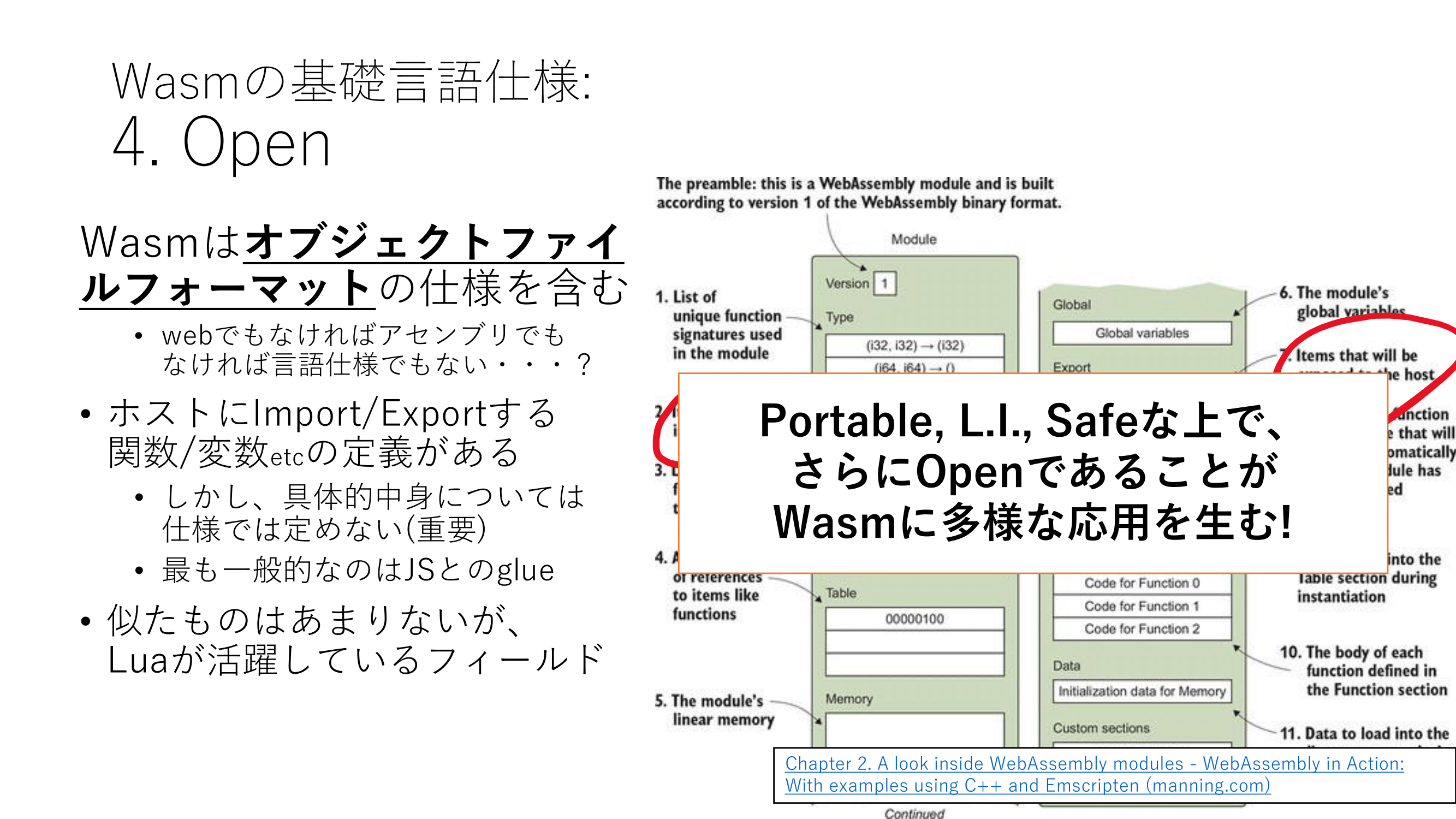
◎正当な理由による書き込みの削除について: 生島英之 とみられる方へ:Rust part15 YouTube動画>1本 ->画像>11枚
動画、画像抽出 ||
この掲示板へ
類似スレ
掲示板一覧 人気スレ 動画人気順
このスレへの固定リンク: http://5chb.net/r/tech/1652347700/ ヒント: http ://xxxx.5chb .net/xxxx のようにb を入れるだけでここでスレ保存、閲覧できます。
c++スレやHaskelスレでああでもないこうでもないと実用性無視してごちゃごちゃ言ってたのがRustスレに移って来て
>>8 正直言うと、俺たちは若い奴らが何やらワイワイさわいでCOBOLおじさんJAVAおじさん、C#おじさん扱いされないよう
カッコよさげだから、なんとなく雰囲気でRustを書いてるんだ。
でも、うまく言えないけど理解する必要性を全く感じない、下請けにおまえRustも分らんの?とマウントするのが夢なんだ
とやかく言われる筋合いは無い
再帰的なmacroはaliasしても展開時に
>>13 foo! の定義中の foo! 呼び出しを $crate::foo!() みたいにすればいけるんじゃないかな
前スレで出ていたこの上限チェックRangeFromだけど
複オジに毒されてるな
>>16 そのclone()は不要
トレイト境界からCloneを外せる
fn countup<T>(start: T) -> impl Iterator<Item=T>
where T: TryFrom<usize> + num::CheckedAdd,
{
let one = T::try_from(1).ok().unwrap();
itertools::unfold(Some(start), move |n| {
if let &mut Some(ref m) = n {
let mut next = m.checked_add(&one);
std::mem::swap(n, &mut next);
next
} else {
None
}
})
}
unfoldでなんでもできるからunfoldしか使わなくなってしまった人
>>18 take()?でもっと簡潔に書ける
fn countup<T>(start: T) -> impl Iterator<Item=T>
where T: TryFrom<usize> + num::CheckedAdd,
{
let one = T::try_from(1).ok().unwrap();
itertools::unfold(Some(start), move |n| {
let cur = n.take()?;
*n = cur.checked_add(&one);
Some(cur)
})
}
>>19 unfoldは要点に絞って見やすい短縮記法として使われている
そのままunfoldを使わずに普通に構造体にimpl Iteratorする形へ置き換え可能なところがメリット
例えば
>>20 はそのまま機械的に以下へ展開できて同じく動作する
struct Countup<T> {
one: T,
n: Option<T>,
}
fn countup<T>(start: T) -> impl Iterator<Item=T>
where T: TryFrom<usize> + num::CheckedAdd,
{
Countup {
one: T::try_from(1).ok().unwrap(),
n: Some(start),
}
}
impl<T> Iterator for Countup<T>
where T: num::CheckedAdd,
{
type Item = T;
fn next(&mut self) -> Option<T> {
let cur = self.n.take()?;
self.n = cur.checked_add(&self.one);
Some(cur)
}
}
これだと長く冗長なので敢えてunfold利用版を記述することで要点のみに絞ることができる
unfoldより関係が分かりにくくなるけど
大人が集まってくつろいでるところに
今回はこれでもいい
九九と違って子供用のおもちゃプログラムでしか使えないコードなんだよなぁ
代案出さずに文句だけつける万年野党みたいなやつがいるな
九九のように簡単だという皆さま方に質問です
>>30 「Rustのお題スレ」でも立ててそっちでやってくれ
>>31 難しくて解けないという表明ですか?
どういう点が難しかったのか教えてください
教えてもらったsuccessorsを披露したくてしょうがない幼児メンタルwww
>>24 の言う通りだな
>>33 successorsは適用範囲が非常に狭いので
>>30 の例には使えないはず
>>33 ぜひそれを披露してやり方を教えてください
フィボナッチ数列イテレータ前スレでだれかが書いてたでしょ
>>36 CopyやCloneを使っているから別問題だろう。
一般的にRustのプログラミングでは、
Copy(暗黙的な自動コピー)やClone(clone()による明示的な手動コピー)を使うと楽になるが、コストは高くなる。
そのため不要なclone()を見極めてそれを回避するプログラミングが出来るかどうか、というRustにおける根源的な話だろう。
>>38 もちろんCopyは最もコストが高い。
個々のコスト自体は通常clone()と同じだが、常に自動的にclone()が起きるため最もコストが高くなる。
複製おじさんはいつも自分勝手な妄想を「一般的には~」とか「皆は~」と言って自分を正当化しようとするよね
>>40 間違いは誰にでもあるからまだいいんだが
指摘されても反省するどころかさらなる妄想を撒き散らすのがほんと迷惑
おじさん使いの人の自演がいつもよくわからん
>>39 Cloneのコストが高い型にCopyを実装するな
Copyはコストが一番高いから出来る限り避けるべきだな
Copyは所有権を複製するから最も高コスト(キリッ!!
もはやどのレスもギャグにしか見えん
今までで一番意味不明なこと言ってるな
>>45 所有権に複製という概念はない
Copyをimplすると使われる時に値が自動的に複製される
そのためCopyは最も高コスト
>>46 君のレスがギャグにしか見えん
Rust のムーブはビットパターンのコピーだもんな。
>>47 それは理解不足すぎるぜ
大文字のCopyはCopyトレイトを意味しCopyトレイトを実装するか否かの話だろ
moveは別方向の話であり比較対象にすらならない
比較するならば「Copy実装(必然的にClone)も実装」「Cloneのみ実装」「どちらも実装なし」の3つだな
>>48 ギャグだと分からない人がいるとは想定していませんでした。
誤解を招いたのであれば申し訳ございません。
>>49 デタラメすぎ
ムーブでビットパターンのコピーは発生しない
ビットパターンのコピーが発生するのは引数の値渡し等であってムーブとは関係ない
さらに引数の値渡しでのでビットパターンのコピーとCopyのコピーも全く異なる
Copyのコピーはディープであって高コスト
そもそもフィボナッチ数列イテレータなんて誰も求めてないので
「ヒープ使うならCloneまでにしとけ」
>>54 Dropを実装する型はCopyを実装できないよ
BoxもRcもStringもVecもそもそもCopyを実装できないので、するかしないか考えること自体が無意味
どういう型にCopyを実装できるか、できないか、すべきかはdocsに書いてあるので
なんのかんの言う前にまずはこれを読もうね
https://doc.rust-lang.org/std/marker/trait.Copy.html >>53 これだけCopyやCloneを理解していない連中が多い状況だと
>>30 の質問に答えられるかどうかは最低限クリアすべきテストとして有用ではないか?
フィボナッチ自体はもちろんどうでもよい話だがCopyやCloneを避けるRustの基本ができるかどうかわかる点で
>>52 じゃあムーブでなにが起こるとおもってんの?
>>53 > フィボナッチ数列イテレータなんて誰も求めてない
それはそうなんだけど
唯一本人にとっては伝家の宝刀だから
少なくともこのスレいっぱいまでは引っ張って
何度も何度も参照するはず
関数の深いところから順に構造体をムーブで返していって
>>50 "Copyのコストが高い" は Copy を実装する行為そのもののコストが高いと解釈すべきということ?
そんなばかな
>>52 ドキュメント読みましょうねー
https://doc.rust-lang.org/stable/std/marker/trait.Copy.html > It’s important to note that in these two examples, the only difference is whether you are allowed to access x after the assignment.
> Under the hood, both a copy and a move can result in bits being copied in memory, although this is sometimes optimized away.
...
> The behavior of Copy is not overloadable; it is always a simple bit-wise copy.
...
> The implementation of Clone can provide any type-specific behavior necessary to duplicate values safely.
> For example, the implementation of Clone for String needs to copy the pointed-to string buffer in the heap.
>>61 アドレスが同じか否かでコピーの有無を判断する意味はよくわからんが
その理屈だとこのコードだと違うアドレスが表示されるからビットパターンのコピーがされてるって結論になるのか?
#[derive(Debug)]
struct S([i32; 100]);
fn main() {
let mut s1 = S([0; 100]);
println!("s1: {:p}", &s1);
let s2 = s1;
println!("s2: {:p}", &s2);
}
>>61 struct S {}
fn main() {
let s1 = S{};
println!("s1: {:p}", &s1);
let s2 = s1;
println!("s2: {:p}", &s2);
}
>>56 ちょっとw
なんで刺さったのか少しは考えてよww
ギャグゴロシめ
>>61 >>63 その二つの相異なる結果を見るとビットパターンのコピーはムーブ以外の要因で起きている??
>>61 高コストなCopyも実装してから確認してみてねww
>>66 ごめんよ
刺さったって「ためになった」みたいな意味で言ってるのかと思ったよ
てっきりオジの自演かと
>>67 デバッグビルドだけじゃなくリリースビルドでも確認してねw
このスレはいつもおかしい人間たちが集まってるな
おじさんイジリ飽きたので結論いっておく
>>75 頭悪すぎ
Copyが低コストなのではなく
低コストなものだけにCopyが実装されている
なぜならCopyは高コストであるため
>>76 ここでいうCopyのコストって具体的にどういう操作のコストのこと言ってる?
構造体データのbitwise-copyのこと?それとも別の何か?
Cloneやmoveの場合にそのコストは発生しないと主張しているの?
>>62 ほーCopyってCloneの実装によらずmemcpy相当の結果になるのか
自動的に.clone()が差し挟まれる感じかと思ってた
>>78 俺も同じくCopyは自動的にclone()されると思ってた
そう思ってた理由はClone実装せずにCopy実装するとエラーとなるため
そこで実験
#[derive(Debug,Copy)]
struct S { not_cloned: usize, cloned: usize }
impl Clone for S {
fn clone(&self) -> Self {
S { not_cloned: self.not_cloned / 3, cloned: self.cloned }
}
}
fn main() {
let s0 = S { not_cloned: 123, cloned: 456 };
let s1 = s0.clone();
let s2 = s0; // copy
println!("Cloned: {s1:?}");
println!("Copied: {s2:?}");
}
結果
Cloned: S { not_cloned: 41, cloned: 456 }
Copied: S { not_cloned: 123, cloned: 456 }
別物になった…
>>52 >
>>49 >デタラメすぎ
>ムーブでビットパターンのコピーは発生しない
>ビットパターンのコピーが発生するのは引数の値渡し等であってムーブとは関係ない
>さらに引数の値渡しでのでビットパターンのコピーとCopyのコピーも全く異なる
>Copyのコピーはディープであって高コスト
このレス最強だな
一つ一つの文すべてが間違ってる
「デタラメすぎ」てw
色々と正確な情報が出揃ったところで質問
場合による。
>>83 前提もまちがってるが
比較する対象がそもそも意味がない
もうちょっと勉強してから出直して
>>83 >A「copy/cloneはコストが生じるので、回避できるならば回避したほうが有利」
何と比べてコストが生じると言ってるの?
回避した場合は何で代用するつもりなの?
考えてみたけどmove/copyが問題になるレベルの大きさの型をスタックに置いて扱ったことが無いな…
>>86 回避する前と回避した後の比較だろう
回避したコードが書けたならばcopyの代用の必要はない
>>83 一般的にはAが正しい
ただし
>>84 が言うように無駄なコピーが消える場合もある
A「copy/cloneはコストが生じるので、回避できるならば回避したほうが有利になることがある」ならば正確
Bについては前半はある意味正しいとしても後半が間違い
>>85 批判や主張はその理由を伴わないと議論とならず意味がない
>>89 > 批判や主張はその理由を伴わないと議論とならず意味がない
基本的にはそうだが、こっちが説明しても理解できるレベルに達してない場合にはどうせ議論にならんのでな。
要は参照使えるなら使っとけって?
オナコードペタペタされてたほうがマシだったなこりゃ
>>92 それもあるが、例えば多数のコピーが行われているコードに対して、回避できる分を見直し、少数のコピーで済むように改善できる場合もある
Copy実装せずに明示clone()した方が見つけやすいかもしれない
>>88 さすがに意味が分からないよ
値の受け渡しにcopyを使わないなら何が他の方法を使う必要があるでしょ
一人だけ間違った思い込みをしてるのに
>>95 頭が硬すぎないか?
