�������ȗ��R�ɂ�鏑�����݂̍폜�ɂ��āF �@�@�@�@�@�����p�V�Ƃ݂������:
Python�̂��� Part70 YouTube����>1�{ ->�摜>11��
����A�摜���o �b�b
���̌f����
�ގ��X��
�f���ꗗ �l�C�X�� ����l�C��
���̃X���ւ̌Œ胊���N�F http://5chb.net/r/tech/1677856680/
�q���g�F5ch�X����url�� http://xxxx.5chb.net/xxxx �̂悤��b�����邾���ł����ŃX���ۑ��A�{���ł��܂��B
���X�����Ă閈�Ɍ���̂ŁA�����Ă���R�ɕ�[���邱�ƁB
�E���X����Ruby�̃\�[�X�R�[�h�ނ��������Ƃ��ւ�
�ERuby���APython�ł͂Ȃ��v���O���~���O����ł̉ށE����������̂��֎~
�E�uRuby �ł́v�uRuby�ł́v�uRails�v���K�\�����u^�N�\�`����w$�v��NG���[�h�o�^����
�E�G���[�������������Ƃ��́A���Ȃ炸
�@�G���[���i����ɏȗ�or�X�N�V���������̉����֎~�j��
�@���܊iPython�̃o�[�W�����ԍ��{OS���ƃo�[�W�����{IDE���j�������B
��Python�̃\�[�X�R�[�h���T�����ɒ��\�̓C���f���g������̂ŁA
�@�@�����̃R�[�h�����p�T�C�g�ɓ\���Ă��Ă��������B�i�X�N���[���V���b�g��������u�����v�֎~�j
https://techiedelight.com/compiler/�@�@Run Code�@�\����B
http://ideone.com/�@�@�@�@�@�@�f�t�H�ݒ肪C�Ȃ̂ŁAPython����ɂ͌����I���{�^���������ߺ��Ԃ����B
http://pastebin.com/�@�@�@�@�@�܂��܂��V���v���B
http://dpaste.com/�@�@�@�@�@�@�ƂĂ��V���v���B������܂ł̓����͏\�����[���w��̂��ƁB
��Python�I�t�B�V�����T�C�g�@http://www.python.org/
��Python�h�L�������g�@https://docs.python.org/ja/3/
���܂Ƃ�wiki�@http://python.rdy.jp/
VIPQ2_EXTDAT: default:vvvvv:1000:512:: EXT was configured ���֘A�X���� ���̏��S�҂́���
�y�܂�1�Łz��������Python(�����S�җp) ����58
http://2chb.net/r/tech/1662514433/ �Z�O�X���Z
Python�̂��� Part69
http://2chb.net/r/tech/1669293584/ ���X���̌�����
>>985�����킷��B�i980�ʉ߂���24h��������Ȃ��Ȃ����j
### END of TEMPLATE ### ?
VIPQ2_EXTDAT: default:vvvvv:1000:512:: EXT was configured
�C�ɓ����X���ɂ킴�ƕ����딚���Ă����X�^�C�������s���Ă�̂�
�딚���܂����A��������������w
>>985 >>1�擪�̃R�}���h�������Ă�̂ŖY�ꂸ�ɂ��肢���܂�
!extend:default:vvvvv:1000:1024
!extend:default:vvvvv:1000:1024
!extend:default:vvvvv:1000:1024
���X�����Ă閈�Ɍ���̂ŁA�����Ă���R�ɕ�[���邱�ƁB
pytorch��Tensor���ǂ��炪�������߂ł����H
�ړI�̓}���`�O���{��肽���ł��B
���U�b�N����������Ǝ����ŐF�X�A���S���Y���g��Ŏ��s���낷��̂�pytorch�ŏo�������̃��f�����g���ăp�p�b�Ɠ������̂�Tensorflow������p�r�Ŏg��������
�Ȃ�ł����Ȃ��
�Ȃ�ŕ`�������Ă����҂��铮��ɂȂ�ˁ[�J�X���Ďv���Ă���
def __lt__���t�ɂȂ��Ă�
�E���R
>>8 ��[���Ȃ��Ƃǂ�Ȗ�肪����́B
>>10 �������c�H������tf�������������A�����łȂ����Ƃ���tf�Ől�̍�����R�[�h�������Ƃ���torch����c
tkinter�Ŕz�u�����{�^�����}�E�X�ō��N���b�N�������̋����ɂ��āA
command=test_func ���g�����ꍇ�́A
�{�^�������N���b�N�������ɁA�{�^�����������܂ꂽ�悤�ȕ\���ɂȂ�B
����������������āA①���N���b�N②�E�N���b�N�̂��ꂼ��ňႤ�������s�킹�悤�Ƃ������ɁA
---------------------------------------------
def test_func(event):
�@�@if event.num != 3:
# ②�E�N���b�N�̏ꍇ�̂ݍs������
�@�@~~~ # ①②���ʂ̏���
btnExeAll.bind('<ButtonPress>', test_func)
---------------------------------------------
�Ⴆ����Ȋ����ŏ����ƁA
�{�^�������������ɁA���N���b�N�E�N���b�N�̂ǂ���ł��A�{�^�����������܂ꂽ�悤�ȕ\���ɂȂ�Ȃ��B
���N���b�N�����������ł����̂ŁAcommand=test_func �Ɠ����悤�Ƀ{�^�����������܂ꂽ�\���ɂ�����@���������狳���Ă��������B
�����Ă�肽��������̎d��������
>>15 �E�N���b�N�̏ꍇ��event.num��3�ɂȂ邩��A
�R�[�h�̍ŏ��̃R�����g�́u②(�E�N���b�N)�ȊO�̏ꍇ�̂ݍs�������A���������B
�����������Ă�肽�����ǂދC�����Ȃ�
Tk/tkinter�g�������ƂȂ���ŎQ�l�ɂȂ�Ȃ���������Ȃ����ǁc
Web�t�����g�G���h�Ƃ�GUI�v���O���~���O�ł悭������ǁA
�����̏ꍇ�A�{�^�����N���b�N�������ƂɂȂ�̂́A�{�^�����Ń}�E�X�{�^�����������ꂽ�u�Ԃ���Ȃ��āA�}�E�X�{�^���������ꂽ�u�Ԃ��Ǝv����ˁB
��ŕ��ʂ�click=�Ŋ����w�肵���Ƃ��́A�{�^�������Ń{�^���������ꂽ���ɕ\����ύX���A
�{�^���������ꂽ���Ƀ{�^���������ꂽ�ӂ��ɕ\����ύX���A����ɗ����ꂽ�Ƃ��Ƀ}�E�X�J�[�\�����{�^�����ɂ����
�N���b�N�����ɂ��Ċ������s����A�Ƃ����悤��bind�����Ă�Ǝv����ˁB
������Abuttonpress�̃C�x���g�n���h�������̂܂㏑������ƃ{�^���̋����Ƃ��Ă͖]�܂����Ȃ����Ƃ������N����̂ł͂Ȃ����ȁ[
Python�̂悤�Ȋ����x�̍���������w�K���Ă���l���A�܂���
�킴�킴python��GUI��낤�Ƃ��闝�R�͊w�K�R�X�g���Ⴂ���炾��ȂƎv��������tkinter�͊w�K�R�X�g�������邾��
���Ȃ�unity��vc�ŏ���
���s���x�����邩�犄�ɍ���Ȃ����Ęb���
tkinter�g���Ă݂��炷���T�C�Y���o���߂Ȃ�����
�������Ȃ��c
pyside�Ƃ��̕���������
�E�B�W�F�b�g�̔z�u�ɂ͂R�̕��@������
(1) .pack()...�c�����P��ɔz�u����i�P�����z�u�j
(2) grid......�i�q��ɔz�u����i�Q�����z�u�j
(3) place.....�ʒu�i���W�j���w�肵�Ĕz�u����
>>19 �q���g���肪�Ƃ��������܂��B
btnExeAll = tk.Button(root, text='������')
btnExeAll.bind('<ButtonRelease>', test_func)
tk.Button()�̒��ɏ����Ă����ucommand=test_func�v���폜���āA
ButtonRelease��test_func��bind�����邱�ƂňӐ}��������ɂȂ�܂����B
�}�E�X�{�^�����������ꂽ�i�K�ł͒ʏ��tk.Button�������̕\��(�{�^�����������܂ꂽ�\��)�ŁA
���̃}�E�X�{�^���������ꂽ�u�Ԃ�test_func���Ă��C���[�W�ł��ˁB
>>27 �����ɗ��Ă��悤�ŗǂ�����
>>15 tkinter�̃{�^�������������ɁA�{�^�����������܂ꂽ�悤�ȕ\���ɂȂ�̂́AButtonPress�C�x���g�����������Ƃ��̃f�t�H���g�̋����ł��BButtonPress�C�x���g�́A�}�E�X�̃{�^���������ꂽ�Ƃ��ɔ�������C�x���g�ł���AButtonRelease�C�x���g�Ƌ��Ƀ{�^���̃N���b�N�C�x���g��\���܂��B
�ʏ�A�{�^�����������܂ꂽ�悤�ȕ\���ɂȂ�ɂ́AButtonPress�C�x���g�ł��̏�Ԃ�ݒ肵�AButtonRelease�C�x���g�ʼn�������K�v������܂��B�������Acommand�I�v�V�������g���ꍇ�́AButtonPress�C�x���g�ʼn�������̏������s�����Ƃ��ł��܂���B
�����ŁAButtonPress�C�x���g�œ���̏������s���A���̌��command�I�v�V�����Ŏw�肵�������Ăяo�����ƂŁA�{�^�����������܂ꂽ�悤�ȕ\���ɂ��邱�Ƃ��ł��܂��B��̓I�ɂ́A�ȉ��̂悤�ȃR�[�h�ɂȂ�܂��B
def test_func(event):
if event.num == 1: # ���N���b�N�̏ꍇ�̂ݍs������
btnExeAll.config(relief=tk.SUNKEN) # �{�^�����������\���ɂ���
# ②�E�N���b�N�̏ꍇ�̂ݍs������
# ①②���ʂ̏���
btnExeAll.bind('<ButtonPress>', test_func)
btnExeAll.config(command=lambda: None) # command�I�v�V������������
���̃R�[�h�ł́AButtonPress�C�x���g�ō��N���b�N�̏ꍇ�Ƀ{�^�����������\���ɂ��A�E�N���b�N�̏ꍇ�ɂ͉����������s���܂���B�܂��Acommand�I�v�V�����������邽�߂ɁA���lambda�����w�肵�Ă��܂��B����ɂ��AButtonPress�C�x���g�ł̏�����command�I�v�V�����Ŏw�肵�������d�����Ď��s����邱�Ƃ�h�����Ƃ��ł��܂��B
�Ȃ��A�{�^�����������\������������ɂ́AButtonRelease�C�x���g�Ń{�^���̏�Ԃ����ɖ߂��K�v������܂��B�ȉ��̂悤�ɏC�����邱�ƂŁA�{�^�������������Ƀ{�^�����������܂ꂽ�\���ɂȂ�A���������Ɍ��̕\���ɖ߂�悤�ɂȂ�܂��B
def test_func(event):
if event.num == 1: # ���N���b�N�̏ꍇ�̂ݍs������
btnExeAll.config(relief=tk.SUNKEN) # �{�^�����������\���ɂ���
>>29 ���肪�Ƃ��������܂��B
�悭�ǂ�ŃR�[�h�ɔ��f���������Ǝv���܂��B
colab��Ő������������̃t�@�C��(50KB���x��3�����炢)�������_�E�����[�h���悤�Ƃ�������
colab�̃Z������
---
fori in range(len(�t�@�C���p�X�̃��X�g)):
files.download(�t�@�C���p�X�̃��X�g[i])
time.sleep(10)
---
�Ə����Ă�
sleep��10�b���Ɂu�u���E�U�̃_�E�����[�h�̃��X�g�ɓ���v�킯�ł͂Ȃ�
����for�����I����ăZ�����I���������ƂŁA�S��������Ɂu�u���E�U�̃_�E�����[�h�̃��X�g�ɓ���v�݂����Ȃ��
������Ăǂ��ɂ��Ȃ�Ȃ����ȁH
colab�̎d�l������ǂ����傤���Ȃ��H
50�s�ŏ����ꂽ�T���v���R�[�h��500�s�ɂ��Ď��s����1/20�ɂ���
�B��������
������x���ԊJ���ăp�b�P�[�W��������@���ׂĂ�ƁA���ׂ邽�тɐV�������@�o�Ă�C������
�����setup.py�Ȃ��Ă�"pip install -e ."�ł���悤�ɂȂ��Ă�
setup.cfg��pyproject.toml�ł��F�X�Ⴄ���o����̑�ς��Č������A�܂��o���Ă͂Ȃ�����
Google�R���{�v���v���X�ɓ����Ă�����܂����H�R���{�v���̗ǂ��������ĂˁI
�@�B�w�K�n�̖{�ŊȒP�ɉ���������x�ɂ���Python�̂��Ƃ�m��܂���
����Python�ɐG���ɓ�����A�������Ƃ̂Ȃ����Z�q�╶�@�������������ꍇ�A�ȒP�ɒ��ׂ���@�Ƃ����Ă���܂��H
�i�킩��Ȃ����Ƃ��o�Ă��邽�тɃO�O��Ηǂ��C��������̂́A�O�O�邽�߂̗p��ɂ��ǂ蒅���Ȃ��C�����Ă��܂��܂��j
gpt4���g��python�ŏ��������Ă�l�͑�����ˁB�Ȃ�ΐ�l�̒m�b���g���Ă����^���������������I����ˁB
HTML�Ȃ�ǂ����낤�H
>>32 ���������̔]�`�h�o�h�o�ł���
�l�b�g�Ɍ��J����Ă�T���v���R�[�h�������狳���ė~����
����1/50��ڎw��😤
Python��datetime.utcnow�̐��x���Ăǂ̂��炢�ł��傤���H
xs = [1.0,2.0]
c = complex(xs)
���ƃG���[�o�邯��ǁA�l�̃R�[�h�ǂ�ł�����
c = complex(*xs)
���ƕ��ʂɒʂ�ƒm�����B
�����ƒ��ׂ������ǂ��̋@�\���ĂȂ�Ă�����ł��傤���H
�h�L�������g��
�܂������o���ĂȂ�����
���Ȃ��Ƃ�lisp��50�N�ȏ�g���Ă邱�̋L�@�̗R���������Ăѕ�splicing(,@list)�̂͂�
�������X�g�̃A���p�b�N�Ƃ�����ł��ˁB
���肪�Ƃ��������܂��B
dos�Ń_�E�����[�h���āAvscode�ł�낤�Ƃ��Ă�p�X�������ĂȂ��Ƃ������Ăł��܂���
�p�X����Windows�̑S�Ẵt�H���_�ɒʂ��Ȃ���ł��傤��
���������and�ŕ�����������ꂽ�ꍇ
False���m�肵�����_�ňȍ~�̔���͍s���Ȃ��݂����Ȃ�
1�O�̏�����True����Ȃ��Ǝ��̏��������G���[�ɂȂ������
1�s�ōς܂��͈̂�ʓI�ɗL��H
>>48 ����
len(val) > 0 and val[0] != 0�Ƃ��͂悭����
�l�I�ȍD�݂������AErr1��2�͋�ʂ�������D���B�Ȃ̂ŁAand��1�s�ōς܂��Ȃ��B
if len(val) > 0:
_if val[0] != 0:
_else:
__Err1
else:
_Err2
>Python��C�^C++�ɕC�G������s���x�������@��MIT�ȂǃR���p�C���uCodon�v�J��
���ꂾ�悱��
�̂�����ǂ�Ȍ���ł��A�R���p�C�������D�G�ɍ��������Ďv���Ă���
����ł��邱�Ɣ���ꂽ��f�����b�g����̂͂���������
����CPU�œ���������R���p�C�����撣�����Ă�
�ϐ��̌^��X�R�[�v���R���p�C�����ɉ����o���镔���͑����o������������
���s�������̕�����JIT���ɗ��炴��Ȃ���
Python�̎|���͌�҂��������߂邩��R���p�C�����撣��Ηǂ������̒P���Șb�ł͖����C������
C++�ł����s�������ȏ����������R�[�h�͂���Ȃ�ɒx����
perl�݂����Ɏ��R�ɏ����������Ă�?
>>54 ����Ȍ��ꂪ���ɂ����
�����Ă���ėL��
���ʂ͌݊����̖ʂ��|���ċƖ��Ŏg���͕̂s�������邯�Ǖ��y���Ă����Ɗ�������
c3dcoord = (0,0,0)
x,y,z = c3dcoord
x += 1
y += 1
z += 1
print(c3dcoord)
=>(1,1,1)
�Ƃ�������ł����ǁA�A���p�b�N�����ϐ�
x,y,z = c3dcoord
���ĎQ�Ƃɂ��邱�Ƃ��Ăł��Ȃ���ł��傤���H
�����܂���B
c3dcoord = [0,0,0]
�ł����B�^�v���ɂ����炻���ύX�ł��Ȃ��ł��B
p = (3,4)
x,y = p
x+=1
p=(x,y)
print(p)
=>(4,4)
���ȏ���Python ���g���Ɏ������o�܂��ĕ�����H
����Python ������ďm�̎q���Ɍ����������ǁA
�ςȗ��R��Python �Ɍ��܂����猙�����
�V�������j���ȏ��������a��Ruby�����Ƃ��A����Ȏ��ł�����̂��낤��...
