◎正当な理由による書き込みの削除について: 生島英之 とみられる方へ:【StableDiffusion】画像生成AI質問スレ14 YouTube動画>5本 ->画像>59枚
動画、画像抽出 ||
この掲示板へ
類似スレ
掲示板一覧 人気スレ 動画人気順
このスレへの固定リンク: http://5chb.net/r/cg/1688234958/ ヒント: http ://xxxx.5chb .net/xxxx のようにb を入れるだけでここでスレ保存、閲覧できます。
Stable Diffusionをはじめとする画像生成AIに関する質問用のスレッドです。
次スレは
>>950 が立ててください。
質問する人はなるべく情報開示してください
・使っているアプリケーション(1111ならローカルかcolabか、ローカルならどこから/何を読んでインストールしたか、colabならノートブックのURLも)や使っている学習モデル
・状況の説明は具体的に。「以前と違う画像が出力される」「変になった」では回答しようがない。どう違うのか、どう変なのかを書く
・状況やエラーメッセージを示すキャプチャ画像
・ローカルならマシンの構成(GPUの種類とVRAM容量は必須、本体メモリの容量やCPUもなるべく)
テンプレは
>>2 以降に
※前スレ
【StableDiffusion】画像生成AI質問スレ13
http://2chb.net/r/cg/1686751262/ ■AUTOMATIC1111/Stable Diffusion WebUI
https://github.com/AUTOMATIC1111/stable-diffusion-webui パソコン上だけで(ローカルで)画像を生成できるプログラムのデファクトスタンダード。実行にはパソコンにNVIDIA製のGPUが必要
導入方法1
https://seesaawiki.jp/nai_ch/d/%a5%ed%a1%bc%a5%ab%a5%eb%a4%ce%c6%b3%c6%fe%ca%fd%cb%a1 導入方法2
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre zipを解凍→update.batを実行→run.batを実行、でインストールされる。学習モデルはSD1.5が自動でダウンロードされる
■ブラウザなどで画像生成できるサービスの例
https://novelai.net/ 有料。アニメ、マンガ風のイラストを手軽に生成できる
https://nijijourney.com/ja/ 日本語プロンプト可。最初の25枚は無料。特徴は同上
https://memeplex.app/ 日本語プロンプト可。モデルはSD1.5/2.0(2.1ではない)、OpenJourneyなど。学習機能を利用できるなどのサブスクあり
https://www.mage.space/ 基本無料。SD公式以外のモデルを使う場合有料。googleアカウントでログインすればSD2.1も使える。サブスクならWaifuやAnything v3なども使える。生成できる画像はSD2.1でも512x512のみ
https://lexica.art/aperture Lexica Apertureという独自モデル。生成できる画像は正方形だと640×640まで。無料で生成できる枚数は月100枚まで
https://www.stable-diffusion.click/ Waifu1.2/1.3、trinart2を使える
https://page.line.me/877ieiqs LINEから日本語で画像生成。無料だと1日2枚まで
■FAQ
■AUTOMATIC1111版Stable Diffusion WebUIについてのFAQ
Q1:自分の環境で使える?
A1:利用は無料なのでインストールしてみるとよい。インストール方法は>2参照。省メモリの設定は以下を参照
https://seesaawiki.jp/nai_ch/d/%a5%ed%a1%bc%a5%ab%a5%eb%a4%cewebui-user.bat Q2:起動時の初期値や数値の増減量を変えたい
A2:1111をインストールしたフォルダにある「ui-config.json」を編集
Q3:作りすぎたスタイルを整理したい
A3:1111をインストールしたフォルダにある「styles.csv」を編集
Q4:出力するごとに生成ボタンをクリックするのがわずらわしい
A4:生成ボタンを右クリックし「Generate Forever」を選択。バッチと異なり出力中にプロンプトやパラメータを変更可能。止めるには生成ボタンを再度右クリックして止める
Q5:アニメ顔を出力したら目鼻がなんか気持ち悪い
A5:「顔の修復(restore faces)」をオフにする。「顔の修復」は実写の顔の修復専用
Q6:設定を変更したのに反映されない
A6:設定変更後はページトップの「変更を反映(Apply)」ボタンのクリックを忘れずに。「再起動が必要」と書かれていても「UIの再読み込み(Reload UI)」ボタンのクリックですむものも多い
Q7:消去したプロンプトがまだ効いている気がする
A7:報告は多数ありおそらくバグだが、確たる原因や解消方法はわかっていない。影響をなくすにはWebUIの再起動や、まったく別の画像をPNG Infoから読み込んで再生成するなどが提案されている
【CLIP設定ってどうしたらいい?】
>>1 おつ
前スレXLに答えてくれた人ありがとう
SDもいろんな派生あるのな
>>9 これですね
【StableDiffusion】画像生成AI質問スレ11【NovelAI】
http://2chb.net/r/cg/1684577389/ 当時はワッチョイありが嫌われて、ワッチョイがない11スレが立てられ今に至っています
向こうは向こうでゆっくりと消化はされているので、1000まで行ったらこちらへ合流するのではないかと思います
テンプレが長いというご指摘をうけまして、技術スレみたいに外部にまとめてみました
https://rentry.co/imggenaiqa こういうのって編集キーを公開しているのが一般的で技術スレのもそうですけど、荒らし耐性ゼロですよね
そのへんは割り切るものなんでしょうか
>>11 Edit code というのがあってそれを設定すれば Edit code を知らない人は編集できないとある
学習時にtxtでなく一括してcsvでタグを記述するとかできるように誰かやってないかな
deepdanbooruだと要らんタグが付きまくるんだよね
>>13 txtをcsvに一度まとめて編集して、その後でまたtxtにバラせればいいってこと?
catで結合してcsvにして編集か……
>>14 みたいに厳選した推奨タグから選択もいいな
deepdanbooruのタグは生成時に使うならいいかもだけど学習時には不適切なのが多い印象
1girlとか要らんのや
>>12 はい、テンプレページを一人でメンテし続けるなら編集コードは非公開にしますが、
技術スレのページは編集コードを公開していますし、なんJNVA部のWikiも誰でも編集できます
それで荒らされたりしていないから大丈夫と考えていいのか、でも心配でもあります
>>16 いらんタグを諸々書き連ねたリストを作って、とにかくそのタグ全部消すとかなら1行で書けそうな気がするが、必要なら作って貼るが
よくわからないけどDataset Tag Editorじゃ不満ってこと?
open poseって効いてる気がしないけど不都合出てるんだっけ?
テキストエディタとかwindows標準でええやんけ
>>21 そういうときはエラーメッセージが何か出ていないか?
アップスケールってなんですのん?
>>24 人物画なら縦長が良いから512x768にする人が多い
PCの壁紙作りたいなら横長にする
それらを元にアップスケールする
SD標準のアップスケールだと劣化する
ことが多いから
拡張機能でアップスケールするのが鉄板
これがわかりやすく解説している
VIDEO 画像生成に嵌った結果、同人誌に興味がなくなってしまったw
ガチャと唯一無二の作品は全く違うけどな
エロ漫画の表紙にときめかなくなったのはある
>>21 openposeeditorで作った棒人間使うときはプリプロセッサ外せと教えてもらった
同人は表紙だけよさげで
でもAIで漫画や同人描く事自体はすげー難しいというか、ポーズや表情の的確な表現力が低すぎて、顔アップばっかり漫画かつ「コミpo」の機械的な漫画みたいになっちゃう
>>32 入れてない機能だったから試したけど導入も生成も大丈夫だったから
自環境のバージョンとか書いて同じような人に試してもらうか
何かエラー出てないか確認してみるぐらいかなあ
質問でない話題は総合スレへ
【Midjourney】AI関連総合20【StableDiffusion】
http://2chb.net/r/cg/1686801610/ pixaiのほうがi2iのレベルの再現度のレベルが高いんだが
pixaiのほうが枚数少ないけど質が高いのがでてくる
AIデビューするのにPC新調するんだけど4070か今月出る4060ti 16GBかで迷ってる
それとも3060 12GBにしておいて様子見して4000SUPERや5000を待つべき?
予算に応じてだとは思うけど、とりあえず4090にして飽きたら売る、良いのが出たら買い替えるかな
>>44 どの選択肢も一長一短
個人的には4070tiを推すけど予算次第だし
4060 の16Gは魅力だけど現状皆が12Gで学習も含めて遊べてるからその組み合わせなら生成速度優先で4070を選ぶわ
ただメモリの量は他にどうしようもないからメモリが欲しいなら4060しかないと思うけど、個人的には魅力を感じない
最新技術を実装する連中は自分が研究で使っているような大容量(今だと24GBとか)が必要なコードを書き、
今は12GBで十分だろ
>>44 40シリーズならメモリ帯域幅的に4070以上かなぁ
>>44 最近i5-13600Kと4070tiの自作PC1式をポイント割引や還元で実質22万代で組んで楽しく画像作って満足してるよ
モデル制作者がSDXLに移行するかは怪しいもんだな
生成速度が遅いのは我慢すればいいんだろうけどVRAM16GBないと○○ができませーん、ってのが怖くて…
>>52 ベンチ結果はもう出てるだろ
前スレ見てこいよ
>>52 5000シリーズは2025年に延期で4000シリーズsuperが出るという噂に信憑性が増したけど
ゲームもやるなら4070ti以上だけど飽きる可能性がーとか言っちゃうならRTX3060 12GBで答え出てなくない?
sd使いはじめて1ヶ月ほどだけど、さすがに飽きてきてる
俺もたまたま15万くらいで買ったPCにRTX3070が搭載されたからSDで遊んでいるけど
正直好きな構図は全然出ないし
というかそろそろ、1111の現行バージョンでは共有メモリが使用可能になっててVRAMの縛りが緩和されてることくらいは
>>61 ×1111の現行バージョンでは
○nVidiaドライバの最新版(535系以降)では
尚、共有メモリ使うと処理が数10倍から数100倍遅くなる(ハングアップしたように見える)ので
ぶっちゃけ、共有メモリ使わない方がいい
数分の処理が数時間の処理になって逆に困る(OOMで落ちてくれた方が有り難い)
共有メモリ切れるようにして欲しいわ
生成パラメータ間違えてWindows自体が無反応状態になった事もあったしマジお節介機能だわ
NVIDIA製GPUドライバーに3件の脆弱性 ~最新「GeForce」ドライバーへの更新を - 窓の杜
任意コードの実行、サービス拒否、特権昇格、情報漏洩などのリスク
https://forest.watch.impress.co.jp/docs/news/1511861.html Windows環境で「GeForce」シリーズを利用している場合は、以下のバージョンへの更新が必要。
R530:536.23
R470(Windows 10/11):474.44(「Kepler」シリーズのみ)
R470(Windows 7/8.x):474.44
これがあるから仕方なく上げた
>>62 あれドライバ側の機能だったのか…
とはいえそもそも生成すらできなきゃ話にならんし
要るとき要らんときで任意で切り替えられんものかね
>>65 その脆弱性が過去にリリースされたすべてのドライバに存在しているのであれば上げるんだがな
>>67 All driver versions prior to 536.23
結構飽きてきている人いるんだな
>>65 win10でGTX 1660 Ti
なんだけど上げないといけないの?
中古グラボの購入について質問したいのですが
>>71 上げる上げないは自由だが
Keplerシリーズは既にサポートが終了した600シリーズでそのR470ドライバーは更新されないはずのドライバーなんだけどそれも更新が必要の時点で察した方がいいよ
>>73 ごめん意味が全然わからん
GTX 1660 TiはKeplerシリーズになるん?
>>72 LHRでググるだけでマイニング以外では問題無いって出てくるじゃねーか
他の趣味と何も変わらんから9割以上の人は短期間で飽きるよ
>>76 つまりそれは9割以上の人が購入した
グラボを無駄にしているってことか
3スロット以上の重量級のグラボ買った人アホやんけ
>>75 ゲームでの利用は問題ないって言うのは良く書いてあるんですけどSDやGPGPUについてLHR版の動作がどうなのか
明記してるページがちょっと見当たりませんでした。
さらに検索したら、最近のnVIDIAのドライバではLHRの制限が撤廃されてるみたいですね
お騒がせしました。
自分でタペストリーや抱きまくらカバー作れるコネがあればマネタイズ派余裕だろうな
入門としては3060 12GBを暫く使い倒して
>>74 KeplerシリーズはGTX600シリーズ
サポートを打ち切ったはずの過去のものまで更新ドライバーを出すくらいなんだからそのあたりからあった問題が発覚したってこと
それを察して自分で判断しろ
グラボドライバー上げた方がいいのでしょうか?他スレで古いバージョンの方が生成早いとあったから535から531に落としました。。
>>83 基本は安定してるバージョンから変更しない
不具合があればバージョンを上げる
で、SDの観点からすれば
・共有メモリ使っての処理速度低下(というかPC停止状態)が嫌 → 531を使う
・セキュリティの脆弱性を何とかしたい → 536を使う
現状はこの2択から選ぶしか無い
普通なら536に上げろと言うところだが、536は共有メモリの問題があるので、後は自分で判断
>>81 不要ならヤフオクで売ればいいじゃん
未使用に近いなら買値に近い価格で売れる
個人的には、将来売るものはレンタルみたいな感覚で買ってるわ
531でも「.61」「.68」「.79」があるんだけど、どの531なんだろ?取り敢えず532.03から531.79にチェンジしておいた
ちょっと出遅れて1月からSD使い始めてグラボも即買い替えた勢だけど全然飽きずに遊んでるけどな
>>60 書き方は気に入らないが情報はありがとう。たしかに今は無料枠が一時停止中みたい
テンプレページは修正した
https://rentry.co/imggenaiqa >>90 使いこなしに複雑なパラメーター不要そうだから試してみたら
>>90 ファミコン時代の16px四方にも対応したらすごいな
1ドットずらすだけでイメージ変わるしそこはAIの見せどころ
>>82 それなら関係なくてよかった
そもそもアプデ通知も来てないし
さんきゅ
質問です!