回避できる分を回避するだけだろ
回避できない分まで回避する、と思い込んてるのはYouのみ
>>89 「○○はコストが生じるので、回避できるならば回避したほうが有利になることがある」
言葉の定義を明確にしないジェネリック文は
恣意的に常に真にも常に偽にもできる
大きいフィールドを持つ型には、Copyは実装しないだろうし普通はCopy/Moveのコスト差を気にすることなくない?
>>94 データフローを見直して単純に消せるclone/copyは消せってことか?
それこそ今更すぎるわ
単純に消せないところまで消した後、さらにパフォーマンス改善するにはどうするかってことで、参照の話か?って聞いたんだけど
どこの誰とも知れないやつのフィボナッチのコードに対する指摘をされても知らねーよ
問題があって対策が分かってるなら自分で直すがいい
>>97 実行回数の話だったのかよww
まさかねw
>>101 フィボナッチの件はBigIntなど非Copyも対象で今回の話は全く無関係だろ
そこを区別できていないのは相当ヤバいぞ
流れからすると本当はジェネリックのフィボナッチにCopyを付けないほうが有利と主張したかったんじゃね?
>>85 根拠も示さず批判だけする一番アカン人間やな
>>104 フィボナッチはCopyを回避できないものなの?
分からないなら分からないから教えてって言えばいいのに意地を張るからこうなる
フィボナッチってこれだろ
>>87 async関数やasyncブロックで生成されるFutureは結構大きくなることがあって、boxingした方が性能出るケースもある
>>106 型制約からCopyを外すこことcopyを回避することは全く意味が違う
>>83 の質問は明らかに後者
プリミティブも対象になるフィボナッチでcopyを回避するのは無理
>>110 型制約からCopyを外せばプリミティブと言えどもcopyされなくなる
具体的には個々のプリミティブ型へモノモーフィゼーゼーションされる前の段階でCopy実装していない型に対してのcopy発生エラーが生じる
フィボナッチでcopyを回避するのは可能
複オジの主張まとめ(1)
複オジの主張まとめ(2)
50, 52, 57
=====
それは理解不足すぎるぜ
大文字のCopyはCopyトレイトを意味しCopyトレイトを実装するか否かの話だろ
moveは別方向の話であり比較対象にすらならない
比較するならば「Copy実装(必然的にClone)も実装」「Cloneのみ実装」「どちらも実装なし」の3つだな
デタラメすぎ
ムーブでビットパターンのコピーは発生しない
ビットパターンのコピーが発生するのは引数の値渡し等であってムーブとは関係ない
さらに引数の値渡しでのでビットパターンのコピーとCopyのコピーも全く異なる
Copyのコピーはディープであって高コスト
これだけCopyやCloneを理解していない連中が多い状況だと
>>30 の質問に答えられるかどうかは最低限クリアすべきテストとして有用ではないか?
フィボナッチ自体はもちろんどうでもよい話だがCopyやCloneを避けるRustの基本ができるかどうかわかる点で
複オジの一連の主張を読んでから
>>83 の複オジ質問を読むべし
主張が毎回変わる
>>98 この文脈では○○にはなんでも当てはまるから意味がないよね
以下なら議論になる?
A「copy/cloneはmoveよりコストが生じるので、copyが必要な部分とそうでない部分で構造体を分離してでも出来るだけmoveを使用する」
B「copy/cloneのコストはmoveよりコストが生じるとは限らないので、一部でもcopyが必要な部分がある構造体は丸ごとcopyして構わない」
>>116 そこまでいったらネット上では別人で良いだろ
>>108 やってみた
fn main() {
for n in 0..100 {
let f = f(n);
println!("f({n}) = {f}");
}
}
fn f(n: i32) -> i32 {
match n {
0 => 0,
1 => 1,
n => f(n - 1) + f(n - 2),
}
}
このあたりから非常に重くなった
f(43) = 433494437
f(44) = 701408733
f(45) = 1134903170
f(46) = 1836311903
f(47) = -1323752223
f(48) = 512559680
メモ化されてないんやから遅くなるのは当然
>>108 は定義を示しただけちゃう?
>>119 そのコードだとcopyは何回くらい発生してるのだろう
0回?1回?2回?3回?たくさん?
ぼくのかんがえたさいきょうのcountup<T>()をみんなバカにしたので
clone()が一個でコンパイル通ったからそのコードでのコピーは一回ではないか
>>119 計算量はO(n), メモリ使用量は定数オーダーにできるのになんで定義どおり実装したの?
>>123 ぼくのかんがえたさいきょうのfizzbuzz<T>()もわすれないで
>>124 そのclone()は子のf(n-1)とf(n-2)やそれらの子孫でも呼ばれるので1回ではなくO(n)より大きい
それをO(n)すなわちn回+定数回以下に抑えられるのかどうか
あるいはO(0)回すなわち定数回以下に抑えられるのかどうか
フィボナッチはu128を使ってもf(187)でオーバフローするからBigInt必須
>>120 メモ化したら速くなったけど
memoをこちらで用意して毎回渡していくのを避けられないのかな?
fn main() {
let mut memo: Vec<usize> = Vec::new();
for n in 0..100 {
let f = f(n, &mut memo);
println!("f({n}) = {f}");
}
}
fn f(n: usize, memo: &mut Vec<usize>) -> usize {
if let Some(result) = memo.get(n) {
*result
} else {
let result = match n {
0 => 0,
1 => 1,
n => f(n - 1, memo) + f(n - 2, memo),
};
memo.push(result);
result
}
}
メモ化する必要ある?
>>135 "rust fibonacci"でググるとよいです
>>134 直前の2つだけ記録して再帰にしない方法ならば
おそらくこうする案だと思うが
>>133 がO(n)で済んでいるのに対して
これは二重のforによりO(n^2)になっていてこれは悪手
fn main() {
for n in 0..100 {
let f = f(n);
println!("f({n}) = {f}");
}
}
fn f(n: usize) -> usize {
match n {
0 => 0,
1 => 1,
n => {
let mut prepre = 0;
let mut pre = 1;
for i in 2..n {
let tmp = pre;
pre += prepre;
prepre = tmp;
}
pre + prepre
},
}
}
>>135 fn main(){
for n in 0..10{
println!("f({}) = {}", n, f(n));
}
}
fn f(n:usize) -> usize{
let mut a = 0;
let mut b = 1;
for i in 0..n{
let tmp = b;
b = a + b;
a = tmp;
}
return a;
}
わざわざRustっぽい書き方をする必要はない
>>138 それもforが二重となっていて全体でO(n^2)だから同じく悪手
>>131 なら尚のことジェネリックにする意味ないよね?
>>137 ,139
悪手ってなにをもって悪手だよ
一般項の導出は高校生でもできるレベルで、そうすればO(log(n))で求められるし、つまらん計算量改善のためだけのアルゴリズム議論はもうやめろ
これ以上計算量の話をするなら別のスレでやってくれ
>>141 mainに既にforループがある
だから個々をO(n)で求めると全体でO(n^2)となる
もし個々をO(log(n))で求めたとしても全体でO(n✕log(n))となる
一方で
>>133 は優れていて全体でO(n)だから圧倒的に良手
まあ(usize) -> usizeのインターフェースを持たせつつ逐次処理したければメモ化が楽だわな
なんでmainのループまで計算量に入れてるの?
いい加減こんな語り尽くされた話終わってろ
>>143 メモ化は良いが
>>133 のコードはインターフェースがあまりよくない
逆に
>>138 のコードはn個の列挙にO(n^2)も費やしている
以下のように書けばn個の列挙がO(n)に収まり、個別f(n)もO(n)で両立できる
fn main() {
println!("f(77) = {}", f(77));
for (n, f) in fibonacci_iter().enumerate() {
println!("f({n}) = {f}");
}
}
fn f(n: usize) -> usize {
fibonacci_iter().nth(n).unwrap()
}
fn fibonacci_iter() -> impl Iterator<Item=usize> {
let mut p = 0;
let mut q = 1;
std::iter::from_fn(move || {
let r = p;
p = q;
q += r;
Some(r)
})
}
僕チンすごい!ってホルホルしたいんだろうけど
>>144 > 今やってるのはフィボナッチ数列の計算量の話でしょ
その通りでアンタが正しい
>>148 フィボナッチ『数列』の計算量だから
mainのループを勘定するのは当然
f(0)、f(1)、f(2)、…、f(n)がフィボナッチ『数列』
イテレーターにするとメリット多いんだな
>>146 はメモ捨ててるから計算済みのf(n)引っ張ってくるのに毎回O(n)かかるけどね
イテレータと相性良いように見えるとしたら0..nループと組み合わせることしかしてこなかったmainが見せる幻想
そろそろRustの話に戻ってもらっていいですか?
>>151 マジで
>>133 のメモ化が好ましいと思っているのか?
イテレータはメモ化とも相性が良い
例えば
>>146 のfibonacci_iter()を含むイテレータ汎用メモ化は即席でこんな感じ
fn main() {
let mut memo = IterMemo::new(fibonacci_iter());
assert_eq!(memo.nth(10), Some(55));
assert_eq!(memo.nth(0), Some(0));
assert_eq!(memo.nth(30), Some(832040));
assert_eq!(memo.nth(5), Some(5));
assert_eq!(memo.nth(50), Some(12586269025));
}
struct IterMemo<I> {
iter: I,
memo: Vec<usize>,
}
impl<I: Iterator<Item=usize>> IterMemo<I> {
fn new(iter: I) -> Self {
IterMemo { iter, memo: Vec::new() }
}
fn nth(&mut self, n: usize) -> Option<usize> {
for _i in self.memo.len()..=n {
if let Some(x) = self.iter.next() {
self.memo.push(x);
}
}
self.memo.get(n).cloned()
}
}
複オジは何が問題だと指摘されてるのか理解しないんだよなぁ
ほらなw
>>152 イテレータの規約に反したオレオレnth()はやめてくれ
IterMemoなんて名前の構造体にnth()が実装されてればイテレータのnth()と勘違いしてしまう
メモ化と個別機能が完全に分離できている
>>152 の方が良さげ
このスレだけでなくRust書く人間はコケ前提なのが馬鹿らしい
>>159 分離できてねーよw
アホだろ
イテレータ使ったことないのか?
Rust書く人間はレベルが低いと思われても平気なのか?
>>156 は普通にフィボナッチ数列を順に表示するだけでも常にVecを使ったメモ化を伴うので筋がよくない
>>152 はメモ化を付け外し可能で問題点も特に無いようだが
「Rustでドヤりたい素人が犯しがちな12の過ち」
>>165 複オジ特有の妄想を一般化するなよ
「複オジがドヤ顔で晒した恥ずかしい勘違い12選」にしとけ
需要ないけどな
こんな数列ごときでヒープ必須の
>>156 はプログラミングが下手
数列ごときのプログラムしか書けない複製おじさん……
cargo run --releaseで予測した動きをしないコードを書くなよ
このスレの底辺のコーダーもどき全員ゴミ
このスレを見る限りRustプログラマは低レベルの人間ばかり
オーバーフローのまともな対処すら知らない馬鹿ばかり
俺が小学生の頃はBASICで整数オーバーフロー考慮したプログラムは書いていた
天文計算なら多倍長じゃなくて浮動小数みたいに指数部と仮数部だけ保持しておくほうがいいだろう
>>177 >>146 のオーバーフロー対策をしてみた
これでいい?
fn fibonacci_iter() -> impl Iterator<Item=usize> {
let mut op: Option<usize> = Some(0);
let mut oq: Option<usize> = Some(1);
std::iter::from_fn(move || {
op.take().map(|p| {
op = oq.take().map(|q| {
oq = q.checked_add(p);
q
});
p
})
})
}
fn main() {
for (n, f) in fibonacci_iter().enumerate() {
println!("f({n}) = {f}");
}
}
必要ないOptionまで追加してtake.mapのネストは汚すぎる
>>179 勝手に戦えww
複製おじさん vs 100点おじさん
>>168 1レスで晒したこの4つの無知は外せないww
(1) ムーブでビットパターンのコピーは発生しない -> ムーブ無知
(2) ビットパターンのコピーが発生するのは引数の値渡し等であってムーブとは関係ない -> 値渡し無知
(3)さらに引数の値渡しでのでビットパターンのコピーとCopyのコピーも全く異なる -> Copy無知
(4)Copyのコピーはディープであって高コスト -> ディープコピー無知
>>182 フラグは必要
それをOptionで簡潔に表現した
批判したいならば代替コードを出すべき
フィボナッチ数列を他の計算の入力として使わないのなら何番目まで必要なのかをusizeとかで受け取ってBigUintのイテレータ返すので十分かな
うげ
俺が出したのは
>>185 の言う代替案じゃないから
勘違いしそうだから念のため
>>186 うん
今回はオーバーフローの対処をしろと言う
>>177 のリクエストに応じたのみ
>>182 mapのネストが苦手と言うならば
mapを使わないバージョンも用意したのでどうぞ
fn fibonacci_iter() -> impl Iterator<Item=usize> {
let mut op: Option<usize> = Some(0);
let mut oq: Option<usize> = Some(1);
std::iter::from_fn(move || {
let p = op.take()?;
op = (|| {
let q = oq.take()?;
oq = q.checked_add(p);
Some(q)
})();
Some(p)
})
}
firefoxってどのへんにrust使ってるんだっけ
>>191 汚いと言うならば同じ動作をするもっと美しいコードを出そう
「汚い」と言う人はいつもコードを出せない人だから負け惜しみで言っているのかと
>>185 unfold使ってた時と同じでフラグという捉え方がコードが汚くなる原因
命名を疎かにせず変数や関数の型を考えよう
そうすればOptionが必要なものと不要なものくらいは区別できるはず
ヒント終わり
コンパイルができた動けばいいだけのコードからは早めに卒業しようね
>>192 君のコードを汚いという人間は一人や二人ではないだろう?
それがなぜなのか?
なぜ汚いと言われるのか?
自分で考えて足掻いてこそ成長するんだよ
>>192 ちなみに汚いコードの反対は汚くないコード
美しいコードである必要はない
実践で重要なのは美しいコードよりも汚くないコードを書くこと
>>193 有無を表現することが必要だからOptionを使うのが最適
Optionを使わずに書けるのならばコードを出そう
>>194 今まで言われたことない
今回言われたから、いつも汚いを連呼しているがコードを出せないダメな人かなと
反論があるならばコードで示そう
>>195 その通りだよ
だから汚くなく、簡素でわかりやすく、無駄をせずに効率も良いコードを
>>189 に出した
同じ動作と同じ効率でもっと簡素に書けるのならばコードを出してごらん
>>184 その4つは全部並んでたからインパクト強いけど
個々で見るとムーブや値渡しの間違った理解は複オジ特有じゃないからちょっと弱いな
>>196 >今まで言われたことない
すごーいwww
お薬必要ですね
後出しでどんどん条件が変わっていくから話がまとまる訳がない
>>202 successorsバージョンはシンプルでいいね
RustとC++を学ぼうと思ってるプログラミング初心者です。
連投すみません...
>>210 どういう領域のプログラムを作りたいかでどっちが適してるか変わるからもうちょっと学ぶ背景とか教えて
なんのために学ぶのかにもよるけど、なんにせよC言語とJavaScriptはエンジニアなら全員勉強すべき
せっかくRustのスレに来たんだしRustをやりなよ
回答ありがとうございます…
>>217 Rustの入門書をぱらぱらと何冊か見たけど計算の優先順位の話とか普通のプログラム入門は全く書かれてないよね
C++の方は確実に書かれてる
入門はCやC++の方がいいと思うよ
個人的にRust以外にやったほうがいいと思う言語
Cをざっと学んでからRustかな
自分はOOPは学んだほうがいいと思う派なのでRustだけでは不十分だと感じる
Rustを学ぶならばほとんどの分野でC++とJavaは不要
単に習得するためなら Rust を学ぶために他の言語を先に知っておく必要はないが、
Rustだけを学ぼうとしてもその環境が整ってないんですよ
>>224 C++は不要
Cを習得しておけばRustのありがたみがわかる
>>225 演算子の優先順位の話はオライリー本には書いてあるよ
プログラミングを初めて学ぶ人間がRustから始めるべきじゃないというのは完全同意だけど
オライリー本もヒープとかスタックとか出てくるあたり、CやC++で動的メモリ確保の面倒くささを知ってる人向けだと思う
逆に考えよう
十分かどうかはさておき
>>233 それは同感で非常に重要
だから最初に
>>223 でCとJavaScriptを先に学ぶのをオススメと書いた
ありがたみなんて知る必要ないでしょ
>>221 C++ と java はやったけど C# 必要ですか?
