを買おう 金がない( ̄▽ ̄;)ありがとう
金がないならいきなり買うより、ネットカフェで試すといいぞ
1080はちと中途半端な感じが凄い
>>709 LoRAはベースのモデルと学習素材の差を学習結果として記録してる(と言われてる)
なのでベースモデルはマージモデルよりシンプル(NAIとか)の方が特徴を覚えやすい(と言われてる)
ただまあ、実際の所出来上がったファイルで判断するしかないので、NAI使ったりAOM使ったり、色々試すしかない
ベースモデルより学習素材やタグ付けの方が重要な気はしてる
Colabでワイルドカードのリストのテキストってどこに入れたらいいの?
webuiって別PCやスマホがクライアントになった時って画像はどこに保存されるの?
サーバー側?クライアント側?
>>725 基本はサーバ側
outputsで指定してるフォルダに貯まる
Colabの有料で動かして遊んでたら2日で制限来ちゃったんだけど。こんな消費速いのか。
colabはあくまでお試し用だな
あんなもんでやってたら金かかって仕方ないぞ
colab2日で制限って本当に48時間ずっと接続してたんだな
>>726 なるほどね
そこらへんの出力の設定関係もサーバー側で保持してどのクライアントでも同じ設定が使えるって事か
>>723 シンプルモデルの方が良さそうなんですね。
知りませんでした
背景だけ学習させたLora使ったら、生成時に併用したキャラLoraの顔まで変わってるみたいなので、
タグつけとかも調整して試行錯誤してみます。
情報ありがとうございます
だんだんと顔が緑や青のパックみたいな感じやマスク指定してないのにマスクしだすようになって直らないんだけど、何かご存じの方いますか?
同じキャラを作るには、controlnetが必要なの?
>>732 DPM++ 2M SDE系でステップ数30以下とか?
輪郭線を太くする方法ってありますか?
かき集めてlora作るしかないかな
Hires.fixで2048x2048作る方法RTX4090しかないですか?
>>736 Steps: 25, Sampler: DPM++ 2M SDE Karras, CFG scale: 10


Steps: 20, Sampler: DPM++ 2M SDE Karras, CFG scale: 8


確かに30以下だけど前から30以下でまわしてたんだけどなぁ、試してみます
「ここを修正するから目印でマスク処理して青く塗っておくか→え?もうステップ数ないの?じゃあこれで出力ね」って感じなんだろうね
こんな感じで笑

キャラの輪郭線を細くしたいんだけど、なにかいい呪文ありませんかね?
VR360の風景を作ろうと思って、そういうLoRAを導入してもイビツに歪んでうまくいかない
誰かControlNetの機能で作ってくれよ〜 普通の写真をエクイレクタングラーとかいう形に変換するやつ
自動で毎生成ごとに読み込むモデル変える方法ってあります?prompt同じでいろんなモデル試したくて
>>754 複数モデルだと再選択面倒だよな
今はスマホで写真とってポチポチしてる
stable diffusionってi2iで一部だけマスクしてその部分だけ訂正してくれる機能ってありますか?
Novel AIだと使えるんですが絵柄がのっぺりし過ぎてどうも。
昨日急にi2iでsketchに画像入れると勝手で限界まで拡大されてしまいフリーズするようになった
inpaintも挙動がおかしくてカーソルが画像の上に出なかったりするんだけど、原因わかる方います?
>>757 ありがとうございます。ジェネレイトしてきます。
リアル系で日本人の14歳の美少女のエロ画像を生成するのに向いてて
かつ、ダンボールタグへの反応も良いおすすめのモデル教えて
chilloutmix, rdosmix, ddosmix は試したけどなんかちょっと違うね
perfectworld はダンボールタグの反応が良いけど2.5次元っぽいのが難点
1111使っててv1.0.0以来アップデートしてなかったが
そろそろcontrolnet試してみようと最新バージョン1.4落としたけど
簡易インストーラーのrun.batが入ってませんでした
バージョン離れすぎて今の環境は保持した方がいいと思ってるので
クリーンインストールした方がいいと思ってるんですが
1.0.0にあるupdate.bat動かしたら最新バージョンになりますかね?
どなたか同じような状況の方、意見求めます
inpaintでアイドル写真のアイコラ作りたいんだけどモデルはどれがおすすめ?
large aaa, large bbb, large ccc, large ddd
な場合は、トークン数節約のためにまとめることってできる?
>>713 4090手に入れてみたら、
解像度高くてもちょぱやで生成されるから作りたい絵が大量にできる。
新しいアイデア試したくなって逆に飽きない
ツイッターの画像生成アカ見てると面白いな
AIを使ってもセンスある奴無い奴明確に分かれるのは手描きイラストと同じだ
当初、慣れたら誰でも同じクオリティなるようなイメージ抱いてたけど
>>767 美的感覚が違うんでねえかな?でもポンコツはマジ不思議なくらいポンコツ。
おきにのキャラのローラ作りにはまると
プロンプトとかどうでも良くなるな
今まで集めた画像フォルダが宝の山になってるわ
センスの有無なんて他人が言うもんじゃないべ
そいつがそういうのが好きで上げているなら単なる好みの違いだ
いいねを貰えてるAI絵は下着や水着ばかりなのがむなしさを感じるわ
ローカル版 最新のSDで、スタイルをUI上で編集できるStyles-Editorなる拡張機能(標準装備)をインストールしてみたが、
マニュアルにあるようなStylesEditorタブは表示されなかった。
だれかこれ使えている人いる?