���s���Ă�A���@���V���v���œǂ݂₷���A���C�u�������L�x
����ȂƂ�����
��w��CS����Ƃ�����Python�ȊO�ł�Java, C�������̂��H
>>59 microPython�Ƃ��q������������ŗV�Ԃ̂ɂ��傤�ǂ����̂����邩���
>>62 10�N�O�����lj���Pascal������
>>59 ���ȏ��̃}�[�P�e�B���O�I�ȗ��R�ƌ��l�^�ɂȂ�u�`�⋳�ȏ��{���L�x�ō��̂��y������ł���
���������v���O���~���O�ɓ��傷��ۂ̗L�͂ȑI�����̕M���ƌ������x�Ȃ炢�����낤����Python����Ƃ܂Ō������Ⴄ�̂͌����߂�
���ɋ���҂��u�Z�Z����v�Ƃ��������v�l�̕Ȃ��q���ɐA���t����̂͗ǂ��Ȃ���
�q���ɂ͒f��I�ȕ���������₷����
�܂݂���������Ƃ����ۓI�ȗ����͓����
�ŁA�f�肵��Python �g�킹������
�����ł͕ςȐ����Ƃ��n�j�g����
Python�Ɍ��߂܂����B�������猙�����A
������f�肵�ċ�����O�ɗ��R��m�肽���Ȃ�����
Python ��Java ��������Ƃ����ċ������
�ǂ��������r���[�Ɋo���Ă��܂���
������ЂƂ����f��I�ɋ��������������
�������̈ӌ��ʼn����t�����ɂ݂�Ȃ�
�ӌ����ĎQ�l�ɂ��Ă�ł���H
Google Collaborates �Ł@pyinstaller �g����exe �t�@�C���쐬�����ʒm�o�Ă���ǁA�̐S�̊�������exe �t�@�C����google drive �̉����ɂ���������܂���
��ƃt�H���_�ɂ��锤�Ȃ̂�
���������āFGoogle Colaboratory
>>68 �q���̔N��⓪�̗ǂ���v���O���~���O���w�т����ړI�ɂ����
�ǂ��������ꂪ�������͕ς���Ă������
���������ď���ɑI���������肷��̂̓_������
���ꂼ��̏ɂ������I����������̒��Ŏ����̍l�����Ԃ̂������߂Ɨ��R�����킹�ē`�����ق���������
���ʎ����ړI����Ȃ�DNCL�͈̔͂����Ȃ̂Ŗ��ߌ^�ŏ����镁�ʂ̌���Ȃ��{�I�ɂǂ�ł�����
�����Č����C���f�b�N�X���[���x�[�X����Ȃ�����͂��s��
�o�b�N�G���h�G���W�j�A : 80���~
Ruby : 90
Python, Go : 85
���K�V�[
Java : 80
�������APython�̓E�F�u�J���ł͂Ȃ��AAI�E�@�B�w�K�B
Java�͋����̒������\��������̂ŁA
�����[�g���[�N�E���ƂȂǁA���_���ȃo�b�N�G���h��Ruby
��ԏ��߂Ɋo���錾��Ȃ�ċɒ[�ɓ�����������p�I�������肷�錾��łȂ���Ȃ�ł��������낤
��̌���ɍS���Ă�z�͌��ǃ��m�ɂȂ�Ȃ���B
Ruby�͊��ɏI����Ă�
���ꂩ��w�Ԃ̂͋��̍���
�G�N�Z����VBA�͗��z�I
�Z������������ԂɌ����ĂčD���ȂƂ��ɐ�������ĉ��Z������
�S�Ẵv���O�������ꂪ�Z������Ă�Ⴂ���̂ɂ�
�ϐ������l���Z�����ɋL�q
�v���O�����̓A���S���Y�������L�q���邾�����Ă�
���z����D���Ɏg���Ɨǂ��̂łȂ��́B
�Z�����v�Z�����v���O�����ɋL�q���Ȃ��Ă���
>>79 ���Ⴀ�A���w���ƍ��Z���̏��̋��ȏ�
>>62 1�N�����{�̏�����CS/IT���e���V�Ȃ�Python��Lisp/Scheme���쒀������ȁA���l�v�Z�ł�Fortran��Matlab(Octave),Python+scipy,R���O��
����̐i�U���̗����n�V���o�X�����Fortran�ꋭ������
Fortran�Ƃ����Ă�����2008���������ʂ�����A���C�u���������̑f��numpy���z�삪�Z�������ċ��́A�f�ŏ\���Ȃ̂Ŋ��\�z���y
�ŋ�pip�������o���Ȃ��Ȃ�����s����Ȃ̂����������A��͂�ŋ��G�R�V�X�e��������Python�����S�e���ɂȂ�͎̂��Ԃ̖�肾�Ǝv����
90�N����(33�N�O)������numpy��fortran�̑Ή��\�A���S�Ɉ�v
https://www.fortran90.org/src/rosetta.html ��������matlab(octave)/Fortran������Python�ł�fortran���ȃR�[�h��������悤�ɂ���̂�scipy/numpy�̖ړI�����S�͂�����A�ǂ����������Ă�l�Ȃ�݂��Ɉڍs����̂͗e�ՂȂ�Ȃ�����
��������ׂ����Ȃ琔��
numpy�̊j��Fortran�R�[�h���R�}���h�ꔭ��import�ł���Python���C�u�����ɃR���p�C������f2py���W���[��������APython�Ŗ{�i�I�ɐ��l�v�Z��z��v���O���~���O���Ȃ�Fortran�������w�Ԃׂ��Ǝv��
���݂܂���A�������Ăŋ����Ăق����ł��B
CSV�t�@�C���ɋ@�������Ă��܂��B�i�ȉ��Q�Ɓj
����CSV�t�@�C����ǂݍ���ŁA�@����N���X�ɒl�����X�g�Ɋi�[���Ă����������������Ǝv���Ă��܂��B
���X�g�Ɋi�[���̂͂ł��Ă���̂ł����A�N���X�I�u�W�F�N�g�̒l���o�͂���ƁA���L�̂悤�ɂȂ���None�ƕ\������镔��������܂��B
1
router
192.168.1.1
admin
None
2
switch
192.168.1.2
admin
None
�\�[�X�R�[�h
https://pastebin.com/1bkPJdVY CSV�t�@�C���͈ȉ��̂悤�ȍ\���ɂȂ��Ă��܂��B
1�s�ڂ̓w�b�_�[�ł��B
id,device,ipaddress,password
1, router, 192.168.1.1, admin
2, switch1, 192.168.1.2, admin
3, swtich2, 192.168.1.3, admin
4 ,accesspoint, 192.168.1.1, admin
print_device_list()���\�b�h�ŁA���M��id,device,ipaddress,password��4��ނ�\�����Ă��邾���Ȃ̂ł���
����5�ڂ�None�Ƃ����l���\�������̂ł��傤���B
�������������B�B�B
>>86 �Ō�̍s���ԈႢ
device_info[num].print_device_list() �̌��ʂ� print ���Ă��܂��� None ���\������Ă�
>>89 �Ȃ�قǁc
�m���ɂȂ�̂��߂Ƀ��\�b�h�Ăяo�������Ă����Ō�̃v�����g�ł��ˁc��
���肪�Ƃ��������܂��I
�X�N���C�s���O����v���O������������ǃ����|�b�v�̃T�[�o�[�ɃA�b�v���[�h���ĉ^�p���悤�Ƃ��Ă邯�Ǐ�肭�ł��Ȃ��B
�݂�ȃ��[�J���ł���Ă�̂��ȁH
�펞�p�\�R���I���Ȃ炻��ł�������
���̃��x���̂���X�N���C�s���O����Ȃ�
User-Agent �͐^�ʖڂɕ`���������ǂ�
cookie �Ή��͕K�{
���Ƃ͑ߕ߂����悤�ɓK�x�� wait
�Q�[���̃L�����N�^�[���N���X������Ƃ���
class Player:
�@def __init__(self, hp, mp, defense, speed):
�@�@self.hp = hp
�@�@self.mp = mp
�@�@self.defense = defense
�@�@self.speed = speed
�@def attack(self, target):
�@�@# �U������
�@�@pass
����Ȋ����ł��Ǝv������
�Ⴆ��attack�̈����̕�������
�i�P�j����̃L�����N�^�[�I�u�W�F�N�g������
�i�Q�j�L�����N�^�[��HP�ȂǁA�g���p�����[�^�[���������
�̂��ǂ������ǂ��̂��낤
�i�P�j�̏ꍇ����
#�U�������@�̕�����target.counter(self)�Ƃ��ł��ĕ֗�����������
�p�b�g���A�����ʼn�����Ă邩�킩��ɂ������H
�i�Q�j�̏ꍇ����
attack�̕Ԃ�l���A�U��������HP��Ԃ��Ƃ��ɂ����
player2.hp = player1.attack(player2.hp)
�݂����ɏ璷���ł�
�i�P�j�̕����A�����炭���̃��\�b�h�lj������Ƃ��Ɋ�{�͈���target�̈�ŏC�����₷����
�ł��A�����ƃI�u�W�F�N�g������Player�N���X�ȊO�̐퓬�V�X�e���N���X�Ƃ�����
player2.hp = player1.attack(player2.hp)�̕��������₷���Ȃ邵�A����̓I�ȃ��\�b�h���ɂ������
�ǂ��܂ŕ������Đv���邩������ȁE�E
���Ɓi�P�j�ł���Ă��܂��ƁA���Ƃ�target�̎d�l���ς��������
target�����p�������\�b�h�S���`�F�b�N���Ȃ��Ƃ����Ȃ��悤��
>>94 > User-Agent �͐^�ʖڂɕ`���������ǂ�
> cookie �Ή��͕K�{
> ���Ƃ͑ߕ߂����悤�ɓK�x�� wait
���肪�Ƃ��������܂��I
>>95 ������������G�������������N���X�ɂ��āA�o�g���}�l�[�W���[�N���X�Ɉ���1�ƈ���2�œn���Đ퓬�����邩��
>>97 ���̃}�l�[�W���̒��̘b���Ⴄ�́H
>>95 ���̂悤�ȏꍇ�A�����ɉ���n�����̓v���O�����̐v������ɂ���ĈقȂ�܂��B��ʓI�ɂ́A�U���Ώۂ̃L�����N�^�[�I�u�W�F�N�g�������ɓn�����Ƃ��D�܂����ł��傤�B
����́A�U�������ɕK�v�ȏ�L�����N�^�[�I�u�W�F�N�g�Ɋ܂܂�Ă��邽�߂ł��B���Ƃ��A�U���͂�h��́A�f�����Ȃǂ͍U�����Ɩh�䑤�̗����ɕK�v�ȏ��ł��B�܂��A�U���ɂ���ă_���[�W����������ꍇ�A�L�����N�^�[�I�u�W�F�N�g�Ɍ��݂̗̑͒l���܂܂�Ă��邽�߁A�U���Ώۂ̗̑͂�ʓr�n���K�v���Ȃ��Ȃ�܂��B
�������A�����ɃL�����N�^�[�I�u�W�F�N�g��n���ꍇ�ł��A�U�����̃v���C���[�N���X�̃��\�b�h���ŁA�U���Ώۂ̃L�����N�^�[�̃I�u�W�F�N�g�����̏�ԂڕύX���邱�Ƃ͔�����ׂ��ł��B�U�������́A�U�����Ɩh�䑤�̃L�����N�^�[�̗����̃I�u�W�F�N�g�̏�Ԃ�K�ɕύX����K�v������܂��B
���̂悤�Ȑv���s���ꍇ�A�퓬�V�X�e���N���X�ȂǁA�ʂ̃N���X�����邱�Ƃ��ł��܂��B�U���Ώۂ̃L�����N�^�[�̃I�u�W�F�N�g�ɑ��āA�U�����������s���邽�߂̃��\�b�h���`���A�퓬�V�X�e���N���X����Ăяo�����Ƃ��ł��܂��B�������邱�ƂŁA�U�������Ɋ֘A��������܂Ƃ߂Ĉ������Ƃ��ł��A�v���O�����̕ێ琫��g���������߂邱�Ƃ��ł��܂��B
@AIBoom_net ���{��t���Ǝ�����GPT-4�����i
https://doi.org/10.48550/arXiv.2303.18027 ���V���g����E�D�y�S�����ǃN���j�b�N�E���k��E�C�G�[����w�̌����҃O���[�v�ɂ��B �ߋ�5�N�Ԃɂ킽�鎎���ŕ����̑�K�͌��ꃂ�f�����e�X�g������GPT-4��5�N�ԑS�Ăɍ��i�����Ƃ̂��ƁB���{��ɂ����Ă�LLM�̉\���������B

�v���O�����S���̏��S�҂�����
�ŐV��Python 3.11����Wiki�ɏ����Ă��邯��
3.9�̖{�ŕ�����̂͂�߂��ق����ǂ��H
3.9����������ǐV�����̔����ׂ�����
���Ȃ݂�Vscode�ŃC���X�g�[���ł���}�C�N���\�t�g�̌��݂̃o�[�W������3.10.10
�܂��唼�̐l��3.9�ȉ��̋@�\�ł����R�[�f�B���O���ĂȂ�����w�K��͖��Ȃ���
�����͍ŐV�ɂ��Ƃ��ĕ֗���3.10��3.11�̋@�\���������������Ă�������
>>102 ��{�I�ɂ͑��v�����I
������Ȃ�������R�R�ŕ����Ă����Γ������ (�K������ĂȂ����)
����Ȑe�ȃX�����߂Ă�
���肪��
�ق�Ƃ��肪�����ł���ˁB
���ӂ��Ă܂�
�i���ʂ�3.9�̊��Ŋw�K���čŏI�I�ɍŐV�g����BPython�̓��发�Ȃ牼�z���̍������炢�̂��Ă�j
�ǂ��X�N���C�s���O�̓T�C�g���ړ��͒��ڃ����N�w����N���b�N�������ق��������ł����H
������Dataframe�^���ЂƂ̃��X�g�^�ɂ܂Ƃ߂��Ƃ��A
���̕ϐ�(���X�g)���o�́E�t�@�C���ۑ�������@�A
�ۑ������t�@�C�����Ăѓǂݍ���Ō��̃��X�g�ϐ������o�����@�A
�������Ă��������Ȃ��ł��傤��?
to_parquet���g���邩�Ǝv������A���X�g�ɂ͎g���Ȃ��悤�ŁA�����Ă���܂�
python�ɂ�matlab��mat�t�@�C���̂悤�Ȃ��̂͑��݂��Ȃ��̂ł���?
>>112 ���X�g�̂܂܂͍s���Ȃ����璆�g���Ȃ��� to_{�C�ӂ̌`��} ����
�ǂݍ��ގ�������
>>112 ���X�g��pickle�t�@�C���ɕۑ�������@���邯�ǂ���g���Ȃ��ł��傤��
>>112 DataFrame�̃��\�b�h�ŃV���A���C�Y�������Ȃ烊�X�g�̑���Ƀl�X�g����DataFrame�ɂ���Ή\
���X�g���g�������Ȃ�pickle.dump/load
�ł�DataFrame���ƂɌʂɃV���A���C�Y�����ق��������₷���Ă����Ǝv��
int��None��Ԃ�func()�̌^�q���g�͂ǂ������́B
None��Ԃ��Ȃ������͏��Ȃ��Ǝv�����A����Ȍ^�q���g�Ⴊ�Ȃ��BNone���ȗ���int�̂�?
def func() -> int:
>>116 Optional[int]
Python3.10�ȍ~�Ȃ� int | None
�^�q���g���ăG���[�`�F�b�N�����Ă����悤�ɂȂ���͂������
>>117,118
����܂Ƃ��B����URL����H������� peps.python.org/pep-0484/ �ɗႠ�����B
def lookup(self, name: str) -> Optional[Node]:
>>119 �_�b�N�^�C�v�͎̂ĂȂ���������ŋ����͗��Ȃ�
TypeScript�݂����ɂȂ�\���͂���Adataclass�Ɍ^�w�肪�f�t�H���g�őg�ݍ��܂ꂽ���̃X�e�b�v�Ƃ��Ċ�{�I�ȃo���f�[�g�����C�u��������C���X�p�C�A����ē��関���͂��邩����
��{�I�ɂ�mypy, pyright, pydantic������őΉ�
ABC���W���[���Œ��ۃN���X����郁���b�g���S�R�s���Ƃ��Ȃ��E�E
https://magazine.techacademy.jp/magazine/19310 �p�����Ďq�̃N���X��sayHello�㏑�����������������Ȃ��́H
https://qiita.com/Akatsuki_py/items/3e35ba326ff254a6790d �����attack�㏑�����������������Ȃ��́H
���@���ʂ̕ϐ���\�b�h�����������Ă��邱�Ƃ������̂ŁA��Ԃ��Ȃ���
�H
�p�����邾���Ȃ̂Ɏ�Ԃ��Ă���H
AI�ɕ����Ă݂�
�悤��
�� ���ۃ��\�b�h���`���邱�ƂŁA�T�u�N���X�Ŏ�������K�v�����邱�Ƃ��I�ɂ��邱�Ƃ��ł��܂��B
�� ���ۃN���X���p�������T�u�N���X�́A���ۃ��\�b�h���������Ȃ�����C���X�^���X���ł��Ȃ����߁A�N���X�̎g���������m�ɂȂ�܂��B
�� ��O�������邱�ƂŁA���ۃ��\�b�h����������Ă��Ȃ����Ƃ��I�ɂ��邱�Ƃ��ł��܂��B
���Ă��Ƃ炵��
�悤�͗Ⴆ�A�T�u�N���X�𑼂̊J���҂ɓ����Ă����Ƃ��A�I�[�o�[���C�h���ׂ����\�b�h���G���[�ɂ���Ė����ł���
���Ă��ƁE�E�H
>>121 �Ȃ�ق�
���̂Ƃ��뉽�����烉�C�u�����ɕt�����Ă���o���f�[�V�����@�\�Ƃ��g���Ă邯��
���̃��C�u�����g���ĂȂ��Ƃ��͕ʂ̕��@�ŁA�݂����ɂ��Ă邩�瑵�������Ȃ��ƑO����v���Ă��E�E
�E�e�N���XHuman�������J����A
�E����Human���p������q�N���X�i���N���X�A�L�N���X�j�������J����B�AC
�E���A�L���C���X�^���X�����ċ@�\����������J����D
�悭�悭�l����ƁA�������ɊJ����B�AC�͎������Y�ꂪ�����Ȃ��Ă�����������Ȃ�
�ł��e�N���X��abc���W���[���Œ��ۉ����ꂽ���\�b�h�ɕύX���������ꍇ
�J����D��sayHello���s������A�q�N���X�ŏ㏑�����ꂽsayHello�����s�����̂ł́E�E�H
��������ŏ�����㏑���O��ŏ������ق����A
�Ǝv���ł��Ȃ��̂ł���
>>124 �Ȃ�̓��发�݂Ă�̂�������p���Ȃ��Python�W�Ȃ��ɔ��̗��ꂾ����g��Ȃ��Ă�����
Human���p������L�Ȃ�ėႦ�Ƃ��Ă��_�O
���C�u������t���[�����[�N�Ȃǂ̒��ŗL�p�ȃP�[�X�͑������ǎg�����̃��[�U�[������o���P�[�X�͂قƂ�ǂȂ��A���w�҂Ȃ�Ȃ�����
���W�������߂��Ăق���
���ɂ��̓������� �Â��q��Python�Ə����ꂽ���ȏ��������ċA���Ă���
�Â��q�͐��w�Ɏ��Ԃ������肷���Ă�̂ŁA�����Python������ċ����Ă�肽��
�����͂��[���ƐH�킸������Python���瓦���Ă����A�����@��Ȃ̂ŁA�������x�����炢�Ɏg����悤�ɂȂ肽��
�Ȃ��A�������C++���������Ɓy�����z�g���Ȃ�
�����C����������
���ƁA���W�Ƃ������Ă����߂Č������������
�I�����C���̊w�K�T�C�g�����݂��邩�炻���ł�������
>>126
Human�͊ԈႦ�܂����AAnimal�ł���
���p���Ȃ��Python�W�Ȃ��ɔ��̗���
�����C�u������t���[�����[�N�Ȃǂ̒��ŗL�p�ȃP�[�X�͑���
����͂ǂ��������Ƃł��傤��
������Ϗ���R���|�W�V�����̘b�ł����
�Ȃ�ׂ��Ϗ��g����Ƃ���͈Ϗ��ŁA�p���Ǝg����������A�Ƃ����b�ł͂Ȃ�
����
�Ƃ������Ƃ́A�ǂ̂悤�ȏꍇ�ɂ��p�����g�킸�ɋL�q����Ƃ����Ӗ��ł��傤���H
Animal�̗�Ō�����
class Dog:
�@def __init__(self):
�@�@self.animal = Animal()
dog1 = Dog()
dog1.animal.say()
�݂����ȁH �p���̃f�����b�g����
�Ⴆ��Bird�N���X��������Ƃ���
Animal�N���X��fly���\�b�h��肪��
�܂茢�ƒ��Ƃ̊ԂŁA���L���\�b�h�ł͂Ȃ�fly���\�b�h���`���������
�݂����Ȗ�肩�ȁA�Ƒz������̂ł���
���������ꍇ�̃f�U�C���p�^�[�����Ă���̂ł��傤��
run���\�b�h��fly���\�b�h���܂Ƃ߂�mixin�p�����āA��Ԍn��Animal�N���X�����ЂƂ��Ƃ�
�ł����ꂾ�ƌ��ǂ͌p�������Ⴂ�܂����
�{���I�ɓ����肾��
�����̒��ł����A��������A�����Ȃǂ���ׂ邯��
���ł��_�`���E�Ƃ���ׂȂ���
�J�C�R����ׂȂ�
�y�����g���Ɣ�r�I�܂��Ƃ�����������
���܂����f�����ł��Ă�Ȃ�悭��
�����I����Ȃ��̂ɖ������K�p����̂��������Ă���
����fly�����Ĕ\�͕s���Ŏ��s�Ƃ��ł��邵
Animal�N���X��Boolean�^��flyable���ă����o�ϐ��������
fly���\�b�h���Ăяo�����Ƃ�
False�Ȃ牽�����Ȃ�(�܂��͉����G���[��Ԃ�)True�Ȃ�fly�̓��e������������Ă����̂̓_�����ȁH
����Dog�Ƃ���ׂȂ�Bird�Ƃ����~�����Ȃ��Ă�����Ǝv�������ǁc
30��Python�N�\�`�����j�͋������̔ƍߎ҂ł��I
���Ȃ��̋߂��ɂ��܂��I
����Ƒc����̌ːГ��{���o�����܂��傤�I
���ނƂ����̂͋��ʍ������肾�������̂�����A�ǂ��������������ĂȂ����̂���������̂͂���������Ȃ�
move��action�݂����Ȓ��ۓI�ȉ��z��������Ĕh�����run��fly���Ăяo���Ηǂ�����
>>135 ���̔��z�W�������object�N���X��fly���\�b�h��flyable������������������ĂȂ邩��
�p���̐^�t�̍l�����ł���
Animal�Ƃ��ĊǗ�������������flyable���������ʂɗǂ��Ǝv�����ǂ�
�Ƃ���������������w���ł��Ȃ�
>>139 ����傪�����Ĕ�ׂ铮���̂ݓ����A�݂����Ȃ̂����Ƃ���flyable�Ŕ��肷����č������ȒP����
flyable�Ƃ������������s���ɕω�������̂ł͂Ȃ��Č^�ɂ���Č��܂��Ă���̂Ȃ�
Gate.accept(target: Flyable)�Ƃ��Ă����Ύ��s���ɖ₢���킹�Ȃ��Ă��ÓI�Ƀ`�F�b�N�\
�قȂ��ނ́h��h���lj�����邽�тɃx�[�X�N���X��~able�ȃt���O��lj�����
�p�������N���X�̃R���X�g���N�^�₻����Ăяo���Ă�R�[�h�����ׂĕύX����K�v�����邩��
���ꂪ�]�܂����v�ƂȂ�͂��Ȃ�����Ă�
�˂��l�߂Ă�����animal�Ȃ�ėv��Ȃ��ĐU�镑�����C���^�[�t�F�[�X�����ł������ƂȂ�
�����Ƃ͉����Ƃ����₢��
numpy��array�œ���\�L���g�����@���Ă���܂���
���X�g����\�L��numpy�ɓn���Ă�T���v���͌�����܂������A����͂܂����X�g������Ă����numpy�ɓn���Ă邾���ł����
>>113-115 ���Ԏ����肪�Ƃ��������܂�!
pickle���悳�����ł��B
>>144 numpy�̑����̃����b�g��������ꍇ�����邩��
numpy�ɍ��킹�������ǂ���
jupyter����Ȃ��Ȃ�ǂ����݂�pyc�Ȃ��₩�炻��ȕς�����
ProcessPoolExecutor���g���ă}���`�v���Z�X�ŕ������������Ƃ��A����v���Z�X����ʃv���Z�X�̏�����m��A�܂��͒m�点��悤�Ȏ����ďo���܂����H
����Manager�ɂ��v���Z�X�ԋ��L�ϐ��Ƀv���Z�X�̏������i�[���ăt���O�Ƃ��A���̃v���Z�X�͂��̕ϐ��̒l������̒l�ɂȂ�܂�time.sleep��while�őҋ@���Ă��܂��B
�X�}�[�g�ł͂Ȃ��悤�Ɏv���̂ŁA�Ⴆ��
�ʃv���Z�X�ɑ��āu�������ĊJ���Ă�������v�ƒʒm������A
�ʃv���Z�X�̃C���X�^���X�̊������s������...