Rustは、プログラミング経験者向けの情報が多い気がするから、PythonとかJavascript辺りをサラッと試してからでも良い気はする。
いつも同じパターン
プログラミング初心者は言語知識よりも
>>241 被害妄想はげしくね?
代案も代替コードもそれなりに出てるよね?
それに悪い物を悪い(汚い物を汚い)というためだけに毎回代案を用意する必要なんて全くないよ
意訳:
>>218 そのかかれてるC++入門本のタイトルあげてみろ
>>225 お前、
>>218 で *計算*の優先順位って書いてるじゃん。
>>225 でしれっと演算子の優先順位にしてんじゃねーよ。
お前ら新しい言語勉強する時に本読まないの?
>>246 Tauriではなくweb-view crateがシンプルで良いと思う
>>250 新たなプログラミング言語を学ぶために本を読んだことがないのでRustについてもわからん
わざわざ本を買って学習する人は少数派ではないか?
おれは基本は本を読む派だけど、読まない派のほうが多そう
昔は本買うか図書館行くかしかなかったもんね
最近はもっぱら言語公式のチュートリアル。Rustだと「the book」
>>252 必ずしも本でなくてもいいが……。 体系的にまとめられた入門用の文書は読むべきだと思う。
Rust に関して言えば
>>1-3 で挙げられているような文書があるからありがたく利用させてもらう。
基礎が身についてない段階で詰まるたびにググるみたいな学び方だと個々の情報の断片を
自分の理屈で勝手に (誤った形で) 結び付けてにっちもさっちもいかなくなってるのはよく見る。
複オジは本を読まないのが原因とは違うと思うぞ
>>251 実際使ってるの?
github HEADの最終更新11ヶ月前とかだけど
>>259 web-view crateは非常にシンプルで
最初のwebviewビルダーと
JavaScript側からのRustの呼び出しと
Rust側でJavaScriptの実行の三つだけをサポート
学習コストもほぼゼロ
だから更新するようなことがほとんど無い
それでも例えばHTMLのonclick等でRust側を呼び出せてRust側で処理してJSで反映ということが出来てうれしい
>>252 じゃあ
>>208 から始まる話題にはお前はおそらく不適切だからレスすんなよ。
>>261 唐突にポカーンだけど
そういった、人への批判は意味がなく荒れるだけで誰の役にも立たないので止めたほうがいいよ
たしかに
「そういった」がかかるのは「人」ではなく「批判」じゃないのかな
元のレスをもじっただけで
多くの人は良い人たちだが
そういうのは反応を見て楽しもうとしてるだけだろうから、無視するしかない
>>260 tauriも同じようなもんじゃないの?
今流行のアプリをweb-viewのテストで作ってみたがこんな感じなのか
MozilaはFirefoxを丸ごとRustに書き換える予定はあるん?
FirefoxはレンダリングエンジンをRustでゼロから作ってるんじゃないの?
>>270 特にそういう予定はないと思う
servo自体も別に次世代Firefoxを目指してるとかではなく、Rustでwebブラウザを書く実験プロジェクトという感じ
その実験でうまく行ったコンポーネントを徐々にFirefoxに移植していっている
暇を持て余した神々の遊び
>>270 C++で書かれてる部分は置き換えられるかも知れないけどJSで書かれてる部分までは置き換えしないんでないかな
JSの部分を置き換えるなんてはなから誰も思ってないってことだと思うが
意訳すると「JSで書かれてる部分まで置き換えるとか言ってるのは君だけだと思うよ」かな?
>>282 正解
>>283 アホ
JSで書かれてる部分まで置き換えるかどうかとか言ってるのは君だけだと思うよ
>>284 じゃ
>>280 で「言ってる」とか書くな
ボケ
>>285 はあ?
JSって言ってるよね?
バカなの?
>>279 JSで書かれてる部分までは置き換えしないんでないかな
>>270 が「Firefox を "丸ごと" 書き換える」と言っていたので全部はRustにならないよと伝えたんだけどなんかお気に召さなかった?
>>270 が言うのはservoのことでquantumの動機がcssパーサrustで書いたら
安全だったからC++で書かれたコンポーネント置換しよだからjs出る余地ないじゃん。
>>282 で終わった話。
そうだね、そんなふうに言われたらシェルスクリプトやMakefileまでrustで置き換えるんじゃないかって思っちゃうよね。
FirefoxはXULのイメージがあってJSも主要な構成要素だと思ってたから変なレスつけちゃったね
よく見たらID変えて暴れてるやつまだ居座ってるのか。
>>290 XULはだいぶ前に死んだよ。
XULRunnerが単体で利用困難な問題が解決できなくて存在意義を失った。
>>291 XUL完全になくなったの?
XBLは完全に消えたって聞いたけどXULは細々と生き残ってるものだと思っていた
>>189 おまえら全員そうだがフィボナッチ数列でusize固定はおかしいだろ
コード自体は問題ないが <T: Zero + One + CheckedAdd> を付けろ
あとは0と1をT::zero()とT::one()へ置き換えればi8型からBigUintまで何でも動作するようになる
https://play.rust-lang.org/?edition=2021&gist=929f3df48db39182558dfad6fe8d1cda さらに今回はfrom_fn()利用をそのままsuccessors()利用へ変換できるので見やすくなる
fn fibonacci_iter<T: Zero + One + CheckedAdd>() -> impl Iterator<Item = T> {
let mut oq = Some(T::one());
iter::successors(Some(T::zero()), move |p| {
let q = oq.take()?;
oq = q.checked_add(p);
Some(q)
})
}
ちなみにCloneを要求しないためBigIntなどでも無駄なコスト増とならない
>>202 そのコードは暗黙のコピーが発生している
from_fn()使用版のコードはcurrがキャプチャ変数なので「let n = curr?;」でコピー発生
successors()使用版のコードはクロージャ引数「|&curr: &usize|」の「&」でコピー発生
usizeならば問題はないがBigIntなどでそのコードは動かないので劣る
暗黙のコピー発生って気にするべき?
>>296 それは逆
そのキャプチャされた変数はクロージャが呼ばれるたびに何度も使われる
つまりムーブされてはいけない、つまりムーブ禁止となる
したがって n = curr? で currの中身は nへムーブされずコピーとなる
>>296 必ずCopy前提の型しか扱わないときは気にしなくていい
しかし今回は!Copyの数値型でも動かないと話にならないからコピーが起きるコードを避けないと
>>299 !Copyの場合はコンパイルエラーになるからわざわざ人間が注意を払う必要はないと思うが、気にすべき?
usizeしか使わなくてもTに置き換えた場合を想定してコードを書くべきということ?
>>300 u128を使ってもf(200)がオーバフローするような今回の案件でCopy型が前提のコードはよくない
案件次第だけど今回はコピーの有無を気にすべき案件
>>295 自分のレスに他人のふりしてレスするキチガイ汚コーダーこと複オジさんちぃーすっ
>>296 それはmoveの意味を間違えているぞ
>>202 のcurr?はコピーが発生する
FnOnceじゃないんだからcurrの値がmoveされたら次に使えなくなる
move禁止となりCopy型ならコピーが発生し!Copy型ならエラーとなるコード
>>301 copyを気にするのではなくusize or BigIntのどちらを使うべきか意識すべきと解釈した
usizeで良い場合はcopyは気にせずして良い
>>303 FnOnceかFnMutかFnかは関係なくて
moveなclosureでキャプチャしたらmove発生するよ
moveでキャプチャされた値をクロージャの中でさらにmoveできるか、refしかとれないかがFnOnceとFnの違い
>>304 それは別の話でその違いを理解できていないようにみえる
クロージャへのmoveはクロージャが作られた時に終っていてクロージャ内のコードでの動作なは関係ない
間違っているのは後者の話でこの部分
>>296 > curr?で発生するのはmove(とそれに伴うmemcpy)
curr?でmoveは起きない
curr?で起きるのはコピーである(!Copy型ならエラー)
>>296 コピーもmoveも同じでそれがボトルネックかどうかが重要
数値プリミティブの場合はコピーを他の方法に変えたところでボトルネックが解消されることはまずないから気にする必要はない
BigUint前提ならVecと同じでmoveやクローンやのオーバーヘッドはそれなりに気にした方がいい
逆に現実的にはオーバーフロー考慮する必要がなくなるからCheckedAddが余計なオーバーヘッドになる
特性の違う物をジェネリック等でまとめたほうがいい場面なのかそれぞれ別の実装を用意したほうがいい場面なのか判断できることが大事
>>307 それは間違ってるぜ
BigUintのchecked_add()は常にSomeを返すためにチェックとSomeは消えてオーバーヘッドとならない
さらにRustのジェネリックは各型にmonomorphizationされるためジェネリックで書いてもプリミティブ型やBigUint型のコードはそれぞれに最適化される
ヒント:
Ratio<T> where T: Integer + Clone + CheckedAdd + CheckedMulは
>>295 の条件を満たす
fibonacci_iter::<Ratio<u8>>()すると
ククク……RatioのCheckedAddの実装を見ても果たして同じことが言えるかな
>>311 たしかにRatioの実装が悪いな
まずAddと同様に
if self.denom == rhs.denom {の分岐をし
そして1の場合は
self.numberとrhs.numberでchecke_addするくらいはしないとな
ジェネリックに書いてもRatio専用コードを書いても
各型を個別に確認しないと良いか悪いか判断できないならジェネリックにしちゃだめでしょ
>>316 そんな個別に確認しなきゃいけないことは起きないから大丈夫
Rustの標準ライブラリも大半はジェネリックに書かれている
>>307 >特性の違う物をジェネリック等でまとめたほうがいい場面なのかそれぞれ別の実装を用意したほうがいい場面なのか判断できることが大事
禿同だわ
コードパズルやってるやつにいつも感じる違和感の原因はこれだな
こういう能力って何て言うんだろ?
>>318 でも今回の件の数列ならばジェネリックが正解やろな
わざわざ各数値型に個別に実装しなくて済む
分けるほうが不自然で手間
男の人って気持ち悪い…
>>318 広く言えば設計能力
狭く言えば実装パターンの選択能力
総合的な能力だから一朝一夕には身に付かない
実装パターンの整理が進んでないRustだと特に
>>202 のlet n = curr?;の部分を
>>189 はlet n = curr.take()?;としてコピーになるのを回避しているだけかと思ったら
両者が全く異なるアルゴリズムを採用していることに気付いた
>>202 のアルゴリズムだとどうやってもコピーを避けられないから詰んでるね
prev, currの状態管理だとcurrの値をprevに代入するのと戻り値として使うのと2箇所に必要になるからね
アルゴリズムというほど大げさな話ではないだろ
f(n)を求めるnext()が呼ばれた時に
>>189 は内部にf(n)とf(n+1)を持っていて、足し算してf(n+2)を作る
そして内部にf(n+1)とf(n+2)を残して、f(n)を返す
>>202 は内部にf(n-1)とf(n)を持っていて、足し算してf(n+1)を作る
そして内部にf(n)とf(n+1)を残して、f(n-1)は捨てて、f(n)をコピーして返す
つまりムダ
>>324 同意
フィボナッチ数のような単純な問題でもプログラミングセンスに差が出るものなんだな
>>218 まずはCから始めるのは間違ってない
Cは仕様が小さいからひと通り学ぶのにそんなに時間は掛からないからね
Webシステム中心ならRustとRails どっちを中心に勉強すればいい?
RustでETみたいなのって書けるん?
>>329 C++ で言うところのテンプレートは Rust には無いよ。 ジェネリクスは ML 風の型システムでやってる。
マクロは Lisp 風と言えると思うけどトークンが型付けされてるから Template Haskell とかのほうが近いかもしれない。
>>331 むしろC++のテンプレートよりもRustのの方がほとんどの利用方法で便利かつプログラミングしやすく快適になった
>>331 そうだよ。ダメだから君もRustは使わないほうがいい
行列クラスを作って
Matrix<Complex> X(2,2 );
>>335 もちろんできる
こういうのがほしいんでしょ
https://docs.rs/simple-matrix/latest/simple_matrix/ 初心者の題材としては適切そうだから、自分で実装してみてはいかがか
>>332 そこんとこ詳しく
解説サイトでもいいけど
とりあえず一度は the book を読め。
rustてこんなコードも許すんだな
fn main() {
println!("Hello, world!");
main();
}
https://play.rust-lang.org/ でやってみるとスタック溢れて死んだけど一応実行できるのねww
そんなことで草生やすのはおそらくキミひとり
>>341 いや、そんなふうに思ってるのはキミひとりだから
エントリポイントであるmainの停止条件のない再帰が
>>343 最適化したら、ループに変換されて死ななくなるとか?
Go でやってみたら gopls(Language Server)で infinite recursive call って warning が出た
>>347 RustもGoもどちらもwarningが出る
そして実行するとスタックが溢れて止まる
完全に同じ
イキッてスタックを増し続ける再帰を書くのは愚か、まともなら限界値でブレイクする、天才と努力家は末尾再帰でスタックを増やさない
リリースビルドだと最適化されてスタックオーバーフローにならない
あれ?
言語仕様的に最適化を保証してるわけではないというだけでは?
LLVMがある程度やってくれる
https://godbolt.org/z/os9YMfozf わかりやすい例
>>355 わかりやすい?
println入れるとなぜ最適化されなくなるの?
>>356 再帰だと&nは毎回異なる
つまり再帰をループ化する阻害要因
ごめん
>>358 ターミナルが標準出力に出てきたのを表示するのがボトルネックになってるだろうな
./a.out > /dev/null するか、printlnの代わりにファイル書き込みするのが手っ取り早い
traitでasync fnなメソッドを宣言してはいけない理由を教えてください
async fnはsyntax sugarだから例えば以下は同じ
現状の対策方法としてはimpl FutureをdynにしてBox::pinして返す
それを手動で変換するのは面倒かつコードも見にくいので自動変換してくれる#[async_trait]を使えばasync fnと書ける
・塩野義製薬が週休3日制導入へ 来年4月、副業も解禁
stableを期待しているということは現状の仕様で納得なんだろうけど
個人的にはIteratorがyield使って実装できるようになれば満足なのでGeneratorそのものの型とかはそんなに気にしてなかった
>>370 yieldを使うとIteratorの実装が楽になる?
from_fn()のようなfrom_generator()を用意するのかな
結局イテレータを作るには構造体か何かを用意してnext()実装するしかないぜ
複クンなんですぐここに貼り付けてしまうん?
>>375 <T>という型情報だけじゃT{b:1}が正しい式か分からないから
値の内容にまで踏み込みたければtrait boundを付けてtraitが許す範囲内でやるしかない
>>375 Tに渡されるのがいつもAだとは限らないからrustはエラーを出すんや
c++だったらエラーにならないが
そういうことなのか!ありがとう!
>>378 Tを引数に取らずにTを返すことも一般的に可能
その場合もTに何らかのトレイト境界を付けてそのトレイトのメソッドを呼ぶ形で実現する
fn c<T>() -> T {
T { b: 1 }
}
↓修整
fn c<T: Trait1>() -> T {
T::method1()
}
自分を返すmethod1()を持つトレイトTrait1を宣言しておく
trait Trait1 {
fn method1() -> Self;
}
そして型Aに対してそのトレイトを実装すれば動く
impl Trait1 for A {
fn method1() -> Self {
Self { b: 1 }
}
}
もちろんmethod1を引数付きのメソッドにしてもOK
>>377 C++すごいな
なんでエラーにならんのかわからん
そうだよ
どう見てもRustの方が安全安心
C++では
>>382 においてb以外のメンバ変数(フィールド)があっても動作してしまう
つまり初期化されていない部分が残り未定義動作となる
単一の機関が作ってるなら未定義動作なんて生じないんだけどなw
C++では未初期化部分がある時
>>382 なるほど
俺の知ってるジェネリックの常識とは違うがある種の合理性はあるな
未初期化領域があっても未初期化領域を読み出さなければ未定義動作にはならない
そもそも初期化されます
https://ja.cppreference.com/w/cpp/language/aggregate_initialization struct A { int x; int y; int z; };
A a{.y = 2, .x = 1}; // エラー、指示子の順序が宣言の順序と一致しません。
A b{.x = 1, .z = 2}; // OK、 b.y は 0 に初期化されます。
Rustのジェネリクスは
一方C++erはデフォルトコンストラクタを使ってデフォルト値を定義した
明示的に指示されないメンバも初期化されることに気づけなかったのはC++の仕様が複雑すぎるため
Rustは綺麗に整理されてるいるから複雑な個別ルールを覚えなくて済むね
トレイトを増やしすぎて普段は必要ない補完候補が気持ち悪いぐらい出てくる破綻言語
そんなに補完優秀だったっけ?