いちいちCsvファイルを編集するのがめんどいのでぜひ使いたいのだが。
https://github.com/chrisgoringe/Styles-Editor ぜひも使えない。
標準拡張機能でも使えないという事もあるのか。
よく見てみたら起動時にエラーが出てた。最新バージョンで仕様が変わった?
だれかわかる人いたら解決策をおしえてくだされ。
<ログ>
Error executing callback ui_tabs_callback for F:\stable-diffusion-webui\extensions\Styles-Editor\scripts\main.py
Traceback (most recent call last):
File "F:\stable-diffusion-webui\modules\script_callbacks.py", line 125, in ui_tabs_callback
res += c.callback() or []
File "F:\stable-diffusion-webui\extensions\Styles-Editor\scripts\main.py", line 215, in on_ui_tabs
cls.dataeditor.input(fn=cls.save_styles, inputs=[cls.dataeditor, cls.autosort_checkbox], outputs=cls.dataeditor)
AttributeError: 'Dataframe' object has no attribute 'input'
>>775 普通に使えるな
操作感があんまり洗練されてないがUI上で作業できるのはまあ便利か
>>778 なるほど、環境の問題かな。
一度クリーンインストールしてみる。
ありがとう。
>>768 BREAK構文で逆に全部分割したほうがいいかもね
>>713 一緒に来年の4000 SUPERシリーズを待とうぜ~
VRAM24GBの4090SUPERとかいくら用意すればいいんだ…
というか昔みたいにVRAMは各メーカーが積めるようにしてほしい
どこかがVRAMに極振りした製品出してくるはずw
ゲームは全くしないから3060でも高いなと思っちゃうんだけど
中古で1080 Ti 11GB買うのはアリかな?
プロンプト内の2つ以上の要素をセットで変化させた時にどうなるかチェックをX/Y/Z plotの1軸(X軸)だけで指定することってできる?
例えば、black hair, white shirtのセットを、red hair, blue shirtのセット、green hair, yellow shirtのセットにしてどうなるかみたいな
>>763 1.0.0の次からインストーラーやアップデータのbatはなくなりました
zipを解凍してwebui-user.batを実行するとインストールされ、次回もwebui-user.batで起動します
マージを繰り返し最強のモエカワJCを開発してしまった
>>763 >784の続きです
1.0.0を新規フォルダに解凍し直してupdate.batを実行すれば、多分最新になります
今なら1.3.2になるのかな? それとも1.4.0RCになっちゃうんだろうか
starfield出るし4090買ってもいいんじゃね?
ちょっとだけ生成しようと思ったのにもうこんな時間……
>>785 にわか情報だけで回答するとない
1000シリーズはAIが苦手みたいで1080TIでもエントリーモデルの3050以下の速度らしい
一番コスパがいいのは2060の12GBで次に3060の12GBで2060は3060に少し劣るくらいというスコア情報がでてる
ただTensorの性能は3000シリーズのがいいからこの先のアップデートではどうなるかわからん
これ以上はもう4000シリーズまって買ったほうがいいTensor機能を使えば秒らしい
3060以上を買わないなら2060一択だし今なら以前の1660シリーズくらいの値段で買えるんじゃね
>>798 >1000シリーズはAIが苦手みたい
これまじで?
>>746 使ってるがぶっちゃけ移行先が4090しかない
VRAM増やしてくれたら
バッチサイズ上げても学習速度上がらないんだけどGradient checkpointingにチェック入れてるからですかね?
>>801 現行バージョンはvram越えた分はエラーにならずにメインメモリ(共有GPUメモリ)使うようになってる
メインメモリ使うと生成速度がガッツリ落ちるから
vram内に収まるようにバッチサイズを調整すれば速く生成できるようになるよ
番号がずれてた
>>787と>789は
>>766だった
iOSのJaneは書き込み最終行のURLが表示されないことがあったりして挙動不審だ
DirectMLってやつにすると
CPUに内蔵のやつでも使えたりする?
>>799 1000番台、つまりRTXになる前の世代はTensorコア載る前の世代だから遅い
>>806 現行って1.4から?
今ノートPCで1.32使ってるけどメモリ不足のエラーでまくってる
VRAMは4GBだけどメインは32GBあるから遅くなってもそっち使ってくれるなら助かるんだけど…
なんか最新のRadeonのアプデでStable Diffusionの性能が2倍になったって聞いたんだけど
VRAMが同じ12GBの6700XTが3060と同じくらいの生成性能になったんかね?
xformersちゃんと動いてます?