�Ƃ����������o����Ǝv�����̂ł��B�����ǂ����@�͂Ȃ��ł��傤���B
>>146 ���X�g����\�L��
> numpy�ɍ��킹
��Ƃ����̂͂ǂ������ł��傤���H
where�Ƃ�mask�ŏ���
>>148 await�ɏ��������̂���ԃX�b�L������Ǝv�����Ǐ��������̂��ʓ|�Ȃ�condvar

Python��PyGame���g���ăQ�[��������悤�ɂȂ肽���ł��B
Python�̃\�[�X�R�[�h�����炷�珑����悤�ɂȂ�ɂ́A�ǂ������炢���ł����H
dictionary�^���Ăǂ������Ƃ��Ɏg���́H
�S�R���肪���݂��킩��Ȃ�
�K�ޓK��������z���ō����ĂȂ��Ȃ�m��Ȃ��Ă�����
�z��̒T���݂͂���܂ōň��S�v�f����ׂ�K�v�����邯��
�����̃L�[�͔�r�I�Z���ԂŒT����\���ɂȂ��Ă���͂���
dict�^��dictionary�^�͈Ⴄ�����
Web�A�v����API�ŃN�G���Ƃ����X�|���X�Ԃ��Ƃ���JSON�ň��������Ƃ����Ȃ�
json.dumps/loads�ł���܂�ӎ����Ȃ��Ă悭�Ȃ�
import json
json_str = '{"a":10,"b":20,"c":true,"d":null}'
d = json.loads(json_str)
print(type(d),d)
json_str = json.dumps(d)
print(type(json_str), json_str)
#<class 'dict'> {'a': 10, 'b': 20, 'c': True, 'd': None}
#<class 'str'> {"a": 10, "b": 20, "c": true, "d": null}
���Ƃ͈����ɓW�J����Ƃ��Ƃ��H
def deco(a,b=0,*args,**kwrgs):
�@print(a,b)
�@print(args)
�@print(kwrgs)
a=1
b=2
args=[3,4,5]
kwrgs={"x":11,"y":22}
deco(a,b,*args,**kwrgs)
#1 2
#(3, 4, 5)
#{'x': 11, 'y': 22}
google�A�J�E���g�Ƃ� python ����Ȃ����ǎ����^����
���[���A�h���X���L�[�ɂ��ăo�����[�͂��̃A�J�E���g�̏��
�z����������ɃA�N�Z�X�ł��邵
�d���`�F�b�N���e��
Ruby �ł́A������Hash
require 'json'
# JSON �ł́Anil �ł͂Ȃ��Anull ���g��
json_str = '{"a":1,"b":"bb","c":true,"d":null}'
puts json_str #=> {"a":1,"b":"bb","c":true,"d":null}
p json_obj = JSON.parse( json_str )
#=> {"a"=>1, "b"=>"bb", "c"=>true, "d"=>nil} # nil �ɂȂ�
p json_obj.class #=> Hash
puts JSON.dump( json_obj )
#=> {"a":1,"b":"bb","c":true,"d":null} # null �ɂȂ�
>>158 Ruby�͌�����
#
https://ideone.com/cpA5lk require 'json'
json_obj = {:a=>1, :b=>"bb", :c=>true, :d=>nil, "b"=>"BB"}
p json_obj.class #=> Hash
json_str = JSON.dump(json_obj)
puts json_str #=> {"a":1,"b":"bb","c":true,"d":null,"b":"BB"}
puts JSON.parse(json_str) #=> {"a"=>1, "b"=>"BB", "c"=>true, "d"=>nil}
���X�AJSON �ł́A:b �݂����ȃV���{���͎g���Ȃ��BParserError�B
"b" �݂����ȕ������g���Ȃ�
require 'json'
json_str = '{:b=>"bb"}'
puts json_str #=> {:b=>"bb"}
p json_obj = JSON.parse( json_str )
#=> JSON::ParserError
���X�AJavaScript �ł��A�����v���p�e�B���㏑������邾��
const json_str = '{"b":"bb","b":"BB"}';
const json_obj = JSON.parse( json_str );
console.log( json_obj );
//=> Object { b: "BB" } 1�ɂȂ�I
���������A�J�E���g�Ǘ���LDAP�g����Ȃ��̂��H
�v���O�������x���̏����ɂȂ�ƃ�������Ńf�B�N�V���i���g����������Ȃ���
�C���f�b�N�X������ DataFrame df �� Series s ������A�S�Ă̗v�f�� float �ł���Ƃ���B
df �̊e�s�ɂ��� s �̑Ή�����s�̗v�f���傫���v�f����ł����邩�ǂ������ׂ������A�ǂ�������ǂ��H
df > s �� True/False ���i�[���ꂽ DataFrame ���Ԃ邱�Ƃ����҂��Ă������A�uautomatic reindexing �͐�������Ȃ��v�ƌ����Ă��ׂ� NaN �� DataFrame ���Ԃ��ꂽ�B
pathlib�ŃC�e���[�e�B�u���ɑ���ł���悤�ȃ��C�u������낤�Ƃ������ǂ߂�ǂ������Ēf�O
�Ⴆ��
�f�B���N�g���\��
data
��a
��b
��c
data�f�B���N�g�����w�肵�āA�q�f�B���N�g���ɑ��đ��삷��ꍇ
pathlib���g�������N���X��PathEX�Ƃ���
PathEX(data_dir_path).find_dir(pattern).delete_files_with_chars(characters)
�ipattern��a��c�f�B���N�g������������j
�݂����Ȃ��Ƃ���肽���ꍇ
�C�e���[�e�B�u���ȑ��삾��
�ua�̒���caracters���܂ރt�@�C���P���폜�Aa�̒���caracters���܂ރt�@�C���Q���폜�A�A�Ac�̒���caracters���܂ރt�@�C���P���폜�A�A�A�A�v
�݂����Ȃ̂����z������
���̑O��dir���ǂ������X���[���鑀���pattern��dir���ǂ����ʂ��Ȃ��Ƃ����Ȃ��̂�
�C�e���[�V�����ł��郁���b�g�����Ȃ��悤�ȁE�E
�Ȃ̂�find_dir�̒i�K�ŃC�e���[�V�������ċA���āApattern�����̃p�X�����X�g�Ɋi�[
���̃��X�g����file�����������i�C�e���[�V�������ċA���ā��t�@�C�������̃p�X�����X�g�Ɋi�[�j
���̃��X�g����delete_files_with_chars(characters)
�݂����ɁA�ړI�̃t�@�C����f�B���N�g���̃p�X������flatten�ɂ���
���̊m�肵�����X�g�ɑ��đ��삷������ǂ��悤�ȋC�����Ă���
���ꂪ�����t�@�C���Ƃ��ɂȂ��Ă���ƈႢ������̂��͂킩��Ȃ����ǁB
���炩��pathlib�I�u�W�F�N�g���̕��������������܂��Ă��������Ȃ̂�
��������Ȃ�.find_dir(pattern).find(pattern).ignor(pattern)�݂����ɂ�����pattern��lj����Ă�
pattern���ɍċA�͑����邯�ǃV���v���ɑ���ł���
���̂Ƃ��낱��ō����ĂȂ����G���[�������ȒP�Ȃ̂ł������ǁA���ʂ͑�����
���������������͂���āA�ŏI�I��0����max�܂ő����Ă邩�ǂ������ׂ���
exists[num] = True
�݂����Ȃ��Ƃ�����ƁA�G���[�ɂȂ�̂ŁA�ǂ�����ĉ����������
>>166 �\�[�g�����r�߂�̂͑ʖڂȂ�H
�ŏI�I�ɐ����~���������Ȃ�0����max�̐������Ă���V���b�t�����������y����
>>166
max = 3
d = {}
while True:
�@print(d)
�@i = int(input(f"{max}�܂ł̐��̐�������͂��Ă��������B"))
�@if i > 0 and i <= max:
�@�@d[i] = i
�@if len(set(list(d))) == max:
�@�@break
print("�I��")
print(d)
{}
3�܂ł̐��̐�������͂��Ă��������B0
{}
3�܂ł̐��̐�������͂��Ă��������B2
{2: 2}
3�܂ł̐��̐�������͂��Ă��������B4
{2: 2}
3�܂ł̐��̐�������͂��Ă��������B1
{2: 2, 1: 1}
3�܂ł̐��̐�������͂��Ă��������B3
�I��
{2: 2, 1: 1, 3: 3} �������Ă��������͎������W�������
�ȂL�[�����Ƃ����̂ɒ�R������
dic{1.1} = True
�Ƃ������Ɠ�����?
google colaboratory��python3.9�͂�����
d = {}
d[0.05]=True
d[1.1]=True
d[1.2]=True
d[2.0]=True
print(d)
print(len(d))
#{0.05: True, 1.1: True, 1.2: True, 2.0: True}
#4
len(d)�����ł����� >168
d = {}
d[1] = True
print(d[0.1+0.1+0.1+0.1+0.1+0.1+0.1+0.1+0.1+0.1]) # KeyError: 0.9999999999999999
����Ȃ̂͂���ς蓮���Ȃ�
�����������̂��͂킩���
���ʂɃG���[�f�����������̘b�ł�
�v�f��max+1��list���g����
��exists[num] = True
���̕ӂ̓䔛�肪�Ȃ���ᕁ�ʂɃ��X�g��append�g����if in�ŏd�����ׂ邾���ł�������
>>164 �s�����̑����DataFrame��gt�Ƃ�lt���g��
>>165 �C�e���u���ƃC�e���[�e�B�u�Ƃ������t�͂��邯�ǃC�e���[�e�B�u���Ƃ������t�͂Ȃ���
��ł����ĕςȃ��C�u�������Ȃ��Ă�Path.glob�ŃC�e���[�e�B�u�ɑ���ł���
���\�b�h�`�F�[�����������Ƃ������R������̂�������Ȃ�����
�����Python�̂����ł͂Ȃ��̂Ŏ��������ǂ܂Ȃ��悤�ȃR�[�h�ȊO�ł͔������ق�������
�ėp���������ꍇ��data_dir_path, pattern, characters�����悤�Ȋ������
���g��for���[�v
python��mxnet���C���|�[�g���悤�Ƃ���Əo�Ă���G���[�Ɋւ��鎿��ł��B
(���̎g�p���Ă�����͈ȉ��̒ʂ�ł��B
python: 3.10.8, mxnet: 1.8.0, windows: 10.0.19044.2728
CPU: intel core i7, GPU�͂���܂���B)
import mxnet �����s����ƁA
Could not find module
'C:\Users\ \AppData\Local\Programs\Python\Python310\lib\site-packages\mxnet\libmxnet.dll' (or one of its dependencies).
Try using the full path with constructor syntax.
�Ƃ����G���[���o�����܂��B
���ׂ�ƁA�ǂ���libmxnet��path�Ɋւ�����炵���̂ł����A
��̓I�ȉ������@���킩��܂���B
��̓I�ɂǂ�ȃR�[�h�����s������G���[�����邩�A�����Ă��������Ȃ��ł��傤��?
���邢��GPU���K�v�Ȃ̂ł��傤��?
>>166 ���͒l�����X�g��0����max�܂ł̐����l�Ȃ̂ł����set�ɂ��Ē������r
�}�C�i�X�l��max���������l�����݂���\��������̂ł����max+1�̒����̔z���p�ӂ��Ĕ�r
def check(input_list):
__xs = [False] * (_max + 1)
__for i in input_list:
____try:
______xs[i] = True
____except IndexError:
______return False
__return all(xs)
max��given�ł͂Ȃ��ē��͂��ꂽ���̍ő�l
>>176 gt, lt �� axis �w��Ŗ]�݂̓���ɂȂ�܂����I
���肪�Ƃ��������܂��I
>>177 ��Path.glob��
����Ă݂�Ƃ킩�邪���ꂾ�ƌ��ǁA�ړI�̃p�X���ÓI�Ɍ��肵�Ă���ꍇ�݂̂̒��������ɂ��Ȃ��Ƃ����Ȃ��̂�
PathEX�����Ӗ��͂Ȃ�
������������ꍇ�ɂ�pathlib�����Ŏ������̂�Path.glob���g������
>>166 ���X�g�̓��e��0����ő�l�܂ŘA�ԂɂȂ��Ă��邱�Ƃ��m�F�Ƃ����Ȃ�range�ŘA�ԍ���Ă���Ɣ�r�Ƃ��ǂ��ł��傤
�d���⏇�ԕs��ɂ��邽�߂�set�g����
set(input_list) == set(range(0,len(set(input_list))))
�݂�����
>>180 �ő�l���ɔc���ł��Ă�Ƃ������悭�킩��Ȃ�����
>>168�̃R�[�h�݂����ɃC���^���N�e�B�u�Ȓ������͑O��Ȃ̂��ȁH
���������Ȃ�v�f�����m��Ă邾�낤����킩��₷�����X�g��append���ă\�[�g�ŏ\�����Ǝv����
>>182 >�ړI�̃p�X���ÓI�Ɍ��肵�Ă���ꍇ�݂̂̒��������ɂ��Ȃ��Ƃ����Ȃ�
�������lj��������Ă邩�S�R������Ȃ�
>>184 �P���ȃ\�[�g���Əd������������ȒP�ł͂Ȃ�����
����ς�set����
�t�@�C�����������Ă݂�Ƃ킩�邯��
�t�@�C���������薼�O��ς����肷���
�C�e���[�^�̏�Ԃƍ���Ȃ����Ƃ�����
����Ă݂Ȃ��Ƃ킩��Ȃ�����
>>172 �����ID:r24Gen790���������������̂������ł��Ă�̂��H
�Ă������S�̓I�ɈӖ����킩���
l = ['1','2','3']
while l: l.remove(input())
>>187 �����glob�W�Ȃ��v�̖��
����v�������C�e���[�^�ł��Ȃ������炢����
�ċA�̕����łǂ݂̂��R�[�h�̗ʂ���x��Ԉȏ�ɂȂ邩��
�����b�g�������������ŏ�����flatten�ɂ���A�Ƃ����b�Ȃ��E�E
�ǂ������������ŁA�C�e���[�^�ێ����悤�Ƃ���Ɩʓ|�������߂����Č����Ă��
glob����āAglob����āA�݂����Ȃ̂Ȃ炻��Ꮡ���邵
���̒��x�̗p�r�����Ȃ��Ȃ疳�����Ă��Ȃ��Ă����Ǝv����
���Ƃ��̐l��������H�I�u�W�F�N�g�w�����p������̒E�p�A�̐l���Ǝv������
������炷�܂�
���̑O�A�����Ȃ�ł��p�����Ȃ����������́H�݂����Ȃ��ƕ�������ǂ����s������������
�����͂��ꂪ�������ԈႢ���͂킩��Ȃ��̂ŏ����ɕ�������������
�v���Ċm���ɂ��̎v�z�̕����ɑ傫���e���������
���^�����`�Ǝv���Ă��Ă��������Ȃ��Ⴂ���Ȃ��Ȃ�
����Ⴛ���Ȃ��A�Ƃ������������
�ł������肪���ʂ�������ŗD��Ă��邩�Ŕ��f��������̂ł�����
��@�͖ړI����Ȃ����炠���Ă��
�Ƃ���łȂ���os.walk�����́H
>>195 os.walk�ł���Ă������̃P�[�X��Path.glob��glob.glob�ł܂��Ȃ���悤�ɂȂ��������
���^�v���O���~���O�͍������Ɋ�^���邱�Ƃ������˂Ǝv���Ƃ�������邵
�I�u�W�F�N�g�w�����Ȃ�I�u�W�F�N�g�w���ł��K�v������ꍇ�Ɍ����Ă�������
������Ƃ����ăI�u�W�F�N�g�w����肽���Ȃ�APython�݂����Ȓ��������ꂶ��Ȃ���C++�ŃS���S���������ق����������ɗD�����������������Ęb�ɂȂ��H
������肽�����ɂ���Ď�i�ƃc�[�����ς�邾�낤����
Python�ł��Ȃ������C++���g�����ق����Ǝ�API����������Ƃ��̎��R�x������
>>192 Path.glob��m���Ă��火����ȃR�[�h�����Ȃ�����
�܂����t�@�����X��ǂ���
>PathEX(data_dir_path).find_dir(pattern).delete_files_with_chars(characters)
>�ċA�̕����łǂ݂̂��R�[�h�̗ʂ���x��Ԉȏ�ɂȂ邩��
����͏���������������
�v�����݂��̂Ă��ق�������
>���^�����`�Ǝv���Ă��Ă��������Ȃ��Ⴂ���Ȃ��Ȃ�
���^�Ƃ͑S���W�Ȃ���
�P����for���[�v�𐄏����Ă����ނ�����^�Ƃ͐^�t
>>190�̐v�̖��Ƃ����̂�
>>187�̂悤�ȏɊׂ�̂͐v�������Ƃ����Ӗ�
�ÓT�I�Ȑv�̖�肾����킩��Ȃ���O�O���ĕ�����
>>199 ����͎��삾���炠���ĕς��Ă邾���Ŏ��ۓ����ł͎���
Path("�f�B���N�g����t�@�C���̃p�X").glob(pattern).filter(����for_each)
������A�ċA������A���Ȃ������肾��
�킴�킴���݂��Ȃ��N���X���A���\�b�h���g���Ă�̂ɂȂ�����ȉ��߂����̂�������Ɠ䂷����
glob���g���Ă��Ȃ��킯�ł͂Ȃ�glob�̃C�e���[�^�ێ������܂܍Ō�̏����܂ł���͖̂ʓ|�Ȃ̂Œf�O��������
�����̕������Ⴆ�h���ڃt�@�C������iremove�Ȃǁj�h�݂����ȓ������ςȒP���ȏ����Ȃ�glob�����ł�������
�������ʂ�Ԃ�����ێ��������ꍇ��A�����r���Ńt�@�C���X�V�A�P�Ƀp�X�������̗p�r�Ƃ��ė��p�������ꍇ�Ȃnjl�I�ɂ������̂�
�����ăC�e���[�^�̉��b���Ȃ���for���[�v�B�����邽�߂ɁA�����̏ꍇ�̓N���X���قڂقڈ���Ɣ��f��������
�ǂ̓��Afor���[�v�����͈�x�ł��s���A�͂��Ȃ�������Ă����ꂪ����Ă��s�����������ł����Đv�]�X�ł͂Ȃ��ł���
���Ȃ��̑z���������{�I�ȗp�r�Ȃ�ʂ�for���[�vfor���[�vfor���[�v�ŗǂ����N���X���Ƃ��K�v�Ȃ��Ǝv���܂���
���Â炢���낤�Ȃ��Ƃ͎v�����̂́A�����Ɋւ��Ă͑S�R�����Ƃ͎v���Ă��܂���
���D���Ȃ悤��
os.walk�I�W�T���ɂȂ��Ă����H
����for���[�v�ŏ����ĊǗ�������Ȃ��Ȃ��Ă����os.path���pathlib�̊g���Ȃ��
�����Ȃ�ł�os�̂�pathlib�݂̂ŏ������肪����Ȃ�ʂɏ��������Ǝv�����ǁB
�����͂��Ƃ��Ƃ̂��ƍl����ƊǗ��ʓ|������for���[�vfor���[�v�ŊǗ��͖�������
�u���̃f�B���N�g���́����ȃt�@�C�����������������v�݂����Ȓ��V���v���Ȏg�����݂̂̑z��Ȃ炻��ł����Ǝv������
>>200 ���[��h�v�h���`���Ȃ��Ƃ́E�E�E
����PathEX(data_dir_path).find_dir(pattern).delete_files_with_chars(characters)�Ŋ撣���Ă���
���͒��߂�
IP�͏����Ă����ǃ��b�`���C���������Ƃ͂Ȃ���
�Ȃ낤
���܂��g����������Ȃ����ǁA���ʂقǒp��������
>>203 ����P���X�ڂ�������\���`����Ă܂���
�����\�b�h�`�F�[�����������Ƃ������R������̂�������Ȃ�����
�������Python�̂����ł͂Ȃ�
�Ƃ������Ȃ��̐v�v�z��
>>177 �N�����Ă���a���ł����Ȃ��ł���
�W�����C�u�����ł��̉��b��a����Ȃ��玩��ł͓O�ꂵ��for���[�v
���߂�ꂽ���ƈȊO�͏o���Ȃ�
���M�Ƃ܂ł͂����܂��ǁA�撣���Ă�������
Python�̓V���v���Ȍ��ꂾ���I���`���łȂ��B
���낢��ڂ��ނ�Ȃ��ƃV���v���Ɉ����Ȃ�����
�ߋ�̕i���ɂ͓��B���Ă��Ȃ��̂͂킩��
��������Ƃ͍l�����t���낤
�ŏ��̃R�[�h�ŕ��G�Ȃ��Ƃ��ł�����y����
python�͈Öقł����Ȃ��Ƃ����܂�̂������̂ŁA��������Ȃ炫������w�肷��
��������w�肵�Ă������蓮���Ă������ʔ����͂Ȃ�
Python�ȊO�ʼn�����������͂���܂����H
Go�����Go�̎d���ɏA���Ƃ��炭�H����
pep8��zen���炢����Ƃ���Monk�ɂȂ��
Go�����C����w�Ȃ��Ă��C���ł��܂����H
Rust�Ƃ܂������ĂȂ��H
�܁[�ǂ̍�����������C����Ă���������[�܂邯�ǂ�
���n�ŃE�F�u�n�Ȃ�ARuby on Rails 1���B
�č��N���ł��ARails, AWS Solution Architect ��13���h��
Ruby, Elixir : 9.3 ���h��
Go : 8.9
Rust : 8.7
�����̌��� : 6.5�`7
PHP : 5
Dart : 4.4
���{�ł́A�o�b�N�G���h�̋��l�{�������{�ŁA
�t�����g��0.5�{�ƁA10�{�̊J��������B
�t�����g�͋����ߏ�ŁA�ቿ�i�����ɂȂ��Ă���
�܂�~�����l�ނ́ARails, Linux, Docker, AWS ���o���鍁��t
YouTube �ŗL���ȎG�H�n�G���W�j�A�EKENTA �́A
�L�����A�p�X���ARails �� Go �݂̂ƌ����Ă�
���n�Ȃ�Python �ŁA��w�@���w�ȂƂ��AAWS �@�B�w�K�̎��i�Ȃ�
Python��Go�𗼕���邱�Ƃɂ��܂��BGo�����ނ���������܂��ˁB���݁A�l�C��
����ł��ˁB
���ǃx�[�X��C��������
C�ł������邱�Ƃ��A���ȒP�ɁA��茘�S�ɁA���ێ琫�����A���������Ă���ɉ߂��Ȃ�
��������C�ŏ������Ƃ����A�[�L�e�N�`���[���o�ꂷ��܂ŁAC�͎c�葱����
C����B�f�j�X�E���b�`�[�ł����B�����̌���ł��ˁBWindowsOS��C����ŏ������
�����ł��ˁB
go��python����PHP������ق����ǂ�
Web�A�v���ȊO�ł�PHP�ŏ����́H�������
ML��PHP��Python�g�����낤jk
perl�ō�����c�[�����ڐA���Ă邯��
if key3 not in d[key1][key2]:
�@d[key1][key2][key3] = {}
�݂����Ȃ̂���������lj��ŗv��
���������[�v�̒��Ŗ���]�����ĂċC��������
autovivification���g�킸�ɑ������������������菑���Ȃ����̂�
�Öق̏������̂悤�ȁA���������̃m���������āAPerl�͌���ꂽ��B
key�����݂��邩�ǂ����̃`�F�b�N�͂ǂ����������Ă���瓯�����Ƃ�
from collections import defaultdict
d = defaultdict(dict)
d['a']['b']['c'] = 1 # KeyError: 'b'
2�����܂łȂ�
����������ȃl�X�g���Ȃ��Ƃ����Ȃ����_�ō��{�I�ɐv�����������̂ł́H
def deepdict(): return defaultdict(deepdict)
d = deepdict()
d['a']['b']['c'] = 1
�����Ƃ��܂������邩�������
dict���������Ȃ炢�����ǁAlist�����������肷����
��o���͏����K�v�Ȃ�
�C�ӂ̊��n�������X�L�ɂ����炦��
a[1] ��list�Ȃ̂�dict�Ȃ̂������Ƃ������_�ŁApython�ł͎����͖����Ȃ��
l = []
l[1] = 1 # IndexError
perl�͂��ꂪ�o����Ƃ����̂��A���Ȃ�̔����
json�Ŏ�����f�[�^���f�R�[�h���Ă��̂܂g���Ă�Ƃ�����Ȃ���
if m := re.search(�p�^�[��1):
�@����1
elif m := re.search(�p�^�[��2):
�@����2
else
�@����3
�݂����ɏ����Ă������̂��A:= ���g��Ȃ��悤�ɕύX
m := re.search(�p�^�[��1)
if m:
�@����1
else:
�@m := re.search(�p�^�[��2)
�@if m:
�@�@����2
�@else
�@�@����3
�C��������
elif�͓W�J����Ƃ��Ƃ��Ƃ����������̂�����d���Ȃ��̂�
assignment expression���K�v�ɂȂ������R�����ꂾ����d���Ȃ���(pep572)
m = None
def search(pat):
____global m
____m = re.search(pat, str)
���������̂O�ɏ����Ƃ�
re.search�͕ʊ��ɂ������Ƃ͏�X�����Ă�
m.groups() ��Ԃ��Ă����ƗL��
�}�b�`���Ȃ�������[]��Ԃ��悤�ɂ���Aif�ɂ��̂܂ܓ�����锤
�Ȃ�Ő��K�\����肱��Ȃɕs�ւȂ낤
���v���ŕ����s�̕W�����͂����Ƃ��Astdin���g�������������ԑ����݂����ȋL�������������ǁA���͂�����g���ĂȂ�
����͎����������L���Ⴂ�����Ă�H
Python�̓I�u�W�F�N�g�w���ƃf�[�^�B���̏����ʔ����B
�n�[�h�E�F�A��db�̐v���Z�L�����e�B���F�X��ς���
�܂��őS���͂�ꂻ���ɖ���
>>241 ������H
�܂��݂��PowerShell���[�U�Ȃ́H
>>240 match�Ȃg�����炾
findall�ŗǂ�
�l�Ńv���O�������Ă�����x�̑f�l����̎���ł�
dataclass�ŃN���X�̍������o������]���̃N���X�̍������o����K�v���Ă���܂����H
dataclass�łł��Ȃ����Ƃ��C�}�C�`������Ȃ��āE�E�E
setdefault���֗��Ȃ��ƂɋC�t����
>>248 �ЂƂ̃R�[�h�ǂ܂Ȃ��Ȃ炢����Ȃ��H
@dataclass�g�킸�Ɏ��O�Ŏ������Ă��鎖�̂���������
����\�L�ɂ������邯�Ǔ����̃x�^�ȃR�[�h���m���Ă��ق���
���l�̃R�[�h�̗������i�ނ������̃R�[�h�̕����L����Ƃ͎v��
>>250 ���肪�Ƃ��������܂�
�]���̃N���X�͓ǂ߂���x�ɂ��Ă����Ď����ō��Ƃ��̓f�[�^�N���X�ɂ��悤�Ǝv���܂��B
��������������self.hoge = hoge���ė��Ă����̖ʓ|�ŁE�E�E
�����ʂ͂���܂�ς��Ȃ�����Ȃ�
repr�Ƃ������Ȃ炻�̕�����
���܂�B�p�C�\�����R�N�ƃ��N���[�g�G�[�W�F���g�Ō����Ă��܂���(��)
�{����vscode�ƌ����������A����Google�R���{�����o�����Ȃ��ł��B(��)
������vscode�Ńp�C�\�����R�N�͉������������ł����H
���ʂ����X�g�ɓ���ĕ���p�ŕԂ�����
def func(list):
# ����
list.clear()
list.extend(result)
����Ȋ����łł��邯�ǂǂ����Ă�����
����p�����������������ǁA�����������Ƃ��Ȃ�Ȃ���
>>254 ���ɂ̓��X�g��n�����Ɋi�[���������ʂ�����Ԃ��āA
���X�g�ɓ����̂͌Ăяo�����̕��ł��̂���ʓI����Ȃ�����
�߂�l�ɂ͐������ǂ�����Ԃ�����
�������������悭������Ȃ����ǐ��ۂƃ��X�g�̃^�v����Ԃ��������
:= ���g�킸��if func()�Ɏg������
�����Ȃ畁�ʂɒl���A���s�Ȃ�False��Ԃ��Ƃ�����ʖڂȂ́H
���ۂƐ������̌��ʂ�Ԃ������ꍇ�͗�O���g���̂���ʓI�Ȃ�Ȃ����Ǝv��
�łȂ����HttpResponse�̂悤�Ɍ��ʃX�e�[�^�X�ƃf�[�^���܂Ƃ߂��N���X�̃C���X�^���X�ŕԂ�
�^�v���͂��̊ȈՔ�
���ʃX�e�[�^�X���������ɃN���X��������@���Ȃ��͂Ȃ�
if foo.func(): do_something(foo.data)
if func(list)�ŕ���p�ŕԂ��Ƃ��܂�����ł͒N�����Ȃ�����f����
result = func()
if result�̐������:
�ɂ��Ƃ��Ȃ�B
l = []
result = None
def func():
____try:
________l.clear()
________l.extend(result)
________return l
____except:
________return False
#
result = None
print("����" if func() else "���s", l)
#
result = ["r1","r2"]
print("����" if func() else "���s", l)
#���s []
#���� ['r1', 'r2']
elif�Ōq���ł����Ƃǂ�ǂ�[���Ȃ���
�����A:= ���g���̂��x�X�g
�ł����I�Ɏg���Ȃ�
����p�ŕԂ��̂����P�̍�ŁA���ۂ��܂��s���Ă���
�����ǂ����Ă��o�O�̌�
�[���Ȃ�Ȃ瑁��return
���d�l�ς������Ȃ��Ȃ�replace_xxx(list)�Ƃ������Ő������邵���Ȃ���Ȃ��H
���̏�Œ��O�Ɋ���`(def)���ď����ɂ����u���b�N�{�b�N�X�ɂ͂Ȃ�Ȃ�
https://gigazine.net/news/20230508-mojo-programming-language/ ���@�]����Python�������������\�ȐV���ȃv���O���~���O����uMojo�v���J�������
���@Mojo�͂���܂ł̃v���O���~���O����ł���Python�̎g�p����
���@C������݂̐��\�����킹�����ꂾ�Ƃ���Ă��܂��B
�����R�[�h�œ����Ȃ����Python13�Ƃ��œ������Ăق���
�����R�[�h�œ����̂Ȃ�A����͌��s��python����Ă�l�B�ɂ��܂��疳�\�ƌ����Ă�̂Ɠ��������炸�[���ƌ��܂������邾�낤
�e�L�X�g��1�s�����������X�g�����ɏ������Ă��āA
��������̎��͎��̍s���ǂ�ŏ���������
���̃��[�v�ł͏����ς̍s�͔��
���ʂ�for�Ń��[�v�ɂ��āA�����̒��ŃC�e���[�^������Ɏ���Ă���Ƃ��ł���?
>>271 2�s���C�e���[�g����H
(1, 2), (3, 4), (5, 6), �c�ŏ\���Ȃ̂�
(1, 2), (2, 3), (3, 4), �c�Ƃ���K�v�����邩�͏������e����
���̎��̎��̍s���܂Ƃ߂ď�������K�v���������肷��Ȃ�C�e���[�V�������ׂ��ŏ�Ԃ��������K�v������̂ŒP����2�s���ƂƂ͂܂��Ⴄ�����ɂȂ�
>>271 �����ς̍s�͔���Ȃ�P��
it = iter(lst)
for x in it: print(x, next(it))
�����ŏI�s��next(it)�������O�ɂȂ�
����Ȃ��Ȃ�more_itertools��itertools�����p����
for�̑Ώۂ����X�g�łȂ���iter�ɂ�������̂�
for��next()���邵���ł��������̂�next()����
�����������ƃf�[�^�ɏ����Ă���̂Ɏ��ۂɂ͖����Ȃ炻��̓G���[�ł���
Ruby �Ȃ�A
input_text = <<'EOT'
����
aa
����
����
bb
����
����
EOT
prev_line = [ ] # �O�̍s
# ���s���폜���āA1�s����������
input_text.each_line( chomp: true ) do |line|
if line == "����"
prev_line.push( "����" ) # ����������ď����͂��Ȃ�
else
puts prev_line.join + line # �\��
prev_line = [ ] # ���e���폜
end
end
# �����A���g���c���Ă���Ε\������
puts prev_line.join if prev_line.length > 0
�o��
����aa
��������bb
��������
���̍s�����ő��������邩���ʂł���Ίy�����ǁA
����ǂ�Ŏn�߂đO�̂ŏI��肾�����Ɣ������鏈���͖���
���ۂɂ͂������̕�������
python�̃R�[�h������
���̂�ǂ�Ŋm��Ȃ�܂��������ǁA�Ō�܂œǂ�I���Ƃ݂Ȃ��������K�����܂Ƃ�
�Ȃ��E�E�@__pycache__�Ƃ������G���݂����ɔ����Ă������Ă������U�炩����f�B���N�g���Ȃ�̖��ɗ��̂���E�E
Twitter�̎������e���X���b�h�`���Ńc�C�[�g�������̂ł����ǂł���̂ł��傤���H
techiedelight.com/compiler/?~dictclass
����Ȋ����Ŏ��ۂɂ̓f�[�^�������Ă鎫���^�N���X�������ł���
def get(self, _id:str):
if _id in self._results:
���̎��_�ł�_id��str�^�Ȃ̂�
def __getitem__(self, key):
����ɃX�e�b�v�����u��key���˂�int��0�ɂȂ�܂�
�f�o�b�K�Ō��Ă������������킩���̂ł���
�ǂ������d�g�݂Ȃ�ł��傤���H
key �͐����^�ƃh�L�������g�ɏ�����Ă��邪�H
>>282 ����̓V�[�P���X�^�̏ꍇ���ď����Ă܂��H
dict�^�̃G�~�����[�V�������ړI�Ȃ�ł���
���Ȃ݂�in��r���Ȃ���myclass[key]�̏ꍇ�͓���͊��Ғʂ�ł�
in�Ŕ�r�������̂ɃG���[�Ȃ�̂łȂ����킩��Ȃ����Ԃł�
�L�[�͎��ۂɂ���̂�__missing__�̎����Ƃ͊W�Ȃ����Ǝv���̂ł���
���ȉ������܂���
>__contains__() ���`���Ȃ��I�u�W�F�N�g�ɑ��ẮA�����o�V�b�v�e�X�g�͂܂��A __iter__() ���g�������������݂܂�
�ł���
a, b, c = list[:3]
�Ƃ���ƁA���g������������ǖ����ƃG���[�ɂȂ�
��������None������悤�ɂ��悤�Ǝv���ƁA
a, b, c = list[:3] + [None, None, None]
�݂����ɂ��Ȃ��Ƃ����Ȃ�
�Ȃ�����₷��̂ŁA�����Ƃ�������������?