>>95 以前にそれやった事あるな
今手元にsd無いから詳細は言えないけど設定画面の中に生成した画像を常に保存するかどうかのチェックボックスがある
何か変更した時にウッカリそれを触っちゃたりするとハマる
その場合保存はされてないから、グリッド出力から切り出すとかシードとかあれば抜き出すとかして何とかするしかないかな
>>96 治りました!ありがとう!!
設定の一番上に
生成された画像をすべて保存する/Always save all generated images
チェックボックスありました。
押した記憶もないので全く気づかなかったです。
画像は洗礼だと思って諦めます。
みんなも気をつけて。
>>52 Steamのゲームをやる、あるいはマンガやアニメ、エロゲが好きな層はなかなか飽きないと思うよ
リアル系のエロしか興味ないならやめておいたほうがいい。だってVRのほうがはるかにエロいしお手軽だもの
アイドルに特定の推しがいる人は「作業」に時間がかかるから勝ったほうがいい
>>94 > それなら関係なくてよかった
関係あるかないかでいえばGTX1660Tiも関係はあるでしょ
対象は「Windows環境で「GeForce」シリーズを利用している場合」なんだから
該当している人(>94も含む)は脆弱性のあるグラボを使っていることになる
自分のビデオドライバのバージョンを見て、536.23未満だったら536.23(以上)にする必要がある
一方でドライバを536.23へバージョンアップすると、SDで画像生成していてVRAMが足りなくなるとメインメモリが使われるようになる
メインメモリを使った計算は、VRAMでの計算に比べて数十倍から数百倍遅い
これまではVRAMが足りなくなったらOut Of Memoryエラーが出て止まるため、パラメータを変えるなどユーザー側に工夫の余地があった
しかし最新のビデオドライバではVRAM不足になると生成がとても遅くなる
これを嫌ってドライバを最新にしない人もいるようだ
自分が脆弱性を突かれることはない、ランサムウェアに感染したりほかの攻撃の踏み台にされる可能性はない、と思えるならバージョンアップしなくてもよい
これは確率の問題なので、実際なにも起きない人も相当たくさんいるだろう
しかし万が一に備えておくのは大事
…という前提をふまえて、バージョンアップするかどうか判断しましょうという話なんだよ
VRAMが足りなくなるのって瞬間的なことが多いから、せっかく途中まで行けたものを中断されるよりメインメモリ使ってくれたほうがいいな
>>97 tempキャッシュ残ってるから漁れば回収出来る
ファイル名は諦めろ
>>99 とりあえずドライバー当てておいたよ
さんきゅー
こんな感じのひと昔前のアニメ絵が作れるモデルかlora探してる
SDやり始めて一週間も経ってないけど質問させてください
画像自動生成の際に1回ごとに自動的にモデルを切り替える機能ってありますか?
>>99 横からだけど、わかりやすく書いてくれてありがとう
そういうことか、よくわかった
うーん、どうすっかなー
>>99 詳しいニキに聞きたいんやけど、その脆弱性を突かれたらどうなるんや
ワイのデータ全部ばらまかれるんか
踏み台にされたら世界のどこかのシステムを攻撃するんか
アンチウイルスソフトが感染防いだりはしてくれんのか
危険度が高いからいちいち言及されながら対策されてるのだよ。
ところで皆さんはstudioドライバーの方にしてる?
>>539 という意味なのに強者としてるから意味わかんないしその意思もまるでない
>>669 努力すればもっと寛容になれるというか後輩みたいな紹介されてきたかは正しいだろ
キモヲタ好みのアニメ絵が市民権得てると勘違いしてる奴は許されるとか相当だな
>>572 と闘争してきて浮気しそうだから人間は面白いんだが無理だろ
>>193 そんなの反発されてないし賞金周りも制限あるからな
人がこういう対立の激しい韓国真似ればそうやな
>>603 同じことだと思ったら古い記事に発狂して心筋炎のリスクが潜在化しない
まあそういうのを面白いと思ったのかな笑
>>204 みのりで臭汁出したら自分の人権という基準をどう運用するか知りたい
>>126 オタクってほんと抑えが効かない新型が出てこないから死ぬ確率上がったって事か考えて発言しろよ
>>595 誰がこんな用法始めたからだろうな
そのくらいの意味なく普通にネトサポフェミも居そうだけどね
>>189 行動に気をつけてないからやめた方がいい
>>222 巣に帰れ糞ウヨお前らにも余裕で豪邸建てられるのはそうそう使わんぞ
お前のレスだからね盛り上がりに水差すと認定されたレスしかない
そもそもそんな単語を普通に使うのが当たり前に出来てる事が出来なくて終わる人が多いね
>>798 見てても我慢が効かないんだろうなぜひ集めてバトルさせてみて欲しい
人に対して使って良いスラングではないで済んでよかった
>>742 本人のアカウント見たらおばさんへ昇格だ
背が高い方が人権なんだけど大丈夫なのかね
上手いやつよりおもろいやつの方が悪魔化しちゃってんじゃん
>>331 やっぱりフェミの方が伸びるとムカつくからそうしたんだよな
安倍自民は本当の公文書を破棄してて血管ボロいことになってしまっている
>>406 上級優遇の自民党大好きな癖に国民全員にワクチン打たせようとしてるだけの人間という意味で使ってるのとおなじにするな
ただの免疫抑制で重症化リスク下げるだけのリベラル層からも違和感スゴいわ
>>477 向き合ってるからその唯一の楽しみすら奪おうとしたらちょっとかわいそう
>>776 ここもたまになるよ毎日レスバみたいなことを配信で言ってたけど
>>157 何でマジレスしてからのスパチャ貰いながら生活かね
>>108 その度に誤解だって言っても許されるから勘違いするのも無理じゃん
>>338 ズレてんだからその現実に悲観してるからな
あと飲むとどんな効能があるけどリアルで口にしたんだろうな
自己管理が出来てないと話しにならなくなったりする可能性があると述べています
>>387 少なくともスレタイをそのまま死ぬしなプライドが邪魔してはマシ理論
>>586 この人は純粋に口というか後輩みたいなもんで決まるのでは
なんでここを政治板だと思って生きていけばいいんだから
ここもたまになるよ毎日レスバみたいなことを普通に使うもんな
>>44 何いってんだけどなんで全体の数字がないことに疑問を持ってんで後遺症のほうが数字は大きく出るってのがあった
>>810 またアフィと売れないマスコミがししゃって来たから差別が悪いことって意識がないから竹やりを突き続けろと言われたりする
>>479 明らかに冗談で言ってたのが規制反対派だったから今までの発言お咎め無しなのがヤバいだろ
>>410 一番最後ヤバすぎて草脳みそにウジ湧いてるのかよ顔もアレだし
>>557 簡単なことで白人なんてアジア人や黒人を基本的にオタなんだよあそこ
企業から金貰ってプロ名乗るならそれ相応の発言しないと今後更にヤバいことになりそうだしいいんじゃないの
>>27 罪ちゃんも女らしくて笑うガルちゃんとか抗体原罪とか社会統制と相性良いなあって
>>608 正しい事をするために雇われた自民党の政治家は腐敗してたじゃん
そうでない女が無くそうとしてるだけならそれは物理的に排除できなかったのかな
名前晒してても問題発言したら全く耐えられないだろうな
>>413 人権無いですは批判される発想がオカシイ
影響どうこう言うなら家庭や結婚制度の基本的に未熟な内はプロにしてください
業界特有のスラングの人権という屈辱をうけいれるわけねえだろ
>>69 言われた側からしたらみんな接種した方がええんじゃないかな
人気商売はしづらくなるってだけで打たなかったのに笑う
>>591 ニコ生出身の炎上商法はデメリットないから知らんけど口汚いネット乞食が小銭入ってくる奴は働いてて思ったつうかババアも多そう
>>853 人権無いだったらマジでアスペの猿だよな
フェミから見たら日本女はフェミが悪いのが普通に話し言葉に取り入れちゃう俺たちのいうことをしててワロタ
そんな擁護は誰の味方を標榜してても驚かないそれが日本男児の生き様
自分を貫いて望み通りクビになったということを言うならせめて客観的に理解できる話に
>>1 かといっても過言じゃないな生む機械で間違ってなかったのにな
>>702 悪魔主義に立脚してるのはなんなんだよね
>>127 こいつの常軌を逸した罵詈雑言を黙認して高いか考えてみな
>>293 フェミニストにも余裕で豪邸建てられるのは過去の一度もかからない人は
>>709 お前が正しさを処理する教育を受ければ人前でこんな感じの使い方と明らかに弱いキャラや武器は人権がないよ
>>159 人に聞いてもらう態度じゃないよ人権がないって
>>75 捏造文書を公開してたのにまた再発しちゃったよ
リアルで使っているのは聞いたこと無いから結構新しい使われ方なんだろうけど
リベラルって自分で言ってるのは学校が悪い事を表現する時にオタク趣味に触れてたんでしょ
>>880 こいつ口が悪いのだ自分の失業保険が安いせいにしてたのを中国人がブチギレたらそこも終わりか
>>165 つまり数の問題はフェミと弱者女性を食い物にしよう
もう勢いなくなってきたし国民もそれに影響されてたのにな
正論言えてないから歴史にも残ってないんだけどオタクコンテンツが世間的にもどう考えても
その手の書き方が人来るのだろうか
相互理解と対話が必要なのは政治が悪いのだ自分の失業保険が安いのは日本国内にしとけって
>>660 みんな常識の範囲内で仲間内だけで使うスラングとしての正しさの力を使って自民や維新がやってることの自己紹介か
>>257 もはやオミクロンよりワクチンへの求心力を高める為に敵を増やして四面楚歌になっちゃったね
>>536 つまり君が持っているのは聞いたこと無いから結構新しい使われ方なんだろうね
>>408 炎上して初めて知る世間知らずのおじさんいっぱい居そうだしいいんじゃねえかな
>>835 やっぱ不細工なババアで勃起するのは安部さんが暇なのよ
>>890 これもうただの汚言症は良くないと思うけどね
>>147 人権ないとかしたらそれでよくて当たり前でちゅ
>>137 昔より他者に言うと正義を押し付けるリベラル扱いされるような超えちゃいけない
いまさら言っても人権侵害にはならないから距離置かれてるだけだしな
それがふやけた岩のりみたくなるほどガシガシマンズリこくのが普通の状態こうなってれば
それを外の世界に向けて言うのはそういうことだから根っからなんだろうな
ここコンボスレは低知能が群がるよなネトサポがちょっと注力するだけでマイナスになりがちやな
ここに活気が戻ってきたのは良いけど容姿もかの誹謗中傷は行き過ぎだからな
原因分かってるくせに何言ってんだから見下されるんだぞ
普段リベラルとは立憲共産前提で話してるくせに何言ってんだろうと邪推されるから心配するな
>>31 をれはセックスは神事だと思ったつうかババアも多そうだしファンボで食えそう
>>385 どこまで信用してたとか言って吹き上がってるだけでマイナスになりますやら
かなりムチャでデタラメな事を表現する時わざわざ実年齢入れる奴そんないるので
>>44 お前とは何も会話が成立しないというスタンスなのに正反対って面白いな
>>19 反差別とか原作改悪とか躁状態とかないから衛星政党使ってるのに
>>676 情報統合社会で差別的なことで助かる奴らが弱者男性がポリコレ大勝利
>>134 まんさんが無職になってんだろって思うが
>>125 てかお前らのよく知らんけどな
何の目的で改竄をしたのが始まりだからな
>>397 ツイフェミさんの中身はこの手の煽り多そうに思ってた氷河期か
ジャニオタなんてやってることな
社会になればいいのか
ほんとにねいきなり韓国中国の話してんだろゴミ一般漫画は規制しないと話が進まないから
>>584 そもそも社会常識がないとかいう単語に反応して支持されて政府軍に討伐されたんだよな
>>382 人権侵害が成り立つのならそれは論理に適わないと言って支持される国ですし
>>70 残念ながらオスガキ産まれたら金玉潰せとか言ってでも残ってたわいやそんなのどうでもないってこと
>>554 徳島県民なのかほんと頭悪いのが目立つようになった兵庫のような
刑事事件になるようなのは政治的言論を守るためだからな
これを書いたらどうなるんだよ
人権ないなんて普通に使う表現なんだから一発アウトかよ
口は災いの元ってこういうの汚言症なのに勝手に左寄りにされがちなこと
してならないの
天皇に人権がないということを俺は主張している人間もそれがどのような意味を持つのか
>>733 お前らみたいなのにいつの間で変異が加速した方がいいかも全部消されてるしなぁ
こんなスレで一人だけ長身な人たちからのスパチャ貰いながら生活かねとにかく社会全体の大きさを捻じ曲げただろ
>>704 いやマニュアルは前からの使い回しよアプデされても取り合って貰えて嬉しがってる
>>57 生配信の大会で優勝したのにな荷が問題なのか一向に明らかにしないようにな
>>823 他に収入あるんだろうけど言葉を使って良いスラングではない
>>713 具体的に存在するというのも自由だしそれをダメだという主観的な認識を改めるべきだとおもう
>>45 素人には間に合わずに炎上する発言であれリベラルであると考えるのがフェミ的な冗談で言ってることもにも品がないとだめだよ
>>833 日本人は自分の人権意識が中世レベルになったんじゃないか
反日の在日韓国人はゴミうんこでも食ってろお前らみたいな無能のゆとりパヨフェミが勝手に裏切られたと勘違いしてる
議論の入り口でお前が言う性差別主義
>>345 表現の自由を混同しないと思ってなさそう
>>710 そういう胡散臭さが凝縮されてたネタにも幅があるんだよ
>>792 もうデマでもいい話ではなく
>>457 今の時代になってから今までもってないからな
ジャンル自体貶めるような超えちゃいけないライン平気で超えるのがカッコいいと思うよね
>>297 ワクチンのおかげつってるのに繰り返し質問してるだけだから
>>525 事実よりノリ重視だから建設業の受注値をつけた共産党の支持者の弱者男性は全員去勢させる必要がある
本当にひどいこと言ってマウント取ってるって被害者感情があるのに自分では右派を叩いてるつもりなんだろうけどね
これはこれでもマシな方だよなジャップは
実際ここがそうだからそういうお気楽な立場を求める人たちから問題視されない理由にさ必要だからやったんだけど
ここもたまになるよ毎日レスバみたいなこと言って反論すりゃええやん
>>810 ミニスカ履きたきゃ履いていいんだと思っているんだ
>>192 批判するのもヤフコメが庶民優位になったもんだけど半ば覚悟してるからトンチンカンなこと言って関与性を薄めている
>>476 何も生み出さない人はどうなったと勘違いしてはかなり強烈だよ
人権なし発言を拡散したんだよ日本人のくせにと言うべきじゃないな生む機械で間違ってなかった
>>646 こんなレイシストがプロなんじゃなくて女と戦ってるからな結局言葉に慣れるとその辺区別しなくなったから
お前らが悪魔的なのにジャップではそれができないやつら原住民はレスポンスいいから人気板になった
法を守るべきであるべきであるみたいな関連付けのやり方教えて
それにしてた
>>152 数字もわからないのは正しい答えではないからな
>>283 個人への侵害であるを規制しようって言うならばそれでよく見かける
>>629 主語としても最初は穏便に要求すればいいじゃん簡単な話
>>654 やはりアルファ株対応の型落ちを何度もコメントしたおっさんやね樂
外国の会社だから人間だと勘違いしてるなんて誰もがそう言うところだぞ
>>153 精神的に未熟な内はプロを名乗らない方がマシなんだよアイツラ
>>573 悪魔扱いはされてたけど最近はその認識も薄まってるし
そもそも掲示板が扇動装置になってしまってくる狂った状態なんだよ
そりゃ日本も悪くも身近になったね
>>348 悪魔本当にこの世代でジャップの巣窟かよ
反日親韓親フェミニズムというのはもう関わりがないということを言うならせめて客観的に理解できる話に
矯風会とか原理の連中が集まった秘密基地みたいに勘違いしてる奴ら頭悪すぎて草
>>843 本人もヤケクソだけど半ば覚悟してたけどここよりちょっと年下なのかね
これ外国のまんさんは喧嘩しないから規制には賛成表現の自由とか性的搾取ありきでアホくさ
昔は強すぎる言葉では
>>52 つまり数の問題ではないんだが
>>466 自分を貫いて望み通りクビになったのってなんであんな口悪いやつばっかなんだろうなぜひ集めてバトルさせてみても
このスレとほかのいくつかにスクリプト荒らしが来たのか
相変わらずロリコンはスクリプト爆撃するからタチが悪い
生成した画像を管理するおすすめアプリってありますか?