自分の場合動かない
No module 'xformers'. Proceeding without it.
ってでる
実際、ブラウザの一番下はN\Aって出てる
ネットの情報か片っ端から試したが無理でクリンインストールしても無理で困ってます
そもそもxformersって必要なのでしょうか?
今でもxformers使ってる?
2.01+118環境で十分なのでは
ゲフォ4000シリーズだとxformerすら要らないのかいいな
初めてLOLA作ってみたら画像の数だけファイルができたwwwもうわからんwww
image folder の指定が間違ってんのかな
未だに利益無しよ
3090でガンガン絵を量産してるがw
芸能人でやってあげてるとFBIに突撃されるからな
あとロリも警察は本気だすからリアル調なのは捕まるぞ
よって版権キャラで違法稼ぎやってるんじゃないの?Fanboxとかで・・
カドと政府が5輪で結託してたからコミケの2次違反者がなぜか許容されて守られて
今や同人はなにしてても許されてるレベルだろうし
著作権法案を変えられるまではそこでもうかるんじゃない?
しらんけど
AI画像生成で稼ぐ方法!みたいなゴミサイトが出てきたようで
ああいうの見て来たんだろうなってお客さんが段々多くなってきた感じがする
AIのエロ絵漁ってるとこれ凄いもっとみたいのあるやろ
そういうのは大体有料なんよ
つまり稼げる
FAZNAの写真集ランキングにAIめっちゃあるしな
1650から3060に乗せ換えたらチートレベルで爆速になった
コスパがどうとかじゃなくて4090 24GBにしたら光の速度~云々で地球が消滅したとかそういう話はないの?
モデルデータのsafetensorsって
中身がどうなってるのか見たいんだけど
どうやって見るの?
有料で買うほどじゃないよね
てか承認欲求に負けて無料で公開してくれてる人多いから、エロもそれで十分
なんかVRAMが3.2GBくらいしか使わないんだけどもっと使ってくれないかな?
GTX1080やけど
>>835 タスクマネージャーでCUDAを確認してもろて
pixivに投稿してたら外人のフォロワーからガチファンレター来てコミッションかリクエストしたいんだけどやってますか?
有料でもしてもらいたいです!
って言ってきたけどAIなめんな!狙った画像出せるほどそんな知識ねーわ!って言ってやったわ
>>815 512*768をHires. fixで2倍でバッチ回数1、バッチサイズ4で
opt-sdp-attentionだとCUDA out of memoryになるのが
xformersだと7m掛かるけど完走するからVRAM12GB程度では
入れてた方が良いと思うわ
グラボ買えば好きなの作れるのにわざわざ他人のモザ付き画像を買ってる奴がわからん
xformersはプロンプト捏ねてるときにたまにわけがわからなくなる、今変えたっけ?みたいな
大きい画像にするときだけ入れればいいような
>>839 とは言っても厳選したり面倒よね、楽しいけど
>>841 ごめん言ってる意味がわかんないです
どんな画像が詰め込まれてるのかなぁと思って
中身を画像として見てみたいと
思っただけです
>>843 それを簡単に見れるようにしたのが1111氏
>>810 DirectMLとOliveを使った環境で効果がある。
この環境、まだCUIだけで、1111に移植中の物はまだ未完成。
>>843 中に人が描いた画像が入ってたら著作権法違反になってしまうのでは?
画像が入ってると思ってる奴
いまだによくいるんだよな
>>843 画像は入ってないよ、学習されたモデルのパラメータの重みが延々と入ってるだけ、だから見ても何だかわからない、
画像が暗号化されてるとか圧縮されてるとかそうゆうことではなく、ただの学習された重みのデータのかたまり
>>846 その判断は難しいね、もっとデータが増えればπみたいにどっかでjpgデータがあるかもしれないね
ID:wvMdCxwv
比喩で言ってるのかと思ったわ・・もう根本から間違ってるよ
起動したりするときに
[notice] A new release of pip available: 22.2.2 -> 23.1.2
[notice] To update, run: python.exe -m pip install --upgrade pip
って表示が出るんだけどアプデしておいた方が良いの?
普通に動くんで困っては無いんだが
CDに音が入っているって言ったら反論してくる奴
おまんこ画像はただの数値の羅列と言いたい奴
まあ4GBとかあるし画像が入ってると思っても仕方ないよね
πの中にあらゆる数列があるとか言うけど、その数列表すのにπを使うと、元の数列より桁数が爆上がりする件
>>847 学習にビットマップ画像一切ナシのスタンドアロンPCで、テキストだけで学習できるならその言い分は認める
>>857 ありがと
気の向いた時にでも入れることにするわ
>>858 絵師はイラスト画像が作れるんだから絵師の脳の中にはイラスト画像が入ってるというなら、SDのモデルにも画像は入ってることになるが、そんな哲学論争してもじゃあないじゃろ
>>845 そっか~詳しくありがとうございます
コマンドライン嫌いじゃないけど札束で殴りつける方が早そうですね
>>848 なるほどありがと
ちなみにモデルデータ作る人って
画像を用意してなんかのソフトで数値化してるって事ですか?