言ってることはHaskellと同じだと思います!
>>405 > ・静的に解決するのでCの10倍速い。
意味わからんw
>>405 haskellでそんなこと聞いたこと無いが。
>>369 Pinは1回だけでいい
そしてas_mutしてresumeする
let mut g = Pin::new(&mut generator);
assert_eq!(GeneratorState::Yielded(1), g.as_mut().resume(()));
assert_eq!(GeneratorState::Yielded(2), g.as_mut().resume(()));
assert_eq!(GeneratorState::Yielded(3), g.as_mut().resume(()));
assert_eq!(GeneratorState::Complete("end"), g.as_mut().resume(()));
CLI向けのコマンドラインオプションと設定ファイルと環境変数統一的に扱えるライブラリとかない?
大量じゃなければdotenv+clapで列挙していけばいいね
>>407 全部プリプロセッサで完了するCみたいなイメージじゃね
知らんけど
回答ありがとう
>>415 clapで環境変数読むの行けるのか、知らなかった
argfileはコマンドラインオプションをファイルに書くと読み込んでくれる感じなのかな
>>416 なるほど、環境変数自体を.envファイルに書いてもらってそれをコマンドラインオプションに読み替えるわけね
これは良さそうだ
env feature指定すると扱える
あと今時の形式
>>416 ではderive featureも必須
配列の中で移動コピーする方法を教えてください
コピーとあるからcopy_within(4.., 0)でいいんじゃないか
なるほど、任意の値で構わないってのはそういうことだったのか
ありがとうございました
>>426 slice::iter::position
positionでもfindでも行ける
str::findは部分列も対応
汚コードでもいいやん
汚コードなの?初心者だからマジわからん
>>430 sliceから部分sliceを探索する頻度が文字列から部分文字列を探索する頻度に比べて圧倒的に低いから、じゃないの
C++のSTLも文字列にしかメンバ関数としてのfindは無いし、これも同じ理由ではないかな
Rustのエラー表示すばらしいなほんとに
いつも汚コード言ってるやつはキチガイだから無視しとけ
>>430 部分スライスに対してもiterの代わりにwindowsを使えば同じようにpositionで部分文字列findと同じ結果を得られる
let buf = b"abc\r\ndef\r\n";
assert_eq!(Some(3), buf.windows(2).position(|b| b == b"\r\n"));
bikeshed bikeshed bikeshed
文字列のPatternに相当するものがsliceになないからでは
>>434 汚いかどうかの判断ができるようになるには言語に限らずその分野である程度の経験が必要
汚いなと思ってたコードが慣れるとそうでもなくなる逆の現象もある
>>434 公式exampleと同じなのでもちろん汚コードではない
もし何か問題がある場合は必ず誰かが代わりのコードを示すので大丈夫
汚コード連呼を相手にする必要なし
こんなスレに質問しに来る初学者なんてものは最初から存在しないんだろうな
ん?
複クンはね
なるほど言われてみればそうかも
流れ的に
>>208 なんかも怪しいな
気をつけよう
自演臭くなるからアレなんだけど
>>449 あれは何もかも自演に見えてくる病気な人による連投だから気にする必要なし
何でもかんでも自演だ!汚コードだ!と言うダメな人
書いてあるコードよりましなコードを出せずに汚コードって呟くしかない可哀想な人は暖かくスルーしてやってくださいな
>>448 汚いというならオマエのコードを出せとイキってたのに
実際にコードが出てきてダンマリ決め込んだタイミング・・・
ありえそう
変な初心者が来たなとは思ってたが・・・
汚コードを連呼してる人が初めて出したコードがこれ。
>>202 しかしアルゴリズムに問題があってフルボッコにされて撃沈。
汚コードを連呼の人が普段コードを示せない理由が判明してしまった事件。
うわーこれ確定じゃん
>フルボッコにされて撃沈。
真面目に書いとくとusizeみたいな数値プリミティブの場合はCopy前提で全く問題ないよ
>>456 一般的にはその通り
しかし今回はusizeだとすぐ溢れるからBigUintなどを見越してのコードの話
>>202 への批評内容はいずれもusizeでしか通用しないアルゴリズムをわざわざ採用したという点
一方で
>>202 が汚コードとみなした元のコードはusizeでもBigUintでもちゃんと動作するアルゴリズムになっていた
汚コード連呼厨は信頼できない
最初のコードでだいたいあってるんですよ
それを君がずっと引っ掻き回してるだけ
最初からあるんだからわざわざ出す必要もない
>>427 で終わってた話を
>>428 で誰も求めてないfindで書き直したり
毎週This Week in Rustのリンクでも貼ればこのくだらない流れは終わるのだろうか
ところでスライスへのfindメソッドなどの後付けはRustのorphan ruleを犯さずに可能なの?
> 誰も求めてないfindで書き直したり
複クンはなぜ汚いと言われるのか理解しないね
シンプルに意図が伝わりやすい書き方が他にあっても
findバージョンで答えようとしたところで
>>427 のレスがあったから「findでも行ける」に方向転換したんじゃね?
幼稚園児と同じでママン達に誉めて欲しかったのに
汚いと一蹴されて涙目
>>460 ブログへのリンクやアップデートはややマンネリ気味だけど
今週のcrateはいつもチェックしてる
>>467 そういう話をしたいのにRustと関係ない話や批判で荒らす連中がうざい
Rustの話ならば最新動向から初心者の質問まで何でも歓迎
しかし他人叩きしている連中は邪魔
可読性や汎用性を犠牲にしてもfindがpositionより優位に速いとか
ユースケース次第ではデメリットを補うだけのメリットがあるなら多少汚くても受け入れられる
フィボナッチの
>>202 と比較対象の
>>181 や
>>189 も同様
速度はベンチを取ってから
ユースケースは具体的に示してから
そういうことを主張してください
そして本当に互いのやり方にメリデメがあると認めているのなら、
>>295 のような他人叩きはやめましょうね
まーたふぃぼなっち言ってるw
>>470 その
>>295 は他人叩きではないだろう
そのアルゴリズムではBigIntで無駄なコピーが発生するというRustで気をつけるべき技術的な問題の指摘にみえる
そして回避コードもきちんと示しているのでそういう書き込みは歓迎
>>470 何のメリットもなく汚くしてるだけだから受け入れられないという話だったんだが
ジェネリックのフィボナッチや
https://play.rust-lang.org/?version=stable&mode=release&edition=2021&gist=41e1df59aeafe6f45fccaa192941d6d1 iter1とiter2は
>>295 からの引用
Ryzen 7 3700Xで計測
ジェネリクスへのこだわりを捨てればこのくらいは速くできるよ
fib_iter1 time: [7.2754 ms 7.2824 ms 7.2907 ms]
Found 2 outliers among 100 measurements (2.00%)
1 (1.00%) high mild
1 (1.00%) high severe
fib_iter2 time: [7.8536 ms 7.8678 ms 7.8818 ms]
fib_biguint time: [4.9757 ms 4.9784 ms 4.9812 ms]
Found 5 outliers among 100 measurements (5.00%)
5 (5.00%) high mild
Playgroundでもベンチマークできればいいのになあ
「RustとC++を学ぼうと思ってるプログラミング初心者です。」(架空)
どの場でも同じだが
>>475 それは流石に比べる対象が違うんじゃ?
ノンジェネリック版もイテレータを返すか
ジェネリック版をフィボナッチ数を直接返すようにして比べないと
>>475 playgroundみたいな環境でベンチマークやれたとしても結果が安定しないのでは
>>475 純粋にジェネリックか否かの比較をしたいならばadd_assignとaddの違いなども含めて条件を全て揃えたほうがよい
元がiter::successorsを使っているならば非ジェネリック版も同じくそれで揃えてみてはどうか
>>478 >>480 https://play.rust-lang.org/?version=stable&mode=release&edition=2021&gist=4f477ec7bc08ea9f61f565c00beb0d19 ジェネリックなほうをできる限り揃えたけどこれでいいかい?
CheckedAddでadd_assignする方法だけ無さそうだったからアレになってるけど
fib_generic time: [7.4054 ms 7.4164 ms 7.4275 ms]
Found 1 outliers among 100 measurements (1.00%)
1 (1.00%) high mild
fib_biguint time: [4.9527 ms 4.9591 ms 4.9655 ms]
>>477 > 後者を行なうダメ人間
そういうのは一定数いるからスルーしてくださいな...
>>483 そういう比較はそれ以外の部分のコードを揃えないと何が要因なのか判断できないよ
>>481 addがchecked_addになることで最適化が妨げられてるみたい
結局複オジが言ってたことは全部間違いだった
premature optimizationとpremature abstructionの典型例
複オジのおかげでいろんな教訓が再認識できて良かったね
>>487 なるほど
「早すぎる抽象化 × 早すぎる最適化 => 汚コード」ってことか
これは身に覚えがありまくる
>>486 正確に言えば
問題はCheckedAdd::checked_add()はselfもotherも参照で取るから、BigUintだと内部で1回clone()されてしまうということなのよね
一方でadd_assignは(桁があふれない限り)in-placeにやるから、その分のコストが発生しない
だから(compiler optimizationという意味での)最適化以前の問題だよ
http://2chb.net/r/tech/1509028624/153 ↑のコードも参考にどうぞ
C++で二項演算子をオーバーロードするときのイディオムです
これを思い出しながら書きました
>>490 ソース見るところ勘違いしてた
確かにaddでも&self使えばclone入るからchecked_add並みに遅くなった
checked_addにownedのselfを取るバージョンが追加されれば改善するだろうけど
trait定義からして対応するつもりのないユースケースかもね
>>491 CheckedAddAssignを導入すれば全て解決しそうだな
必要ならextension traitを書けばいい
リーナスさんから受けたパニックのありがたい指摘って結局どうなったん?
放置されてんじゃないの?
パニックにならないオプションくらい作ってもいい気もするけどね
パニック自体はもう1年前くらいに修正済み
リーナスレベルに行く前に誰も問題視してなくて指摘もされてないんだろうか
try_reserveはstabilizeされてるよ
>>498 リーナスが最終承認だけするイメージなんかな?
LKML読めば分かるけど、普通にパッチ投げるたびに突っ込んでくるよ
>>481 1.5倍も差があるのは妙だな
Rustでは最適化されるのでジェネリックで書こうがそんな差は出ないはず
そのベンチマークの仕方がおかしい可能性があるので
ジェネリックか否か、check_addか+か、Option利用か否か、など5つのコードで順に調べてみた
ベンチマーク使用コード
https://gist.github.com/rust-play/18d303c3ec79c19c4285ed190e5b2562 (1) ジェネリック + checked_add + Option + successors 版: 元の
>>295 と完全に同じコード
(2) BigUint + checked_add + Option + successors 版: (1)のTをBigUintへ
(3) BigUint + add + Option + successors 版: (2)のchecked_addを'+'へ
(4) BigUint + add + Option削除 + successors 版: (3)の変数Optionを削除
(5) BigUint + add + Option削除 + from_fn 版: (4)のsuccessorsをfrom_fnへ
結果
test bench_1 ... bench: 619,527 ns/iter (+/- 18,257)
test bench_2 ... bench: 620,293 ns/iter (+/- 23,787)
test bench_3 ... bench: 624,149 ns/iter (+/- 24,388)
test bench_4 ... bench: 626,810 ns/iter (+/- 20,343)
test bench_5 ... bench: 619,675 ns/iter (+/- 30,977)
結論
いずれも誤差の範囲でほぼ同一結果
Rustではジェネリックで書いても最適化される
BigUintでchecked_addやその結果のOptionを使っても最適化される
したがってi8からBigUintまで任意に動作する
>>295 のジェネリックコードで問題なし、となる
>>502 Rust凄いな
ジェネリックもOptionも何でも最適化してくれるとは改めてRustの素晴らしさを実感
>>502 そのやり方で差が出ないのはchecked_addと同じようにcloneが発生するタイプのaddが使われてるからだよ
ジェネリックにしても差が出ない場合もあれば差が出る場合もあるということ
>>502 やはり同じになったか
既に
>>478 が指摘しているように元のコードとイテレータ同士で比較ベンチを取ろうとしないから
>>475 を怪しいと思ってた
ちゃんと比較ベンチすれば最適化されて同じ速さになることを知っての狼藉だったりして
https://gist.github.com/rust-play/8caca28378745b36aaba5358d2a54fe8 test bench_1 ... bench: 426,714 ns/iter (+/- 5,563)
test bench_fast ... bench: 201,510 ns/iter (+/- 2,926)
Criterion の使い方が分からなかったのかな
>>504 どういうこと?
具体的に
>>502 の各コードよりも速いコードを書けるってこと?
そのコードを示せない限り
>>502 のベンチ結果を覆せない
>>506 君は全く別の問題にすり替えて誤魔化している
>>502 のようにイテレーター同士でベンチマークをとるべき
https://gist.github.com/rust-play/bde9b95f9bfe4de77fad841db30222c7 test bench_1 ... bench: 420,671 ns/iter (+/- 53,102)
test bench_fast ... bench: 219,091 ns/iter (+/- 1,147)
こんな汚ないことしてまでイテレータになんかしたくないんだけど
どうせ次の文句も大体予想付くし
この件はRustにとって重要なことだから口を挟むが、
Rustではジェネリックで書いてもmonomorphizationによって各型で書いた時と同じコードになる。
だから標準ライブラリの大半はジェネリックに書かれている。
そしてSomeなどのOptionは最適化できる時は綺麗に消えるため、
BigIntのchecked_addのように常にSomeを返す時も最適化でOptionは消えると考えられる。
いずれも抽象的に書けるのに動かすとC並に速いというRustの長所である。
つまり、
>>502 の結果が出たことはそれらが実証付けられたことになる。
しかし、以前からジェネリックは無駄とか遅いとかRustの長所に反する主張をする人がいるので気になっていた。
今回もRustのジェネリックは遅いと主張するために、
>>506 のように、完全に異なるもの同士を比較したり、
>>511 のように、Rcを返すという別仕様のものにしてまで、ジェネリックは遅いと主張し出した。
反Rustか反ジェネリックの立場なのかもしれないが、そういう捏造や詐欺のようなことはよくない。
>>512 ジェネリクスが無駄だの遅いだのはコード生成の話ではなくてコードのメンテナンスコスト含めた全体の話では
例えば今回ジェネリックなコードで無駄なcloneを避けるためには CheckedAddAssign といった trait を用意し、各整数型に実装するという余計な手間が発生する
また、各整数に追加のtraitを実装したとしても固定長の整数型ではすぐに桁あふれしてしまうから、実質BigUintの実装しか意味がないものになる
だったら最初からジェネリックにせずBigUintで実装するか、BigUintやBigIntといった桁あふれしない型だけを対象にすればよい
ジェネリクスの良さを語りたいならもっと良い例があるんじゃないの
>>511 そのコードはイテレータ内部で無理にunwrapしているためこれだけでpanicしてしまう
let mut iter = fibonacci_biguint_iter();
let first = iter.next();
let second = iter.next();
実行結果
thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', src/main.rs:23:30
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
これでは反証コードになっていないので
ちゃんとimpl Iterator<Item = BigUint>を返すコードを書いたほうがいい
>>514 その無駄なcloneとは何?