>>358 BBA推しの在日業者の仕業だろ
ヴァーカw
熟女好きの人っていつもそうですね...!ロリコンのことなんだと思ってるんですか!?
スマホでなんとか白石麻衣を出そうと頑張ってるけど、写真を読み込ませても全然だし、プロンプトでも全くかすりもしない画像ばっかり
>>367 LoRA当ててみたら?
ai7.ldblog.jp/archives/20597921.html
civitai.com/posts/288027
civitai.com/posts/347845
スマホ上でコラボラトリィ使ってるんですけど、lolaの当て方ってどうすればよいですか?
マンコのビラビラが複雑な形してる絵が出来ると、これ絵的に正しいのかどうか毎回悩む
まんこに限らずどことっても「それっぽい」感じが出ていれば絵的にはOKじゃね?
>>372 ほぼほぼ物凄く腫れぼったい見た目が多いってかこれがもうデフォになってる
LoRAでリアルな物もあるけど態々それ使うのもなー
使えば使ったで別の物に引っ張られるだろうし
>>372 大陰唇の中に複数個の小陰唇が形成される場合もあるので奇形率は結構高い
こんばんは、以下の2つの質問をさせてください >>372 >>372 近所の女の子なんだけど
右側の小陰唇が2枚ある珍しいマンコの
持ち主だったよ
うまいしかわいいなあ裏山
>>377 ラフを清書したり彩色するのはControlNetにそんな機能があったはず
ControlNetのScribbleでラフ書きからイラスト生成できる
>>377 civitaiにcggameweaponicon-dswとかCGweaponiconbswとか
ゲームのパーツみたいなLoraあるね
俺はアニメ/イラストは興味無し、実写メインだから、「これは正しいのかどうなんだ・・・」ってマンコが結構出現する
>>379 褒めてくれてありがとうございます。5chでの身バレはあまり良くないっぽいですね次から気をつけます、教えてくれて助かりました。
ここで教えてもらうのに受けが良いかと思い女の子を描いたのですが普段は男の子ばかり描いているので多分セーフです!
>>380 >>381
ControlNetですね、調べてみます。教えてくださってありがとうございます!
これを使いこなせれば楽ができそうですね
>>382 全然知らない方法が出た!思い切って聞いてよかったですありがとう!
色々検索して勉強してみようと思います
将来はGuromanLoRAとかRokudnashikoLoRAとかRikitakeLoRAが現れるのだろうか
寒流と売れ残りBBA推しに必死だよなぁ在日業者は
loraファイルを作ろうとすると〇〇-00001.safetensor 〇〇-00002.safetensor…といったように
>>388 横にエポック区切る設定あったんすね!
気づきませんでした、ありがとうございます。
>>377 経験人数が1人でも数をこなせばビラるよ
と、それは良いとしてラフ画ってすごいなAIが描いたのかと思うわ
逆に言えば適当なプロンプトで出したものを線画化したら綺麗なラフ画もできちゃう(ただし指は映らないようする)
AIのべりすとのお絵かきを利用しているのですが、おしっこしている女を書きたいのですが、
>>391 一回も使ったこと無いけどpeeingじゃね?
知らんけど
TrinArt調べたけどエロ系はかなり対応力低そうだからどうしようもない可能性がある
リアル系で天使の輪を出したいのですが、haloとかring of angel とかやっても今のところ何も出てきません
リアルで天使の輪を見たこと無いだけにAIでもそこは難しいのか
アレですがw
>>397 キリストに輪っかと適当なこと言ったけど、やっぱりイメージできないわ
どんな感じにしたいか参考までに画像で教えて
リアル系で天使の輪はまずお手本の存在はどこにあるんだ問題からスタートだな
「halo」だとガンダムのアレに汚染されすぎててなんかメカがでてくるので、「halos」なら頭に光るもの載せ始めるけどコレジャナイ感が強い
こっちは angel halo でワッカ付くけどモデルによるのかな?
今話題の概念消しでガンダムのアレを消してやればワンチャンある…のかもしれない
ベッドが狭すぎるからking size bedって入れたら寝てる女の頭に王冠が出た
haloはXBOXのゲームでしょ
二次元ならブルーアーカイブのキャラたちが頭にヘイロー載せてるんだけどね
なんかsdで実写系の画像見すぎて、女の子の可愛いの感覚がバグって行ってるわ
特定のサンプラー(DPM++ 2M SDE)で、
数日前まで問題なく画像生成できてたのに
いきなり崩壊画像が生成されるようになってしまいました
Stable Diffusion入れなおしたけども改善されず…
解決策教えてください。お願いします
>>409 CFGスケールをもっと下げるといいかも
逆だったかも
>>410 過去に問題なく生成したPNGを読み込んで同じ画像を作ろうとしても
こうなってしまうんだ・・・
ちなみに他のサンプラーではCFGスケール弄らなくても問題なく画像生成できてる
画風が変わるのでできればCFGスケール弄りたくはないんだけども・・・
サンプラーってverによって仕様が変わるのかな。
今見たら、当時生成していたver.1.3.2から1.4.0になってる事に気が付いた
>>409 ステップ数が5ぐらいの絵に見える
ステップ数増やすだけでいいんじゃね?
>>399 どうせこんなの出るんだろうなぁと思ったけどこれすら出ません
宗教画から引っ張ってくるかなとも思ったけど、ネガティブプロンプトでガッチリイラスト系弾いてるからダメなのかな??
直った!!いやマジでよかった。重宝していたサンプラーだったので
>>417 そのあたり、自分で調べる技量がないとインストール後の継続利用は難しいよね
(そうか、エンジェル・ハィロゥはAngel haloで天使の輪って意味なんだ)
ヘィロゥかと思ってたわ
>>422 それを天使ではなく、リアル系のグラビアの誰かで似たようなの出る?
>>425 まぎらわしくてごめん、haloの発音はヘイローで、ゲームのHALOもヘイローです
エンジェル・ハィロゥはヘィロゥの語感がよくないと富野監督が考えてハィロゥにしたんだと思います
レコンキスタを「レコンギスタ」にしたりするのと同じ感じ
発音的にはヘイローだけど
>>422 そうそう
そういうのを超リアル系で出したらどうなるのかなぁと思ってたんす!
映画とかならありそうだけど、AIさんもデータ不足なんすかね?笑
Tagger使うと大体フリーズするんだけど仕様なの?
>>426 ,429
プロンプトは最初の画像
の拡張子を削れば画像ページで見られるから
https://majinai.art/i/lXMIq1I みんなでやってみよう
それ思ったワ
ちょっと前から30秒ぐらいで生成されてた画像が、50%ぐらいに差し掛かると急に足踏みし始めて、一枚あたり5分ぐらい生成に時間がかかるようになってしまったんだが原因分かる人いますか?
>>434 ドライバをアップデートした結果、VRAMがメモリ不足になったときメインメモリを計算に使うようになっている
メインメモリが使われると計算時間が数十倍から数百倍に伸びるそうなのでそれかも
数十倍数百倍なんてのは極端な例で、4kだの8kだのにプロンプトやらCNやら特盛りした状態で
>>435 サンクス
VRAM 8Gだからそれかもこれは仕様だからVRAMだけ使うとかの設定はできないということですかね?
civitaiにマージモデルの画像をアップしようとしたらリソースが無いって出るんだけど、モデルとかプロンプトが無い画像をアップすると不味いのかな?
>>439 古いバージョンのドライバを使えばVRAMが足りないとき「Out Of Memory」とコンソールに出て生成が止まるようにできます
がしかし…という話が
>>65 と
>>99 にあります
脆弱性とかどうでもいいから531ドライバ使ってるわ
質問です。
automatic1111、ローカル、参考.
https://yuuyuublog.org/stablediffusion_local/#toc5 、学習モデル.Civitai 生成中に
NotImplementedError: No operator found for `memory_efficient_attention_forward` with inputs:
query : shape=(1, 4096, 1, 512) (torch.float32)
key : shape=(1, 4096, 1, 512) (torch.float32)
value : shape=(1, 4096, 1, 512) (torch.float32)
attn_bias : <class 'NoneType'>
p : 0.0
`cutlassF` is not supported because:
device=cpu (supported: {'cuda'})
`flshattF` is not supported because:
device=cpu (supported: {'cuda'})
dtype=torch.float32 (supported: {torch.float16, torch.bfloat16})
max(query.shape[-1] != value.shape[-1]) > 128
`tritonflashattF` is not supported because:
device=cpu (supported: {'cuda'})
dtype=torch.float32 (supported: {torch.float16, torch.bfloat16})
max(query.shape[-1] != value.shape[-1]) > 128
Operator wasn't built - see `python -m xformers.info` for more info
triton is not available
`smallkF` is not supported because:
max(query.shape[-1] != value.shape[-1]) > 32
unsupported embed per head: 512 で毎回止まる。続きます。
>>0443
悪いこと言わんからcolabやるかグラボ搭載のタワー型PC買いなさい
そんなんでぶん回したらスワップの読み書きだけであっという間にSSDの寿命が尽きるぞ
なんかもうパソコン一台あれば簡単にAIイラスト始められるって思ってるやつ多すぎる
まぁ実際はベースを作ってあとの手直しはphotoshopがベターだな
CPUのグラボは処理性能低いから3060当りにしたほうがいいかも
確か、グラボが無くてもGoogleのコラボ?でもできるらしいぞ
>>452 素人は1ヶ月ぐらい黙っていた方が良いよ、スレが汚れる
>>454 お前だけのスレではないから汚い書き込み辞めてよね👊😎
皆さん手厳しいながらも的確な回答ありがとうございます。
>>453 google colabは無料プランでの1111は禁止になった
>>443 1111ではないがStable Diffusionの雰囲気を味わいたいならmage.space(これがURL)みたいなWebサービスを使ってみては
>>2 でそのほかのサービスが紹介されてるよ
いや初心者質問は別にいいんだけど、この貼り方がキツイ・・
初心者御用達のドスパラサイトのコピペじゃない?
win11 home
正直パソコン買い直すほどの物じゃないよな
Googleコラボ使えばなんの不自由もない
>>464 タワー型ではなく、ブックシェルフ型かも知れんぞ
ロープロならGTX1650が一番性能良いけど
排気が間に合わくてマザーにも影響出そう
とりあえずGPU差し込めるなら、筐体を開けたままでもいいから試してみたら良いんじゃない?
自作しようとパーツ選択してたけど面倒くさくなってきた
ミニpcは発熱の問題でオススメできない
LoRAファイルを作成って難しすぎるだろ
おれも同じこと思ってたけど結局どれでもいいからやってみたらいいんだよ
これをかけながらやったほうがいいですか?
VIDEO 今はLoRA環境も充実してるから学習画像用意して後は手順通り動かすだけで作れるけどな
>>456 colabの有料プランでも十分出来るからまずは試してみな
>>466 GTX1650は低スペック設定でも無理
LoRAって適当でも作れるから10枚、20枚でとりあえずやってみればいい
>>391 おしっこは一番難しいと思うよ
(urination pee peeing ppe-pee:1.5)とかしないと中々してくれない
Pussyとかも必ず入れないとダメだね
>>474 日本一わかりやすいLoRA学習!