>>862 それを言われると困る人がたくさんいるんですよ
>856
3060を買おうかと思ってたんですが、4060ti 16GBなら予算的にそんな変わらないかと思って。
>>863 Deep Learningの学習はtorchとかkerasとかライブラリーがあって、そのライブラリーに学習ツールも入っているのでそうゆうの使って学習することが多いよ
学習した結果、最初はランダム設定されたモデルのパラメータってゆう数値が意味のある数値にだんだん変わっていって、その数値を保存したのがモデルデータ
>>866 つまりビットマップは要るの?要らないの?
今までエロいイラストはモザありや海苔越しばかりだったのに、綺麗に全部見られるようになって不思議な感じ
>>869 ちなみにcivitaiとかにいっぱいあるマージモデルは1111にもチェックポイントのマージ機能があるからから試すレベルなら自分でもすぐにできるよ
Ebsynth Utilityのエラーで出てくるNameError: name 'Loader' is not definedってどうすりゃええねん
>>825 いいなぁ、1650だけど
512平方でhiresしたら4分かかるわ
>>850 へ?そうじゃ無いの?
画像と対応するトークンの集まりかと思ってた
こんばんは質問なのですが
Kohya’s GUIというのをインストールしようと思ったのですが
Pytorchのインストールでコマンドが動かなくなってしまって困っています
どなたか対処法ご存じの方いらっしゃいましたらお教え願えないでしょうか
ちなみに一枚目が止まってるところで
参考にしてるブログの記事だと二枚目みたいになるみたいなんですが・・・
https://imgur.com/uK5s2VG https://imgur.com/undefined >>876 某blogでもPytorch 2系でインストールが止まるから1系でインストールしてから手動でPytorchをアップデートしてみたいな記事はあったからそのパターンかな?
使ってるGPUとかで挙動は変わってくるし一概には言えないけど
皆さんは多目的トイレをどうやって出してますか?
civitaiではそれっぽいloraは見当たりませんでした
>877さまレスありがとうございます
今再び見てみたら進んでました・・自分の回線が遅かったみたいです
でも具体的なアドバイスいただけて大変助かりました
初歩的な質問なのにありがとうございました
watabe,ってプロンプト入れたらいつかでそう。
ControlNetの情報って生成された画像に保存されないのかな?
エクステンションのImage Browserのsend to ControlNetから引っ張ってこれるもんだとばかり思ってて
使ってたけどよく見たら生成画像をControlNetに飛ばしているだけだったw
欲しいのはその時に使ったControlNetの情報なんだけどこれはどこか別に保存しておかないと無理なんですかね?
物がいっぱいあってゴチャゴチャしている背景ってどうやって出すの?
なにか学習させなきゃいけないのかな。
モデルに画像が詰まっててそこから対応する絵を取り出してるって発想逆にすごいなどうしたら考えつくんだ
間違うのは誰にもあるからまぁいいんだけど、上から知ったかして人に教えだすのが怖すぎる
昔技術スレに画像が圧縮されて入ってるって延々言い張ってる奴がいた
突っ込んだらAIで画像を高画質にする技術があるんだからそれは圧縮と同じだろとか言い出して、もう手が付けられなかった記憶
pixiv見てたら「あれ?俺の生成した絵と全く同じじゃん」ってのがたまにあるの見てやっぱりAIなんだなーとしみじみ
中に入っている画像をタグで取り出すだけならAI要らんわね…
>>885 SDって画像が、モデル名やシード諸々の設定とプロンプトのテキストに圧縮できる技術という考え方は出来なくもないw
ただモデルファイルがデカイwww
1111のローカルで、モデルはAOM3などを使用しています。
Boy and girl hugging, のようなプロンプトで、絡みの絵は出るのですが
男の方にだけ指定のlola、女の方に別の指定のlola…みたいにする事は可能ですか?
あと、男の方にだけプロンプト指定(例えばイキ顔とか)、女の方にだけプロンプト指定(舌を出すなど)や
それぞれに年齢指定をするとなると、どのような位置にどのような記述が効果的か分かる方いますか?
画面を左右2分割などしてそれぞれlolaを指定できる方法がある、という事は知っているのですが
それ以外の構図だと、生成した画像を男女片方ずつ修正していくしか無さそうでしょうか
英語が弱い事もありいまいちプロンプトを使いこなせていないので
プロンプトの辞典や勉強できるおススメのサイトなども知ってる方がおられましたら、教えていただけると幸いですm( )m
hires fix ってCPUかなり依存しますか?