List_A
List_B
List_C
�������āACSV�ɏo�͂����1�s�ڂ�A,2�s�ڂ�B���Ă����ӂ��ɂȂ�܂��B
������c�ɕ��ׂ�1��ڂ�A,2��ڂ�B,3��ڂ�C�Əo�͂������ł��B
�p���_�X�ōs��ɕϊ����Ă���]�u�A�]�u�������̂�1�s�ڂ����X�gA',2�s�ڂ����X�gB'�݂����ɂ��ďo�͂��đΉ��͂ł����̂ł������������X�}�[�g�Ȃ����Ȃ��ł��傤���H
>>285 ���������Ȃ���
a, b, c = unpack_or_default(mylist, 3)�̂悤�Ɏ����Ŋ�������
����������ł��悯���
from more_itertools import *
a, b, c = take(3, pad_none(lst))
����Ă邱�ƈꏏ�������
����ĂȂ�����None�Ŗ��߂܂��A���Öقɂ����ɂ͂����Ȃ��āA
���炩�̕��@�ł��ꂪ����悤�ɏ����Ȃ��Ƃ����Ȃ��Ȃ�A���̂܂܂���ԑf�����������
���O��̂����ŃN��������������
a, b, c, _ = (list + [None] * 3)[:3]
print�ŕ�����Ɛ��l�����킹�ĕ\������ꍇ
format���\�b�h�g����str���Ő��l����ɕϊ�����K�v�������H
format���Ď��R�x�������ċt�ɐ����������
n=1
print(f"�Ƃ肠����{n}���Ă݂��炢����")
�Â��l�ԂȂ��
print('�Ƃ肠����{}���Ă݂��炢����'.format(n))
Format�͎g�킸��
a=1
print("a�F")
print(a)
�Ƃ�������Ⴄ�ȁB
print(f'{a=}')
���g���Ȃ����Ԃ͂ǂ̂��炢����������
a=1
print('a��', a, '�ł�')
��1�s�ɏ�����B
�����w�蓙���Ȃ��Ȃ�format���g��Ȃ��Ă��悢�B
����ł��������Ƃ����v��������������Af������̎���������Ȃɒx�������낤��
str = f'a��{a}�ł�'
print(str)
���ł���̂ŁA������ɂ��������������������
PIL�ŃJ�E���g�A�b�v����gif�摜������v���O��������肽���̂ł����Agif�摜�������܂���B
https://dpaste.com/2ZDT9KPHC ��]�ł͊J���Ə����������J�E���g�A�b�v�����gif�t�@�C���ƂȂ�͂��Ȃ̂ł����A
�ǂ�����邢�̂��킩��܂���B
���ȉ������܂����B
�ŏI�s�̃p�����[�^��
append_image
�ɂȂ��Ă܂����B�������́Aappend_images�ł����B
�X�N���C�s���O���悤��bs4�ł����Ƃ���
URL:http---.jpg�������Ă��̂܂܂��Ƌz���o����
���̂��ƂɂÂ�.net�ł���
����ǂ�\s��\n�Ȃǂł���Ă������ł���
�u�������ł�����Ƃ���print�Ō����.net�̕������s�ɂȂ��Ă܂���
�v�f�������ʁX�ɂȂ��Ă�悤�Ȋ����ŁA�A�A
���S�҉߂��Ă悭������܂���
soup = BeautifulSoup(res.text, "html.parser")
[tag.extract() for tag in soup(string='n')]
elems = soup. find_all("img", class_="�قɂ���")
for elems in elems:
elems = elems.get("data-src")
elems = elems.replace('.net','')
elems = elems.replace('jpg','jpg.net')
elems = elems.replace('png','png.net')
if elems.startswith("http") and (elems.endswith('')):
print�����������Ȃ�܂�
http jpg.net
http jpg.net
http jpg.net
���s�̂悤�ł͂Ȃ������̂łǂ̂悤�Ɍ���������
�t�@�C����1.jpg���珇�ɏ����o���ɂ͂ǂ������炢���ł����H
���S�҂̓X�N���C�s���O�͂���Ȃ�
import ffmpeg
# �o��①
stream = ffmpeg.input("test1.wav")
stream = stream.filter('afade', type='in', start_time=0, duration=5)
stream = ffmpeg.output(stream, "test1.mp3")
ffmpeg.run(stream)
# �o��②
stream = ffmpeg.input("test2.wav")
stream = stream.filter('afftdn')
stream = ffmpeg.output(stream, "test2.mp3")
ffmpeg.run(stream)
���̗l�ɂ����ꍇ�o��①�̃t�B���^�[�͏o�͂Q�ł��L���Ȃ̂ł��傤��
stream�̃I�u�W�F�N�g�����Z�b�g�ł��܂���
ffmpeg�̋����͓䂪��������Ȃ�
�R�}���h���C������ł��悭�������̂�����ɏォ��킹��������Ɣ����
stream = None�Ƃ����Ă��������̂���
stream�̃C���X�^���X�͂��ꂵ�Ă��ς���
���C�u�����̎������܂����Ȃ�Python���Ńv���Z�X������Ƃ�
fork�Amultiprocessing��
>>308������
URL���i�[�����̂�\����������\n\n�ł���
��������Ηǂ����������ł���
����ŏ�������J�E���gjpg�ɂ��āA�A�A
���̂������ƌ��t�@�C����png�Ƃ��̃t�H�[�}�b�g����jpg�ɒu�������Ă邾���ł����ϊ�����̂�������Ȃ��̂�
����DL����Ƃ��̂������x���̂�
web�ɂ͕���̔�asyncio���ǂ��Ƃ���Ă����ł���
�������I�������Ԃ̂���J�E���gjpg�ɂȂ��ł����ˁH
����asyncio�����ꂩ��Ȃ�ł����Ǐ��S�҂ɂ͓�߂����A�A�A

asyncio�g���̂͂������Ǖ��ׂɋC�������
���q����ď������������ʂȂ���
�Ƃ肠�����e�L�X�g�G�f�B�^�̔w�i�������̂���߂��
�s�\���A
�Ȃ�ł��ł��錾�ꂾ�ƕ����܂�����
�u���O�Ƃ���낤�Ǝv������
HTML�̂ق���������ł����H
JAVA�̐l�C�������ł����A
�p�C�\�����o�Ă��Ă����̌��ꂪ�쒀����ĂȂ���ł��ˁc
���݂܂���A�딚���܂���
���S�҃X���s���ł���
�h�X�g�G�t�X�L�[�̕��͂��������
�o�Ă��Ă��Ƃ������Ă邯��python���̂͊m��30�N�ȏ�O����J������Ă錾�ꂾ���ǂ�
1.5.2���O����g���Ă邩��Ȃ������������đ�
��Ђ̊���3.6�ŌŒ肳��Ă�̂ŁA�ςȉ���Z���g�ɂ�
>>326 ���l�̏����ł͊�ł����B
flask���g����logging�Ń��O���t�@�C���ɏo�͂��悤�Ƃ��Ă��܂��B
���O������ƃG�X�P�[�v�V�[�P���X�����܂������Ă��Ȃ��H�̂ł����A�ǂ�������Y��ɓǂ߂镶����̂ݏo�͂����ł��傤���B
�����Ȃ�ɒ��ׂ���t�H�[�}�b�g���w�肵�Ă��Ȃ��Ƃ����Ȃ�Ƃ�����������̂ł����A������Ǝw�肵�Ă�����ۂ��̒ʂ�̌`���ŏo�͂���Ă���̂Ŕ��f�͂���Ă���Ǝv���Ă��܂��B
�}���̐Ԃ��ӏ��iESC[31m�ȂǂƂȂ��Ă��镔���j�ł��B

���ɂ��
����windows�ŁA���̏ꍇ�͋V�����K�v
https://qiita.com/nash_4ed9/items/85ab1660262a44d47a61 ����PyAudio���������̃\�[�X���R�s�y���āAcmd�ŋN������
���u�[�g���ă}�C�N���͂���ƍċN�����ĕ\����������
recognize_google()�Ȃɂ����������̂���
>>329 chatGPT�ɕ����Ă݂���
Flask�Ń��O���t�@�C���ɏo�͂���ꍇ�A�f�t�H���g�ł̓��O���x����INFO�ɐݒ肳��Ă���A�F�t���̃��O���o�͂���邱�Ƃ�����܂��B����̓^�[�~�i���Ń��O��\������ۂɖ𗧂��̂ł���A���O�t�@�C���ł͂��܂��\������܂���B
���O�t�H�[�}�b�g���w�肷��ۂɁA�F�t�����O���ɂ���悤�ݒ肷�邱�ƂŁA�t�@�C�����Y��ɓǂ߂镶����̂ݏo�͂����悤�ɂȂ�܂��B��̓I�ɂ́A�ȉ��̂悤�Ȑݒ��lj����Ă݂Ă�������:
```python
import logging
from flask import Flask
app = Flask(__name__)
app.logger.setLevel(logging.INFO)
# ���O�t�H�[�}�b�g���w��
formatter = logging.Formatter('%(asctime)s %(levelname)s: %(message)s')
# �F�t�����O��������n���h����lj�
handler = logging.StreamHandler()
handler.setFormatter(formatter)
app.logger.addHandler(handler)
# �ȉ��̓��O�̏o�͗�
app.logger.debug('�f�o�b�O���b�Z�[�W')
app.logger.info('�C���t�H���[�V�������b�Z�[�W')
app.logger.warning('�x�����b�Z�[�W')
app.logger.error('�G���[���b�Z�[�W')
```
���̐ݒ���g�p����ƁA�F�t���̃G�X�P�[�v�V�[�P���X�����O�t�@�C���ɏo�͂��ꂸ�A�Y��ɓǂ߂镶����݂̂��o�͂����͂��ł��B
>>330 �����������Ă݂�
�ȉ��̂悤�ȃR�[�h���g���āA���u�[�g�Ɠ��͂���ƁA�ċN���ƕ\������܂��B���҂��錋�ʂ̓��u�[�g�Ƃ��̂܂ܕ\������邱�Ƃł����A�������������Ƃ���͂���܂����H
�ȉ���
��b�����ݍ����ĂȂ����Ǔ����ň�x�p��ɕϊ�����Ă邩��Ȃ낤�Ǝv��
������l������Ɗ��ݍ����Ă�̂��Ȃ���
���̃R�[�h�ɂ͂������̖�肪����܂��B
1. `import speech_recognition as sr`�̑O��`import pyaudio`��lj�����K�v������܂��B
2. `stream_callback=callback`�̍s�̑O��`callback`�����`����K�v������܂��B�R�[�h�̏㕔��`def callback(in_data, frame_count, time_info, status):`��lj����Ă��������B
3. `sprec.recognize_google(audiodata, language='ja-JP')`�̍s�̑O��`sprec`������������R�[�h���K�v�ł��B`main()`������`sprec = sr.Recognizer()`���R�����g�������Ă��������B
�����̏C�����s������A�ċN���Ɠ��͂���ƁA"�ċN��"�ƕ\�������͂��ł��B
�A���J�[�ԈႦ��
>>331��
332
333
�Ƃ����ۂɎ����Ă͂��Ȃ�
�ʗ�G�X�P�[�v�V�[�P���X����̂͏o�͐悪�Ή����Ă�Ƃ�������
Flask��Python��Windows�Ή����}�Y���ĉ�ʂɌ���������Ă邯�ǂ�
�t�@�C���o�͂���Ȃ炻���͂Ȃ��ł���
�F�t���ŕ\�������A�Ƃ����p�b�P�[�W�͂��낢�날�邯�ǁA
�G�X�P�[�v�V�[�P���X�̕������萔�ɂ��Ă邾���ŁA�����ō���������܂�
colorama.init() ��������Ƃ���ok
>>336 �{�����̂悤�ɉR�t�����
windows�Ől�H�m�\ deep learning �f�[�^��͂Ƃ���python�ŕ��������̂ł����A
wsl2�Ƃ������̂�python���C���X�g�[�������ق��������̂ł����H
�ꉞ�Â��Ĉ����z�����ǃO���t�B�b�N�{�[�hgeforce2060�����t���Ă܂��B��������ɂ͂������̂ق��������̂ł����H
�Ǝv��������windows�̕����x���Ƃ����v�����ʂ����邩��Alinux�̕��������炵��
�����ŋl�܂�悤�ł�DL�ɂ��ǂ蒅���ɂ͉��N�����邩�c
�܂��A�������������Ǝv�������ɏ�芷���ł�����Ȃ�����
>>341 343
�Ƃ肠����wsl���킷�邱�Ƃɂ��܂����B���肪�Ƃ��������܂����B
Python����Tor�v���L�V�h����IP�ς���Ă邩�m�F����R�[�h�������ƃG���[�ɂȂ���ǁA���̃X���Ŏ��₵�Ă������ł����H
�G���[���b�Z�[�W���Ă��Ή��ł���̂Ȃ�A�����ŕ����Ă����ʂ���ˁH
�O�O���ďo�Ă��邱�ƈȏ�̉ȂȂ���
�O�O��܂��������ǂ킩��Ȃ�������ŕ������Ǝv������ł��B
5�����̓V�˕��Ȃ�m���Ă邩�Ȃ����āB
tor�Ȃ玩�͂ʼn����ł���悤�ɂȂ�܂ł�����
��ɑ��l�ɖ��f�����Ă�
>>345 ���ǂ������R�[�h�ƃG���[���m��ǃI��������������Ȃ�����
imgur.com/a/WGJSCEi
�܂��Ator�ʼn����������̂��������Ɛ���������
�D�����l�Ȃ���Ă���邩����w
���̃R�[�h�ł�����Tor�ˑ�����Ȃ�SOCKS Proxy�g���Ă邾��������
Tor���������ƋN�����ĂȂ���������Ȃ��́H
�u���E�U������Proxy�ݒ�Ŏg���Ă邩�܂��m�F������������
���ꂩPython�����z�}�V���œ������Ă邩
WSL��GUI�������ƌ��d������R�[�f�B���O�����Windows���ɂȂ邶���
�������炻�̂܂�VS Code�ŋN������Ηǂ��˂��ĂȂ邩��
����WSL�v��Ȃ���
��{�I�ɉ��z�����Ď��g�̊J�����Ƃ͕ʂ̖{�Ԋ���z�肵�Ďg�����̂���Ȃ��H
���g��PC�œ��������̍���Ă������킴�킴���z���Ȃ�č��Ȃ��Ă����Ǝv������
windows�p�̃o�C�i�������̂�WSL2����N���X�R���p�C�����������y�������肷��
345�����Ǐ������݂��ł��Ȃ�...
���A�ł��Ă��I
345�����ǁAIP�̔铽���Ɋւ��Ď������Ă邾���Ȃ̂�B
�����������������ł���ȏ㉽���������Ȃ��̂�B
�͂�݂��Ă�������(��)
[�ړI]
Python��tor�̃v���L�V���g���Đڑ����AIP���ς���Ă鎖���m�F�������B
[��]
Tor�u���E�U(12.0.6)
PC��surface go 3
python���s����jupyter lab
�ڑ��̓e�U�����O
OS��Windows11
[����]
[WinError 10061] �Ώۂ̃R���s���[�^�[�ɂ���ċ��ۂ��ꂽ���߁A�ڑ��ł��܂���ł����B �ƃG���[���o�Đڑ��ł��Ȃ�
[�Q�l]
�ETor�u���E�U�P�̂�web�ɐڑ������ꍇ�͖��Ȃ��ڑ��ł��AIP���ς���Ă��B
�E�t�@�C�A�[�E�H�[�������ł��_��������
�ETor�ɐݒ肳��Ă�v���L�V��ǂ��ɂ������č����Ă�(�f�t�H��127.0.0.1��9050�炵������...�ǂ��ɐݒ肳��Ă�̂�)
�E�e�U�����O�ł������LAN�ł��������ۂ�����
[�\�[�X]
import requests
proxies = { 'http':'socks5://127.0.0.1:9050', 'https':'socks5://127.0.0.1:9050' }
res = requests.get('IP�C���t�H��URL',proxies=proxies).json()
print(res)
�A�����܂���B
���������̂ƁA�����N������Ə������݂ł��Ȃ������̂ŏ������ɂ��܂����B
������낵�����˂������܂��B
Edge�ł�Chrome�ł�����SOCKS�v���L�V��ݒ肵�Ă�
����Őڑ��悪���������蕪���ł���ł���
>>349 �������Ă邩�疾��������
>361
Edge��Chrome�ǂ���ł��ASOCKS�v���L�V��ݒ肵�Ă݂��̂ł����A�l�b�g�ڑ�����邾���Ń_���ł����B
�����Ȑl�ɕ����Ă��A�����ݒ�Ȃǂ���Tor�u���E�U�����グ�Ƃ������ŁAPython����Tor�v���L�V�h������Ă�����ł��B
�����̊��������łł��Ȃ��낤��...
>>358 tor.exe�����s���Ă�Ƃ���Tor�u���E�U�����s���Ă�Ƃ��ƂŁA�g���|�[�g�ԍ��Ⴄ���ǂ���͂����������H
�u���E�U�̏ꍇ��9050����Ȃ���9150�ŁA�ǂ��������
>>349��URL�ɓ\���Ă���\�[�X�ł�9150�g���Ă�B
tor�͋@�B�A�N�Z�X�Ŏg�p����悤�ȃ��\�[�X����Ȃ�
���f�������߂Ƃ�
�O�̈�jupyter lab��������������ǂ�����ip�ς����

copilot����Ă݂����ǁA
�y������
�R�[�h���R�����g�J�ɏ����悤�ɂȂ�w
345�ł��B
>364
���Ȃ��͓V�˂ł��B
9150�Ŏh������ʂ�܂����B
���ɂ����Ă������������X�{���ɂ��肪�Ƃ��������܂����I
�����ƕ����܂��B
>>367 �R�s���b�g���Ăǂ��łł���́H
>>369 github�Ő\�������
vscode�̃v���O�C�������
pycharm�ł��A���������
>>370 �T���N�X����Ă݂�
������L����
>>371 �L�������ǁA�������_�Ԍ����
�o�����R�[�h��gpt�ɓǂ܂���ƁA�܂��ʔ���
AI��AI���J������悤�ɂȂ�ƃV���M�������e�B�N���邼
ai�ŃG�������肽���̂ł����A�X�^���_�[�h�ȃc�[������܂���(�L�E�ցE`)
�R�����g��ϐ����܂Ŏw�肵�ď�����
���J�ɕ⊮���Ă����
���i�͌��\������������
>>352 WSL���Ƀt�@�C�����̂��̂���s/�f�o�b�O����u���āAWindows��VSCode���烊���[�g�ڑ�����B
python�Ƃ����������炭VS code �̖��Ȃ낤����
����̃X�N���v�g�����s����Ƃ��Ƀf�o�b�O�|�C���g�f�ʂ肵�Ă��܂��܂�
py�t�@�C���ɂ�class�������������
�X�N���v�g���s���ɂ͂��̃N���X�̃C���X�^���X�������
���\�b�h�ĂԂ����Ȃ�ł���
if __name__ == �e__main__�f:
�Ƀu���C�N�|�C���g�u���Ă��������炷�蔲���Ă��͂�Ӗ��킩��܂���
�ʂ̃X�N���v�g���烂�W���[���Ƃ��ăC���|�[�g���鎞�͊��҂ǂ���ɓ����܂�
�܂��A����py�t�@�C���ł̓u���C�N�|�C���g�ɖ�肠��܂���
launch.json�ł́fstopOnEntry�f : true�ɂ��Ă܂�
�Ώ��@�����Ă�������
__name__ �� '__main__' �ɂȂ�͎̂��������s�����Ƃ���������
${file}���f�o�b�O�N�����Ă邩��
__name__��main�ɂȂ�͂�����
if __ name__ == �e__ main__�f:
pass
���Ǝ��ۂ����Ŏ~�܂����
if __ name__ == �e__ main__�f:
�@h == hoge()
�Ƃ����if�Ŏ~�߂鎖����ł��Ȃ��ĂȂ����S�����s�����̂�
�Ӗ����킩���̂ł�
�ŏ�class hoge��def __init__�����������̂��Ȃ��Ďv��������
�����������ׂẴu���[�N�|�C���g���������Ȃ�
1�s���Ƃɒu���Ă�����
syntax error���o�ĂȂ����������}���`�X���b�h�ł��Ȃ�
if __ name__ == �e__ main__�f:
�ȊO�̂Ƃ���ʼn�������ĂȂ��H
�����ҏW���Ă�̂ƈႤ�t�@�C�������s����Ă�\���������
>>382 from import��15�s���炢
�܂肽���ނƑS���B���̂�class�ȊO�Ɏ��s���Ă�R�[�h�͖���
�����̏��������W���[���ȊO����
tqdm���O�����C�u������
���ꂪ�������������NJm�M�͂Ȃ�
>>383 �gprogram : �g${file}�h�Łhmodule�h�͎w�肵�Ă܂���
MS�W����Python�g�����Ɩ��Ȃ��~�܂邯�ǂǂ��������H
����Ȃ��Ŏ��s����Ă�
% /usr/bin/env /opt/homebrew/bin/python3 ~/.vscode/extensions/ms-python.python-2023.10.1/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher 53796 -- /PATH/TO/test.py
windows�A�b�v�f�[�g���Ă�����ċN���������璼��������
�~�܂�悤�ɂȂ����c
�G���[���b�Z�[�W��ChatGPT�ɃR�s�y���ċ����Ă����Ă��
�ł����炩�ȃC���f���g�G���[�������Ƃ�����ȁAchatgpt
�������傢�ł�������A�����Ȃ��Ă��������̂�
�\�����Ă邾���₩���
�܂蓖����O�ꂠ�����Ă���
�R�[�h�̈�s��s�͂��܂����߂��Ă����
�ł��S�̂�����ƂȂ�ƁA�K���ɂȂ���
���ɗ��镶�߂̉\���݂Ă邾���������
���ɗ��鎚�傪�K���̉\����]�����Ċw�K���ĕ��ϓI�������ł���A�K�ƕ]�������Ⴄ���
�����ł����Ă��A�]�����ʂɉe�����Ȃ��悤�ɏo���Ă���ۂ��̂ŁA�\�������������o�͂����d�g�݂����
�܂��Ґ����˃��x���ɂ����B���Ă��Ȃ�
����͂Ђǂ�
detail.chiebukuro.yahoo.co.jp
/qa/question_detail/q13281535528
a=100
if a == 100:
print("�P�O�O�_���_")
else:
print("����˂�")
��������n�߂�������Ŏ���ł��B
�C���f���g�̓X�y�[�X4��2�Ə����Ă���A�Y������G���[�ɂȂ�Ə����Ă��̂ł����A0.2.3.4.5�������̂ł����A�G���[�ɂȂ�Ȃ��ł��B
�ǂ��������G���[�ɂȂ�܂����H
�u���b�N���ŃC���f���g�Y���Ă�ƃG���[�ɂȂ�Ȃ��H
�Ⴆ����100�_���_�Ƃ�����˂̓C���f���g�������ĂȂ��Ƃ����Ȃ����ǃY���Ă邩��G���[�ɂȂ�͂�
if a == 100:
�@print("100�_���_")
�@�@print("�������")
else:
�@�@print("����˂�")
>>399 �C���f���g�𑵂��Ă��牽�ł��������Ă��Ƃł����H
(�����ł���Ă݂�����������Ȃ����낤���E�E�E)
strip()�őS�p�X�y�[�X���������������A
�C���f���g�Ɏg�킹�Ă���Ă������̂�
https://github.com/discord-camp/discord-autoposter �Z�����Ɩ��Ȃ��̂ł���1000�������炢�̒������Ɠr��Ă��܂�����A�ꕔ���������M����Ȃ������肷��̂ł����������ʖڂȂ�ł����ˁB
>>404 �����������̃A�v���P�[�V�������p�K��ᔽ����ˁH
����o�������ǃ{�b�g�A�J�E���g�ȊO�����������ĉ����s���̃_���������C�����邯��
>>404 �K������������� URL �\��������
discord.com/developers/docs/topics/oauth2#bot-vs-user-accounts
> Developers must abide by the terms of service, which includes refraining from automating standard user accounts (generally called "self-bots") outside of the OAuth2/bot API.