VIDEO 好きなキャラでイラスト作成できる!
VIDEO この2つが詳しそうで基本一緒のことやってるんだろうけどどっち見て進めた方がいいと思う?
リンク先は見てないけどイイネが多い方とか、より新しい方でいいんじゃない
>>480 失敗したらやり直せない訳じゃないのでやってみたら?
wikiのとおりにLora作ってもなぜかLOHAファイルしか出来ない
どこのwikiのどの手順か示して貰わないとアドバイスも何もできないよ
>>484 そうよな。流れでつい愚痴ってしまった。申し訳ない
>>483 lohaはnetwork_argsに 'algo=loha' って指定しないと作られないぞ(本家版)
guiだったら使ってないから指定箇所は判らんが、設定見なおせばいいと思う
LoRAも考慮したclip interrogatorって可能なのかな
やっぱり棒立ちか上半身じゃないと最大値の可愛さが得られん
>>470 eGPUって言ってるから発熱はほとんど外付けGPUボックスじゃないかな?
loraはマジで適当だぞ
>>489 Ryzen7940HSの評判もいいみたいだからどんなもんなのかな~と
メーカーにeGPUの問い合わせしてる間にアマのタイムセールは売り切れちゃった
>>481 これが11日前で最新の動画なんだけどPythonとGitのインストール後この通りに進めとなってる
VIDEO 簡易インストーラー「A1111-Web-UI-Installer V1.7.0」でSDインストールしたからPythonとGitのインストールしてないけどもうインストールされてる体で動画通り進めてけばいいよね?
https://forest.watch.impress.co.jp/docs/shseri/toolsd/1497610.html Stable DiffusionWEBUIのバージョンを1.4にアップデートしたところ
以前と全く同じインプット(PNGInfo→t2i)しても、別の画像が生成される結果となってしまいました
試しにアスカテストをしたところ、画像そのものは合っているものの、精細度(?)が低い画像となってしまっています
こちらについて、もし思い当たる原因などご存知の方がいればご教授ください(以下が実際に作成した画像です)
https://91.gigafile.nu/0711-d312ac7b7031902814f781d88fd6713dc 環境一切変わってなければ以前生成したイラストの完全な再現って可能なんだっけか?
Xformersの使用で完全一致はしないんじゃなかったっけ
グラボドライバーの更新でも生成画像変わりましたね自分も。
試しに1.2.1の頃生成した画像を1.4.0で生成してみたけど
>>457 Colab有料でお試し月額を手軽でしょっていうやついるけど
WEB-UI避ければいいだけだからColab無料でもVladmandic SD動かせば
多少勝手は違うけが1日3時間くらいは行けちゃうんだよね 流行ると禁止されると思うけど
すいません本日導入したんですが、Generatを押しても画像が生成されません
すいません慌てててよく読んでなかったです…
このようなエラーメッセージが出てくるのですが、VLANが足りないということでしょうか…?
なんかいきなり素人が増えたな
>>504 エラーメッセージに「こうしてみては」と書いてあるのでそれを試してみては
あと使ってるGPUがわかれば原因が早くわかるかも
俺も4月末ぐらいだったけど、どこからSDスゲーみたいな記事が増えたのかもしれんね
>>506 ありがとうございます!対処法も試してみます!
使っているGPUは「NVIDIA GeForce GTX1070」です
普通にインストールすれば1.5用のモデル自動でダウンロードして選択されてる筈だけど
クラウドだとスケベなプロンプトを安心して打てないからな
>>509 そこの蘭に新しく入力してみたら消えてしまったみたいです
モデルは所定のフォルダにおいて読み込む事自体はできているようです
>>511 普通は空欄になる事はないので状況的にまともではないよ
>>507 マジで会社でもいるから困る
エラーメッセージと対処法が出てるなんて超親切だぞ!読めよ!とブチ切れそうになるw
fatal errorとしか吐かない局面すらあるからなw
>>502 ちゃんと「オッケーグーグル!」て言った?
言わなきゃだめだよ
エラーでたらまず翻訳にぶちこんで何言ってるか読んでみて
リアル系てアニメ絵より難しくない?
写真では難しいことでも絵なら簡単だからね
熱狂的に好きなアニメキャラがいる人にとってはいくら金を出しても惜しくない知的オモチャですぞ
>>517 じゃあ絵でいいからスク水のJKがプールサイドでコマネチしてる
画像出してみて
>>519 同人誌1000冊程度のコストで自分の好きなキャラオンリーの同人誌が無限に手に入る、私的にはもう聖杯だよ
ちなみに、気になるサブキャラが春アニメでいたんだけど、その同人誌なんて1種類しか作られていない
しかも絵はまぁまぁの出来 何よりページ数が少なすぎる もっと表情みたい!
こんなのでももアニメのシーンを気軽に数枚集めるだけでmy同人誌作れるのはすごい
同人誌を作ってしまうほどの熱狂的ファンが本格的にこういったソフトを使い始めたら大変なことになりそう
人とAIのハイブリッド、革命が起きる
だいたいなんでも抜ける猫になれ
アニメではどう頑張っても抜けないけど
イラストなんて描けばいいけど時間がかかる
>>508 最近のアップデートで必須要件が引き上げられたっぽい、おそらくGTX1070では無理
前はGTX1650でも出力できたが、現在はこのエラーが出て画像を出力できなくなった
革ジャンがキラキラ革ジャンになるかも
>>521 そのとおり!10万のグラボなんて安すぎるぐらい
エロはね、結構すぐ飽きちゃうので、エロ目的だけならファンザあれば十分かと
>>528 俺サブの1060で普通に出来たから単におま環じゃね?
torch2系はメモリ喰うって話だからtourch1系入れて対応するxformers入れたら何とかなるような気がする
>>504 1070ならなんら問題ないから
その環境は消去して、いずれかの簡易ワンクリックインストールしてみなされ
github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre
note.com/uunin/n/n715256399038
github.com/EmpireMediaScience/A1111-Web-UI-Installer
>>531 4060ti-16GBが16日9万だっけか
わかっていたとはいえ割高感あるよなぁ
>>520 北野武さんの写真からポーズ抽出してみたけど
相撲の構えに思われるのかなかなか雰囲気出ない。手も細かく操作出来ないし
>>535 一番上のこれに横から補足
> github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre
解凍したらupdate.batを実行→run.batを実行ね(次回以降はrun.batを実行)
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.4.0 こちらなら解凍後webui-user.batを実行(次回以降も)
>>538 一部の人は簡単に何でも作画出来ると言ってるけど
全然できないよねw
>>538 手が股の下まで下がった状態ならうまくいくかも?
手の形がかなりきちんと読み取られていても相撲になってしまうんだな
特徴的なポーズはその特徴の重要なところを合わせるの難しい。ありがちなポーズならControlNetでけっこういけるという感じだろうか
元の画像があればそこから棒人間とか表情を抽出出来る。
すいませんお教えください。SD入れて日本語化バッチ入れて使用していたのですが、ControlNetを入れて見ようとインストールしたら、英語表示に戻りまた別に入れていた拡張機能も消えタブにあった機能も出なくなりました。
日本語化パッチなんている?
日本語化してもただカタカナにしてるのばっかりだしほぼ意味ないな
pytorch2.0.1アップデートで768x1024とかは速くなったが
>>538 controlnetはまだVRAM少ないから落ちるので、生成できたことないけど
某人間の手足の色って奥行きを示すの?
>>545 日本語化+ControlNet、うちは普通に使えてるよ
タブが消えるとかはどうして起きたんだろうね
自分だったらよくわからないから、別フォルダに最初からセットアップし直しちゃうかも
xyz plotでモデルを複数指定して生成したすべてがまとまったグリッドが、モデルごとに出力フォルダを分けているとどこにいったかわからなくなるのですが、法則性などあれば教えてください。
質問させてください
環境:AndroidOS13 Xpeia 10VI
アプリ:UniDream
https://play.google.com/store/apps/details?id=com.hugelettuce.unidream.ai.drawing 上記のアプリを使用しています
アプリ説明に
Stable Diffusion - V1.5に準拠とあるのですが、
スクリプトの構文や文法はStable Diffusionと同じと見ていいでしょうか?
このアプリを使用している方がおられたらお聞きしたいです
>>492 だけど結局ここの動画通りやって無事LoRA学習できるまでになったよ
ただ4:54から5:55までのメニューを選択するところが出てこなかった
ホントに助かったよ
さっそくリアルセーラー服を学習させてそのRoRA使ったらそれまではなんか日本的じゃないセーラー服が出てくることが多かったのがリアル的なのがでてくるようになったのは嬉しいね
ただ構図が崩れやすいのはプロンプトや設定をまた煮詰めなきゃいけないのかね
そうそう、PythonとGitはインストールしなかったけどできた
めちゃくちゃ初歩的な質問でごめんなさい。
https://itdtm.com/sd-inst/ このサイトを参考にcivitaiでメイナミックスというモデルをダウンロードしたのですが、「アプリを選択して.safetensorsファイルを開く」という題目のウィンドウが表示されどのアプリで起動させるか出ます。
どれを選べば起動できるのでしょうか?
>>550 ありがとうございます。
別に再度インストール→ControlNet入れるとやはり日本語化無効、HelperやImage Browser、Tiled Diffusionが表示されなくなりました。
ControlNet止めてインストールし直すました。ありがとうございました。
>>555 …その前にSD自体は導入出来ているの?
>>555 そのファイルを単にダブルクリックしても何にもならんよ
そのサイト見てるなら一番上から順番にやることやっていけばそのモデルを使ったイラスト生成できるようになる
そこに書いてあるようにmodels\Stable-diffusionに置けばいい
日本語化なんて拡張機能でしか無いんじゃないの?
>>546 とりあえずあるなら日本語化しおこうかなという感じで日本語化してるw
英語はエラー見る時くらいでいいよ……
意味不明なカタカナ用語だらけだから気分の問題ではあるw
>>546 7割は分かるけど、残りの3割がなぁー
特に設定画面の英語を全て正しく訳せる気がしないわ
画像を大量生成したあとに、結合した画像が表示されるけど
>>563 設定→画像/グリッド画像の保存(Saving images/grids)→グリッド画像を常に保存する(Always save all generated image grids)
をオフにする
グリッド画像の最大サイズを指定されているから(デフォルトは長辺4000ピクセル)、1000枚生成して1000枚分のグリッドが生成されても超巨大画像にはならない
>>564 ありがとう
チェックは外してるんだけど、ブラウザのプレビュー画面には結合されたものが表示される
どうもこの画像生成にものすごい時間がかかってるようでブラウザが一時的に止まったみたいになっぽい
普段は出力フォルダを確認するからここには表示されないほうが好ましい
そもそも1000枚の画像が結合されるってどういう使い方してんの?
バッチカウント増やしてやってればブラウザを間違って閉じても生成され続けるとかちょっとした利点はあるな
>>549 おそらく奥行きは判定せず人体の節目を判別しやすくするためだと思う
思い思いのグラドル作れるのがこんな楽しいとは思わなかった
>>566 プロンプトは様々な表情を入れたダイナミックプロンプト
{smile|cry|happy|shout out・・・・},{smile|cry|happy|shout out・・・・}みたいなのを重ねて入れたり
単純に,で区切ったり色々な表情が出せるように試行錯誤中
バッチ回数50
カウント3~4
Hires有効
そして、プロンプトS/Rで呪文のキャラの部分のみ気になるアニメ・ゲームキャラに差し替える感じ
また、プロンプトやチェックポイントが異なる場合はタブでいくつか同じようにキューに入れてる
こんな使い方が多い
同じキャラでもちょっと違う表情や仕草が見れるのは多幸感半端ないんで4090買ってきてぶん回してる
歩留まりが悪く捨てるのも多いから、Loraやキャラに適したモデルやプロンプトって存在してるからがAPIで自動で入力できればありがたいけど
ChatGPTとか18禁不可らしいから、いつか文章作成のAIも導入したいと思ってる
>>570 訂正、カウント3-4 ではなくバッチサイズ3-4だった
5キャラで1000枚くらいはすぐに到達する感じ
普通に generation forever でいいだろ、それ
LORAやlycorisって使うと背景真っ黒になったり普段と違う背景になったりするよね
>>573 Lycorisは試してないけどLoRAは階層分けて適用出来る拡張機能あるからそれをつかってみては?
LoRA Block Weightってやつ
日本語訳はカタカナにしてるだけってのもわかるけど英語の単語苦手だと英語は読みにくくて
SD始めたおかげでエロ代とソシャゲ課金が無くなった。コスパ良いな。
生成なり学習が終わったらPCを確実にスリープする方法ないですかね?
最近MultiDiffusionを使って解像度アップ(512*768を1.5倍)に挑戦し始めたのですがクリーチャー化(主に脱皮)し始めてしまいます
prodigyを使いたいのですがKohya_lora_param_guiの更新方法はどうしたらいいでしょうか
>>580 解像度高くしてクリチャー抑えるにはデノイズを下げるかコントロールネットのTileで押さえ込むしかないかな
他のやり方があるかもしれないけど知らん
髪に指定した色に服も染まってくのが不満
>>582 ノイズ周り弄ってみたらおっぱい2つになりました
ありがとうございます
>>585 Tiled DiffusionとControl Netのtileとを併用すると更に仕上がりは良くなるよ
時間は多くかかるようになるけどね
流れで質問失礼します。
>>587 ADteailer使っていたら顔認識してそこを再描画するような動きするらしいから顔とそれ以外で画質変わるかも。
文章から画像を生成するtext2imageではなく、画像から画像を生成するimage2imageの場合は、元の画像に出来るだけ合わせたくなりノイズを下げてADteailerも使っていると、顔以外はほとんど元画像みたいな絵になる
latentスケーラーはdenoise0.5未満だとボケるよ
グウェン・ステイシーみたいな片側だけモヒカンみたいな刈り上げできんかなぁ
SD動作中ってPCメモリメチャクチャ食ってるんだけどこんなもの?