ベンチ
>>502 のジェネリックコードを含めた5つのコードを見てみたが無駄なcloneは見当たらなかった
それらよりもベンチで速いコードが出てこない現状をみると無駄は無いのではないか
あと、BigUintを使うまでもない需要も多いのだからジェネリックに書かれたコード一つで十分と感じる
>>503 それはLLVMのおかげじゃない?
他言語でできないRustならではの優位点てあったっけ?
>>518 C系だと構造体にtypeフィールド作って定数入れてその定数の値に応じて呼び出す関数変えるみたいなことやるんだけど
インタプリタの動的オブジェクトみたいなもの
Rustでもtypeフィールで条件分岐するのが普通?
抽象オブジェクトと検索して出てくる例みたいなのをRustでやるならこうだな
gccではなくg++とかだとフィボナッチ数列とかは演算しないように最適化される場合がある。
>>523 演算しないように最適化されるとか意味不明
演算はどこかで必ず発生する
コンパイル時点で演算してしまう定数化のことならばRustでも当然できる
const fn fibonacci(n: usize) -> usize {
const fn f(n: usize, a: usize, b: usize) -> usize {
match n {
0 => a,
1 => b,
_ => f(n - 1, b, a + b),
}
}
f(n, 0, 1)
}
const F77: usize = fibonacci(77);
>>511 俺環の遅いマシンだと6倍近く速くなった
この差なら用途によっては汚くする価値が十分あるね
まあ実際のプログラムでBigUintのサイズまで一つ一つイテレータで返すような使い方をすることはまずないだろうけど
>>511 コードが汚い上にget_mutが失敗してpanicする欠陥コードを恥ずかしげもなく披露できるもんだな
>>525 だからそう言ってる、そして機能紹介は知ってることを言わなくてよいよ?コンパイル時実行とは違う。gcc系は数学的に既に答えが出るようなアルゴリズムを書いた場合に演算しないで低い桁で答えを持つ場合がある。
意味が分からないんだったら日本語から勉強しなおせ。それと汚いものを張り付けるな
>>523 定数たたみ込みのことかな
試した限りでは gcc でも clang でも rustc でも最適化されて fib 呼び出しは消えているよ
どういうコードで問題おきるの?
gcc:
https://godbolt.org/z/nx3hnsxTT clang:
https://godbolt.org/z/MYc7G9jeG rustc:
https://godbolt.org/z/x18ob3MjP >>523 あとrustがllvmに執着しているというのも間違いで
gccのcodegenを使えるようにするプロジェクトもあって活発に開発されてるよ
https://github.com/rust-lang/rustc_codegen_gcc フィボナッチなんて普通に解析解あるんだからそれ使えばいいじゃん
>>532 フィボナッチは単なる題材に過ぎないことを理解できていないのはヤバいぞ
例えば
>>529 の定数畳み込みや
>>502 のジェネリックやOptionが最適化される話などが本題
単純だが単純過ぎない題材の例としてたまたまフィボナッチ数列が使われている
ワッチョイありスレに移住してここは複おじに明け渡してやったほうがいいのかもな
>>536 複おじの意味がいまだにわからないが
ジェネリックよりも速いコードがあるならきちんと示そうぜ
>>506 はイテレータと関数の異種比較のイカサマ
>>511 はイテレータ同士の比較へ改善されたがイテレータの中のunwrapでpanicするマガイモノ
そんなデタラメばかりしていたら信頼を失うぜ
https://play.rust-lang.org/?version=nightly&mode=release&edition=2021&gist=5180fadf9fda409e0456042fc1bccd8e 遅くなるの分かりきってたから出し渋ったつもりだったけど普通に速かったわwwwメンゴメンゴ
test bench_1 ... bench: 426,277 ns/iter (+/- 1,804)
test bench_fast ... bench: 350,928 ns/iter (+/- 2,760)
一応criterion版も貼っとく
>>502 で提起されたベンチマーク不適切説の真偽が気になるなら是非実行してみてくれ
https://gist.github.com/rust-play/3bd45555b9e6faef2b1426712e4e7601 >>539 はin-placeなchecked_addを実現するtraitがないことで速度差大きくなってるものだよね
ジェネリクスが遅いと言ったときに、
ジェネリクスの機構自体による速度差と、ジェネリクスにまつわるエコシステムによる速度差という二通りの解釈があると思うけど、
>>537 は前者のことを、
>>539 は後者のことを言っていて議論がかみ合っていないのではないか
ジェネリクスの機構だけの話をするなら前者の議論だけで良いけど、
メンテナンスコスト含めた実用性考えると後者の範囲も考える必要があるよね、
というのが
>>514 で言いたかったこと
>>539 君のベンチはいつも何と何の違いを比較しようとしているのかよくわからない
一方で
>>502 は何と何を比較するのかを明確にした上で各項目毎に段階を経て比較しているから
仮にベンチで違いがあればその要因が明確となり知見が得られる比較となっている
君の投稿からは結果に対して何が要因なのか知見が全く得られない
>>540 まず速度差がそのおっしゃっているchecked_addによるものなのかどうかを明確にしたほうが良いかと思う
>>502 を見てみると(2)→(3)がchecked_addの有無になっているがベンチは同じ
その結果からchecked_addは関係ないのではないか?
>>540 ジェネリックにやりたいならCheckedAddAssignを作ればいいんじゃん?
Rcのもジェネリックにもできるわけだし
>>540 そもそもコードが汚いという指摘が発端なので
前者が論点だと思ってる人はいないと思うよ
>>544 元と同一コードを含む5種類のベンチ
>>502 のコードを見たけど
特に汚いコードは見当たらないんじゃない?
もしあるならば具体的にどの部分なのかを言ったほうがいいと思うよ
>>541 「checked_addしてから代入」と「add_assign」の比較だよ
で現状後者はジェネリックにやるために適切なtraitが無いから、
ジェネリックな関数では性能向上に限界があるよねって話
>>540 の言う通り、ジェネリック関数とmonomorphized関数をの性能を比較したいわけじゃないよ
>>542 >>490 ,491でも出た通り、checked_addとadd(両辺とも参照の場合)はどっちもcloneが発生する
だから(2)を(3)にしても、遅いchecked_addを遅いaddで置き換えただけなので性能向上は無い
あとclone発生してるのはここね、docs.rsの[src]からたどれば&BigUint同士のaddがこのマクロで定義されているのが分かるはず
https://docs.rs/num-bigint/latest/src/num_bigint/macros.rs.html#91-107 あんまり頑固になっても聞かなさそうなんでそろそろ妥協案でも
>>546 あなたのコード
>>539 もclone()しているから
1回あたりclone()が1回発生している点で同じではないかね
そこは重要なところだから曖昧な推測で済ませずに細かい差異でベンチマークを取ったほうがいいのではないか
Rustが自由自在に書けるようなプログラマになりたがったンゴねえ
いや理解したんご
>>548 そのベンチが
>>539 のつもりなんだけど、これにどういう問題があって具体的には何をしろと?
from_fn使ってる分(5)のほうが近いから比較対象を(1)から(5)に変えろってこと?
というかそれが分かっているなら他人にやらせるんでなく自分で検証すればいいのでは?
>>551 結局、何が原因なん?
ジェネリック?それともchecked_add?あるいは変数Some?まさかのswap?
Rustスレとしてはコードよりも原因を知りたい
>>502 「1.5倍も差があるのは妙だな Rustでは最適化されるのでジェネリックで書こうがそんな差は出ないはず」
これがそもそもおかしい、最適化されようが何だろうが生成されるコードは違うのでMIRなりdisamなりでインストラクション単位で目視すれば一発だろ。ベンチを取る以前の思い込み低レベルな話
そしてほぼ最適化された無駄のないコードだったとしても
>>523 ここ5年程度のCPUでは64バイトのDSB境界を持つ小さなループ呼び出しなどが単一のμopsキャッシュに収まる場合があるがコードの配置によって異なり1.5倍程度の差が出ても不思議じゃない。
言ってるのに全く聞かない
>>553 その件は1.5倍差あった
>>481 がイテレータと関数を比較するという大チョンボをしていたことが原因と判明済
そしてジェネリックか否か自体では速度に差が出ないことを
>>502 のベンチが証明済
>>554 よく見ろ、それは
>>475 の話だ
>>481 は両方とも(usize) -> BigUintな関数
これだけ時間をかけても原因すら分からずノンジェネリックとの速度差を埋められない状況をコストとして認識できてないのが恐ろしい
一般的に、数列を順に求めるイテレータと、
そのうちの特定の数だけを求める関数とでは、
オーダー問題もアルゴリズムも変わってくるため、
>>481 はまた別の問題となっている。
イテレータ同士の比較で1.5倍となっていないことからも、
異なる問題であると理解できるはず。
>>556 ジェネリックとノンジェネリックに速度差が無いことは、
>>502 で既に示されたのだから、
ジェネリックかどうかは一切関係ないと思う。
ジェネリックとは別の問題。
>>557 >>502 はジェネリックでも実現できるコードをノンジェネリックにしただけ
ノンジェネリックならadd_assign, mem::swap, cloneで
>>502 のいずれよりも速いコードが書けるが
ジェネリックだとchecked_addを使わざるを得ず同じことが実現できない
>>537 では「ジェネリックよりも速いコードがあるならきちんと示そうぜ」と言っていて
>>540 の言う違いを理解している感じだったのに
いざ本当にコードが出てくるとジェネリクス自体のオーバーヘッドの話に限定して、差は無いと連呼
わざとやってんの?
>>558 > ジェネリックだとchecked_addを使わざるを得ず同じことが実現できない
それは違うのではないか?
ジェネリックでも自由にCheckedAddAssign等を定義して実現することが可能という話が既に出ている
>>492 >>543 一方でノンジェネリックで書いてもオーバフロー対策としてchecked_addは使わざるを得ない
つまりどちらが有利とか優れているとかいう問題ではない
>>560 他人の意見を鵜呑みにしてないでやってみれば?
俺はちょっと試してみたけど結局無理だと確信したよ
CheckedAddAssignの定義難しいよね
>>560 > 一方でノンジェネリックで書いてもオーバフロー対策としてchecked_addは使わざるを得ない
つまりどちらが有利とか優れているとかいう問題ではない
BigUintの場合はオーバーフローを想定しなくて良いからただのAddAssignで良いよね
ジェネリックな実装の場合は考慮すべき事項が増えるというハンデを抱えている
ジェネリックでなくても各i8版~u128版でchecked_add要るんじゃね?
>>560 CheckedAddAssignはAddAssignと同じようには実現できないよ
速度差は他の方法で工夫すれば埋めることは不可能ではない
このままでは誰も気付かなさそうなのでここでネタばらし
>>539 のcriterion版ですがこちらで動かすとこうなりました
fibonacci_iter_1 time: [7.3605 ms 7.3655 ms 7.3711 ms]
Found 9 outliers among 100 measurements (9.00%)
1 (1.00%) high mild
8 (8.00%) high severe
fibonacci_biguint_iter time: [7.5944 ms 7.5967 ms 7.5992 ms]
Found 2 outliers among 100 measurements (2.00%)
1 (1.00%) high mild
1 (1.00%) high severe
同程度に遅くなってしまいました
理由は
>>548 の通り、せっかく減らしたcloneをイテレータ化するために戻さざるを得なかったからです
一見非ジェネリックのほうが速い結果が出たのは、criterion版がN=50000としていたのに対して、
test crate版は最初に貼られたN=10000から変えずにやっていたためでした
criterion版をN=10000で、test crate版をN=50000で計測してみると大体同じような結果になりました
N<2^15あたりまでは非ジェネリックのほうがちょっとだけ速いみたいですが、まあ誤差の範疇かと思います
そういうわけで
>>539 で非ジェネリックのほうが速いと主張したのは嘘です
本気で信じちゃった人はごめんね
最初はcriterionとtest crateの差だと早とちりしたため、ベンチマーク不適切説とか勿体ぶった書き方をしてました
>>502 で根拠も無く疑いをかけたのに対するカウンターのつもりで黙ってたんですが、不発になっちゃいました
まあでもtest crateってwarm upもしないしサンプル数固定だし、その結果ひどい場合だと
>>511 なんか相対誤差10%超えてるし
criterion使ったほうがいいよってのは大筋では間違ってないよね
最後に+=でイテレートするこれだけ貼っとくから
某おじはこれに相当する性能のジェネリックなイテレータが書けるまでそういったクソどうでもいい執着に人を付き合わせるんじゃないぞ
https://play.rust-lang.org/?version=stable&mode=release&edition=2021&gist=76cd0aad53f19888900a4b450fd078c5 >>567 ジェネリックは遅くて使い物にならずRustはクソ言語のいい流れが出来ていたのに邪魔すんなボケ
>>567 それが本当にベンチマークしたかった内容なのかな?
Nの変化による性能差の変化が重要
Rcでイテレータ返すやつと合わせて確認すればN=50000だと差がなくなる理由も分かる
>>567 結局ジェネリックに書いても非ジェネリックでも速さはほぼ同じなのかよ
どんな方法で書いても結果を返すためにclone相当が最低1回は必要で
>>502 のジェネリック版はclone相当がchecked_addでの1回のみだからこれ以上は速くできないってことか
iterなんだけど
まちがえたこうだ
>>573 IteratorのItem生成のためにcloneが必要という話なので
参照返すとかRc<RefCell>にするとかすればまだ改善する余地はありそうではある
「Atom」の開発者が究極のコードエディターを目指す ~「Zed」の開発が始動
「Electron」を捨て、Rust言語を採用。GPUI、tree-sitterなどで武装し、超高速なコードエディターに
https://forest.watch.impress.co.jp/docs/serial/yajiuma/1374986.html >>575 Vec<i32>のiter()は&i32のイテレータ
filterした結果も&i32なのでVec<i32>でcollectしたければcopiedやclonedが必要
Vec<&i32>のままcollectするならclonedは不要
mapの例はx * 2でi32が新たに生成され
map以降は&i32ではなくi32のイテレータになるので
cloned無しでVec<i32>にcollectできる
>>577 Rc版はmake_mutにすれば呼び出し側が参照をつかんでる時だけcloneにフォールバックしてくれる
つかんでなければcloneしないので高速
全ての値をつかむようならRcを使わないやり方より少し遅くなる
>>355 はRustだと末尾呼び出しの最適化が効くの?
末尾呼び出し最適化必須のschemeですら自動的には最適化されず、人間が意味を解析して、アキュムレーター使って末尾再帰になるようにしましょうって練習問題になるくらいなのに。
Rust凄い!!
>>581 簡易的なstreaming iteratorにする方法もあるよ
>>582 どういう理解をしてるのかようわからんが、
>>355 はいわゆる末尾呼出しではないよ。
>>584 340くらいから末尾呼び出し最適化の話題があって、355の2で「リリースモードだとスタックが溢れない」と書いてあったので、末尾呼び出し最適化が効いたのかと思いました。
十分なスタック容量があっただけ?
1+count(n-1)
を
count(n-1, acc+1)
に書き換えてくれる最適化があるのかな、と思いまして
>>586 生成されたバイナリを見た方が良いよ
https://godbolt.org/z/Kcd6zf68e 定数たたみ込みでnopになってるっぽい
>>583 ストリーミングイテレータを試してみたけどRc使ったほうが少し速かった
ただ呼び出し側が参照をつかんだままにするとコンパイルエラーにしてくれるのでRcより望ましいケースが多々ありそう
streaming iterator! そういうのもあるのか
>>586 すでに
>>587 が指摘しているが、定数畳み込みが起こっている。 入力が定数で、かつそれに対する演算が副作用のない基本的なものであった場合に定数畳み込みがされやすい。 定数ではない場合でもこの関数 count は
mov rax, rdi
ret
になってて、入力をそのまま返す形にまで最適化されるので末尾呼出しがどうこうというレベルのものではなくなっている。
最適化というのは、レジスタ割り当てなどは理論的な背景がはっきりしているが、多くの細々としたものは「大量の置き換えパターンを辞書のように持っている」という物量で押し切る泥臭いものだったりするので (それをやりやすいようなデータ構造とかに工夫はあると思うが) 結局のところは投入されたリソースが多いやつが強い。
ちなみに Scheme の末尾呼出し最適化は言語仕様で要求する最低限度がそれだけ (しかし常にやらなければならない) という意味であって、それ以上の最適化をやっちゃ駄目という意味ではないよ。 最適化をどのレベルまでやるかは処理系次第。
汚文章は汚コードの兄弟
最適化の話はかなりコンパイラーに詳しくないとなぜそうなるかって分からないだろうからな
まぁ要するに
最適化と言えば&mutがnoaliasになって高速化したコード出会ったことある人居る?