これ使うのだけ、ベンチ回すと生成速度が同じグラボの人よりも落ちる
regional prompterで検索すれば幸せになれるかも
>>786 それならダイナミックプロンプトのほうが楽
{black hair, white shirt|red hair, blue shirt|green hair, yellow shirt}
と記載して、
Combinatorial generation
Fixed seed
をチェック
Batch countとBatch sizeは1
seedそのものは-1でもいいし指定してもいい
これだけで1回の出力で3枚の”同一seedの画像”を出力できる
今日も3090で高解像度なAI絵量産してるが
売らせようと思ってない単なる趣味
>889
9万か…3060の倍近く値がしますね。
確実に3060より性能上なら検討の余地ある気もしますが値下がりしないと微妙ですね。
>868
ビットマップってグラボ選択に影響するのでしょうか。
アンカー間違い?
ビデオテープにはエロ映像など入っていない!ただの
磁気のツブツブだ!とか言いたがる奴
シンセは音の波形を変えれる装置なんだ!といいつつほとんどサンプリング音源だしな
久しぶりにSD起動したけどxformersバグとかあるの?削除したら正常に起動したけど
>>896 3060より4060Tiの方が性能が高くないわけがないけど、値段の差と性能の差のバランスを定量的に見ないとね

ドスパラで3万5千の3060 12GB買ったわ
ここから価格が上がりすぎなんだよ
12GBの3060でも生成するだけなら--lowvram付けて768x512のhi-res4倍くらいはいけるやろと
10年前のデスクトップのビデオカードだけ(多分無理)交換なら4.5~30万
手持ちのノートPC強化なら3080-16GBで28万
出来合い一式買うなら15万~
一発の金額がデカイだけに悩ましい…
>>903 PCIE3でも少ししか性能落ちないから電源がしょぼくなければグラボ交換だけでいけるだろ
3060あたりならOK
4070ti以上ならCPUがボトルネックになってくるのでNGというかもったいない
1111使っているがControlNEt使って高解像度(フルHD以上)で生成するとモデリングソフトの素画像みたいな
色なしの怪しい画像しか出来ない
3060(12GB)だけどVRAMフルに使っている感じだしやっぱりそれの問題なのかな?
俺は筐体と予算の都合から4070に行く予定だ
現在の2070とは比べものにならんだろうし
>>907 的外れかもしれないけれど、ADetailer使ったら画質上がる。少しつくりものっぽくなるけど
>>900 その値段で買いたいわ~
夏には値下がるかな
逆にいうと、「元ネタは既存の画像だ」と言われたらなんでそんなに困るの
符号化レベルの話と何を表現してるかの違いが分からないアホだから
>>905 AMD FX-6300なんだけどいける?
2013年1月の購入履歴見てケース以外総入れ替え必要かなぁとなんとなく思ってた
画像からプロンプト抽出できるのな。キャラ名まで出てくるし。
すごい時代だ。
こことかサイト見て資金的に3060の12GBでPC組みました。
超初心者な質問ですいません。
普通に生成は大丈夫だと思うのですが、スレ見ていてハイレゾ4倍とかはキツイみたいですが、画像サイズを512✕512でハイレゾ4倍とかなら大丈夫なものなのでしょうか?
>>908 現状640*480でhires*2でメモリオーバーになるw
512*384でhires*2でぎりぎり。
そこからtiledとかでアップスケールしようとすると100パーメモリオーバーなんだが、どもならんw
Adetailer、640*480の単倍でつくって適用させてアップスケールとかできんのかな
>>916 512✕512の4倍試してみたけど
xformers使用でvram+メインメモリ(GPU共有メモリ)は21G超えてた
メインメモリ16Gだと足らないね
medやlow-vram使えば行けるかも
easyNegativeV2をダウンロードしたんですけど花札マークからクリックするとネガティブプロンプトではなくプロンプトの方にeasyNegativeと入力されます。
これって正常に導入できてますか?
outputsのフォルダが自動作成されないです
手動で作成しても画像は中に保存されず
>>919 それをネガティブのほうにコピペ
ui側はネガティブなものなのか区別してない
>>916 --medvram --xformers
このオプションでかなりいけるようになる筈
うちは2070S 8GBだけど基本は512 x 792でHires. fix 2,5位で使ってる
それ以上にしたい時はi2iに送ってアップスケール
>>919 ネガティブプロンプトの方のテキストボックスクリックしてカーソル出てる状態で押せばネガティブ側に入力される筈だけど
>>916 拡張を入れなされ
とりあえずTiled Diffusion
それで3060なら8kだって出せるようになる(奇形化防止に苦しむけど)
ただしデカいサイズは生成に時間がかかる
とりあえず2kなら3分、4k程度なら数分で終わるのでまずはそれをやってみて
>>921 >>923 ありがとうございます!
Negativeプロンプトの枠をクリックしてから操作したら正常に使えました。
助かりました
>>920 i2iでもメモリ不足でこけるんだよね
なんつても2070(8GB)という骨董品なもんで・・・
xformersは使っているので、medvramも追加するか・・・
medvramは速度低下以外にデメリットありましたっけ
>>922 ワシの8GB(2070)じゃむりだった・・・
--medvramいれてみますわ
非SLIで二枚ざしした場合、VRAM増量の恩恵は受けられるのだろうか?