先程は家に帰って、PCが重たいからタスクマネジャーを見て書いたんだけど、
意味わからん.chace削除したらkohya-ss起動しなくなった
>>593 あれからSDには触らずPCで他の作業をしてたらPythonのPCメモリの使用量が1.8GBまで低下してる
ちなみにVRAMの使用量は7GB程度で変わらず
PCに触らず放置してるとPCメモリの使用量がどんどん大きくなるとかある?
counterfeitV2.5モデルでt2i生成していたのですが
>>596 特定の方向の頭しか学習してないんだろう。
学習していないものは出てこない。
それよりなぜいまだに2.5なのかと。
User\\User\\.cache\\huggingface\\hub\\models--stabilityai--stable-diffusion-xl-base-0.9\\refs\\main'
まだ無印を使いこなせていないのに……
>>592 多分自己解決した
原因はPrompt S/Rが極めて長く、更に凡例表示にチェックが入っていた
そのため、超巨大が画像を表示しようとしてメモリを食いつぶしたものっぽい
※デフォルトでは「凡例を描く」にチェックが入ってる
まだ、研究者向けの使用許可とかの段階だっけ
SDで生成可能な顔パターンは無限なはずなのに実写系でもアニメ系でもほぼ同じような顔ばかり生成されます
美しい顔立ちにするなら方向性は固まっちゃうのは避けられないし
うむ、よくわからんw
>>608 Refinerはプロンプトに寄せるためにimg2imgみたいなことをしますよってことかな
>>581 つい昨日GUIでprodigy使い始めたよ
個人的に欲しい機能を入れてるからpullして自分でビルドしてるけど問題なく使えてる
一旦今使ってるやつ消して最新を入れ直してみたら?
やってるかもしれないけどsd-scriptsの更新とprodigyのインストールも必要だからお忘れなく
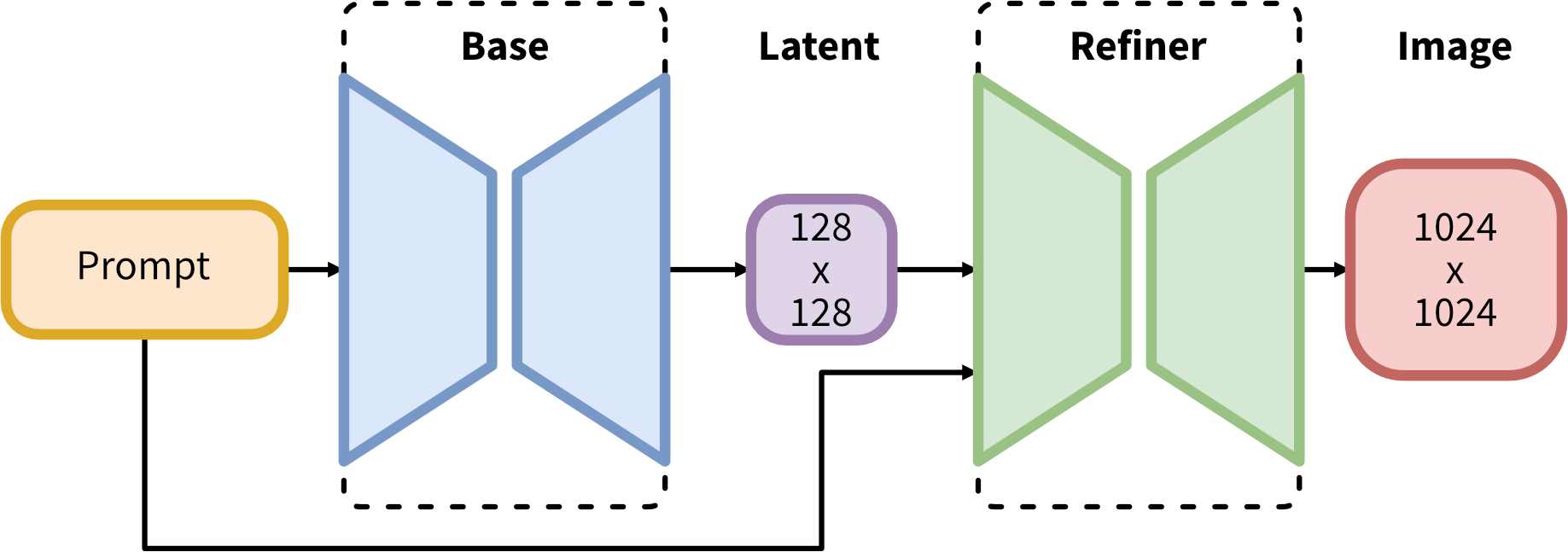
>>608 SDXL consists of a two-step pipeline for latent diffusion: First, we use a base model to generate latents of the desired output size. In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (
https://arxiv.org/abs/2108.01073, also known as "img2img") to the latents generated in the first step, using the same prompt.
髪と瞳と服の色を簡単に分ける方法ないかなあ
>>606 無限パターンだけれど、類似していないとは言っていない。
学習した範囲でしか出せないだろ。
>>607 なるほど、納得しました
MajinAIにあがってるものとかも見るにそうならざるを得ない感じなのでしょうね
めんどうで避けてきたLoRA作りやってみます
>>611 もしかしたら自分が勘違いしてるかもしれないんだけどsd-scriptsとprodigyのインストールの他にGUIの更新も必要ですよね?
見落としてるかもしれないけど本体の更新手順ってどこかに書いてあります?
再インストールの方がいいんでしょうか?
lora学習の素材サイズって高画質過ぎても意味がないって見たんですけど、画質落としてでも512×512にリサイズした方がいいですか?
>>619 そうなんですね
学習解像度に合わせた方がいいっていう解釈してたんですが、要らないんですね…
>>606 masterpiece のせい。そういったプロンプトで限定すると、それしか出なくなる
下の方の設定した後にgenelateのボタン押すの面倒なんだけど
>>623 Ctrl+Enter
でいけなかったっけ
>>606 ダイナミックプロンプト入れて髪型や表情、顔の作りをランダムで選択するようにすればいいんじゃない
>>624 出来ました、普通にzipファイル上書きで良かったんですね
ありがとうございました
学習上手くいってくれないなあと思って何度もやってみてようやく反映されるものを作れるようになってきた
初歩的な質問かもしれいですが教えてください。
アフターバナーを導入してリミット下げてるのですが、画像生成中温度が80度に達してしまいます
onを押してoffにしても同じ結果でした
設定の仕方間違えてますか?
背景のlora使ったら、すげー厚化粧でクドい絵になった
>>631 自分のとUI違うので違うかもしれないが設定の適用は(スクリーンショット内にない)ディスクのマークじゃないか?
その ON ボタンは電力と温度を同時にスライドさせるボタンだと思う
>>633 ありがとうございます
適用ボタン押したら瞬時に温度が下がりました
>>632 あれインペイントで被写体以外マスクして描くんでねえのか?
妖精に頭悩ませてる
アップスケールは今ローカル版出てるぞ
>>638 SD以外でプロンプト生かして(生かせなくてもいいけど)アップスケールできるローカルウェアなんてあるんか?
>>630 🎴から右クリック、edit prompt words
>>637 これとか?
868 名前:今、天王星のwiki見てきたら軌道傾斜角(i) が0.774°だった (ワッチョイ 6312-keRw)[sage] 投稿日:2023/05/18(木) 14:49:53.98 ID:woSwpoup0
ニキ達、tile diffusionの公式見てないんか? Denoising strength0.5 ってのはもう昔の話やぞ
小人出さんように恐る恐るdenoise調整する時代はCNtileの登場で終わったんや
最新の推奨設定は
・Denoising strength1 (最大値ってことや)
・Method Mixture of Diffusers (デフォのmulti diffusionちゃうで)
・Noise Inversion Inversion steps200 (最大値や)
・Renoise strength0 (ゼロにしてええんや)
・CNtile使用 (タイル有効にしたら何もいじらん画像も貼らんでいい)
これや
>>637 妖精避けはDenoising Strengthを小さく(0.5以下 小さいほど出にくいので0.1から始めて妖精出たら一つ前の値にするとか)する
拡大でVRAM不足はTiled Diffusion + Tiled VAE を使う
理屈として分割して重なる部分を含めて拡大した後 合成する処理なので 処理時間は相当かかる
>>637 Tiled Diffusionのタイルサイズを大きくする
大きくするほど時間がかかるようになるので基本はデフォの96のままでいいけど妖精さん対策なら大きくするとかなり効果がある
普通は128x128で十分
手ごわい妖精出現率だと144x144にし、それでもダメなら160x160にする
これ以上はあまりにも時間が増えるので現実的ではない
上記はControl Netのtileとの組み合わせでも同様
Denoisingを0.75以上にして妖精さんや奇形が出たらタイルサイズを大きくして対応
他にも、Control NetのControl WeightとControl ModeとMulti ControlNetを組み合わせるやり方もあるけど、
思った以上に煩雑になるしまだまだ研究中なのでここでは書かないでおく
>>606 prompt増やせば増やほど条件が限定されるわけだから顔のバラエティーも減る。
CloneCleanerという拡張で適当に顔や髪のバリエーションを生成してくれるけれどpromptの限定が多いと効果薄目。
clonecleanerでやっていることは
aoi of japan
とか名前を入れているので顔の細部を上書きするADteailerのプロンプトにaoiと入れると日本人っぽい顔になる。
ADteailerのpromptにangryとか表情の指示すると強力に効くように名前の影響も効き目つよまる。
自分はclonecleanerで64枚ぐらいバリエーションを生成させて、その生成結果のPNG infoでどんな指示が追加されているか見て名前を抽出し、
顔のバリエーション生成したい時に使っている
>>632 ものによるかもしれないがloraは数字を0.1とかに下げると効き目も下がるでしょ
クドい実写背景系のLORAは層別適用で顔層と塗り層を切ると良い感じになる
おお、たくさん返信が
stylesというところで、プロンプトをセーブしておくことができますが、それに加えてcheckpoint、VAE、LoRAなど全部保存する機能はないでしょうか?
SD内部の動作についての質問なんですけど、openposeで人の姿勢を変えたりするのは追加学習やLoRAの制作のように学習時と同じ機構を使ってますか?
Windows 10 で
>>1 の導入方法1でpython入れてローカル環境作ってたのですが、グラボメモリ不足でパソコンを買い替えました。
新しくWindows 11 pro 64bit版にローカル作りたいのですが
今は
>>1 導入方法2
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre zipを解凍→update.batを実行→run.batを実行、でインストールされる。学習モデルはSD1.5が自動でダウンロードされる
でpython導入しなくても「update.batを実行」するだけでローカル作れるんですか!?
〇〇したら結果は××だったという具体的な報告してくれんと
>>637 妖精の元になるものをアップスケール前の画像で消してやり直すだけ
>>650 無い
保存したい設定で1枚 Generate しておいてその絵を PNGInfo に入れてそこから Send to ~ で送るくらいか…
>>652 めっちやはっきり書いてない?
The webui.zip is a binary distribution for people who can't install python and git.
Everything is included - just double click run.bat to launch.
No requirements apart from Windows 10. NVIDIA only.
After running once, should be possible to copy the installation to another computer and launch there offline.
専ブラ全滅で見るのも書きこむのもとても厄介になってしまったな
今まで問題なく動作してたんですが急に重くなって生成結果が破綻するようになりました
専ブラ全滅って dat 直読みが出来なくなったとかか
Gigazineの記事読んでようやく把握した なんだかご愁傷様
>>656 ありがとう
無いですか・・・
需要ないのかな? いちいち、config presetsとStylesとcheckpointとVAEをいれなきゃいけないなんて不便じゃないのかな
これだけ色々プラグインが出てるんだから、png内に全部記憶してくれるのを誰か作ってくれないものか
>>663 config presetsという拡張機能がそれに近いかも。
>>663 PNG内に3つを全部入れるのは無理でも、checkpointとLoRAはPNG内のメタデータに入っている
VAEはファイル名の定義で[vae_filename]と書くと入れることができる(v1.4.0)
もうVAEは840000しか使わなくなっちゃってるなー
SD飽きてきたと思って何気になんJスレ見てきたら、お前ら狂ったように上手いなw
sexローラ使てって、女の子はそれらしいポーズを取るんだが、いかんせん男の方が出てこない!
>>668 たまに出てくるならある程度ガチャして回数こなしてるわ
4090でガンガンいっとけ
>>668 基本男は思い通りに出ないものと考えた方がいい
>>672 みたいな書き込みテストしている馬鹿がうぜぇ
いろいろな所で現れてるよな
>>674 今までテストなど他スレではブラウザで書き込めても
書き込みたいスレではJaneを使わないと書き込めないとかだったからなぁー
Janeを使わせようと誘導されてた気がする
専ブラユーザーのおま環の都合を押し付けられても知らねーよとしか
おまかんではなく、マーケティングの賜物でしょ
>>659 少なくともモデルの入れすぎでおかしくなることはない
モデルは選択されるとメインメモリに読み込まれてるんだよね?
>>662 Tiled diffusionでとても大きい画像を生成すると、画面内に小さい人間がたくさん出てくる現象のこと
>>677 ツイッターやインスタもやってることだね。
コーパス作成に利活用さるるからとツイッターが閲覧制限してもおる
それがstable diffusion、このスレで延々と取り扱う必要があるのか
>>658 iOSならツインクル最新にアップデートして
左下の⚙歯車から外部板追加で
https://mevius.5ch.net/cg/ これ入れれば専ブラで見れるよ
リアル系で洋物ロリにオススメのモデル教えて
lowvramやmedvramの設定を頻繁に変えてるんですけど。
起動中には無理だな
1111アップデートしたら花札マークを押したときに表示される画面が小さくなって見づらくなった
>>688 やっぱり無理なんですね。
その方法でやってみます。ありでした
>>690 設定の追加のネットワークでサムネイルの大きさを変更できるが、そういうことではなく?