�ȉ� DeepL ��
�J���҂́AOAuth2/bot API�ȊO�̕W���I�ȃ��[�U�[�A�J�E���g�i��ʂɁu�Z���t�{�b�g�v�ƌĂ��j�����������邱�Ƃ��T����ȂǁA���p�K������炷��K�v������܂��B
>>405,406
�ƂȂ�ƃf�B�X�R���Œe���Ă�\��������܂���
BAN�����̂����Ȃ̂ō���͂�߂Ă������Ǝv���܂�
���肪�Ƃ��������܂���
����A���Ԋu�Ń��b�Z�[�W���M���邭�炢��������ȒP�ɍ���Ǝv������A�{�b�g�����������ق��������Ǝv���B
�����A�T�[�o�[�̊Ǘ��҂���Ȃ��ƃ{�b�g�Q���������Ȃ����ǁB
�܂�����discord.py�͝��ߎ��������ĊJ���ĊJ���Ă��獡�ǂ��Ȃ��Ă邩�킩��Ȃ����ǁB
>>408 �f�B�X�R�̉^�p���S�҂ŏڂ����Ȃ��̂ł����A�{�b�g�ňႤ�T�[�o�Ɏ������e�Ƃ����̂͏o���Ȃ���ł���ˁH
��肽���̂̓Q�[���̃`�[����W��10���ԂɈ�e�Ƃ��������Ȃ̂ł���
�{�b�g���Q�����Ă�T�[�o�[����Ȃ��Ɩ�������
���ƃ`�����l���Ƀ��b�Z�[�W���M�ł��錠�����K�v
>>410 �܂��������e���čr�炵����肻���Ȏ��ł������
�蓮���e�ł����܂�
���ϐ��̕������u������̂ɉ������@����܂��H
�ȉ��ł̓G���[�ł����B
aaa = "$HOME/xxx"
re.search("(\$[^/$ ]+)", f"{os.environ(\1)}", aaa)
>>412 hoge = re.sub("\$([^/$ ]+)", lambda x: os.environ[x.group(1)], aaa)
>>413 �m�F�ł��܂����B
������܂����B���肪�Ƃ��������܂��B
DISCO���Ă悭�킩��A�u���E�U�œ����Ȃ�Selenium�Ŏ����������炢����Ȃ��H
>>415 ��������������̂����p�K��ᔽ���Ęb
���[���ʂ�API�g���ςޘb����
API���낤���O���̃A�v���P�[�V�������낤���ADiscord�̗��p�K��ł́u�{�b�g�A�J�E���g�ȊO������������̂��֎~�v�Ƃ����b�B
�����I������b�����炱��ȏケ��ɂ��ċc�_���鉿�l�������Ǝv��
>>404������悭�ǂ�ŗ~����
>>419 793d-C6j3 �͎����̃T�[�o�[�Ɏ������e��������Ȃ��āA���̃��[�U�[���Ǘ����Ă�T�[�o�[�Ɏ������e�������Ƃ����b�B
�Ȃ̂� Bot ����Ă����̃T�[�o�[�̊Ǘ��҂����� Bot ���T�[�o�[�ɒlj����Ă���Ȃ����Ƃɂ͈Ӗ������B
�������b��
>>409 �����肩�珑���Ă�����ǂ����Ɠǂ�ł��烌�X���Ă�H
���� Discord �����Ɂubot API�v�Ȃ�Ă��̂͑��݂��Ȃ�����悭�h�L�������g�ǂ�ł��珑���������ǂ���
discord.com/developers/docs/intro
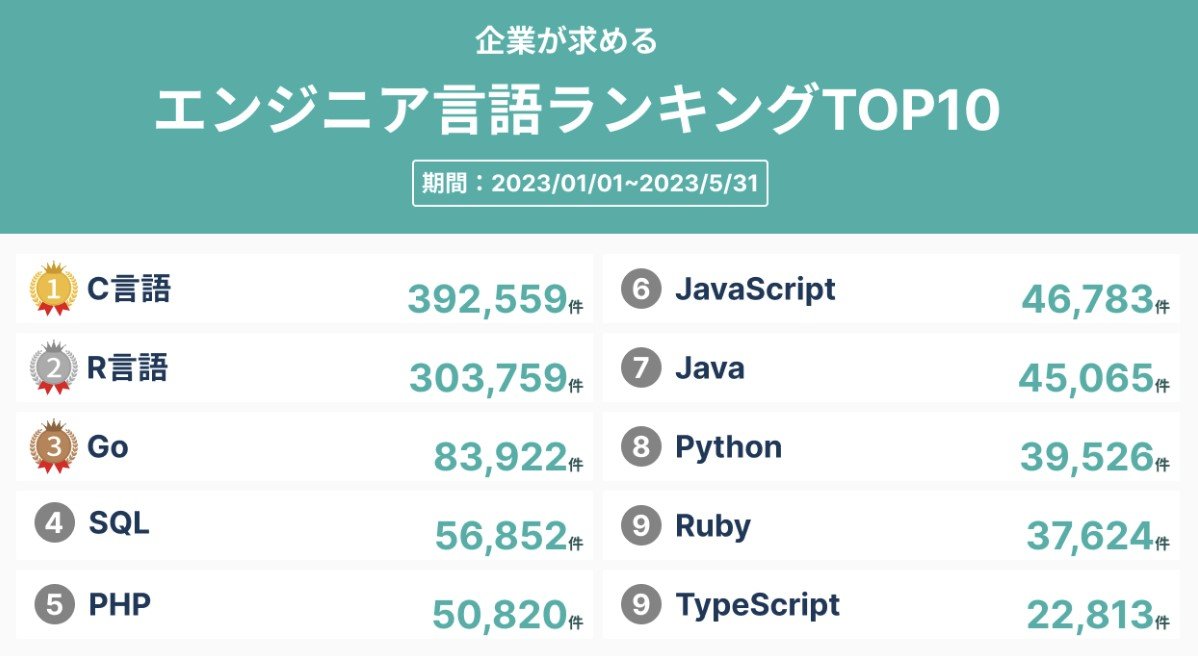
�y�v���O���~���O����z��Ƃ����߂�G���W�j�A���ꃉ���L���O�@2�ʁuR�v�A3�ʁuGo�v�@1�ʂ́H�@���DB�^�c��Ђ����\
http://2chb.net/r/scienceplus/1687350694/ �f�t�H�ŃG�N�Z���ǂݍ��߂Ȃ�R���Ȃ��āH
�����[
perl��?
Perl��D��������DeNA�����͂قƂ�ǎg���ĂȂ�����
C�͔[�����邯��R�̈�a����������
�@�B��f���鏈���n��
�֗������Ȗ����̕����D��Ȃ낤��
C�������̂͂�������������W�c�ȂȂƎv��������������Ɠ�����R�����Ԃ͓̂䂷����
���ꂩ��R�ŐV�K�ɉ����������͂��Ȃ����낤����A
�����V�X�e���̃����e�v���Ȃ낤���ǁA��������Ȃɂ�������R�ō������
aws transcribe��boto3�Ŏg���Ă邯�ǁA�����֗��Ő��x������
�ł����A���^�C����������肽��
chrome���烊�A���^�C���ʼn����������aws�ɓ����āA���A���^�C���ʼn����F���ł�����ō�������
aws�̃T�[�o�[���XLambda�ł������̂��A����Ƃ�flask�ł��̂������Ă�
�������@�Ȃ�����
��l����Javascript�ł��A�ƌ���ꂻ��������
�������ꂠ�ꂾ��
���l���Ŏ����Ăė~���������ȃX�L�����W�v�����z��
excel�Ƃ������������ǁA����͌��ꂶ��Ȃ�����Ȃ���
R���֗��Ɏg���ė~�����āA�ꉞ���ꂾ����c�������ǁA����ŊJ�������ł͂Ȃ�
R��Java���t����˂��Ă����炢�Č����Ⴄ
JavaScript����̂�matlab�͖����̂�����������
Python������Ă݂Ă��݂��݂킩��
��������C�ɍ��܂��������́AC�����n�I�߂���̂���
����C�ɂ͉��炪Python�ʼn��C�Ȃ��g���Ă��郊�X�g���Ȃ��A
�f�[�^�\���̎����ɂ͔z���\���̂�g�ݍ��킹�ă|�C���^�ŃA�N�Z�X���邱�Ƃ����߂���
����ł͖���Python�̃��X�g�@�\���ꂩ���������Ă���悤�Ȃ��̂�
�R�[�h�̑唼���f�[�^�\���A�N�Z�X�ɘQ���A�̐S�̃��W�b�N�������O�Ƀv���O���}�[�����Ղ��Ă��܂�
�܂��e��f�[�^�^�͈�U�R�[�h���������烉�C�u���������čė��p���Ă��������A
������API���g���ăR�[�h�����Ă�Ƃ��ɂ͂���API���e��̌^�����Ă���ꍇ������
���ǂ�
���X�g�^�͂Ƃ������A
�ԗւ��K�v�ɂȂ��āA�upip �ԗցv�����悢���̂��A�Ĕ������Ă��܂����Ƃ͂悭����B
���� AWS �̃e���r�R�}�[�V�������߂Ċς�
���ʂ̐l����ςĉ���CM�������
�ǂ������}�[�P�e�B���O�Ȃ���
>>435 STL�g���Ȃ�C++
C�Ȃ獡��tcl/tk�̃N���X�g���ƕ֗�
AI�v���O���}�[�ɂȂ肽����ł����A���X�̎Q�l���ǂ߂Ȃ�܂����H
���܂ł�Xbox�n�APlaystation�n�̃v���O���}�[������Ă��āA
�������C++��Python�͎g���Ă܂��B
>>442 �����肪�ł������邩��A�܂��{���łǂ�ȕ��삪����̂����ׂ�Ƃ����炾�Ǝv����
�Ă��A���т̂������������������l�ɑ��k����O�ɂ܂��͎��g�̃X�L���Z�b�g�̐������炩��
Kaggle(����Ȃ��Ă���������)�ɋ��������镪�삪����Β��킵�Ă݂Ă�
�{�͊�{�x����������������Ƃ�������œǂނ���
>>442 �f�[�^�T�C�G���X�̂���w����3�N���ғ�������H���Д�������������肾���ǁA�̌n�I�Ɋw�ԕ����Ƃ�������₷��
AI�v���O���}�[�ɂ͂Ȃ�Ȃ����낤����e���i�ł�������
>>444 ���肪�Ƃ��������܂��B
Kaggle�͂悳�����ł��ˁB
�����ŗ��p�ł���݂����ł��ˁB
>>446 ���肪�Ƃ��������܂��B
���͍�����w�i������w�j�̏��H�w�o�g�Ȃ̂ŁA
����Ȃ�Ɋ�{�͗������Ă邩�ȂƎv���A�����{�ŕ��ł�������ȁA�Ƃ��v���Ă܂����B
�A�����J�̑�w�ɍs���̂���������
���呲���֏��̗������Ŏ��₵�Ďs�̖{�ŕ�����킯�Ȃ�
�f���Ŏ��ȏЉ�Ă��{�l�ؖ��͂ł����
�ے肷�闝�R���Ȃ�����
���������@�@�ĂȂƂ��낾��
��������Ă�����������ł߂�������Ȃ�Ȃ��́H
�{���Ƃ͂悭����������
def func():
�@func.counter += 1
�݂����ɁA����.�ϐ����őO��̒l���ێ��ł��邯�ǁA
����͂ǂ���������?
static�ϐ��ł�����?
�o�J�ǂ����A
�S�~�������݂����āA�l��@���Ė�������X��
�o�J���c
�킴�킴�o�J�̏W�܂�Ƃ���Ƀ}�E���e�B���O�����ɂ���
���ȍm�芴�������悤�Ƃ��邪
���ꂷ�犐�킸�̂đ䎌��u���Ă����X���̊ԈႢ�ł�
�܂�
�S�~�������݃o�J�o��
�o�J���c
>>456 �m��ǁA(���I�u�W�F�N�g��)�I�u�W�F�N�g�ϐ�?
�t�ɐu�������̂����ǁA����A�ۏ��ꂽ����Ȃ�?
���A�ʖڂȂ�?
�O���[�o���ϐ����g��������ۂǃX�}�[�g���Ǝv������
�O�����珉��������̂��ʓ|�Ȃ�����
�����ŏ����������悤�ɂ��悤�Ƃ���Ɩʓ|�������������������邱�Ƃ��ł��Ȃ��̂�
���ʂɃ��W���[���O���[�o���E�N���X�ϐ��E�C���X�^���X�ϐ����g�����ق�������ۂǃX�}�[�g���Ǝv��
�N���[�W��������O�ɕϐ�������������
���O��ԉ����Ȃ��̂͂�������
def func(): ...
func.counter = 0
���ׂď����ΕK���������͂���邵
���낢��f�����b�g�����邩��g���̂Ă̒Z���v���O�����ȊO�ł͂�߂Ƃ����ق��������Ǝv��
�N���X�ɂ���̂��I�[�o�[�L���Ɗ�����ꍇ�Ȃ�N���[�W���g��
def make_counter(i=0):
__def inner():
____nonlocal i
____i += 1
____return i
__return inner
�f�t�H���g������mutable object���g�����������邯��
�����������Ƃ����n�b�N�Ȃ̂Ŕ������ق��������ǂ��Ǝv��
�������������̂͐���ł͂Ȃ����̂Ȃ���
���ǒN���m��Ȃ��Ƃ������Ƃ���
���I�u�W�F�N�g�Ƀv���p�e�B�lj����Ă邾��
Python�p��ł́u�������v�ƌĂ�Ă�
�����l�͂ǂ̂悤�ȂƂ�������Ă��邩�Q�l�ɂȂ�Ȃ�
�����K������������܂�Ȃ�
���Ƃ��f�[�^�x�[�X�Ń����[�V�����V�b�v�g�ނƂ���
user�����e����post�Ƃ����v�������Ƃ�
User���f����Post���f��
���̃����[�V�������f������PostUser�ɂ���̂�UserPost�ɂ���̂�
user,post�͂܂���Α��Ȃ̂ł킩��₷������
������Έ�̊W�������ꍇ�A�ǂ������ǂ����ł������������ĂȂ�悤�ȁE�E
�p�ɂɍ���͂��Ȃ����ǃR�[�h����Ō��������Ƃ���
�ǂ������悾���������H���ă�����������
userpost���ƃ��[�U�[���|�X�g�������e���̂���
posruser���ƃ|�X�g�������[�U�[�̏��
�ϐ��Ȃ�Ȃɂ��ǂ��������̂�
���\�b�h�Ȃ�Ȃɂ��ǂ�������̂��������p���ċL�q����̂��I�k�k��
�B�������������Ȃ�
create post session
get input by user from contentviewer
query results
validate from controller
�Ƃ����S��
�����������\�b�h���̖����K���Ƃ������
JOIN���łǂ̃e�[�u�������ɏ�����
�݂����Ȗ��Ǝ��Ă�Ǝv���@
>>471-472 ���O���߂Ă����T�C�g��������
������p�T�C�g�g���قǁA�ϐ������邱�Ǝ��̂͂����܂œ���Ȃ��������قǍ���Ȃ�
�|��Ƃ�ChatGPT�ł�����
�v���O���~���O�̌o�����ꂽ���Ɂu�p�C�\���`���g�f�L���v�Ɠ����Ă��������?
�������ł���Ǝv���Ă������������
����ȃt���b�Ƃ�������Ɍ������͋��߂ĂȂ�
���܂�Java�Ƃ�C++�ŃR�c�R�c�R�[�h�������Ă���ł����
�ŏ����O����@�B�w�K�̂��Ƃ�����ĂāAPython�͂����Ŋe�탉�C�u�������Ăяo���̂�
�����g���ĂȂ���ł���ˁA��{�I�ɂ�
Python���̂��̂�胉�C�u�������ǂ��g�����ɏd�_�����銴��
����Ȃł��u�p�C�\���`���g�f�L���v�ƌ����Ă݂Ă������ł���?
478�̃R�����g�Ŗ������Ƃ���
�I�}�G��������
���p����python�F�莎����2�̎��i�i��b�E�f�[�^���́j�Ǝ����o��5�N�ȏ�ʂł�����Ƃł���ł����Ǝv��
����Ȃ̂Ƃ��Ă�Pythonista�ǂ��ɂ����H
���ۃR�[�f�B���O�����Ŕ\�͑��邩�炢����ˁ[��
���i����Ă�l�͖��Ԃɏؖ����Ă��炦�邩��Č��l�����̃A�s�[���ɂ͂Ȃ�
������킩�邪
�������@�����ǂ̒��x�ł��邩�@�������������킩���̂�����
���i�������ǂ����łƂ肠��������ł���
�����Ƃ����Ƃ��܂ł͍����Ă�
�g���đʖڂ��������ɁA�ł��������i�����Ă�����A�ƍ̗p�S����������ׂɂ���
���z���0���ߏ��������ׂ���
list = [[0]*13]*20
�Ƃ������Ă��������ǂ�������̔z���id�����ׂē����ɂȂ��Ăă_�������
�Ȃ�ŕ����̃T�C�g�ŃR���ʼn������Ă�́c�����ɖ��ʂɎ��ԐH�����c
�z��߂ď���������
array[n]
�ɂ��A�N�Z�X���Ă��G���[�ɂȂ�Ȃ���
�Ƃ����l���͌Â��̂ŁA����Ȃ��Ƃ����Ȃ��Ă��ςޕ��@���l������������
��encode�w�肷��ɂ͂ǂ������炢���́H
������ɂ�������Ɛ��l�ɂ��������݂��Ă�B
csv�C���|�[�g���Ɏw�肵���炢���̂��G�N�X�|�[�g���Ȃ̂����悭�������ĂȂ��B
csv�C���|�[�g����sum�܂ł͂ł������Ǖ��������Ɛ��l��������ŕ���������������ԁB12+34=1234�݂����ȁB
�ł�������w��ɂ��Ȃ���0�����������c�B
>>493 pandas�g�������̂ł�
>>490 ���܂��ɂ���ȉ�����Ă�T�C�g�͌N�������ɎN���Ēm���̋��LDB���ɍv�����Ă���
���ƕ��ʂ̓��X�g����Ȃ��Ĕz���numpy�g��
�z��ƃ��X�g�͎����悤�Ȃ���
�Ƃ����l�����Aperl�g���Ă�����ŋ߂܂ň��������Ă�
$array[10] = 1;
�Ƃ������Ȃ菑���Ă����C
���̎���$array[0]�͋�Ȃ̂ŁA1�𑫂��Ă���������������������Ă�����
>>497 ������B$array ��
[1,0,0,0,0,0,0,0,0,0] �ɂȂ��?
[1,1,1,1,1,1,1,1,1,1] �ɂȂ��?
����Ƃ��S���ʂ̉���?