>>596 要するに~
元の説明より長なっとるやないかーいww
脳みそ整理整頓してこんかーいww
またいつもと同じパターン
善人 = 情報や説明やコード等を書いてくれる人
悪人 = 文句や批判だけの人
>>597 Rustでは基本的に二つの & mut がaliasになることはないからnoaliasでいいけど
LLVMのバグが見つかったりやRustコンパイラの改修などで変遷を経てきてるみたいね
> Rust 1.0 ~ 1.7 noalias enabled
> Rust 1.8 ~ 1.27 noalias disabled
> Rust 1.28 ~ 1.29 noalias enabled
> Rust 1.30 ~ 1.54 noalias disabled
> Rust 1.54 ~ noalias enabled
>>602 「rust add assign optimize site:stackoverflow.com」でトップヒットだったわw
どおりでね
>>601 Rustの仕様は変わっていない
LLVMへの最適化指示のうちの一つをLLVMのバグ発見のため一時的にオフとしていただけ
そろそろRust製の有名なソフトウェア作ってからビックマウスしてくださいね、Firefox以外で
TechEmpower Round 18で1.5倍の差を付けて堂々の1位をかっさらったactixは有名ソフトウェアではない了解
WinとかLinuxの中身ですでに使われてなかった?
>>611 Linuxはまだ
winは確実なソースあったっけ?
OS系だとAndroidでは使われてる(まだデフォルトで有効ではないけど)
>>612 どうでもいい
>>613 同じくどうでもいい
Rustはver2.0にはなりませんって言ってるけど実質はとっくの昔にver2.0になってる
>>562 >>566 CheckedAddAssignにこだわる必要はないため、発想を転換して、
checked_add()の原関数であるoverflowing_add()を用いることで、
overflowing_add_assign()を用意して同じようにbool値を返せば解決する
具体的には以下のように引数はadd_assign()と同じでbool値を返せばよい
trait OverflowingAddAssign {
fn overflowing_add_assign(&mut self, rhs: &Self) -> bool;
}
オーバーフローするi8型〜u128型にはoverflowing_add()があるため実装はこうなる
let is_overflow;
(*self, is_overflow) = self.overflowing_add(*rhs);
is_overflow
この3行のコードでちゃんと最適化されるかどうかを確認するため、
単純にadd_assignを用いた場合、すなわち「*self += rhs」と比較すると
https://godbolt.org/z/WP3En8xM8 のアセンブリ出力となり、オーバーフローを返す以外は同一に最適化されることが確認できる
一方でオーバーフローしないBigUintなどの型への実装はこうなる
*self += rhs;
false
つまりオーバーフローの結果として常にfalseを返すので、
こちらは使う側でオーバーフローの扱いが消えてadd_assign部分のみに最適化される
したがってこのOverflowingAddAssignを用いてジェネリックに書けば、
どちらの型の場合であっても、非ジェネリックに書いた時と同一コードとなる
>>577 一般的に参照返すイテレータ類を実装する場合の注意点として、
1. let x0 = x_iter.next();
2. let x1 = x_iter.next();
3. ここで x0 の指す値を使う
順にこのような使い方をした時の挙動として、以下4パターンが考えられる
A. ✕ 実行時エラーとなる
B. ✕ x0の指す値が変化してしまう (次のx1の指す値と同一になってしまう)
C. ○ x0もx1もそれぞれ正しい値を指す
D. ○ コンパイル時エラーとなる
Rcとget_mut()を使った
>>511 のコードがNGのパターンA.で、これを避けるために、
Rc<RefCell>を使う提案のようだが、それもNGのパターンB.となってしまう
Rcとmake_mut()を使えばパターンC.となり、これがRc利用の場合の解となる
しかし参照を返すイテレータ自身がmake_mut()でclone()するのは役割として過剰である
切り分けとしてはイテレータを使う側が必要に応じてclone()するのが望ましい
そういうコードへ適切に誘導できる道が、コンパイル時エラーで示すパターンD.
具体的には、似非IteratorであるStreamingIteratorを用いるか、
Rust本命のGATsを用いたLendingIterator (=GATs適用後のIterator) を用いると、
clone()が必要な場面ではコンパイル時エラーにより知らせてくれる
もちろん普通にnext()ループ内の利用ならばclone()の必要なくコンパイルが通る
実際に >>618 のOverflowingAddAssignを用いてLendingIteratorで実装すると >>511 のコードでの「iter::once(p.clone()).chain(...」部分であり必須 NAVERまとめを彷彿とさせるレス乙
>>620 構造体メンバーであるis_overflowが常にfalseであることが分かるほどコンパイラ賢いんだっけ?
実際に生成されるコード確認した?
>>624 構造体メンバの値はグローバル変数なんかと同じで関数外で値が変更される可能性があるので
メンバが特定の値しか取らないことを暫定として最適化するためには、
crateの範囲を超えてプログラム全体で値が設定されうる箇所が他にないことを確認するか
メンバが可視な範囲で確認する必要があると思うけど、
前者をやるためにはリンク時最適化が必要だし
後者ならメンバの可視性をLLVMに渡さないといけないと思う
rustcとLLVMはそこまでやってるの?
rust結構面白いからマイクロソフトがVisualStudioでRustでWindowsFormを作れるようにしてくれればなあ
>>618 それが
>>566 の2行目で書いてる工夫のことだよ
boolではなくchecked_add使ってOption<()>返すメソッドにしておけば?演算子でシンプルに書ける
>>627 assignでない演算は生成のため内部でcloneが発生して無駄と既に結論が出ている
GATがstableになるの意外と近い予定なんだな
>>625 Rustでそれは起きない
書き換えるには所有権か&mutが必要でコンパイラは全て把握している
更に構造体のメンバーはpub指定がない限り他者はアクセス不能
つまり今回ならばnext()しかメンバー書き換えしないとコンパイラは確定できる
>>630 その最適化するのはLLVMだけどLLVMが最適化できるだけの情報を渡してるの?というのが聞きたいこと
>>623 その通りRustコンパイラが賢いことを確認したよ
is_overflowが常にfalseとなることを察知してNoneを返すことが無くなったみたい
Noneが来ない利用側のwhile let Some(n) = iter.next()は無限ループのコードとなっちゃった
さらにwhile loopより後ろのコードは永遠未達と判断されて完全に消えた
>>628 checked_add使うのはプリミティブだけだよ
BigUintはadd_assignで常にSome(())
>>620 GATってIteratorとか既存TraitのAssosiate Typeに直接ライフタイム書けない仕様になったの?
LendingIteratorみたいに別のTraitを使わないといけないようならイテレータ関連の仕組みが2重なって使い勝手が悪い
>>633 意味不明
Some(())/Noneにするならば
>>618 のbool値のコードで十分
>>634 もちろん出来るようになる
今は無理だからRust公式ブログで解説された例に倣って仮にLendingIteratorとの名で定義して使うなどする
>>632 おー、そんな賢いんだ。すごい
ちなみにfn mainとイテレータの定義は同じcrateに含まれている?
lib crateでイテレータを定義してbin crateから使った場合にどうなるかも気になる
>>626 こういうMicrosoftからのサポートは俺も期待してる
VC++よりもRust書きたい
乱数系のモジュールの仕様変更がかなりガッツリあったみたいなんだけど
>>640 人に読んでもらう文章は重要なところ省いたら読んでもらえないよ
>>640 標準ライブラリで破壊的変更はほとんどない
外部crateなら概ねsemverに従ってるし lockfile の仕組みもあるから、
以前ビルドできていたものがビルドできなくなることもほとんどない
>>638 サポートってどの程度のサポートを期待しているんだ?
MSがRustコンパイラー出せばWindowsのRust用フレームワーク出すんだろうがな
出さないなら、C/C++/C#のAPI/フレームワークをRustからとりあえず使えるようにしました
程度のサポートになるだろう。
期待しているのはRust用フレームワークであってRustからとりあえず使えるよじゃないだろ?
>>643 あれ外部ライブラリか
しかし乱数系の標準ライブラリってまだRustにないのか
やぱ若い言語だなRust
>>645 若いというか意図的に標準ライブラリから外してあるよ
理由は標準入りしてしまうと破壊的変更ができなくなって腐るから
だから将来的にも標準に入る予定はないと思う
>>646 意図的に外してるの?
ふーん、それはそれで面白い
>理由は標準入りしてしまうと破壊的変更ができなくなって腐るから
基本的にRustはシンプルに最小限の言語構成部分しか標準ライブラリに持たない方針
OptionやResultの便利メソッドはどんどん追加されてるし別に標準ライブラリを最小限のものにしようとはしてないでしょ
>>649 >最小限の言語構成部分しか標準ライブラリに持たない方針
俺もそんな方針だと思う
これが良いのかどうかは分んが。
標準ライブラリだとコンパイラ屋がコンパイラを出す限りサポート・メンテされるのが
他の言語では標準ライブラリなのが外部クレートだと、将来これをメンテする奴がいないになって
放置になり困ったになる可能性あるからな。
>>650 それは最小限の意味合いの受け取り方が違っているだけで同じ
Option/ResultはRustにとって言語構成部分
そしてそのメソッドは強いて言えば多彩な制御構文にも相当する
だからRustの最小限の標準ライブラリに含まれているし必要性が認識されればメソッドも増える
>>651 それは「サポートする人がいなくなればサポートされなくなる」という当たり前のことでRustとは別の一般的な話
どんな製品でも、どんなライブラリでも、どんな言語でも、同じ
そして基本構成部分を含むRust本体の改善&メンテと、それ以外のライブラリのそれとは明らかに別の話たから切り離されているのも自然
同じではあるがcargoの性質で余計に面倒な状態になってる。
>>654 低レイヤー向けのプログラミングをRustでしていて相性の悪さで困ったことはないが具体的に何だろう?
聞きかじりだけどクロスコンパイルとかやりたかったらxargo使うもんなんじゃないの
同梱されるライブラリが巨大な言語で
>>652 確かにOptionやResultそのものは言語機能にも関わってくる基本的な構成要素だけど、
OptionやResultの便利メソッドは外部crateでも定義できるよね
また、HashMapやBTreeMapなどは "言語" の構成要素ではないし、
最近ではonce_cellという外部crateで実現できていたものをstdに取り込もうとしている
"言語" を構成する最小限の要素に絞るのであれば、これらは外部crateで実現すればよくて標準ライブラリに入れなくても良いはずだよね
おそらく、標準ライブラリに取り込むものは厳選してコンパクトさを保つことを前提に、
広く使われていてAPIが安定しているものは取り込んでいくというスタンスなんだと思うよ
あー、rustで書かれたプログラム全体の中でのデファクトスタンダードとかお作法とかも含めて言語って言っているのかな
マンパワーが足りないから選択と集中で切り捨ててるだけ
>>661 アレをRustに取り入れようという動きはないのかな?
>>648 利便性ではなく一貫性で標準を決めているってことだろ
>>658 Rustの利点はOption, Resultがmatchなどの構文で評価できる事、演算子もあるが演算子オーバーロードができる言語であれば同様のことができてしまうがC++23とか26とかで提案されていたinspectはmatchそのもの
Rustの活用でElectronよりも軽くて速いアプリフレームワーク「Tauri」が安定版に
まずはデスクトップから。モバイル・Webへの対応も進行中
https://forest.watch.impress.co.jp/docs/news/1417148.html TauriとYewで純正Rustデスクトップアプリ開発か、
Tauri + Vite + Vue 3 + Vuetify 3でデスクトップアプリ開発オラァ!!!
>>665 PC Watchが報じるほどのニュースか、これ?
>>668 >>UIフレームワークには、GPUを活用した新設計のものを用意。このフレームワークは「GPUI」と呼ばれている。
これがどうなるかだな
rust製フレームワークの話なら歓迎、jsは該当スレでよろ
>>670 俺的にはそれなんかバックにC/C++のVulkan系を用いたものって気がするんだよな
rustでgpuなんか使い始めたらライブラリぶっ壊れまくるぞ
俺も今日からラスタシアンだからよろしくな
>>676 カタカタで書くとラステイシャンかラステイションだからよろしくな
全然関係無いんだけど
モヒカン族とか、一部の人間が使ってるだけでネットではろくに聞かない言葉だね
>>679 どうもありがとう
ネットスラングだったのか
でもPython界隈以外で聞いたことないや
俺は本場海外の用語以外は一切使わない陰キャチー牛の日本人が勝手な造語の和製英語とかクソダサいからな
2005~2010頃の技術コミュニティではよく聞いたけど
サビちゃんでもありヘビちゃんでもありヘジたんでもあり職場では犬たん++
>>678 C 使いや C++ 使いのことは Cer とか C++er と書いたりすることはあるが、どう読むべきなのかわからぬ……。
この世の中あまたの言語があるのになぜCやC++でコード書くかと言えば仕事だから
普段仕事でC++使わない俺からするとRustめちゃくちゃわかりやすくて触ってて楽しい
>>689 まあ他の言語触ると扱いやすくて気絶するから触るな
※お話の途中ですが蟹が通ります
命名規則のガイドラインがスネークケースなのがC/C++に配慮した結果なのかなぁって気がするけどまぁ慣れの問題だから文句ないよ
公式ドキュメントにRustは式指向言語ですってあるんだが式指向とはなんぞや?
制御構文が文じゃなくて式になってて値を返すという意味かと
終端にセミコロンつけたら式じゃなく文になっちゃうとか独特だよね
Rustはラムダ引数の型推論が多くの他の言語とは異なって機能するんだよ
最近、ゲームのRustが人気過ぎて検索に支障が出てる
>>694 日本語訳は公式じゃないから
今はもう公式では式指向(expression oriented)という言葉は使われてない
式指向言語の意味を知りたければwikiでもどうぞ
https://en.wikipedia.org/wiki/Expression-oriented_programming_language VTuberやストリーマーの間で人気を博しているサバイバルゲーム「RUST」とは?
https://www.moguravr.com/vtuber-rust/ Goを見習って、Rustlangで検索してくださいね
Rustではboolを論理値と訳してるけど言語ごとに揺らぎがあるのはなんでだろうね
作った人というより訳した人の違い
手元のRust本見てみたけど真偽値も真理値もあるね
型は論理型と言いたくなる。真偽値型ってのもたまに聞くけど。
the bookの日本語訳は翻訳の質が低いしアップデートもされてないからrustを本気で勉強したい人は読まない方がいいと思う
https://jp.mathworks.com/help/matlab/logical-operations.html > logical データ型を使用して boolean データを表現します
matlabではlogicalってデータ型があって中身は0か1
false, trueも結局はlogicalの0と1でしかない
https://doc.rust-lang.org/std/primitive.bool.html > The bool represents a value, which could only be either true or false.
> If you cast a bool into an integer, true will be 1 and false will be 0.
一方rustではtrueもfalseも依然としてboolのまま
ブール値のブールの意味を知らん人が多いのかもしれない
>>710 値の呼び名の話と、内部表現の話と、castせず別の型の値として利用可能かどうかという3つの異なる話を混同してる
Rustを含めたほとんどの言語で
おまえらってほんとう用語の定義とかそういう話になると生き生きしよるな
>>714 自分の呼び方が正しいんだー
っていうキチ同士の争い
>>714 ジュールとかニュートンのほうが先に頭に浮かんだ
>>716 とはいえ「所有権の複製」は見過ごせないって
これはプログラミングに限定した話ではなく他のカテゴリでも用語を英語に統一すべきだと思うんだよな
>>719 はぁ? 何を甘っちょろいこと言ってんだ。
日本語を押し付けていく気概もなしに学問をリードできるかいな。
>>722 日本語だけは絶対にイヤ
Rubyも英語だったろ?英語でいいんだよ
高階関数の解説を読むたびに出てくるカリー化がそれオーバーロードでよくね?って思うんだが誰か納得感ある説明頼む
>>725 カリー化は、ElmとかF#みたいなパイプライン演算子を多用する言語じゃないとありがたみを感じない
なんとRustには関数オーバーロードが存在しないのだ!