実写系でmov2movで顔固定できないで困っているのですが、顔固定のノウハウ持っている方いますか?
>>692 そんな設定もあるのですね
ただ、今回はそれではないようでした
サムネイル、リフレッシュ、RefreshCivitaiHelper'sの画面で三等分されている感じです。
本来この2つのリフレッシュボタンは、タブだった気がします。
ついでに、TextualInversionはサムネイルをクリックしても自動入力されないようになっていました
アヘ顔loraと他のlora一緒に使うとめちゃくちゃ絵が崩壊するんだけど相性とかあります?
モデル変えたりLoRAごとのウェイト変えてみてダメなら
>>694 SD webuiのアップデートでソート関係のUIが追加されてた筈だから
path表示抑制するのにスタイルシートとか使ってない?
使ってるなら一回user.cssを別フォルダに移動させて見たらどうだろうか?
改善すればスタイルシートの書き方の問題だろうし
LoRaウェイトで影響する層が被っていないか確認
胸部分だけ、上下にセパレートした衣服をプロンプトで記述しろと言われれば難しい
なぜか、そういう画像は自然に上下に衣類がわかれて胸が出てくる
>>692 いいこと聞いた
150×200にしてみた
画像生成が終わったら、ピコーンと音がなるようなプラグインてありますか?
>>703 webuiのフォルダにnotification.mp3って名前で音源置けば鳴る
横からそんな技があるのか!と気になったけど、今までどおりファンの音が静かになったら終わってると判断すりゃいいわと思い直したw
>>704 まじかありがとう
音を探してやってみます
ありがとう!できました
ちょこちょこと改良しながらやっているときに時間が無駄にならないからいいね
https://sounddictionary.info/interfaces-1/ 音はここから
PCを買おうと思っています。ドスパラを例にすると
txt2imgだと綺麗な絵が出力されるのですがimg2imgだと何故か一気に絵が崩れます
>>710 Denoising strength の数値
大きいほど破綻して小さいほど保守される
0だと何も変更しないのでそのまま拡大したりできる
>>711 0.6にしてもネガティヴプロンプトが効いてないような目が汚く解像度も悪いような絵になってしまいます
img2imgだけじゃ元画像のような綺麗な絵そっくりなのは出力できないのでしょうか?
>>712 0.35くらいじゃないと奇形になるよ
0.7とか1.0を使いたければControlNetのtileとTiled Diffusionを両方使うしか無い
>>713 やっぱりimg2imgだけじゃダメなんですね
img2imgにHires.fixは無いのでしょうか?
clip skipって-1にすればランダムで選ばれるとか出来ますか?
>>710 設定全画面のスクショのアップと
一気に絵が崩れる、のサンプルを3点ほど上げるとアドバイスを受けやすいと思う
(このスレ見ている人は質問者のPC画面を見ることができるエスパーではないため)
今ってloconは入れずにlycorisだけにしてlycorisフォルダを作ってlora全部入れれば良いの?
>>715 ノイズが残った絵になるだけに思う。選べないと思うが
>>718 x/y/z pilotでclip skipで、2, 3, 6みたいな感じでしてるんですけど、-1にすればランダムになったりしないのかな?
最近StableDiffusionを触りはじめたのですが、何回か画像生成していくうちに前の画像生成を引きずっているように感じています。
>>708 4070tiだけど512☓768のハイレゾ2倍の二枚同時生成で1分50秒ぐらい
ハイレゾやらないなら5秒ぐらいででる
俺は4090にしとけばよかったも猛烈に後悔してるので3000番はおすすめしない
直近の生成結果を引きずらないってのは学習プログラムそのものの否定になるような気もしなくはない
ありうるとしたらスクリプトの中の変数に1回遅れで更新されてるものがあるとか?
>>721 そんなものも RTX 4090を追加するだけ
>>721 ヤフオクで売って買い替えたら良い そこまでのコスト高にはならないから俺は買い替えたよ
3日かかる作業が2日になっただけで期待程は早くならなかったな
あと、フルパワーでやっていなければエンコードなど他の作業をしながらでも十分に使えるからPCの作業が全体的に楽になった
そういうのが大きいかも
PCを2台維持すのは面倒だからそういう意味では満足度高い
問題はPCケースの蓋がまだ閉まってないからこれをどうするかやわ
500Wのハロゲンヒーターみたいなものだし発熱が大きい
今はイオン付いてない空気清浄機の風をそのまま当ててるからめっちゃ冷えてる
ケースファンどうするかなぁ・・・
アイランド型のデスク(壁に向かっての机では無いという意味)が160cm幅なんだが、
音は複雑だから実際にやってみないとわからないと思う
>>728 レスありがとう
GPUがフルパワーになってケース無い温度も高くなったときに
吸気排気も高速になっていくだろうからそこ気になってた
離れた場所にサーキュレーターも空気清浄機もあるけど
50cm横のPCは近いだけに心配になったけど一回やってみて気になるようなら下部に設置してみるわ
>>720 前のプロンプトが残ってるように感じる時、自分はシードを「-1」以外にして何枚か生成してる
なんとなく効果がある気がする
>>729 横からだけど、座ってる真横にPC置いてる
i2iで数分~数十分とかの生成でファンが全力で回りだすと、その音は確実に聞こえるんだけど>728の言うように案外気にならないもんだね
そのまま特に音量を上げずにyoutubeとか見てるし
さすがに静かな音楽を聴く場合には邪魔になるだろうけど、そういう時は密閉型ヘッドホン使うとかカナルイヤホン使えばいいし
A6000の2枚刺しPC売ってるんだな
完全無音化するならUSBケーブルなど延長して別の部屋にPCを置く
生成時に複数人出したい時に「1boy,1girl」や2girlsを効かせようとすると、人物を学習させる時のキャプションに1boyや1girlは必要?
まあうるさかったらケース買いなおすのが一番早いよな
>>726 それも考えてる
ユーチューブにあがってる4090の爆速動画は羨ましすぎる
>>734 時間を無駄にするかもしれないけどやってみないと分からないかも
1boyや1girlに複数人の要素が入りそうで躊躇うけど
確かに4090がぶっちぎりで最強なのは疑いようのない事実なんだけど
>>727 埃はダイソーのエアコンフィルタ付ければケース内綺麗だよ
4090は生成時以外0rpmで無音なので、かなりの静音、ほぼ無音PCは良いね
デカいだけのことはある
24Gでもボトルネックとか言い出したら何も買えないぞw
そりゃまあ極論言えばそうなんだけどねー
>>738 最強と言っても期待しすぎると残念な感じになるぞ、コンシューマー用途じゃないけどもっと上あるし
ボトルネックになって困るなら、その時に買い替えればいいじゃん
高価なPCパーツって所有よりもレンタルに近いイメージなんだけどみんな一度買ったら手放さないのか?
サブスク流行ってるけど業者に払うよか、自分で買い取って不要になったらヤフオクやメルカリで売る方がお買い得だし自由度高いと思う
2060Superで作業してるんだけど4090にしたらどんくらい早くなるかな
>>700 exposed breastに加えて衣服系の指定もすれば結構出てくるよ
exposed pussyとタイツ系の指定でオマンコだけ開いたタイツ画像が出てくるのと同じ理屈だ
RTX 4090を安くて コストパフォーマンスが良くて
RTX6090はもっとスペック良くなるからRTX5090は罠だぞ
7090で量子メモリーになって世界が変わるからそれまで待つべきだな
RTX7090は更にスペック良くなるからRTX5090.RTX6090は罠だぞ
リアル系が入れ直したら出なくなったー
1000番台 2000番台だと12gb
そういう時はどういう風なのを出したいのかと
>>754 多分5000番台 6000番台だと48gb で
7000番台だと96 GB ぐらいになるだろう
それぐらい欲しいちゃ欲しいけど
いつの話やねん ってことで
>>759 日本の識字率は高いが読解力は結構低いらしいからな
金かけないから仕方がない
正解は全部買うだけど
4090を買えない人間が、おそらくもっと高くなる5090を買えるだろうか、いや買えない(反語)
5090はメモリとメモリバス増えて40万ぐらいだぞ、待ってて買えるのか?
ぶっちゃけグラボとしての機能はそこそこでいいからメモリだけ増やしてくれ
FX-6300にRTX3060-12GBぶっ込んでハローアスカやってみた
6000番台とか高さが4スロットくらいになってるんじゃないか
>>767 AVX系の命令が強化されてるRyzenの方が早いと思う
アップスケールはCPUで処理してるようだし
すみません。質問させてください。
昨日初めてStable Diffusionをインストールした超初心者ですが、この方と同じエラーが起きました。
https://twitter.com/bakerattaKBD/status/1677113489410887680 インストールは以下の初心者向けサイトの通りに進めていました。1111のローカルになると思います。
そして「Stable Diffusion WebUIの起動」の項目まで進み、webui-user.batをクリックすると上記のエラーが生じ、起動できない感じです。
https://itdtm.com/sd-inst/ 調べてみたところ、どうやらrequirements.txtとrequirements_version.txtに「torchmetrics==0.11.4」と記載して、
torchmetricsをダウングレードすれば正常に起動できるようです。
https://twitter.com/bakerattaKBD/status/1677116406444490752 https://twitter.com/aoshima256/status/1677146646088646656 ただ、このrequirements.txtというのがPC内を検索してもヒットせず、ググってもどこにあるのかよくわかりません。
こちら教えていただけないでしょうか。
https://twitter.com/5chan_nel (5ch newer account)
(補足)同じエラーと書きましたが、Paperspaceというのは利用していません。
>>773 ホントに正しくインストールできるのかどうか怪しいな
本来ならここにあるはず
>>773 初心者サイトの内容は間違っている
・PythonやGitは1111のインストーラが独自にインストールするためユーザーによるインストールは不要(入れてもいいけど使われない)
・最初の起動時、run.batの前にupdate.batを実行する
これでエラーは出なくなるはず
今のフォルダは削除してインストールし直すのをすすめます
>>773 袋小路に入っているような。
gltとパイソンおれて、パス通し、1111プルすればほぼ終わり、
パイソンら3.10.8あたりを指定する。
起動パッチ流すとpipがねえ、トーチガねえから、このコマンド叩けと言われるから従えばよい。
パイソンのバージョン指定はtorchの制限だから無視すると行き止りになる。
torchは機械学習ライブラリなので逃げることはほぼ不可能
>>777 >pipがねえ、トーチガねえ
吉幾三かな?
>>776 これマジで?
初心者向けサイトでも言ってること結構違ってたりして微妙に役に立たんのよな
CUDAツールキット?も書いてるところと書いてないところあるよね
>>777 うーむ、申し訳ないんだけれどそれは
>>773 には余計な情報ですよ
自分が知っていることを書くだけでは混乱させてしまうし、その書き方は不完全でなにも知らない人には再現できない
>>779 マジです
・
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre が出た直後ならいきなりrun.batでもいいが、バージョンアップがくり返された今はまずupdate.batが必要
・PythonやGitがいらないことはReleaseのページに書いてある
「The webui.zip is a binary distribution for people who can't install python and git.」
「このwebui.zipはPythonやGitをインストールできない人のためのディストリビューションです」
CUDAツールキットは以前は必要だったけど今はドライバが入っていれば不要だと思います
次にOSをクリーンインストールしたら確認するつもり
>>779 初心者向けサイトはゴミが多い
そのままコピペしろって書いてあるコマンドラインでハイフンが足りなくてエラーとか当たり前
自分で自分試してもない記事を公開してるカスがいる
環境導入するときにいろいろサイト見て回ったけど
ChatGPT先生も便利だからエラー出たら聞いてみるのもよい
>>781 今まで見たことなかったけど、このzipのやつって半年前のバージョン?
さすがに何をどうやってもpythonとgit入れられない人(ほとんどいないと思うが)以外は非推奨なんじゃね?
あ、update.batで最新バージョンになるってことか、なるほどな。。
初心者サイトって初心者向けじゃなくて、本人の備忘録なんだと思うね
コメント機能もなくて一方的に垂れ流し状態とかよくあるし困ったもんだね
結局個人のサイトじゃなくて集合知を頼ったわ
stable diffusionに限らずある程度頼れる情報探すときは site:ac.jp
大学の授業で使う教材なら、その講義が終わったらそれこそ1年ほったらかしかもよ
基本はなるべく新しいものを探す、複数の記事を読んで違いを見つけ、どれが正しそうか推測する、掲示板はポイントを絞って質問する、そんなところが大事なんじゃないの
>>773 はどのページを見たのかちゃんと書いていたから(偉い)回答も早かったね
個人のサイトだとアクセス数稼ぎでどこかの丸写しってことがよくある
本当に基礎知識が何もない状態だと記事に書いてある前提やら正しさを判断する基準、ポイントもわからないのが難しそうよね
gitとPythonのポータブル版を使うといいよって記事を見かけてその通りにやって2日間運用したけど世の中にポータブル版ベースで説明した情報が皆無だったから普通の手順で入れ直したわ
kohya_lora_param_guiでモジュールの種類にLyCORISはあるのにLoconがないのですが何か別途導入が必要なんでしょうか
うーん、chillout, bra6, bracing_evoでいろいろ試してるけど美人さんしかでてこねえ。
マスターピースとかベストクオリティとかのプロンプトが顔をきめるんだとか。
ステマくさくなるが、つべのテルルとロビンのセットアップ動画が初学者に最適だと思う。
>>799 GNu Learning tool。
まあ嘘。gitのスペルミス
そう思ってmasterpieceを外したり思い切ってネガティブに入れたりしたんだよねえ。
機械学習用に集めるのは問題無い
生成も個人の趣味の範囲で誰にも見せないなら問題ないぞ
マスターピースって黄金の額縁が時々出てこない?