���A�P��
[0,0,0,0,0,0,0,0,0,0,1] ���B
>>497 �z��ƘA�z�z����������傭���ɂ��Ă����Ȃ̂�
BASIC�̂悤��Perl�̊ɂ��͂܂��ʂ̘b
�P�ɋ�ɂȂ�
��͐����Ƃ��ĕ]�������0�����A������Ƃ��ĕ]�������''
>>497�̈Ӗ����������
perl�̔z���Python�̃��X�g���悤�Ȃ��̂ƍl���Ă����Ă������ƁH
C�̔z��
�̈����Ă��܂��Γr���̃C���f�b�N�X�ɂ����Ȃ�A�N�Z�X�ł��ē��R�Ƃ������o
perl�̃��X�g��python�̃��X�g�͌����ڂ��������悭���Ă邯�ǁA
���{�̂Ƃ��낪�S�R�Ⴄ
���݂܂���asyncio�Ȃ�ł���
asyncio.run(main())
�Ƃ����̂�
asyncio.run(main)
�Ȃ�킩���ł����A�Ȃ�� asyncio.run(main()) �Ȃ�ł����H
���Ăяo���Ă܂���ˁH
�[���ł��闝�����o�Ă��Ȃ���ł���
����Ƃ� asyncio.run() �� main�̕Ԃ�l������Ă邾���ł��傤���H
����Ȃ�킩��܂���
DataFrame df ���������Ƃ��A���Ƃ���
df["A"] > 0
�Ƃ���Η� df["A"] �̊e�v�f�� 0 ���傫�����ǂ����������^�U�l�̗Ԃ�܂���ˁB
10 ���傫�����A0 ���傫�� 10 ��菬�������A0 ��菬�������A�Ƃ��� 3 �l�̕��ނ��������Ƃ��͂ǂ̂悤�ɂ���̂��ǂ��ł��傤���H
apply �ōs���Ə�����������͕�����̂ł����A��̗�̂悤�ȍ����Ȃ�����m�肽���ł��B
�ǂ��撣���Ă��^�U�l��2��ނȂ̂ŁA���̑g�ݍ��킹�ɂȂ邾�낤
>>508 �����ԈႦ��
�������܂ނ悤�ɒ�`���܂�
>>509 DataFrame�̏������ł͂ǂ����A�Ƃ�������ł�
(df['A']<0)*1+(0<df['A']<10)*2+(df['A']>10)*4
����
(df['A']<0)*1+((0<df['A'])*(df['A']<10))*2+(df['A']>10)*4
�͂邩�̂�BASIC�ő��x�҂����߂ɏ������g��ł��̂Ɏ��Ă��
������������Ƃ���ł悭�ˁH
(df['A']<0)+((0<df['A'])*(df['A']<10))*2
���A����ł�������
(df['A']<0)+(df['A']>10)*2
3�p�^�[�����������̂�3bit�K�v�Ƃ������_�ł�������
3�����邱�ƂɂȂ��Ă��P���Ɋe������bool�̌��ʂ��ق��������Ǝv��
1���ōς܂��������True/False�̈Ӗ���������ƕς�邯�ǃu���[�h�L���X�g����Α���
df[�eA�f].to_numpy()[..., None] < [0, 10]
>>511-512 ���肪�Ƃ��������܂�
loc�Ƀu�[�����n���̂ł��ǂ��������Ǝv���܂����B
>>514-517�����������肪�Ƃ��������܂�
exe�ɂ��ă_�u���N���b�N����ƋN�������������ʂ��o�Ă�����ǂ�����ď�����H
exe�ɂ��Ă��đ��삪Python�W������Ȃ�����Ȃ�Ƃ�������
�g���Ă�c�[���ɃR���\�[���������݂����ȃI�v�V��������͂�
pyinstaller xxx.py --noconsole
>>521>>522
���肪�Ƃ��A����Ă݂�
pypy��beautifulsoup�Ƃ��̃��C�u�����g���Ȃ��̂Ȃ�Ƃ��Ȃ��́H
������html�p�[�T�[�Ȃ�đg�߂Ȃ���
>>520 �\�[�X�� hoge.pyw �ɂ���Ə�����
>>524 pypy�������炢��������͂킩���Ă�ł���H
�f����Pure Python�ȃ��W���[����
���O�ŊO�����C�u������CFFI��cppyy�Ŏg����낵
Pylance���}�ɓ��{��ɐ�ւ���ĂċC��������
�t�@�C����f�B���N�g�����̓������𐔎��ɂ����
import����Ƃ��ɃG���[�ɂȂ�
��̂ǂ�����E�E
��@5ch���W���[����肽��
5ch.py
import 5ch # error
_5ch.py
ch5.py
�y�ړI�z_5ch.py
�Ȃ_�T�����ǎd���Ȃ���
�擪�����̎��ʎq���g����ق����}�C�i�[������
�����̎��_�Ō�₩��O�������Ȃ�
>>529 import importlib
_5ch = importlib.import_module("5ch")
>>529 �Ⴆ�Ɋ����ē˂����ށB
�Ђ�䂫��5ch��D�҂�����A���W���[�����������ȂȂ��ł���B�Ȃ̂ŁAchmate �ɕ킢 ch.py�B
5�Ԗڂ̃`�����l���Ȃ�ch5�����ʂȂ��
����������AI�ɓ����������ꂪ�V�����o�����Ȃ������H
����Ȃ̂͂��낻��AI������ɍ�邾��
������Ă��͂�@�B�ꂶ��Ȃ��H����ɐl�Ԃɂ͓lj�s�\�Ȋ���ꂩ���m���
AI����l�ōl����Ȃ猾��Ȃv��Ȃ����ǁA
������AI���b�����������悤�Ƃ���Ɖ��炩�̋��ʌ���͗v�邾�낤��
����ȃj���[�X�͂������ȁB
�I���̎n�܂�c�H �Ǝ�����Řb���͂��߂��l�H�m�\�AFacebook�������I��������
https://www.gizmodo.jp/2017/08/facebook-ai-sf.html AI�C���X�g�Ŕw�i�╞�ɕ`����Ă��̕��������ꂶ��ˁH
�����ł����l�Ԃ̌���ł��F�X���邵
�v���O���~���O���ꂾ���Ĉ����Ȃ��̂�
AI������g���n�߂��炻�ꂱ���S��㇗��ɂȂ邾�낤��
�n���s�W����݂����ȃG�X�y�����g�ɑ�����̂��ł��邩�������
����Ȃ��Ƃ��C���^�[�v���^����̒E�p�͂܂��܂���Ȃ̂���
�s���l���X����A�l�O�����ꂪ����̂��Ǝv���Ă��܂����B
>>546 �\�[�X�Ǝ��s�t�@�C�������Ǘ����������
�C���^�[�v���^��������
��Python����ChatGPT��code interpreter�ŏ\������
�ʂɃR���p�C�����悤�Ǝv���Ώo���邶���
����ɃC���^�[�v���^�[�̃����b�g�͎��s���I�Ȃ��Ƃ���ɂ��邩��
>>539 �@�B�ꂶ��Ȃ��Ē��Ԍ���ɂȂ邾��
�@�B�ꓯ�m�͕�����������
>>550 �v�Z�ɂ���Ă̓n�[�h��OS�̈Ⴂ�Œl���ς�邱�Ƃ����邯�ǂ�
���傤��Cython�����W���[�A�b�v�f�[�g�����炵������g���Ă݂���
���O��m��Ȃ��悤�����狳���Ă����悤�Ǝv��������͂�~�߂邱�Ƃɂ����B
selenium�Ńv���L�V��ʂ��Ƃ��A���[�e�[�V�����^�C�v�̃G���h�|�C���g���Ƃ��������F�_�C�A���O�˔j���Ȃ���Ȃ�Ȃ��̂��߂�ǂ�
�Ⴆ�@
http://username:password@host:port�@�݂����Ȃ̂���
--proxy-server=��chrome�h���C�o�[�̃I�v�V�����ݒ肵�Ă��F�ؖ���������
profile�㏑�����āA�݂����ȉ�����͂���݂�������
>>557 ����͎����Ŏ��ۂ���Ă݂ďo�������Ă��ƁH
�ꉞ����Ă݂悤�Ǝv�����A�ߋ���add_option�Ƃ��ł�����C�����邩������Ȃ���
��������StackOverflow�ɖ��������Ǝv���̂ł��Ԃ�ł��Ȃ������ȋC������
>��������StackOverflow�ɖ��������Ǝv���̂�
�Z�p�Ҏ��߂��ق��������悗����
��������selenium�g���̂��_���ȂƎv����
>>559 �Ȃ�ŏ��Ă�̂��܂������킩���
StackOverflow�ɂ��疳�����������A�t�ɂ������玎���ς݂���
���ĈӖ���
�ŁA����
��HTTP�w�b�_�œn����H
���Ă͎̂����Ŏ����Ăł����̂��낤��
�����������������̂Ɋ��S�X���[����Ă�
���Ȃ݂ɔF�w�b�_�쐬����add_argument������@�͒ʂ�Ȃ�����
�Ƃ��������̒��x�ʼn������Ă�Ȃ�stackoverflow�ɂ��łɂ���Ă�l������Ǝv��
���������v���L�V�T�[�r�X������x�[�V�b�N�ȉ������@��
����selenium����--headless�ł͖����ł��X�}���A�݂����Ȑ�����������
�Ă�stackoverflow�Ɍ��炸�܂������Ɠ������ᒲ�ׂ�̂��ĕ��ʂ̂��Ƃ��Ǝv���Ă����LjႤ�̂�
>>557��HTTP�w�b�_�œn����H�i���낤���j
�̂悤�ɂ܂��A�^�����āA�u���A�C�P���@�������[�I�v�݂����ȁH��
�������������т͂��邯�Ǎ���݂����Ƀ_�����������ǂ�����
�ׂɐ����Ă�킯�ł͂Ȃ����C�ɂȂ�Ȃ�
�������������^���e�B�̐l�͉�����Ă��_�������
�������ɁA�����Ŏ��������Ƃ��Ȃ����@�ŏ������郁���^���e�B�̐l�͉�������Ă����߂��낤�Ȃ�
>>557�͉\���̈����������������
�����ے肵�āA���������̍�����Q&A�T�C�g�ɍڂ��ĂȂ�����A����
�����Ԃ������
�T�������Ă�Ƃ��Ɉ�ԃn�b�L�������Ă��������̂�
����������������T����
���ǂ������ĂƂ���
�������ɂ�������ȁ[���H
�Ƃ������ǂ��납�ނ���ז��ł����Ȃ�
���ʂ͉\���������ꂽ�炻�ꂪ�����ۂ��̊m�F�������ł��Ȃ��H
�p�\�R�����̂̕s�����������či�荞��ł�����
�܂��O�O��Ƃ͌���������
�����҂ɂ́A�o����Ǝv������Ȃ��܂������Ŏ���
�Ƃ͌���Ȃ���
���肪�������Ă�����A���ꎎ���܂������ĕs�тɂȂ�\�������܂�̂�
�Ȃ����ォ��ڐ��Ŏ����ɊÂ�
���ہA�����ďo���܂����o���܂���ł������Ď��Ⴊ����̂�stackoverflow�Ȃǂ̃i���b�W�R�~���j�e�B
>>565�͍��{�I�Ɋ��Ⴂ���Ă邯��
>>555�͂P�_�������͋��߂ĂȂ���
�ǂ������Ś┃�����炤�܂���������
�Ƃ����\���������ꂽ�琶���ۂ��m�F�������ł��Ȃ��Ƃȏ�
����A����Ȃ��Ƃł��܂������Ȃ��ƒm���Ă鑤���炷��Ίm�F�Ȃǂ���킯�Ȃ�
�܂����܂��������Ŏ����A�ƂȂ邾��
A�u�킩��Ȃ���ł��@�����Ă��������v�@���@B�u������������̂ł́v�@���@A�u�킩��܂��������܂��v
����͂킩��
A�u����͏o���Ȃ����ۂ����v�@���@B�u������������̂ł́v�@���@A�u����Ȏ���Ȃ����ǁA��������łł����H�v�@���@B�u�m��ǁA�\���������ꂽ�玩���Ŏ�����v
����͂܂������������킩��Ȃ�
�����I�Ɍ�҂̂�������炲���������ʂɕs�M����������
>>555��URL�݂��Basic�F���������
�Z�p�I�ɂ͌Œ��HTTP�w�b�_���o�͂��邾���Ȃ̂��ē�
���܂������Ȃ��̂̓w�b�_�o�͂��A�ȁ[��قǂƂȂ�ƊÂ��l���Ă�
���Ȃ��悤�� site:stackoverflow.com ����ŃO�O��������
add_argument�͎d�l�łł��Ȃ�����request_interceptor��������
������ł��q�b�g���邵�Ӗ��킩���
���߂�Ȃ����A�Ԉ���Ă܂���
�����̂�ID:Ewgs5Hf50�ł�
�C�ӂ̒�����list�������ŁAlist����̗v�f���������Ȃ��Ƃ���list�̑���ɂ��̗v�f��n���Ă��ǂ����Ƃɂ������̂ł����ǂ�����ׂ��ł��傤���H
�܂�
func([hoge])
�̑����
func(hoge)
�Ə����̂����������Ƃ������Ƃł��B
C++�Ȃ�I�[�o�[���[�h���邾���ł����APython�̏ꍇ�͂ǂ̂悤�ɂ��܂����B
>>573 API�v�̗ǂ������͒u���Ƃ��Ƃ���
�������Ȃ��Ă����̈����ɈႤ�^��n���̂͋�����Ă�
type hint�̘b�Ȃ�union�g������
int | list[int]
�I�[�o�[���[�h�I�ɕʊ��ɂ������Ȃ������ς���
list����̗v�f���������Ȃ��Ƃ��ł��A��O��݂���list��n���ׂ����B
���O�Ō^�肵�ĕ���B
def func(arg):
�@if not isinstance(arg, list):
�@�@arg = [arg]
�@return arg
print(func(1)) # [1]
print(func([1,2,3])) # [1,2,3]
�ꉞ�A�I�[�o�[���[�h���ۂ����������ł���B(���ʂ͏�Ɠ���)
singledispatch �Ƃ������O�̒ʂ�A�擪�̈����ɂ��������Ȃ����ǁB
from functools import singledispatch
@singledispatch
def func(arg):
�@return [arg]
@func.register
def _(arg: list):
�@return arg
a, _, b, _, c = list
�݂����ɂ����ɁA
a, b, c = list[0, 2, 4] # ���
�݂����Ȋ����Ƀ��X�g�̈ꕔ���������o���ɂ͂ǂ������
>577
a, b, c = (list[0], list[2], list[4])
���ƕϐ�����'list'�ɂ���̂͂悹
numpy��pandas�g���Ƃ���������ƋC�̗�����������������
>>577 >>> L = [1, 2, 3, 4, 5]
>>> a, b, c = (L[n] for n in [0, 2, 4])
>>> a, b, c
(1, 3, 5)
>>577 >>> import pandas as pd
>>> L = [1, 2, 3, 4, 5]
>>> L = pd.Series(L)
>>> a, b, c = L[[0, 2, 4]]
>>> a, b, c
(1, 3, 5)
>>577 >>> import numpy as np
>>> L = [1, 2, 3, 4, 5]
>>> L = np.array(L)
>>> L
array([1, 2, 3, 4, 5])
>>> a, b, c = L[[0, 2, 4]]
>>> a, b, c
(1, 3, 5)
����̓��X�g�̃C���f�b�N�X�Ƀ��X�g������Ƃ����̃G���[�ɂȂ邩��A
python��pandas��numpy�̎d�l����荞��ł��������̂�
�܂��A
a, b, c = L[[0, 2, 4]]
�������������
a, b, c = np.array(L)[[0, 2, 4]]
������������������
�s�v�ȗv�f����������X�e�b�v��
�ʂ̕ϐ��⎫���Ƀ}�b�s���O����X�e�b�v��
����������������Ȃ����Ƃ����C������
�ǂ��l���Ă݂��番�����Ă�Ƃ����Ε������Ă�̂�
�������ӂ̗v�f���̈�v��ۏł���R�[�h��
��v���Ȃ��ꍇ���l�������R�[�h����Ȃ��ƃ�����������
��̓I�ɂǂ������p�r���������Ƃ����ƁAexcel�̃V�[�g����U2�����z��ɓǂݍ���ŁA
���̒�����K�v�ȕ������o���Ă���
�擪�̍s���C���f�b�N�X�ɂ��āA�����ɏ����ꂽ���O�ł��̂����ʂ����ǁA
���̂̒m��Ȃ�����f�[�^���\�[�X���ƁA����Ȃ��Ƃ�����
>>588 ����Ȃ�filter�̂��y����Ȃ���
>���̒�����K�v�ȕ������o���Ă���
������R�[�h�ɗ��Ƃ����߂�Ȃ炾����
filter(lambda x: x % 2 == 0, l)
��є�т���A�Ƃ����Ӗ���0, 2, 4�Ȃ����ŁA�����Ƒ�����ƁA
0, 2, 4, 7, 11, 12 �݂����Ȋ����ɂȂ�
���������p�r�Ȃ�pandas��read_csv��read_excel��skiprows��usecols���w�肵�ĕK�v�ȕ��������ǂݍ��ނ���
csv.reader����ł������悤��
usecols = [0, 2, 4]
[row[i] for i in usecols]�I�ȏ���������
���̓f�[�^�𐮌`����X�e�b�v��
���`�����f�[�^�����ƂɌv�Z���H����X�e�b�v�͕������Ă�������
>>590 >>589�̃R�[�h�͂����܂ŗ�ŁA�K�v�ȕ������o�������������ł���Ȃ���Ă����Ӗ��ł�
���������瑗���Ă���f�[�^�ŁAcsv�Ƃ�json�ő����Ă��ꂽ��y�Ȃ̂�excel�t�@�C���ł��������Ă���Ȃ��Ƃ������̂�������
���������ŏ����������͖����ɂ��Ȃ��Ƃ����Ȃ�excel�Ƃ��n��
���Ɖ��̂��݂�ȃZ��������D��
�}�C�i���o�[�Ƃ���肭�s���Ȃ��n�Y����
�}�C�i���o�[�͍�������ɈÏؔԍ��̓o�^����ʂɂ��������_�ŁA
����͐�Αʖڂ���Ǝv����
�s���ɗ��n���F���Ȃ��
���n�Ȃ�������Ƃ������ƂC�ł���Ď��s����
���܂��ɃR���r�j�Ō��t����̂��Ȃ�Ƃ�
�V�X�e���͕ʂɊԈ���ĂȂ�
�R�Â��̏������Ԉ�����q���[�}���G���[
���̊Ԉ�������Ƃ����ƁA�O�̐l�̉�ʂ̂܂��̐l�̓��͂�������
��������ƁA���������������ɏo��悤�Ȃ��̂��ȁB
>>593 ��������R�g���Ă邩���
�݊����������邽�߂�pandas�������Ă��Ƃł���
�}�C�i���o�[���v���C�}���[�L�[�ɂ����95%���炢��������b
�v����`�Ŏ��s���Ă�
�v�J��������Ƃ̖��O�͑S�����\���ė~������
���̒i�K�ł̃~�X�͂����̃o�O�ŗe�ՂɏC�����\
�d�l��v�������������Ԉ���Ă�̂ŁA�����ǂ����悤���Ȃ�
>>601 �}�C�i���o�[���v���C�}���L�[�ɂ�����_������
�N���W�b�g�J�[�h�ԍ����v���C�}���L�[�ɂ��Ȃ��̂Ɠ���
��̂ǂ������V�X�e���g�߂Γ��������̑��l�Ǝ��Ⴆ�ēo�^�ł����Ƃ����̂͋^�₾����
�܂��}�C�i���o�[�Ɍ��炸�������͐̂���x�m�ʌn
���̓~�X����Ȃ��ĕx�m�ʂ��o�O�����ĂȂ�����
�܂����i����EXCEL�����G��Ȃ����������炷���csv�����ꂾ�����
pandas�g���ɂ���ڎ��葀��ɂ��O�����͂܂��K�v
�l�Ԉ�l��l��{�C�Ŏ��ʂ��悤�Ǝv�����牖��p�^�[���̃_�C�W�F�X�g�l�ł����߂邵���Ȃ�����
���₻�ꂱ���l����ǂ�
���H�x�@��DNA�Ӓ�����ʂ����Ă��ƁH
>>612 ���T�肢���x���ƕ����Ă��邪�A���サ���̂��ȁB
>>598 �咣�P�u�O�̐l�����O�A�E�g���ĂȂ��v
>>605 �咣�Q�u���������̐l���d���v
�܂�Q�̌������P���ƌ����Ă邱�ƂɂȂ�
����Ȋ�֓I�Ȃ��Ƃ����邩�H
���{�̔��\�͉R���Ƃ�������
�l�ƃ`���p���W�[�̈�`�q��99%�������Ęb������P�O�O�������ړx�Ƃ��đe��������Ď������ǂ�
>>610 �ŋ߃v�[�`���̉e���҂��b��ɂȂ��Ă��邪
NE�����������Ă�摜������100�����̈�Ŕ���o�����F��AI�Ŕ��肵�ė~�������̂�
>>601>>604
�ǂ̃e�[�u��/�G���e�B�e�B��Ώۂɂ��Ă��邩�����ċc�_����̂����������_���B
�}�C�i���o�[�ɕR�t���ׂ�����ێ�����e�[�u���Ń}�C�i���o�[���L�[�ɂ���͉̂����������Ȃ��Ƃ͂Ȃ��B
>�}�C�i���o�[�ɕR�t���ׂ�����ێ�����e�[�u���Ń}�C�i���o�[���L�[�ɂ���͉̂����������Ȃ��Ƃ͂Ȃ��B
�}�C�i���o�[�s����@�\�̃V�X�e���ł��A�N�Z�X�L�[�������ۗL�@�ւ̃V�X�e���ł�����Ȑv������_������
�ڂ����m�肽�����DB�v�X���ɂł��ǂ���
�ڂ����͒m�肽���Ȃ������������������ł��Ȃ��͉̂����m���Ƃ���
>>618 �܂��͂ǂ��������R�Ń_���Ȃ̂����ꌾ�Ő������Ă݂āB
�X�V�ُ�Ƃ��p�t�H�[�}���X�Ƃ��Z�L�����e�B�Ƃ����낢�날��킯�����B
�}�I�Șb�肩���m����
�Ȃ��}�C�i���o�[�J�[�h�͂��܂������Ȃ��̂�
http://2chb.net/r/prog/1688658413/ �܂����������b��͐g�߂ȃv���W�F�N�g�ł��N���肤��̂ł��Ȃ��������ł͂Ȃ�
>�l�ԍ��i�}�C�i���o�[�j�͌����Ƃ��Đ��U�����ԍ����g�������Ă��������A���R�ɕύX���邱�Ƃ͂ł��܂���B