そうですね
// 引数2つの関数 (例としてたまたま足し算)
>>725 関数を書くたびにカリー化のためのオーバーロード書いていくのは面倒くさすぎるでしょ
カリー化なあ……
安直に引数個分のダミーパラメータを与えるカリー化マクロcurry!を用意してみた
>>733 rustを作る側からしたら嫌かもしれんけど、使う側からしたら有ったほうがいいんじゃない?
まぁ、俺がオーバーロードがある環境に慣れちゃってるからかもしれんけど
シャドーイングは許容できて関数のオーバーロードが許容できない理由ってなんだろう
>>735 クロージャ多用のRustでオーバーロードってどうするの?
例えば
>>734 に挙げた例でカリー化を同名でオーバーロードにする場合
let add = |x, y| x + y;
let add = curry!(add, a, b); // = |a| move |b| a + b;
assert_eq!(add(1)(2), add(1, 2));
この引数の数が異なる二つのaddの存在をオーバーロードとして許すの?
オーバーロードのある言語ではこの問題をどう解決しているのだろう
>>736 シャドーイングは同時に存在できるのが一つだけで曖昧さがなくプログラミングにおいてプラス効果
オーバーロードは同時に異なるものが存在できるため可読性を下げたりミスを起こす機会を生じさせてマイナス効果
>>735 読む時にはどのオーバーロードが呼ばれるのかを確認するのが面倒
RustだとT, &T, &mut T違いもあるから他の言語よりもさらに面倒
メリットよりデメリットのほうが大きいと感じる人が多いんじゃないかな
デフォルト引数/オプション引数/キーワード引数はいずれ導入して欲しい
乱用されるとAPIが汚くなるがオーバーロードほどのデメリットはないと思ってる
元の英語から違うので訳の問題ではありません (truth value)
logical values 論理値
まぁプログラマーでござい(ドヤッ!な勘違いの陰キャチー牛の癖に英語読めないポンコツなの日本人くらいだからなwww
同じ意味とされることもあるが、若干のニュアンスの差もあると思うんだよな。
たかが二値論理の値の型でしかないものを誰がboolだのbooleanだの呼び始めたのかと思って調べたらALGOL60だった
真理値だけは3値以上の場合も含むからちょっと意味が広い感じはする
関数オーバーロードをありがたがってるのはジャバの連中だけ
>>746 どれも注記がなければ二値だけど
three logical valuesやthree-valued Booleanと言えば3値になりえるので
基本的に意味するところは同じだと思うよ
>>749 確かに論理値も多値ありうるのか
真偽値もそう?これ字面からは2値限定な気がするけど
どうでもいいけどwasmerがaarch64 完全対応したということで、rust+wasm+wasmerでcliを試してみたけど完全にただのjavaで草生えた
Wasm は JVM より低レイヤ寄りだから設計思想は違うんだが……。
個人的にWasmよりもTauriの方が開発環境構築がめちゃ楽でシンプルだから好き
wasmとtauriって別にそういう競合するポジションとかじゃなくね?
Tauriはただのwasmのレンダラーだよ。Chromium内蔵をやめて実装をRustにしたElectron。
>>744 >>748 Rustの公式referenceでもbool値に対してのoperatorをlogical and やlogical orと明記されているから日本語訳は論理値でもよいのではないかな
>>756 論理和・論理積に対応する英語は logical disjunction / logical conjunction であって、 logical or / logical and ではない。
(でも演算子として OR / AND を使った表記をすることはよくあるし……。 カジュアルな場面では曖昧だったりするのかな?)
logical or / logical and は bitwise or / bitwise and と区別するために新しく作られたプログラミング用語として考えるべきで、
もちろん過去からの様々な分野の用語を踏襲してはいるにしてもあまり対応づけて考える必要はないと思う。
bool は人名 (固有名詞) に由来するんだからそのままブール値と訳すのに一票。
>>757 まずRustを含めてプログラミング用語の話においてのみboolが出てくるのだから他へ話を広げる必要なし
次にbitwise andに対してboolean andと言わずにlogical andと用いられているのはlogicalが説明としても用語としても妥当であるため
日本語としてもカタカナ訳語を使う必要はなく論理値や論理演算子でよいのではないかな
Tauriのモバイル対応はwasmのUIフレームワークの整備が進んでいないから、まだいいかな
もしreact 自体をウェブアセンブリとしてビルドできたら、、革命起きそう
Reactはもういいよウェブベースのクロプラフロントエンドフレームワークの問題を凝縮した実装だから早く消えてほしい
MSのweb開発フレームワークとプラットフォームはくそじゃん
>>755 ん?言ってる意味がわからないんだけどTauriのUIレンダリングプロセスはJS/TS/ReactなんかのウェブベースのフロントエンドFWだが?
Chromiumやnode.jsをバイナリに含めずプラットフォームのWebView(WenKit)を使うからサイズが小さいのだが?
レンダラーがWasmってどういうこと?具体的かつ納得できる説明よろ
DOM (またはそれの元になる html や JavaScript とかも含むのかも?) を生成することをレンダリングと呼ぶ界隈が存在するぞい。
>>766 >>JS/TS/ReactなんかのウェブベースのフロントエンドFW
フロントエンドに使えるフレームワークはjavascript系に限らないよ例えば上コメにあるYewとか
その前に
「wasmのレンダラー」の意味不明度が高すぎて混乱しているのだろう……
wasmのレンダラーっていうのはtauri+yewの組み合わせなら間違ってないよ
ちなみにjavascriptバインディングの無い既出の"web-view"ってのがcrate.ioにある
こっちは正真正銘wasmのレンダラーよ
https://crates.io/crates/web-view だからwasmのレンダラーっていう書き方が悪いだろうよ
Tauri can render JavaScript and WASM and more.
>>775 わかんね
アーキテクチャの違いとかならまだ興味わくけどな
まあフロントやらずにバックだけ開発の人には関係ない話だな
違う話題って事で
>>773 >>774 二人ともおかしい
wasmをレンダーすることはない
一般的にレンダリングとは抽象データから実データを生成すること
今回はTauriの話のようだからレンダリングは2階層あって
1つはTauri上で作るアプリが自分のデータからDOM(HTML)を生成するレンダリング
もう1つはTauri自体がそのDOM(HTML)からコンピューター画面へ描画生成するレンダリング
wasmが関係するとしたら前者
つまりwasm上で動くアプリがDOMを生成するレンダリング
wasmを使わない昔からのやり方ではJavaScript上で動くアプリがレンダリング
つまり対比点はwasmがレンダーするかJavaScriptがレンダーするか、とも言えることから
>>766 > レンダラーがWasmってどういうこと?
ここへ繋がるのではないかと推測
つまりRustコードを書くだけでアプリ作成を完結できるか否かの話にみえる
>>737 ローカルな宣言はシャドーイング優先でいいんじゃない?
関数やメソッドがオーバーロード出来たらいいなぁくらいの気持ちなんで。デメリットとかはやっぱあるよね
>>739 やっぱめんどくさいかなぁ?
そういう言語しか使ってこなかったからいまいちわからんのよ。rustに慣れればやっぱこっち!てなるんかねぇ
今スレの怪文書頂上決戦
52 デフォルトの名無しさん sage 2022/05/16(月) 19:06:18.85 ID:78bNbDCr
>>49 デタラメすぎ
ムーブでビットパターンのコピーは発生しない
ビットパターンのコピーが発生するのは引数の値渡し等であってムーブとは関係ない
さらに引数の値渡しでのでビットパターンのコピーとCopyのコピーも全く異なる
Copyのコピーはディープであって高コスト
755 デフォルトの名無しさん sage 2022/06/20(月) 17:55:14.20 ID:JDT/MbKD
Tauriはただのwasmのレンダラーだよ。Chromium内蔵をやめて実装をRustにしたElectron。
wasmerはレンダラーしないwasm実行環境。
TauriはJavaScriptやWebAssemblyをWebViewが理解できる機械語に変換するライブラリじゃないの?
オーバーロードがなぜ出来ないかって、型推論の完全性が失われるからじゃないの?
taui+webview==web rendererであってtaui≠=web rendererだから。
俺はフロントエンドやらないからこのスレでTauriの話をしないでくれ
renderやらrendererやら、レンダーやらレンダラーやら、ややこしいなおい
ジェネリクスで表現できるくらいの自明なものはオーバーロードしてもいいけど
オーバーロードできないのは違和感あるけどすぐ慣れるぞ。頑張れ。
>>784 言ってる本人が理解してないだけでwasmレンダラーって言い方はあるよ
TauriがElectronみたいにWebViewを内蔵してないから、TauriがWASMのレンダラーって勘違いしちゃったってことだな
古今東西ウェブのレンダラーってレンダリングエンジンのことじゃん
いい加減「wasmのレンダラー」を「wasmがレンダラー」と読むのやめたら?
「wasmのレンダラー」は、wasmでビルドされたレンダラーじゃなくて、wasmバイナリを読み込むことができるレンダラーってことじゃないの?
>>795 それは視野が狭い
例えばウェブ業界でCSR(client side rendering)やSSR(server side rendering)と言うときのレンダリングとはHTML/DOMを生成することを指す
CSRはブラウザ等の中でそれを行なうのでReact等ではJavaScriptでレンダリングをするしYew等ではWasm/Rustでレンダリングする
つまりWasmでレンダリングするということはTauriでは全てのコードをRustで書けることになる
cssを読み込んで適用できるからってわざわざそのレンダリングエンジンのことをcssレンダラーって呼ぶことがあるか?
>>797 Rust使いはASTまでは構築できてもそこから意味理解が弱いんだろうな
きみたちは一度これを読んだほうがいい
Rust GUI の決定版! Tauri を使ってクロスプラットフォームなデスクトップアプリを作ろう
Chapter 03 Tauri の概要
https://zenn.dev/kumassy/books/6e518fe09a86b2/viewer/168468 より
アーキテクチャ
Tauri のアーキテクチャを図示すると、次のようになります
Core Process はアプリケーション全体のライフサイクル管理を行ったり、 OS のインターフェース(メニューや通知など)の操作、 WebView Process の管理などを行います。
Core Process のコードは Rust で記述されるので、標準ライブラリも crate.io で公開されているライブラリも利用できます。 Tauri は非同期ランタイムとして tokio を利用しているので、非同期 Rust も使えます! Rust のコードはアプリケーションのビルド時にネイティブコードにコンパイルされるので、高速に動作します
WebView Process は Web コンテンツのレンダリングを行うプロセスです。通常の Web ページと同様に、 index.html, JavaScript, CSS から構成されて、 wry にラップされた WebView で動作します。
Tauri の JavaScript API を利用することで、 Core Process と通信したり、ファイルシステムにアクセスしたり、通知を表示する、などの操作が可能です。
WebView Process から WebView のサンドボックスを超えていろいろな操作できてしまうとセキュリティ上問題になることがあります。そこで、 tauri では JavaScript API で利用する API を allowlist に明示的に記述する必要があります。 Electron では preload スクリプトによって Renderer Process に公開する API を制限できましたが、同様の仕組みは allowlist で実現できます。
Tauri でアプリケーションを作ると Electron とは違い、 Chromium と Node.js 実行環境をバンドルする必要がないので、アプリケーションのサイズを小さく保つことができます
>>751 の、WASI実装のwasmerによるrustのVM言語化の話は興味深いけど、GUIフレームワークTauriの話はいい加減スレチ
Electronスレにでも行って議論してくれ
>>802 にあるようにHTML/DOMから画面へのレンダリングはWebViewがしてくれるからアプリ開発者は関与しない
アプリ開発者が関与するのはアプリデータからHTML/DOMへのレンダリング部分のコードを書くこと
この点はWeb開発でもTauriでも同じ
結局怪文書の出どころはいつものオジだったww
IDコロコロしないでほしいわせめて
wasmくんたちはコッチ
【wasm】ブラウザでC++。Emscriptenを語ろう
http://2chb.net/r/tech/1547549448/ 論理構成が薄弱で常に自己正当化するためだけにレスを重ねる人は相手にしちゃダメなんだよ
コテハンつけてくれるんなら
>>980 ワッチョイついでで思い出したけどvs C++へのリンクは落ちてるから消しといてくれ
>>719 これ和製英語もそうだが和製発音も相当やばいよ
今ホットなウクライナがバリバリの和製発音でUkraineって本来ユークレインて発音するからな
英語できないでボランティア行ったやつウクライナ!ウクライナ!って全く通じない発音を連呼してたかと思うとはこっちが恥ずかしくてまさにもう見てらんない!
いい加減に読みも発音もグローバルスタンダードにしろっつーの何でもかんでもガラパゴスなの頭悪すぎる
>>815 強いて言えばウクライーナってくらいで和製発音じゃないから通じるよ
日本は英米と違って中華系の地名・名前以外は現地発音に寄せてるものが多い
中華系は日本語漢字読みだと外国人には全く通じない(中国人・台湾人なら漢字で書けば通じる)
Rustも最初はルーストって発音してる人いたよね
Scalaをスケイラとかも
いや通じないんだなこれがアジアの英語圏ですら通じないんですよ嘘吐いちゃダメよ
フィリピン人のオンライン英会話レッスンで
触れちゃいけない人だろ
論破されると変人扱いでシカトとかまんま陰キャチー牛オタクで草
ID変わっちゃうのは仕方がないことだからコテハンつけてくれ
俺の場合、英語だと何倍も読むのに時間がかかったり、わからない単語や言い回しがあったりするので和訳はありがたいんだけど・・・・
発音か…
ヨーロッパの地名も日本語は英語よりまともなことが多い。現地語をカナカナに当てはめちゃってるので発音は違うけど。
おまいらどれを読み間違っていたか正直に言いなさい
>>815 そこは英語できないじゃなくて、English出来ないだろ!
欧米のひとなんて日本をジャパンとかいう謎の呼び方するじゃん
最近の言語って、代入は使う事少なく無い?
>>830 Siriとかに発音させるアプリいいよ
単語レベルならかなり正確
あとは技術系の動画
最初に舌の動きやlinkingを学んだほうが効率いい
>>833 ヘイト
ウィズス
アジャスト
フォルス
キュー
デキュー
ラムダ
ちゃー
基本点5点
>>833 width, deque, char
widthは発音記号(/wɪdθ/)を見て長いことウィドスっぽく発音してた
clothes /kloʊðz/とかも一緒
charとかは純粋な英語ではないからSQLと一緒で英語圏で広く使われてる発音と違ってても全然気にしない
Rustで言えばmut、impl、dyn
>>833 昔の会社の上司が lambda をランバダって読んでた。
冗談なのかマジなのか未だにわからない。
>>843 社内で言ってる場合はまだいい
客先で言ってないか心配
falseがいまだにフォールスと読めない
英語なんて下層階級発音の言語をありがたがってもしょうがない。
英語はまだ覚えやすいんだよ
charは英語でもチャー派とキャー派の両方いる
>>847 char aznableのシャア派はいないのか?
CHR$のころならキャラもありだけど
int イント イントゥ インテジャー
英語人の発音なんて知らんよ。
中世に母音がずれてってスペルと発音がずれてしまった
ナルトとかドラゴンボールみたいな日本作品を海外放送するときに日本語っぽい発音を使わせよう
世界的に見ても英語は最も訛りが酷いのでそれほど気にする必要はない
>>836 European、American、Russianが本当の人間、〇〇〇eseは彼らの感覚では亜人種
「ese」を使って「軽くバカにする」のは「journalese」や「officialese」とう言葉です。
tauriがcargoだけでセットアップできれば即導入するんだけどなー
html+jsベースのアプリのネイティブのバックボーンがtauriじゃないの?