質問なのですが
https://www.pinterest.jp/pin/601371356516837589/ https://www.pinterest.jp/pin/702139398173266226/ ラフ寄りというか塗りで差別化している
雰囲気寄りの絵柄での出力は可能なのでしょうか?
プロンプトで何とかなったりしますか…?
結構色々なモデルを試してるのですがどれも絵が上手すぎて…という状況です
自身でのマージモデル等はためしていません
>>928 別々のGPUで並列して生成とかしかできないそうな、合算ではない
ゲームの交互にフレーム担当とは全然仕組みが違うとか
>>913 おまえはどちらのつもりで発言しているんだ?
>>913 都合が悪いと逆の意味に回り込む奴。
FLmask裁判を思い出すは
>>912 記録を目的としたシステムじゃないから
そういう既存の画像を出すだけの低レベルな事もできるけど、そんな低レベルな代物だと思われたくないって話だろ
定期的に出没する「モデルに画像そのまま入ってる」君
たぶん反AIみたいなの拗らせたのが、知識もないのとりあえず勢いのあるスレに突っ込んできてるのかなって憶測
画像そのまま入っていて、そこからリアルタイムで生成するなんて我々のPCでは不可能だなw
>>937 トークンと画像の集合体からなんとなく薄く色々なところを集めてきて集合体になっていくイメージと思ってたけどそれであってる?
>>914 動かすだけなら行けなくも無いって感じだな
どうせならケース毎変えれば良いと思うけど
古いPCの置き換え用に用意して素組み状態でSDにハマってしまった
環境移行の作業が進まないw
もう一台組むしかないのだろうかw
>>942-943 ありがとう、先月からハマってて低VRAMながらもすでに3000以上は作ってて
すぐに止めたり、livePreviewを見てるからノイズからベクトルというか形状に合わせようとして出来ていくというのは知っていたのよね
ただあのモデルデータの中には「学習した画像そのもの」は入っているかどうかは見たことが無いから気になるんだけど実際は入ってるの?
>>944の
>Stable Diffusionの学習に使われているデータセットのサイズは、
>約2GBというStable Diffusionのモデルデータのファイルサイズよりもはるかに大きいことから、
>Stable Diffusionにそのままデータセットの画像データが残っているわけではありません。
ここをもうちょい視覚的に深掘り説明しているところがあればいいんだけどなぁ
オリジナルデータ入ってないんだ、たしかに2GBにしては足りないだろうと思ってたけど
オリジナルデータを多少なりノイズ化したものが入ってるのかしら
_kaiinui(@Kai INUI)さんがツイートしました:
RTX2080Ti を VRAM 44GB に魔改造した猛者が現れた
2080Ti は GDDR6 4Gb (0.5GB) チップを使っていたため、SUMSUNG の 16Gb チップに入れ替えることで実現
GPU-Z では認識したものの、ドライバ等がうまく動作しないため実用はできない
https://twitter.com/_kaiinui/status/1667899821783666693?s=51&t=v_xy-gl7y1zQf182MLmXWg https://twitter.com/5chan_nel (5ch newer account)
>>916 4070Tiだけど640x640の4倍まではいけた
Torch active/reserved: 24864/25148 MiB
>>946 こう思ってるのかもしれんが
学習データ → 何か → 再現データ
こんな感じ
パラメータ → ネットワーク結合値 → 学習データ
使うときはこう
パラメータ → ネットワーク → 生成データ
>>950 ノイズからトークンで紐付けられた画像からジワジワいろいろ混ぜて再現していく
と思ってた
実際はなんだかすごいな、文字列では想像がつきにくいわ
>>940 ありがとう
ケースが古タワーで場所とってるからゴミになるくらいなら再利用したいのよね
全部変えるならMini-ITXで専用機作りたい
画像サイズをデカくしたいなら3060でも16000x16000とかは出来るでしょ
どういった方法を用いるかは別として
>>937 おまえだよ
自分でプログラミングしたわけでもない他人のソフトで遊んでるだけのくせに
何をしったかで言っているのやら
MMOで初心者にマナー講釈たれてくる奴と変わらないよ
そもそもそんな大きな画像に憧れない・・512x768の2倍くらいでいいよ
>>945 画像にしても.jpgとか.pngといった文字列(encode)化された文字列情報を復元(decord)して表示する必要があるから
ミ●キーマウスなりを復号化できてしまうStableDiffuionにオリジナルデータが入っているか、と言われると否定することはできない
https://gigazine.net/news/20220831-exploring-stable-diffusions/ ただ学習画像に関しては512x512px~1024x1024pxといった形で圧縮して学習しているので
厳密に元の画素数(px)そのもので保存されている訳ではない
https://gigazine.net/news/20221011-novelai-model-improvements-stable-diffusion/ >>929 本当にSLIにしたらビデオカードの使えるメモリが増えるんですか?
>>958 誰も復号の話なんかしてないと思うが?