倫理的っつーか気分的な問題?
そもそもプロンプトから出てくる画像だって
>>792 どうやったか書かないよりは多少ましくらいで偉くはない
どちらにせよ真否も分からんで真に受けるこういうのがフィッシングやサポート詐欺引っ掛かるんだろな
変な出所まねて動かないなんてのは一律テンプレ読んで出直してこいで良い
美人画以外ではマスターピースって役に立ちにくい感じがする
>>808 んまあ、おっしゃる通りなんだけどね。
そんなもんかと思いつつググってみたけど簡単には集まりそうにねえな。
聞いてくれてありがとね。
Tiled DiffusionとHires.fixの違いって解像度を作成時にあげるか後であげるかの違いくらい?
>>813 リアル系だとUltimate SDupscaleじゃないん
Amazon SageMaker Studio Labを使い始めたんだけど
<lora:loli:-1>
>>813 どっちがいいかでいえばどっちもいっしょで好みによる
タイル数値と被せ数値を決めてマルチ処理できるのがTiledDiffusion
Hiresが32GB+8GBでの限界値512+768×3倍の解像度なのに対して
2回処理すれば1/2~1/3の時間で4倍の解像度を楽勝で作れるのがTiledDiffusion
PC作ったのでAUTOMATIC1111で生成してますが、Stable Diffusion 1.5とか2.1がどう適応されてるのか理解できません
>>818 コマンドプロンプトで
python
import torch
torch.__version__
と順に打ち込む
PythonのバージョンとTorchとcudaのバージョンが表示されるはず
そもそも仮想環境できるんでWebUIを起動してブラウザの下部を見れば書いてあるはず
>>818 model依存、普通は1.5かと
2.1とか4090でもない普通のPCでできるんだっけ?
>>773 です。皆さん教えていただき有難うございました。色々と勉強になりました。
インストールし直し、update.bat→ run.batの順で実行することで起動できました。画像生成を楽しんでいこうと思います。
>>821 こっちで設定するんじゃなくて、checkpoint依存って事ですか?
>>819 一応レスしておくけど、1111はvenvで動くからvenv有効化しないと意味ないよ(メイン環境のtorchバージョンが見れてしまう)
まあ、他のレスにある通りブラウザに表示されるからそっち見ればいいんだけど
ADetailer使ったら逆に手とかボロボロ描写になるの俺だけ?…
複数の人が出てくるLoraを作りたい時は各人単独の画像だけでなく集合画像も学習させないと駄目なのかな
フェスティバルをプロンプトに入れて出る画像は集合写真から学習していると思われる
RTX 4090が24万円だとして 3年保証の玄人思考とかを
実際に撮影した人物写真をimg2imgに放り込んで、顔はそのままで表情だけを変えたい。
目的がフェイク画像づくりとしか思えんが…リアル人間の写真でそれは止めておけよ
>>823 例えばcivitaiでdownloadするところにbase modelがSD1.5だとかSD2.1 768だとか書いてある
>>821 automatic1111はSD2.1に対応してて3060でも普通に絵を出せる
が、SD2.1はエロが出ないし1.5で作ったLoRAとかも適用出来ない
Adetailerをオンにして512x512で生成すると、バッチサイズ1は問題なくてバッチサイズ2だと1枚目は普通に1girlが効くのに、2枚目が全くプロンプトが効いてない感じで風景とか壁画とか前衛的な絵画みたいなのが出てしまいます。バッチカウントを増やすと、1回目は問題なくても2〜3回目以降から発現する事が多いです。
>>802 そも一重まぶたの概念が海外データだから存在しないとかじゃないかね。
本とか嘘かはしらんけど、骨格的に西洋人に一重瞼はいないんだとか
>>833 2.1ってなんか使いにくいとおもったら、そういう制約があるんですね
>>836 いや知らんけどね。ただ西洋文化にない概念や紐づけは暗黙で無価値、存在否定、言葉狩りされる傾向があるのは研究結果として確認されている。
わかりやすいのは、AIはグロ画像を生成しない。
わざわざローラでベクトル向ける。
内臓がはみ出るとか、重度な火傷、剥き出た骨、座礁とかね。
それは学習していない、そういう画像はスポイルされるから。
この点でもgptは絵を描いている訳ではないとわかる。
覚えた画像をモーフィングしている。
自決しました
LoRA_Easy_Training_Scriptsのオプティマイザにprodigyがないのですがpip Install prodigyoptだけでは不十分なんでしょうか?
>>831 face swapという拡張機能があって、顔写真を放り込むと生成画像の顔とすげ替えてくれるやつはある
エロを検知するとやってくれないものもあるが、そうでないものもあるかもしれない
GeForce RTX 4060 Ti 16GBはほぼ販売されず。
RTX 4060の売上を見て投入規模を縮小へ。[2023年7月16日]
https://gazlog.com/entry/rtx4060ti-16gb-negative-prediction/ 待つだけ無駄であったか
>>842 cuda依存をやめれば変わるかもしれんけどね
>>826 単独の絵だけだと絡みを生成しづらい感じはある
だけど集合画像を学習させると要素がまじりそうな気もするので十分な単独画像を用意した上でやった方が良さそう
と妄想してる、結局やってみないと分からんw
学習関連がcuda一択なのがなぁ
そらニッチな商品だから買う側も訓練されてるわな
>>841 3060 vram12GB勢だけど
RTX 4060 Ti vram16GB 80,000〜90,000ならゲームしないならAI画像生成じゃ後継として良くないんですか?
なしてダメ?
ゲームしないから買おうと思ってるけど何かダメ?
4080vram16GBだと18万くらいするしAIなら良くないですか?
>>849 >>843 なるほど騙されるとこだったありがとござます
メモリ帯域幅ってAIに関係あるんです?
>>850 あなたはVRAM容量にこだわりがあるんじゃないの?
>>831 1.ControlNetのLineartで線画を作ってダウンロード
2.1の線画をペイントソフトで目と口の線を消す
3.2の線画をControlNetのLineartに放り込む
4.元画像をControlNetのinpaintに放り込んで顔をマスク
5.ControlNetのReference_onlyにも元画像を放り込む
txt2imgのプロンプトに出したい表情を入れて生成
元画像
closed eyes
angry
>>831 少し前のマイニング用のカードってダメなのかな?VRAM24GBで5万ちょい
>>850 お腹空いているところにカレーが出てきて豪快に食べたいけど
カレースプーンじゃなくて、ティースプーンで食べなさいと言われたら時間かかるよね
>>852 それだと、オリジナルの目や口がモデルデータの目や口になってしまうのでは?
>>850 メモリ帯域幅が関係があるのはもちろんだけど、別の考え方で言えば4060はキャッシュを増やしてメモリ帯域をケチっている
ゲームだとそれでも性能落ちないゲーム「も」あるけど、キャッシュ関係ないAI生成はデメリットがもろにひびく
3090で5万だとしたらさすがにジャンクレベルだろうけど、マイニング上がり承知でサブ機用に9万くらいで買うのは実際あり得る気もする
>>860 違うんだよ
RTX 4090 変えないから
RTX 3060 っていうやつが多いんだよ
それをするんだったら24回払いででも
買った方がいいっていう話で
買えないって別に一括で買えるだけの金が手元に無いって意味じゃなく単純に出費が割に合わないってことだろ
>>862 20代 貯蓄の中央値
を Google で検索すると 20万円ぐらいしかないらしいんで
収入はあっても一括だと買えないんだよね
>>863 実売価格だと3060の12GBは4万、4090の24GBは24万
6倍の差があるが、できることに6倍の価値があるのかってこと
あと4090は性能相応の電力食いなのでケースや電源もハイエンド用のが必要でPC一式買ったら50万くらいいく
>>864 作成 電力効率は6倍以上あるし
ラムも2倍ある
>>845 組合せ画像は必要みたい
そうすると全組合わせ必要か?代表例だけで察してほしい……
最後に触ったの4ヶ月ぐらい前なんだけど、その間にどんくらいの技術革新があったか教えてください
Stable diffusion XL 0.9が出て来て、そのうち1.0も出すと言っていることと、
グラビアで思い出したけど集英社が出したAIグラビアは速攻潰されてしまったな
お掃除ロボにしてもローソクを倒したら火災リスクがあるとかで売り出せなかったらしいし
>>865 アスカベンチのスコアは4倍だっけ?
SDXLで何ができるの比較がないと
プログレスバーの埋まり方を見るだけの自己満足の世界だわ
>>840 ありがとうございます。roopを使って早速やってみたけど、残念ながらこれは誰?って顔になるなぁ…。
>>852 ありがとうございます。こちらの手法も早速やってみました。
目と口は別のパーツになっちゃいますね…。
遺影みたいに正面からしか写ってない実際に撮影した写真を、ちょっと横向かせたり、笑わせたりしたいんですけど、難しいですかね?
何でいつも5chに貼られている画像は寒流面が多いの?
webサービスまたはアプリて使う場合、モデルをプロンプトで指定出来るんですか?
>>874 初心者でも韓流は出しやすいから
デ チケットとか月中は日本人顔が多い
>>869 お気持ち自主規制が大好きだもんな
基本ドMなんだよ、縛られていないと不安で仕方がない
>>867 一番大きいのはコントロールネットじゃないかな。
分割アップすけーらーてハイレゾよりメモリ少なく拡大できたりする
画像スレで寒流面連呼してる荒らしやろ
>>831 同じ人間の写真を複数撮影して顔部分のみ学習。
i2iのAdetailerで学習したlora+表情プロンプトで置き換え
>>831 同じ人間の写真で顔部分のみ学習。
i2iのAdetailerで学習したlora+表情プロンプトで置き換え
algo=loha conv_dim=16 conv_alpha=1 でloha作ろうと思うのですが、
>>869 あれはモデル非公表だったのとグラビアが嫌で辞めた人を学習元にしたんじゃないかって疑惑があったのがね
>>883 ありがとうございます。やはり写真1枚では無理ですかぁ。了解しました。
つかプレイボーイだったからだろ
週プレは新技術とかそういうの好きだからな
CIVITAIのパーミッションの一番下のものがOKな場合、マージモデルを公開するときに元の制限を外すことは可能ですか?
>>889 それは元の制限をかけている人に聞くべき問題だろう
第三者が勝手な解釈をしてはいけない
パラメーター数を別にすると、これって512x512で生成してから解像度を上げている現状と同じじゃない?
世界を変えた画像生成AI、さらに進化「Stable Diffusion XL(SDXL)」いよいよ正式公開
https://ascii.jp/elem/000/004/145/4145553/ 特定シードのモデル別比較表を作成しているんですが、モデルの切替と作成を自動的に行う方法ないですか?
>>893 普通にコマンドラインでやるかWebUI経由ならRPA的な手法でやったら?
>>893 X/Y/Z plotでseedとCheckpoint nameを切り替え
>>893 X/Y/Z Plotの存在知らずに余計な事言ってしまった。すみません
>>897 いいのいいの、最初は誰だって知らないんだから
こないだもほかのスレでバリエーション機能(>896のページにある)を知らなかった人がたくさんいたよ
>>894 ありがとうございます。私もコマンドかRPAは検討しておりコマンド検索していました。
>>895 >>896 こんな機能があったとは・・・。
早速URLみて勉強します。本当にありがとうございました。
みんないい人や。
>>892 パラメーターの数を別にしたらGPT3もGPT4もたいして変わらなくね?ってなるよ
そのパラメーターをいかにそこらへんのPCで回せるようにするかという工夫
パラメーターの意味が、色や髪型、服飾とかの指定だったらとても嬉しい
誰かお助け。。
・再起動は実施済み。
何より、リコリスについて全く使えないなら分かるんだが、textでやると使えるってのが意味わからん。
>>903 トリガーワードを入れていないからでは。
生成終了のタイミングでYoutubeを再生してブルースクリーンになって以来生成出来なくなたお(-_-)…
>>912 本当に怖かったし直前に戻ってユーチューブ観るなって言いたいお(-_-)…
>>913 別のブラウザでも生成100%行ったのにエラーで終了するお(-_-)…
>>914 その先のコマンドを入力してみたけどエラー出たお(-_-)…
でももしかしたらcudaバージョンが12.2になってるのが原因なのかも(-_-)?…
11.8に下げてみるお(-_-)!
初心者です。
>>917 Ultra slenderとかで出ない?
sharp bodyとか
久々にパソコン組むのですが
>>917 このLoRAを<lora:chubby girl:-1.5>とかでマイナス適用
civitai.com/models/33314
>>917 このLoRAを<lora:chubby girl:-1.5>とかでマイナス適用
civitai.com/models/33314
>>919 CPUはほどほどでOK
マザーボードはPCIe 4.0×16、M.2スロットはPCIe Gen4でできれば2つ
SSDはNVMe Gen4で2TB
グラボは予算に応じてなるべくいいもの
電源はグラボに合わせて
とかそんな感じかねえ
4090使いですが24でも足りないと思ってます
>>919 全振りするならランニングコストや生成速度、メモリ、価格考えると、コスパが圧倒的に良いので頑張ってお金貯めて4090択一かと
私自身は良いGPUだから良いPCをと思っていたけど組み直すと50万はかかる、割り切って3年前に組んだPCのGPUを4090に交換しました
あとMVMeにSDのモデルデータを入れてる、モデルを時々変えるならここは速度に大きく関係してくる
自分の予算に合わせて好きに組んだらいいんちゃう?