>>859 既に前スレで出ているように
Tauriはcargoだけで利用できます
npmやNode.jsなどのJavaScript環境は全く必要ないです
http://2chb.net/r/tech/1644596656/192 >>860 Webサイトを自分でJavsScript書かなくてもRustのみで構築できるように
Tauriでも同様にWasm利用のRustによるフレームワークを使ってRustのみで可能です
糊しろ部分のJavaScriptコードは自動生成されるため気にする必要がないです
Yewが1.0.0になってMaterialUIのcrateできたらやるわ
Tauri以上に未完成なYewとか本当に触るだけだなこんなので何が出来るんだよw
YewはReactと比べてライフサイクルや状態管理はどうなん?
>>862 Rustでは大半がメジャーバージョン0なのを知らないのか
例えばcargoは最新が0.62.0
1.0.0にならないから使わないのか?
Yewのmaterial UIならば material-yew crate
デモ
https://yew-material.web.app/components >>863 ツールチェーンの変更は不要
必要なのはtargetとなるアーキテクチャのインストール
rustup target add wasm32-unknown-unknown
この1行で済むから悩むところもない
その後のbuildでのtarget指定などはtrunkで全自動化されてるから指定不要
難しいところは何もない
Rustコードを書くだけ
>>865 randとかの準標準系ライブラリはまた別かもしれないけど、semverの一般論として0.y.zは更新を追い続ける気のある暇人&人柱向けでしょうが
使ってほしかったらこんなところでレスバしてないでバグ出してパッチ書いて1.0.0リリースするの手伝いなさい
>>867 本気でそんなこと言ってるなら笑う
使っているクレートほとんどが0.y.zだぞ
Rustで1.0.0にこだわる人を初めて見た
まぁsemverの一般論としては1.0.0より前は互換性の制約一切ないからそれは正しいんだが
YewやPerchやseedが流行るとは思えないけどねじゃあ何が流行るんだって話だけどwasm自体が流行らないと思うわ
若いのにバージョン8.0とかになってるライブラリよりはバージョン0.8.100なライブラリを使いたい
wasmのistioのように拡張機能を書くのに使われるんじゃないの
>>870 wasmを理解できていない
とっくにブラウザと切り離され発展していってる
>>871 同感
メジャー番号がデカい=破壊的バージョンアップを繰り返している だもんな
まぁUnityとかLua置き換えとかそういうニッチで局所的に使われるだけだわな
ちみたちが全否定してボロクソ言われてるElectronが人気出てちみたちも使ってるであろうVSCodeもElectronなのだよ
>>876 C++、JavaScript、Pythonあたりのバインディングが実装されれば人気が出るかもね。
>>875 そうでもない。
クラウド内でも実行中のプロセスを他のノードに移動させて負荷を平均化するなどの用途に使える。
ちょっと前までRustなんて流行らないと喚いてたアホが別のところにケチをつけはじめたな
ウェブでwasmを使っているケースは増える一方
たしかにCloudflareとかFastlyがすでにやってるように、wasmが一番使われるのはアプリケーションのホスティング関連ではありそう
オジ必死すぎやろww
wasmは、アーキテクチャ共通の中間コードを生成する点、主要webブラウザ上では既に完璧に動作する点、当然ながらマルチスレッドに対応している点が良い
アプリをPWAにして独自決済にすれば手数料を取られない!ギャグだろwww
無知がバレたから話をそらして挽回しようとするアホの図
個人的には審査の通らないスマホエロゲとか発展しそうでいいかと思ったんだけど
散々wasmを誉めそやして語って布教した結論がスマホエロゲ
このスレでRustスゲーするのは理解できる
じゃあみんなこっちにもきてよ
【wasm】ブラウザでC++。Emscriptenを語ろう
http://2chb.net/r/tech/1547549448/ wasmを使うならRustだからだろう
GC言語では本末転倒
C++よりRustという当たり前の結果
>
https://www.atmarkit.co.jp/ait/articles/2107/08/news112.html > 「WebAssemblyアプリケーションの作成に使用している言語は何か」と質問したところ、Rustが最も多くの回答を集めた。
> 「WebAssemblyアプリケーションの作成に今後最も使用したい言語は何か」という質問でも、Rustを挙げた回答が最も多かった。
Wasm の側に GC を入れる提案も出てはいるので将来的にはどうなるかわからんぞ。
>>873 1.0未満のバージョンって仕様自体fixしてなくて予告なく破壊的変更入る可能性があるのが普通だと思ってた。
窓の杜: C++言語によるお嬢様コーディングがブームの兆し!?.
https://forest.watch.impress.co.jp/docs/serial/yajiuma/1419370.html メモリをしっかりお片付けなさりたいのならRustを使いませんこと?
お嬢様コーディングなんて流行ってねえよ
>>895 普通はそうだ。でももちろん例外だってある。
その辺は開発者組織の感性しだいだな。
何年もずぅ~っとβ版のプログラムだってあるだろ。
>>895 自分たちが使っているcrateのtreeを見れば分かる
大半がバージョン0
それで誰も困っていない
>>894 GC導入は各言語であまりにも異なるため失敗した
各言語が様々な形でしている効率的な方法は取れない
WebAssemblyはRust一強が続くだろう
>>896 Rustはなんだかゾクゾクしますぞ!!これは服なぞ着てる場合ではありませんぞ!!
まあクソネタにはクソって言っとかないと本当にウケてると思っちゃうやついるからね
そうそう、クソネタにはそうやってダサいと言っておかないと
スルースキルが皆無なのですわ
>スルースキルが皆無
wasmって流行ってるけどコード量膨大に増えすぎないか?
フロントエンドの奴らが rust を使ってるの見てらんない。
ところでものすごい今さらなんだが wasm は何て読むんだ?
ネイティブはだいたいワズムとかウォズムみたいに発音しているような気がする
この動画では冒頭でwasmをワスムって言ってる
VIDEO >>918 これはワズムっていってないか?リスニングはからっきしのゴミ耳だからよくわからんけど
asm.js(アズム ジェイエス)が進化してwasm(ワズム)に
英語できねーおっさんが蘊蓄垂れてクソワロタwww
>>925 もちろん Wasm は WebAssembly の省略形だよ。
公式にもそう書いてある。
それはみんな知っての上でレスしてるのに
>>925 みたいな周回遅れのレスを堂々と付けれるやつって
脳みその構造どうなっとんやろな
>>926 じゃあ、ウェブのアセンブラって意味で良いんじゃないの?
WebAssemblyは仮想命令セットアーキテクチャあるいはプログラミング言語の一種である。略称はWasm。C・Rustなど様々なプログラミング言語のコンパイルターゲットとしてWasmバイナリは生成され、ウェブブラウザを含む様々な環境内のスタックベース仮想マシンにより実行される。
ネイティブコード相当の高速性・隔離環境でのメモリ安全な実行による安全性・仮想マシンによるハードウェア/プラットフォーム可搬性・ソースプログラミング言語中立性などを特徴とする[4]。この命令セットはバイナリ形式で定義されており、またアセンブリ言語ライクなテキスト形式も定義されている(その意味で低水準プログラミング言語といえる)。
Wasm自体は命令セットアーキテクチャであり、Linuxカーネルが提供するようなシステムコール(例: ファイルI/O)、Webブラウザが提供するようなDOMアクセスなどを提供していない。上記の安全性や可搬性はこの特徴に由来している。それと同時に、WasmエコシステムとしてはシステムコールやDOMアクセスがAPIとして個別に定義されており、Wasmランタイムが実装することでそれらの機能を提供している(例: システムコールを提供するWASI)。シンプルでオープンなISAとランタイムごとのAPIを組み合わせることでWasmエコシステムは高い拡張性を有している。例えばWasmをHTTPプロキシでのフィルタスクリプトとして利用するプロジェクトが存在する。
https://ja.m.wikipedia.org/wiki/WebAssembly より
>>930 >>931 にあるように、ウェブのアセンブラという解釈は間違ってる。
ウェブアセンブリっていう名前なだけ。
わかった?
現実問題としてWasmはRustで書くのがベストソリューション
仮想マシン上で動くという点でWASMはJavaと一緒だな
>>930 そもそもアセンブラとかいってる時点でなにもわかってないから相手にするだけ無駄、無視推奨
Rustで書くとバイナリ肥大化するから、WATが基本になりそうでは?
>>935 javaの問題をある程度解決したのがwasmっていう認識でおけ?
それな。Javaっぽくwebvmとかwebバイナリとかいった名前の方が分かりやすかったんじゃなかろうか
>>930 仮にウェブのアセンブラだとして、ウェブのアセンブラってなんやねん……
>>941 俺の予想では、それが質問内容だと思います。
DOM・シャドーDOM操作が遅いからwasmはあまり流行らない、これを何とかしない限り、シコシコts書いてるオジサンが量産される
俺は白人の読み方なんか認めんよ。
命名の伝統としてちょっとしたネガティブワードを使うことがあるんだよ。
いわゆるギークセンスというやつだが、日本語でいう中二病に近い。
GIMP の名前を変えるためにフォークするだのなんだのでもめたことがあるの知らんか?
Wasm もそれと同じようなノリなんじゃねーの?
https://eow.alc.co.jp/search?q=wasm >>952 きみはそう呼んでればいいと思うよ
きみにそう呼ぶ機会はないと思うけどw
菅総理が、我が国はワッセンブラに注力すると宣言したら、どうするんだよ?
なるほど、、?(わからん)
WebAssembly Reference Typesで、WasmでDOMを操作する壁がここまで下がった
https://zenn.dev/igrep/articles/2021-11-wasm-reference-types DOM操作なんか、どうやっても遅いんだからワズムからいじる必要ないだろ
そんなことはない、JSやTSのようなダメ言語を排して、全部ほかのコンパイル型言語で統一して書けるように考えたのに
wasmはjsを置き換えるものではないっていう方針がよくわからんな。置き換えていいのに。
タイプスクリプトでドム操作書いてみたら分かると思うけど、キャストだらけになる
WebAssemblyはJavaScriptを置き換えようとしていますか?
いいえ!WebAssemblyは、JavaScriptを補完するものであり、JavaScriptを置き換えるものではないように設計されています。WebAssemblyは、時間の経過とともに多くの言語をWebにコンパイルできるようになりますが、JavaScriptには信じられないほどの勢いがあり、Webの単一の特権( 上記のとおり)動的言語のままです。さらに、JavaScriptとWebAssemblyは、さまざまな構成で一緒に使用されることが期待されています。
・JavaScriptを活用して物事をつなぎ合わせるコンパイル済みのC++アプリ全体。
・WebAssemblyで制御されるメインのセンターキャンバスの周りのHTML/CSS / JavaScript UIにより、開発者はWebフレームワークの力を活用して、アクセス可能なWebネイティブな感覚のエクスペリエンスを構築できます。
・ほとんどの場合、いくつかの高性能WebAssemblyモジュールを備えたHTML / CSS / JavaScriptアプリ(たとえば、グラフ化、シミュレーション、画像/音声/ビデオ処理、視覚化、アニメーション、圧縮など、今日asm.jsですでに見られる例)開発者が今日のJavaScriptライブラリと同じように人気のあるWebAssemblyライブラリを再利用できるようにします。
・WebAssembly がガベージコレクションされたオブジェクトにアクセスできる:ユニコーン:ようになると、それらのオブジェクトはJavaScriptと共有され、独自の壁に囲まれた世界には存在しなくなります。
https://webassembly.org/docs/faq/#is-webassembly-trying-to-replace-javascript より
tenplate要素使ってDOMツリー作ってそこに値や要素追加して表示しろって言われた時は訳わかんなかった
>>972 スペル間違うぐらいなら無理せずカタカナで書けよ
フロントに全く興味ない奴らが無理してrust使おうとしてるってのがもうクソだわ
Stringの中身が変化してほしい時のtrim()はどうすればよいですか?
s.retain(|c| !c.is_whitespace());
>>979 そりゃそうだろw
後側の削除だけならtruncateすればいいんじゃね?
let mut s = String::from("てすと ");
let end = s.rfind(|c: char| !c.is_whitespace()).unwrap();
s.truncate(end + 1);
thread 'main' panicked at 'assertion failed: self.is_char_boundary(new_len)'
ダメだった…
s.truncate(s.trim_end().len())
Linus「メモリ確保でpanicするって?認めんわ断じて認めん、ワシの目の黒い内は許さんぞ」
Linuxの話題は、あわしろを召喚しちまうから、やめとけ
fn trim_in_place(s: &mut String) {
> s.find(|c: char| !c.is_whitespace())
5chでまともな回答期待する方が頭おかしいことになぜ気付かないんだ
>>988 関数を自分で定義しとけばわたせるけど
合成しながらだとマクロ使わないと無理なんじゃないかな
>>461 https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=9110b8c76b17fb479bfef80e1f10182d >>989 プログラミング情熱のある2-30代の集う板じゃなく
プログラミングはもう碌にしないおっさん・爺が多数の板だからな
質問してもおいおいな回答になるのは仕方ない
>>989 翻訳の話題はあわしろを召喚しちまうからやめとけ。
rust cliコマンドがなぜrustupなのか誰も疑問に思わんの?
>>995 今はrustcやrustfmtなど含めて全て実体は同じでハードリンク
cargoが各ワーキングディレクトリに対して適用されるのに対して
rustupは全体に適用されるため
同じ名前のサブコマンドでも全く異なる
💣 🎴 💣 🎰 🎰 🌸 🌸 😜 👻
♥5 ♣8 ♠7 HP: 1000 pts. たぶん(0) このスレッドは1000を超えました。
5ちゃんねるの運営はプレミアム会員の皆さまに支えられています。
運営にご協力お願いいたします。
───────────────────
《プレミアム会員の主な特典》
★ 5ちゃんねる専用ブラウザからの広告除去
★ 5ちゃんねるの過去ログを取得
★ 書き込み規制の緩和
───────────────────
会員登録には個人情報は一切必要ありません。
月300円から匿名でご購入いただけます。
▼ プレミアム会員登録はこちら ▼
https://premium.5ch.net/ ▼ 浪人ログインはこちら ▼
https://login.5ch.net/login.php
このスレへの固定リンク: http://5chb.net/r/tech/1652347700/ ヒント: http ://xxxx.5chb .net/xxxx のようにb を入れるだけでここでスレ保存、閲覧できます。TOPへ TOPへ
全掲示板一覧 この掲示板へ 人気スレ |
Youtube 動画
>50
>100
>200
>300
>500
>1000枚
新着画像 ↓「Rust part15 YouTube動画>1本 ->画像>11枚 」 を見た人も見ています:・なんUSTR部 なんUSTR部 SUPER GT+ catch surf SUPER GT+ TRAP MUSIC SUPER GT+ SUPER GT+ SUPER GT+ SUPER GT+ sui part1 初心者Vtuber NUMBER SHOT Sproutsスレ Nexus 9 Part19 aurisms 尊師 Uber Eats 邪魔 Nexus 6 Part36 DONGURI QUEST Castle Burn 汁@Shirutaro_ Duelyst Part7 Music Thread Nexus 5X Part7 Suchmos part 8 OnePlus Part88 OnePlus Part92 LuckyFes part1 Supreme Part.2 Oneplus Part.8 ZOZOUSED part4 OnePlus Part81 berghaus Part.1 VOI SQUARE CAT OnePlus Part93 24bit RISC CPU OnePlus Part86 Supreme Part.2 UberEatsを哲学する OnePlus Part121 OnePlus Part25 OnePlus Part15 Nisus Writerを使おう YAESU FT1D part5 Supreme Part6 Suchmos part 39 Suchmos part 16 ZOZOUSED part1 SonarSound Tokyo zatudan e sure Treasure Casket OnePlus Part133 VirusTotalスレ ( ゚д゚)、ペッ RUSEEL Nexus 6 Part30 Suchmos part 41 Nexus 6P Part22 Do It Yourself OnePlus Part73 OnePlus Part45 OnePlus Part34 Suchmos part 20 Suchmos part 19 Tumblr 21 notes Android Studio 2
09:31:51 up 29 days, 19:55, 0 users, load average: 7.38, 6.74, 7.52
in 1.8703248500824 sec
@1.8703248500824@0b7 on 011023