「学習ソースはインターネットの画像」ってことを言うとすぐファビョって否定してくるよな
>>945がそう言う質問をしたんだな
すまんかった
>>933 何を言いたいのかも分からんが、リテラシーレベルの理解もないアホなのは分かる
モデルデータには児童ポルノ画像が入ってるって言って
暴れてるおばさんとかいるから
逆にっ徹底してロリが出ないようにしてるモデルあるよね
どうやってるんだろ
>>960 SLIってCUDAが対応してるの?
SLIそのものはメモリを2枚の間でコピーしてたし…
次シード
【StableDiffusion】画像生成AI質問スレ13
http://2chb.net/r/cg/1686751262/ ネタかマジか判らんのでマジレス
簡単に言えばSLIは複数のグラボが交互に描画する事で性能を上げる仕組みで、VRAMを増やすとかはないぞ
StableDiffusionの場合、2枚差しした場合
・片方をSDに、片方を他ゲー等に使う事でグラボ単独性能をそのまま維持して使用出来る
・2つともSDに使うようにすると、グラボ1枚目のSDとグラボ2枚目のSDで、2つのSDを同時に動かすことが出来る
というだけで、実際のメリットはぶっちゃけ無い
>>964 理解できないならすっこんどれ
何をうまいこと言おうとしゃしゃってんだよ
「学習ソースはインターネットからの画像」ということは誰も否定できないよな
インターネットの画像を一切利用禁止、ってなったときにSDに何ができるのかって話だけど
写真家や絵描きが自分のリソースで学習させることはできるわけだろ
そもそも本来そうあるべきなのでは?
再度質問なのですが
https://www.pinterest.jp/pin/601371356516837589/ https://www.pinterest.jp/pin/702139398173266226/ ラフ寄りというか塗りで差別化している
雰囲気寄りの絵柄での出力は可能なのでしょうか?
プロンプトで何とかなったりしますか…?
結構色々なモデルを試してるのですがどれも絵が上手すぎて…という状況です
自身でのマージモデル等はためしていません
>>970 そりゃわかるわけない
画像ファイルだって事を説明してよ
>>976 何度も言わないよ
「学習ソースはインターネット上の画像ファイル」
否定したいならどうぞ
>>975 そもそもお前が言う雰囲気とか塗りっていうのは絵描きの人は何て表現してるの? 水彩画風とか、何か呼び方無いの? あればそれをプロンプトにしてみればいいし、無ければそれはお前の頭の中にしか無いから当然学習されていないから無理。
>>978 たとえば文書ファイルなら、文書をエンコードして書き込む、
そして読み込むときにはデコードする
この対になる概念があるわけだよね
画像ファイルや画像のアーカイブみたいなもんだって言うなら、
元の画像を再現出来てないとならないわけだ
>>981 そうかもね
でも「画像ファイルや画像のアーカイブみたいなもんだ」とは言っていないよ
俺は画像ファイルである事の説明を求めて回答をもらいました
違いますか
「学習ソースはインターネット上の画像ファイル」
てのを認めたくない奴多すぎだろ
ダメだww
頭が悪すぎる
ソースがどうこうの話じゃない
認めたくないものだな
若さ故の著作権ガーなどと喚いて痛いお気持ち表明する事を
おまえらは謎のエンコードがほどこされた画像ファイルだと信じてればいいわ
>>973 なら人間の学習もそうあるべきなのだろうか?
果たして人間の学習とAIの学習に違いはあるのだろうか?
レコードの溝を目で追うとね、オーケストラが聞こえてくるんですよ
>>988 つまり認めないってことなのか?はっきりしろよ女々しい奴だな
>>997 でも対戦練習では使いまくってるよね
つかAI利用してる騎士とそうじゃない騎士との差が広がりまくってるよね
藤井聡太が好例だよね
そもそも禁止云々関係なく違いを問うてるのに対し君の答えは明後日を向いてるよ
だって違いは無いから
AIの学習は人間の脳の仕組みを模倣して作られてるからw
lud20250126124854ncaこのスレへの固定リンク: http://5chb.net/r/cg/1685519479/
ヒント:5chスレのurlに http://xxxx.5chb.net/xxxx のようにbを入れるだけでここでスレ保存、閲覧できます。
TOPへ TOPへ
全掲示板一覧 この掲示板へ 人気スレ |
Youtube 動画
>50
>100
>200
>300
>500
>1000枚
新着画像
↓「【StableDiffusion】画像生成AI質問スレ12 ->画像>33枚 」を見た人も見ています:
・クリスタ、画像生成AIパレット実装を中止 - ユーザーの懸念を受け方針転換 [朝一から閉店までφ★]
・■ エロ画像やエロ動画の質問スレ 2 ■©bbspink.com
・【絵柄割れ厨】画像生成AI信者ヲチスレ_59【AI○○】
・【画像禁止】 エロ漫画の作者・作品名 質問スレ 53
・【StableDiffusion】AI画像生成技術12【NovelAI】
・Midjourney】AI画像生成技術交換2【StableDiffusion
・AI画像生成雑談総合 ★1 ヲチ・グチなど
・画像で質問! これなんてエロゲ? Part52
・画像で質問! これなんてエロゲ? Part32
・大学の同級生の女の全裸画像がネットにあったんだけど質問ある? [無断転載禁止]
・AI生成画像のブームが一気に終わった ★2
・【竹島問題】 世宗市の女子中学生たちによる抗議の手紙に日本「大騒ぎ」〜送り先の中学校でなく島根県が対応(画像)[12/17]
・画像で質問! これなんてエロゲ? Part81
・裸の画像がネットに流出して人生積んだ女だけど質問ある?