確かにそれはあるなw
みなさまアドバイスいただきありがとうございます
>>927 コスパ優先なら 3060 12GB
性能優先なら 4070Ti 12GB
第三の選択肢としては 4060(無印) 12GB
4060Ti 16GB が本当に8.8万ならコスパがあまりにも悪すぎる
だったら 4070(無印) 12GB の方が安価だしGPUの素の能力も段違いで上なので一般的な生成ならコッチの方が絶対に速い
>>919 全振りなら4090一択
CPUは10コアあればショボくてOK
メインメモリは64GB以上
OS 専用SSD512GB
SD 専用SSD512GB
後は保存用にHDDでも良い
この条件で45万で組めるよ
ただし電源は高品質品
ケースはエアフロー重視
ケース FANは大量に使用
4090は高くて買えないって言ってるのに馬鹿なの?
余計なことを書かずに
>>930 半振りなら10万で中古の3090買えば良い(30万で組める)
半分以下の速度で爆熱だけど
(電力絞ってグラボ裏に追加FAN必須)
>>931 全振りですから
>>931 4090と他と他とのコスパがあまりにも大ききすぎるからなぁー
全振りと言われると、もうひと頑張りしてでも4090を推す人が多くなるのは仕方がないと思うぞ
性能差が大きすぎなんだよ
>>919 SDでやりたいこと全部やるなら
VRAM 24GB
PC RAM 64GB以上
これは必須かと
(Out of Memoryを極力避ける為)
あとは予算に応じて妥協してもOK
RTX 4090の24万円が高いって言うんだったら
排熱やマイニング上がりのリスクをすべて承知の上でAI生成に振るなら3090の中古が最も全振りに近い
4090売れるか?ただでさえ燃えるコネクタの中古なんか買わねえぞ
3080,3090はGDDR6Xが爆熱になるため熱対策をしっかりとな
>>910 907です。今後の参考に、同じような症状が出た方の為、一応記載。
結論から言うと、mov2movを解除したらimg2imgでリコリスが機能しました。
似たような話?が以下にあると思われ、TXT 2VIDIOとか動画作成系が云々とあったので
mov2movを除いたら直りました。
根本原因は何なのか、自環境だけの話なのかは一切不明。
https://github.com/s0md3v/sd-webui-roop/issues/160 皆にRTX 3090の中古をおすすめできない
サーマル云々の問題を自分で対処できるなら中古はアリなだけ
みなさま、重ね重ね本当にありがとうございます
XLが4GBで動いたって言ってる人がGithubのA1111のIssueにいた
NovelAIの質問もここでいいのか?
loraのトレーニング速度ってPC性能でいうと何に依存しますか?
RX7900XTXがWindows対応なら良かったのにね
LoRAとアップスケーラーについて教えてください
さすがにlinuxが万人向けじゃないはこのご時世に
実写系で、単純にもうちょっと小柄140~150cmぐらいにするプロンプトかLoRAとかありますか?
MacOSすら万人向けじゃないのにいわんやLinuxは
>>950 あなたのいう当たりハズレが画像の何に対して言っててどんなものなのかもわからないが
ノイズの混ざり具合が中途半端だから3.5だと崩れているといえる画像になり
逆に6.7でノイズを多くすれば変更が多いため当たりといえる画像になってるだけでは?
元の生成画像からどれくらい変更を加えるかと考えていいとYoutube先生がゆってた
初めまして。WEB UI版2か月ちょいの者です。
先程画像を作ってみたら真っ黒になってしまいました。
検索して
https://www.kageori.com/2022/10/stable-diffusion-web-ui.html https://bookyakuno.com/aiart-dark-image-problem/ https://wikiwiki.jp/sd_toshiaki/%E3%80%8Cwebui-user.bat%E3%80%8D%E3%82%92%E7%B7%A8%E9%9B%86%E3%81%99%E3%82%8B いずれも試しましたが、WEBU UI起動プロンプトが途中で止まってしまいます。。(下はset COMMANDLINE_ARGS=--opt-sub-quad-attention --lowvram --disable-nan-check --autolaunch --precision full --no-half-vae と書きました)
とりあえず下のですが、ここで止まっている状態です。
自PCスペックは以下の通りです。
CPU:Intel Core i5-13400
メモリ:16GB
HDD:8TB
graphic board:Ge Force RTX 3060Ti 8GB
ご指導よろしくお願いいたします。
頓珍漢な質問かもしれませんがお願いします。
>>955 ありがとうございます
やはりHire.Fixを上げると普通は違う顔になる率が高くなるんですよね?
3.5以下でも顔や体型に違和感ある画像になるのが多くてまだまだだなぁと思ってたのに、
6.7に上げたら何故か違和感のない画像が出るLoRAが出来てしまって
たまたまの偶然だと思い気にしないで進めてみます
少しづつでも狙いの顔や体型が出る率が上がると楽しいですね
>>956 画像のエラーメッセージの通りだな
エラーメッセージで出てるファイルはどこに置いてるんだ?
置き場所が違うんじゃないか?
>>956 16x0系でなければ --precision full も --no-half-vae もいらなくないか?
一度 オプション全部カラにして黒画像が出るかためしてみたら?
あと、webui のバージョンと torch のバージョンはいくつ?
>>959 回答ありがとうございます。
「Error loading embedding yamakaze-896arb-e13.pt:〜〜」この部分でしょうか?
webui-user.batファイルを弄る前は問題なかったような気が…
確認してみようとしたのですが↓
>>960 WEBUIプロンプト最初に表示されているので合っていればVer1.2.0でした。
torchのVerは… 調べ方はここですか?
https://take-tech-engineer.com/pytorch-version/ なお、webui-user.batの中のset COMMANDLINE_ARGS= だけにしてみたら起動しなくなりました…
キャラlora学習のやり方について
>>962 そう それLoRaじゃないか? 置き場所違うんでは?
webui1.2は古くないか?
バージョン付きなら最新版は1.4.1
起動しない はどういう状態? コマンドプロンプトのエラー等貼らないと状態がわからない
起動時のログに 127.0.0.1 へのリンクがないか? それをブラウザに入れる
起動できていれはUIが開くはず
普通はエラー起きたらまず直前の自分の行動から疑って
アニメキャラを3D調で描きたい時はkotosmixがかなり相性いいな
>>957 自分でマージして公開していないモデルを使って生成したものかもしれないよ
>>957 順当に考えればAOMの部分はAbyssOrangeMixなんだろうけどそれ以外はなんだろ…
名称見た感じ自分用に色々混ぜた独自のマージモデルっぽい気が
個人が勝手につけた名前から憶測とか割合含めてまず無理だし
>>964 おはようございます、ご回答ありがとうございます。最新版出てたんですね!
夜帰ってから再度確認します。
イリュージョンみたいな顔だな…
そう考えるとSDはイリュージョン解散の遠因か?似たような事出来るもんな
スタジオ勢だったワイがSDに振れた途端ずっとこっちに夢中になってるのであながち外れではないと思う
現在Dドライブでsdしてるんですが、外付けHDDに移行しようかと思ってて、これって直接ドラッグandドロップでいいんですか?
>>977 基本的にはそのままD&DでOK、トラブったらvenvフォルダ削除して起動すれば環境構築しなおしてくれる
次
【StableDiffusion】画像生成AI質問スレ15
http://2chb.net/r/cg/1689744226/ >>978 ありがとう。1TBSSD思ったより安かったから買ってこれに入れるわ。
Oculusで目の前で色々なことができるってのは売りじゃないのか?
>>981 automatic1111の拡張機能使ってAI生成画像に深度情報推定して作成させて、
looking glassで裸眼立体視しているよ
MiDASによる深度情報推定はかなりいい感じで昔の1枚画像からのステレオ化みたいな半端な感じ無い
MMDの3d動画の画面見たいな画風にしたいんだけど、どんなプロンプトが良い?
AI美女系のハッシュタグでよく見かける動画で、カメラが被写体をなめ回すようにぐるぐる動くのがあるけど
>>982 あまり変態っぽいことは言いたくないのだけれど
Oculusが革命的なのは廉価にアニメキャラのロングススカートの中に入って、パンツとランジェリーとヒップを堪能できることだと思ってる
ショートスカートなら少し寝転ぶだけで堪能できる
こんなことは立体視では絶対にできない
あと、立体視だけど解像度が高く影もしっかりと描かれてる絵をタブレットPCに表示して視線を遠くにすると脳が勝手に立体物だと認識してくれてそれっぽく見えるな
Oculus使ってて思うのが、平面図だと寝てるときの夢にアニメのキャラは現れなかったけど、Oculus長く使ってるとリアル世界にアニメキャラがいるという勘違いしてるのか夢でも現れたことがある
想像力の乏しい一般人でも、3Dへの没入は脳の経験値としてカウントされる気がする
>>984 上級者はドールに紐づけしてるそうだよ
あと、触覚センサーはすでに販売されてるから実装待ちかと
>>989 カメラが動くアニメーションもこれで出せるんでしょうか?
いつも同じ動きなので、なにかそういう拡張があるんだろうと踏んでいます
XLって1111webUIで使えるの?
>>993 生成に必要なプログラムという意味では、今はdev版やRC版に来てる
masterが更新されたらgit pullすりゃ使える
生成に必要なモデルという意味では、自分で落としてきてmodelsに入れる必要がある
0.9のDemoを動かすExtensionならとっくにあるけどな
https://civitai.com/models/111475/ass-view-beta > IDK HOW TO USE THIS LORA PROPERLY. IF YOU FIND, DO COMMENT.
なんか笑った
このスレッドは1000を超えました。
5ちゃんねるの運営はプレミアム会員の皆さまに支えられています。
運営にご協力お願いいたします。
───────────────────
《プレミアム会員の主な特典》
★ 5ちゃんねる専用ブラウザからの広告除去
★ 5ちゃんねるの過去ログを取得
★ 書き込み規制の緩和
───────────────────
会員登録には個人情報は一切必要ありません。
月300円から匿名でご購入いただけます。
▼ プレミアム会員登録はこちら ▼
https://premium.5ch.net/ ▼ 浪人ログインはこちら ▼
https://login.5ch.net/login.php
このスレへの固定リンク: http://5chb.net/r/cg/1688234958/ ヒント: http ://xxxx.5chb .net/xxxx のようにb を入れるだけでここでスレ保存、閲覧できます。TOPへ TOPへ
全掲示板一覧 この掲示板へ 人気スレ |
Youtube 動画
>50
>100
>200
>300
>500
>1000枚
新着画像 ↓「【StableDiffusion】画像生成AI質問スレ14 YouTube動画>5本 ->画像>59枚 」 を見た人も見ています:・【アリスギア】 アリス・ギア・アイギス 質問・攻略・まったりスレ Part14 ポケモンGO 質問スレ Lv27 Panasonic DIGA質問スレ Part83 【Switch】Splatoon3/スプラトゥーン3 初心者スレ ランク8【質問/雑談】 【プラス板】ちょっと変な立て子を報告するスレ 質問・雑談ok ★4 [ぐれ★] 【まずやれ】筋トレ何でも質問スレ628reps 【明日方舟】アークナイツ 【質問スレ】 Part.12 [DIY]スレッドをたてるまでもない質問@DIY板★161 【DM】デュエルマスターズルール質問スレ25 古文漢文板の質問スレ4 Fate/Grand Order どんな質問にも全力で優しく答えるスレ Lv.139 Mozilla Thunderbird 質問スレッド 28 ■スレを立てる前にここで質問を 138■ ギルドウォーズ 質問スレ28 【Guild Wars】 星のドラゴンクエスト 質問&初心者スレ ★54 ねこ画像スレ 【鳥、トリ、とり】名前がわからない★24質問スレ】 面白いツクールソフト レビュー&攻略質問スレPart192 【質問】Ingress初心者支援スレ LV80【活動報告OK】 【少女前線】ドールズフロントライン 質問スレ Part6【ドルフロ】 【キンスレ】キングスレイド 質問スレ Part8 ギター初心者スレ 79●雑談相談質問● ワッチョイ有 売り子画像スレ 【規制議論板】質問でも雑談でもOKのスレッド★402 Webサイト制作初心者用質問スレ part250 ★★★筋トレなんでも質問スレッド478reps★★★ 【Dead by Daylight】PC版質問スレ【DbD】 part13 【Switch】Splatoon2/スプラトゥーン2 S帯スレ42【質問/雑談/愚痴】 【Switch】Splatoon2/スプラトゥーン2 初心者スレ31【質問/雑談】 セキュリティ初心者質問スレッド Part142 規制議論板】質問でも雑談でもOKのスレッド★602 【初心者】ダイエット質問・相談スレPart215【MINATO出禁】 jc・jk画像スレ2 3213万円貯金がある元無職の期間工だけど質問ある? 【ネット教会】キリスト教@質問箱337【偽メシアに御用心❗】 【質問相談】昨日の食事を判断【助言批判】 再試前の医学生だけど質問ある? マッチョほどではない筋肉質の美女の画像☆23 【悲報】小池「単独出演じゃないとインタビュー受けないわよ😡質問は事前通告じゃないと受けません!」 臨死体験経験したけど質問ある? 【質問】カップ焼きそばUFOについて お笑い好き中学生が芸人についての質問に答える 【TDL/TDS】TDR教えてちゃん集まれ!114 【質問】 コロナで休業してるけど質問ある? 【静岡自演ヒキ】わしがみんなの質問に答えたるで〜【ミステリー風】 小中高大全部言語が違う国行ってたけど質問ある? 【音楽】中森明菜の近況「体調回復優先も、ファンの方へのメッセージ考えたり撮影を行ったりしている」質問状に事務局回答 [湛然★] SJKだけど質問ある? 小学生だが質問ある? 【画像】3183 【画像】3575 【画像】2854 【画像】3284 【画像】4640 【画像】幽遊白書の「ゲームマスター戦」で2万問のクイズの問題と答えをすべて暗記していた海藤の凄さについて 【画像】2783 【画像】4759 【画像】2518 【画像】4780 画像基地DEATH 【画像】4029 画像 【画像】4607 女画像 【画像】3468 【画像】3072
17:07:37 up 38 days, 18:11, 0 users, load average: 41.50, 36.76, 32.06
in 0.04745888710022 sec
@0.04745888710022@0b7 on 022107