・【人工知能】「視線ひきつける」仕組み、画像生成AIで解析 京都大学 [北条怜★]
・【悲報】画像生成AIで静岡が水没したデマ画像を作ってアップする奴が現れる SNS崩壊へ
・【JS】女子小学生 高学年画像スレPart12【JS】
・【沖縄暴動】 沖縄署騒ぎの発端「高校生が警棒で殴られ失明」、負傷画像から元刑事・小川泰平氏が食い違う警察発表に疑問★2 [トモハアリ★]
・画像で質問! これなんてエロゲ? Part53
・画像で質問! これなんてエロゲ? Part67
・JK 女子高生画像スレッド:Japanese school girl thread
・【画像】女子小学生(10)「先生、この問題わかりません」
・【悲報】絵師さん、あと数日で全員失職へ 超高性能画像生成AIが無料公開予定
・【画像】渋谷にエロいコスプレした女子小学生グループ★2
・【画像】生活保護オレ、涙の訴え「生活保護費が少なすぎて苦しい。あなたは月10万で一人暮らしできますか?」
・AKB48『FNS歌謡祭』出演決定!「結成15周年特別企画として“ある卒業生”と一夜限りのコラボパフォーマンス」
・【画像あり】秋田でスープラ乗ってるけど質問ある?
・【画像】これがセンター試験の世界史で「100点満点」を取った生徒の問題集
・小学生のエロリ画像を集めるスレ180 ©bbspink.com
・【JS】女子小学生 高学年画像スレPart17【JS】
・【JS】女子小学生 高学年画像スレPart2【JS】
・【画像】女子小学生コスプレイヤー愛菜たん、口元を見せる
・【JS】女子小学生 高学年画像スレPart16【JS】
・【STAP論文問題】小保方氏「これは若山先生の実験部分じゃないですか」画像誤り指摘で反論[5/23]★3
・【JS】女子小学生 高学年画像スレPart19【JS】
・【JS】女子小学生 高学年画像スレPart13【JS】
・【JS】女子小学生 高学年画像スレPart14【JS】
・【JS】女子小学生 高学年画像スレPart15【JS】
・【STAP論文問題】小保方氏「これは若山先生の実験部分じゃないですか」画像誤り指摘で反論[5/23]★2
・【JS】女子小学生 高学年画像スレPart16【JS】
・【JS】女子小学生 高学年画像スレPart14【JS】
・【JS】女子小学生 高学年画像スレPart11【JS】
・デレステの3Dモデルが生身の身体になる(画像あり)
・【画像】女子中学生、エッチなコスプレをしてしまう
・画像質問大歓迎!このエロゲ何 Part7
・【JS】女子小学生 高学年画像スレPart16【JS】
・【JS】女子小学生 高学年画像スレPart16【JS】
・美人声優種田梨沙ちゃん誕生記念画像スレ
・2852万円貯金がある期間工だけど質問ある?(画像有)
・【JS】女子小学生 高学年画像スレPart13【JS】
・生野陽子 (ショーパン) in 画像板 part12
・【JS】女子小学生 高学年画像スレPart15【JS】
・アル中カラカラ男が人気 125万回再生(画像あり)
・【エロゲー】画像で質問!これなんてエロゲ?Part45
・アル中カラカラ男が人気 125万回再生(画像あり)
・【JS】女子小学生 高学年画像スレPart13【JS】
・【JS】女子小学生 高学年画像スレPart13【JS】
・【性的画像問題】 チアリーダーの隠し撮り画像流出 「身の危険感じた」 [ベクトル空間★]
・【画像なし】女子小学生(11)のおまんこ、キレイすぎる
・【ダビスタ】ダービースタリオンマスターズ初心者&質問スレ41頭目【ダビマス】
・Windows 10 質問スレッド Part73
・【JS】女子小学生 高学年画像スレPart4【JS】
・【JS】女子小学生 高学年画像スレPart6【JS】
・【JS】女子小学生 高学年画像スレPart9【JS】
・【画像】羽生結弦さん、リプニツカヤさんとイチャつく1820
・生き物苦手板エロ画像スレ
22:48:54 up 12 days, 23:52, 1 user, load average: 8.10, 8.28, 8.79
in 1.9038290977478 sec
@0.056797981262207@0b7 on 012612
|