>�������A�R�������ĕs���ɗp�����邨���ꂪ����ƔF�߂���ꍇ�Ɍ���A���{�l�̐\���܂��͎s�������̐E���ɂ��ύX���邱�Ƃ��ł��܂��B
��P
�V�������R�[�h���쐬���đΉ��i�l�ԍ�����L�[�Əo����j
��Q
�l�ԍ��{�K�p���Ԃ̃e�[�u�������i�l�ԍ�����L�[�Əo���Ȃ��j
DB�v�I���Y��Ȃ̂͌�҂����ǁA�������y�ō����Ȃ̂͑O��
�e�[�u��������������������͐��\�v�I�ɂ�肽���Ȃ�
�l�ԍ����͈̂��p���ꂽ�ꍇ���ɕύX����邱�Ƃ������Ȃ����������H
���Ƃ���A������v���C�}���[�L�[�ɂ�����܂����Ǝv������
��O�Ȃ��l�Ɛ��U�Ή������B��ID�݂����Ȃ̂������āA����ŊǗ�����Ă���
�l�ԍ��͂���ƕR�t����ꂽ���̈��
>>624 ����͌l�ƃ}�C�i���o�[�������Ƌ�ʂ���b�B
�Ĕ��s������Ȃ�Â��i���o�[�ɕR�t�����ƐV�����i���o�[�ɕR�t����ʂɑ��݂��邩������Ȃ����B
�l�ԍ������鐔�l�Ŋ����ď�]���Z�Z�݂����ȌÓT�I�ȈÍ������������
�l�ԍ����Ĕ閧�ɂ�����̂Ȃ́H
�g���ؖ��Ƃ��Ďg���ӂ��ɘR�k���邶���B
�ǂ����̓X�̉���o�^������A�g���P�[�X�͍��㑽���Ȃ��Ȃ��H
�Ȃ��Ȃ�ی����Ƌ����Ȃ��Ȃ�̂�����B
�ԍ����̂łǂ������ł��Ȃ����ǂ�
�g���b�L���O�Ɏg���邩����W�͐�������Ă�
�l���͕ی삵�Ȃ����
�Ɨ��R���Ȃ��v������ł�t�V������
�̂͏Z�����d�b�ԍ������ʂɌ��J���Ă��̂�
�X�E�F�[�f���݂����ɔԍ��m��ꂽ���ĉ��������Ƃ����X�^���X�̕������낢��֗�
10�N�ȏ�Python�g���Ă������ǁA�����h�L�������g�����Ă���match���đ��݂����߂Ēm���Čy���J���`���[�V���b�N����
����C�Ƃ���switch����ˁH
Python��switch���Ȃ��A�����̏�������ɂ�if~elif���g�����Ă̂��펯�������悤�Ɏv�������������Ƃ��Ă����̂�
�܂��܂��ŋ߂ɒlj����ꂽ����m��Ȃ��Ă����������͂Ȃ�����
C��switch/case�Ƃ��Ă��g���邵�����ƕ��G�Ȃ��Ƃ��ł���
�E��Ōl�I��EUC�𐄐i���Ă��Ă�
�����ŏ����������c�[���𑼎҂ɐ��������肷�����
�̂����ɁuPython�̓V���v�����|�Ƃ��A��̂��Ƃ�����̂�
�����̏������͂ł��Ȃ��悤�ɂȂ��Ă�B
����ď��������if�����Ȃ��v�Ȃ�Ĕ\��������Ă����
�l�ɋ����闧��̎҂͏�ɕ����ĂȂ��Ƃ����Ȃ��Ȃ��Ĕ���
match���̂܂ܑ���ł�����悩�����̂�
>>634 ���Ȃ݂ɁAutf-8���EUC�𐄏����闝�R�ɂ��Ă͂ǂ��������Ă��ł���
>>635�̈Ӗ����킩��Ȃ���������
>>637�Ŕc��
�}�W���X���Ƃ��ƃG���h���[�U�[�R���s���[�e�B���O
�G���h���[�U�[���傪���͂Ńc�[�����J�������e������������炸�d�����y�ɂȂ�
>>635 euc��sjis����ɍ��ꂽ�B������R�������Ă̂��Ƃ��B
UTF-8���W���Ȃ̂��ȂȂ�
�}���`�o�C�g���Ȃ�UTF-16�̂������悭��
���E�I�ɕ��y���Ă��钆�Ő��E���̕���������Ȃ�Ɉ�����̂�UTF-8������
EUC����ԕs�v
���̃����b�g�������
>>623 ��������12�����ď��ȉ߂���
��Ώ����͊�������
>>628 ���������閧�Ȃ�u������v���Č����Ă���͂���������
���������d�g�݂ɂ͂Ȃ��Ă��Ȃ���
>>642 unicode��codepoint�̂�����
sjis�ɕϊ��s�\�ȕ����͑��݂��邪
euc�Ȃ�ϊ��o�����Ȃ�����
���ꂾ���ł�sjis�������ɕ�������
>>638 �Ƃ肠�����A
>>637 ���Ă������Autf8���y���܂����Ă�̂ɉ��ł킴�킴euc�ɂ����ł������ĕ����ꎞ�͂ǂ������Ă�́H
>>647 �ǂ݊ԈႦ�Ă��
��FEUC�iExtended Unix Code�j�𐄏�����
���FEUC�iEnd User Computing�j�𐄐i����
EUC�iEuropean Union Center�j����B
>>643 ���{�������������^�p����Ȃ牽���ɂ��Ă��͊�����
����Ȃ��Ȃ�����d�b�ԍ��݂����Ɍ����₷�ł���
���̎��͂������d���ŃO�_�O�_�ɂȂ�낤����
IP�A�h���X�̌͊��Ƃ��Ɠ������Ǝv���Ă��
�r�b�g���Ȃ��܂��ĂȂ�����ǂ��ɂł��Ȃ�
�����I�ɂ�19���܂ł����锤
web3�͍���̂͂������ǂ��Ȃ����̂��낤��
���s���������R�b�`�Ŏ��s����������̗ƂƂȂ�̂ɂ�
web 2.0�̎��_�ʼn�����m������̂ɂ܂����̂�
from import���Ăǂ��Œ�`����Ηǂ��̂��K���Ƃ�����̂ł��傤���H
from . import samples
def util():
�@pass
def main():
�@������samples.aaa�Ȃǂ��Q�Ƃ��鏈��
�Ƃ�������ꍇ��sample.aaa��util�Q�Ƃ��Ă�ꍇ�ɏz��import�G���[�ł܂����
�Ȃ̂�main���̒���from .import samples
�ɂ��邩��������utile�����邩�A���Ƃ������̂ł���
���������ꍇ�́A���Ċ��K������̂��C�ɂȂ�܂���
as hogehoge ����Ƃ�
�f�B���N�g�������� __init__.py �̕��łȂ�Ƃ�����Ƃ�
�ŏ��\���͂���Ȋ����ł�
https://pastebin.com/1VEJDXPC �v�́Asamples��hoge�͂��݂��̋@�\���g�����������A�����ł�
���ɁAaaa�ł���samples.util�g��Ȃ��Ȃ�aaa�̒���import����Ώz�͉���ł��܂��B
�܂��A
hoge.util�̒��ł�samples���Q�Ƃ��Ȃ��A
�̂͒N�������Ă��_���I�Ɋm�肵�Ă��邩��
hoge.main�̒���samples��import����
�Ƃ��������������肫�܂�
�������Ahoge.main�ȊO��main1,2�Ƒ������ꍇ�ɖ��x���̒��ŏ������ƂɂȂ�܂�
�Ȃ̂ł��ꂪ�ʗ�H�Ȃ̂��ȁA�ƁB�܂��͕ʂ̊��K������Ƃ�
���ꂾ����������A
�usamples�̋@�\���g���悤�ȃ��W���[���Ƃ����łȂ����W���[���v
�Ƃ��āAhoge.util�����S�Ɋu�����������V���v���Ŗ������Ƃ͖����̂ł͂ƍl���܂���
����������__init__.py�Ƃ��ʼn����ł����ł����ˁE�E�H
������ƒ��ׂĂ݂悤�Ǝv���܂��@
>>656 ����_�Ō�����
�uhoge.util����samples�̋@�\�ЂƂ��g���Ă��Ȃ��̂ɁA�ǂ�����hoge�S�̂�samples��import�����́H�v
�����{�I�Ȗ��Ȃ悤�ȋC�����āE�E
hoge.py �̒��� from samples import aaa
>>658 >>655�́�������samples.aaa�Ȃǂ��Q�Ƃ��鏈��
�́h�Ȃǁh�Ƃ����̂́A������������bbb��������Ȃ���ccc��������Ȃ���
main�̈���������ď���������getattr�����肷�邩������Ȃ�
�Ƃ������Ƃł�
�܂�hoge.main�����������ėp�I�ɏ����Ƃ����
hoge����samples����g���@�\��c�����Ă����A�Ⴆ��
from samples import aaa,bbb,ccc,ddd
�Ȃǎg���\���̂���@�\���������O�ɐ錾���Ă�����
def main(sample_type):
�̂悤�ɏ�������v���x�X�g�Ƃ������Ƃł��傤��
�������ɂ���Ȃ�main�Ɠ����ꏊ��util�������Ă��_�������S�ۂ����ȂƎv���܂����B
�f�����b�g�́Asamples����samples_type�ɓn�������ɕύX���������ꍇ
import aaa,bbb,ccc,ddd �̍s�@�Ɓ@hoge.main�̏���������̃R�[�h���C�����Ȃ���Ȃ�Ȃ�
�Ƃ������Ƃ��炢�ł��傤��
�Ƃ�����samples��from .hoge import util���Ă����
hoge.py�̒��ŕ����I�� from samples import�@���Ă��z�G���[�o�܂��ˁB
>>658 ��͂�A�g��Ȃ��@�\�͊u�����Ĉ������import����
�Ƃ����̂��x�X�g�Ȃ̂�������Ȃ�
���ł��������\���Ȃ̂��悭�킩��炠�ꂾ���ǁA���̂܂܂ł����Ȃ�hoge.py��main��__int__.py�Ɉڂ��Ƃ�����Ȃ�
�����ł��������\��
�\���ɂ��Ă���Ƃ������A����͂��Ă܂���
samples.py��hoge.py�ł��݂��̋@�\��import�������P�[�X���Ă�����
�Ƃ����̂��O��ɂ����āA����
�uhoge.main��hoge.util�͋@�\�I�Ɋ֘A���������̂œ���py�t�@�C���ɂ܂Ƃ߂�v
�Əz���N����
���
�i�P�jimport�̏ꏊ��ς���
�i�Q�jpy�t�@�C������
�i�R�j__init__.py�ł��
�ŁA���́i�Q�jhoge.main��hoge.util��hoge.py��hoge_util.py�ɕ����Ă܂�
��hoge.py��main��__int__.py�Ɉڂ�
�Ƃ����̂����܂����킩��܂���
�Ƃ肠����__init__.py�ŏ��������̂�
https://pastebin.com/DctEgQwC ����ł����A��͂�z�G���[���o�܂�
�����������Ă���̂��͂킩��܂���B
.hoge��"."�݂����Ȏg�������߂Ēm����
>>663-665 ���肪�Ƃ��������܂�
��main��__int__.py�Ɉڂ�
���ĕ����ʂ肾������ł��ˁE�E��
�����A�������hoge_util.py��hoge.py�ɕ�����
�Ɖ����Ⴄ��ł��傤���H�H
hoge.main�Ƃ��������͂����܂ōŏ��\���̂��߂̉��̖����Ȃ̂�
__init__.py���ɏ����͕̂��͋C�I�ɂ͍����Ă܂���
�����Ƌ�̓I�ȋ@�\���������ꍇ��
hoge���W���[���ƂقڊW���f������̂ō���悤��
���Ȃ݂�hoge_util.py hoge.py�ɂ����ĕ�������ł�
https://pastebin.com/SkAM1JhB >>662 >samples.py��hoge.py�ł��݂��̋@�\��import�������P�[�X���Ă�����
���邩�H
__init__.py���ăf�B���N�g�����𖼑O��ԂƂ���
���̃N���X���g������ȃ��W���[�����Ƃ����F��
����������f�B���N�g�����Ƃ����N���X�̃R���X�g���N�^�ł���
�f�B���N�g�����̃��W���[���͓����N���X�ł���
util��������
>>662�́i�P�j��import�̃X�R�[�v��ւ��ĉ������A�����ł�
https://pastebin.com/NsXLF3T2 ��͂�import�͎��샂�W���[�����ۂ��Ɋւ�炸
��{�͈�ԏ�̃X�R�[�v��import����悤�ɂ���
����import�������W���[���̋@�\���g���Ă��Ȃ����̂�
�f���Ɋu�����ď������A�Ƃ����K���ɏ]���������������ۂ��ł���
�܂��������Q���肻���ȋC�͂�����̂�
matplotlib.pyplot.show()����ƈ�X�E�B���h�E���ł��ăX�N���v�g���~�܂邯�ǁA�����Ȃ�Ȃ��łق���
block=False�ɂ���Ǝ~�܂�Ȃ����}����u�ŏ�����
show()����x�ɉi���I�� (=����܂ŏ����Ȃ�) �E�C���h�E���o���Ȃ���X�N���v�g�͑��s������@����܂���
ChatGPT�ɕ����Έ�u�œ����Ă������
���̎�̎��₵�Ă���l��
>>671�����ăp�b�Ɨ����ł���Ƃ͎v����
��show()����x�ɉi���I�� (=����܂ŏ����Ȃ�) �E�C���h�E���o���Ȃ���
���ċɘ_�u���N���݂����ɂȂ���Ă��ƁH
>>670 ���̂����͂킩��Ȃ��̂ŕK�v�Ȃ��������������ĕʂ̕��@���f��
���������Ȃ�摜�ɏo�͂��āA�r���[���ŕ\������Ȃ�
�ȈՓI��http-server�ł����Ă�web�A�v���ɂ��Ă��܂�
�摜�o�͂��邾���̕����`���b�s�[�ɕ����Ă��̂܂��s�������ǂł���
https://ideone.com/pNXjgN show()�g�킸��pause()����draw()�����
>>671,673
�����B�S���킩��܂���B
�ꎞ�t�@�C���ɏ����o���čŌ�ɑS���\�����ď����Ƃ��ő�ւ��悤���Ǝv���܂��B
>>674 >> show()����x�ɉi���I�� (=����܂ŏ����Ȃ�) �E�C���h�E���o���Ȃ���
> ���ċɘ_�u���N���݂����ɂȂ���Ă��ƁH
�����ł��B
�ӊO�Ɠ�����ۂ��ł��ˁB
>>675 �������������I�O��Ȃ��ƌ����Ă�ˁB
����悭������
>>671�������E�C���h�E���Ŏ��X�ƈႤ�v���b�g���o�����@�����B
show()���ɑO�̃E�C���h�E���c�����܂ܐV�����E�C���h�E���o���Ƃ����̂�����肽�����Ƃł��B
�܂�������
���₷�鑤�Ȃ̂Ɉ̂����ȓz
���������Ȃ��O�삪��Ԉ̂��������w
>>670 ���̕��ʂ�ChatGPT�ɓ���ĕ�����
>>678 ����B�ŁA�Ȃ��
>>675�݂����ȓ��e����������H
�}���`�X���b�h�A�}���`�v���Z�X�A�����A���A���̕ӂ������̊�b�m���Ȃ��ƃ_������
�}���Ή��ł܂��͂������w�ڂ�
���������
�����Ԉ���Ă���
�摜�̃G���R�[�h����w��ł���I
�܂��u�}���Ή��v(Walk, Don't Run) ���܂��傤�B
ChatGPT4-Default��ChatGPT4-Code Interpreter
�Ɉ˗����܂���Ί�b�m�������Ă��A�v���ł����Ⴄ��
���C�悭��b���āA�b�����ݍ���Ȃ��Ȃ�����
�`���b�g��V�K�Ŏn�߂�
�G���[���o���炻������̂܂�ChatGPT�ɓ`����
ChatGPT4-Code Interpreter�{Custom instructions�̉�
matplotlib.pyplot.show()���g�p����ƁA
�ʏ�A�}��\������E�B���h�E���J���A
���̃E�B���h�E��������܂ŃX�N���v�g����~���܂��B
�������A�X�N���v�g���~�������ɐV�����E�B���h�E�Ő}��\���������ꍇ�́A
���̕��@�������Ă݂�Ɨǂ��ł��傤�B
ion()���g�p���ăC���^���N�e�B�u���[�h���I���ɂ��܂��B
figure()���Ăяo�����ƂŐV�����}���쐬���܂��B
�O���t���v���b�g���܂��B
draw()���g�p���Đ}���X�V���܂��B
�ȉ��́A���̕��@���g�p����3�̈قȂ�}���쐬���A
���ꂼ��̐}��V�����E�B���h�E�ɕ\�������ł��B
import matplotlib.pyplot as plt
import numpy as np
# �C���^���N�e�B�u���[�h���I���ɂ���
plt.ion()
# �ŏ��̐}
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
plt.figure() # �V�����}���쐬
plt.plot(x, y1)
plt.title("�}1: sin(x)") # ���{��̃^�C�g��
plt.draw() # �}���X�V
# 2�Ԗڂ̐}
y2 = np.cos(x)
plt.figure() # �V�����}���쐬
plt.plot(x, y2)
plt.title("�}2: cos(x)") # ���{��̃^�C�g��
plt.draw() # �}���X�V
# 3�Ԗڂ̐}
y3 = np.sin(x) * np.cos(x)
plt.figure() # �V�����}���쐬
plt.plot(x, y3)
plt.title("�}3: sin(x) * cos(x)") # ���{��̃^�C�g��
plt.draw() # �}���X�V
ChatGPT4-Code Interpreter�{Custom instructions�̉�(�ʂ̃`���b�g)
matplotlib�̃f�t�H���g�̋����ł́Aplt.show()���Ăяo���ƁA
�E�B���h�E���\�������ۂɃX�N���v�g�̎��s����~���܂��B
�������Ablock=False��ݒ肷��ƁA
�E�B���h�E�������ɕ��Ă��܂��Ƃ�����肪�����܂��B
���̋�����ύX���āA
show()���Ăяo�����тɐV�����E�B���h�E�����Ȃ���X�N���v�g�s����ɂ́A
�ȉ��̎菇�������Ă݂邱�Ƃ��ł��܂��B
plt.figure()���g�p���ĐV�����t�B�M���A���I�ɍ쐬���܂��B
�v���b�g��T�u�v���b�g���쐬���܂��B
plt.show(block=False)���g�p���ăt�B�M���A���u���b�L���O���[�h�ŕ\�����܂��B
plt.pause()���g�p���ď����̊ԃE�B���h�E��\�������܂��B
���̎��Ԃ͒����ł��܂����A�ʏ�͒Z�����ԁi�Ⴆ��0.1�b�j�ŏ\���ł��B
�ȉ��́A���̎菇���g�p���ĘA������2�̃O���t��\������T���v���R�[�h�ł��B
import matplotlib.pyplot as plt
import numpy as np
# �f�[�^�̐���
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
# �ŏ��̃O���t��\��
plt.figure() # �V�����t�B�M���A���쐬
plt.plot(x, y1)
plt.title("y = sin(x)")
plt.show(block=False)
plt.pause(0.1) # �E�B���h�E�������̊ԕ\��������
# ��ڂ̃O���t��\��
plt.figure() # �V�����t�B�M���A���쐬
plt.plot(x, y2)
plt.title("y = cos(x)")
plt.show(block=False)
plt.pause(0.1) # �E�B���h�E�������̊ԕ\��������
����Ȃ��Ȃ�ق��Ăĉ�����
�E�U�������ł�
>>688-692 �S�����̂�肽�����Ƃ���Ȃ�
�w�E�ł���l������Ǝv�������ǃ_����������
Selenium��webdriver_manager������O�̂悤�Ɏg���Ă����ǁAChrome115���ł�����ƐF�X�l��������ꂽ�B
���Ǎ����Google���h���C�o�[�̏ꏊ�ς�����G���[�f���킯������Ώ�����Ȃ�chrome�̃A�v�f���Ȃ��悤�ɂ���ׂ����B
�蓮�Ń_�E�����[�h���Ă����炢�������ł�
"""
Usage:
test.py [-t <test>]
"""
from docopt import docopt
args = docopt(__doc__)
print(args)
>test.py -t aaa
{'-t': False,
'<test>': None}
win11��docopt�������ĂȂ��C������
docopt 0.6.2
�`���`���V���b�V���b�V���b���Ă銴���̃X���b�h��
����
>python test.py -t aaa
{'-t': True,
'<test>': 'aaa'}
win10�Ƌ������Ⴄ
test.py �ŋN������ƁAopen('file')��test.py�Ɠ����ꏊ����J��
python test.py ���ƃJ�����g�̏ꏊ���ς��̂ŃG���[�ɂȂ�
�R�[�h�ɐ�p�X���ߍ��ނ̂��������Apy�̂���ꏊ���擾����̂��ʓ|����
�������肷��Ɩʓ|��������
parent = Path(__file__).resolve().parent
parent.joinpath(file)
�݂����ɂ���Α��ŏ�����
����͕֗����Ɗ������C�u�����ɓo�^����ƁA���C�u�����̂���p�X�ɂȂ��Ă��܂�
�ʂ̃t�H���_�̃��C�u�����ɂ�������Ăяo���āA
open(add_current_path(LOG_FILE))
�݂����ɂł��Ȃ�����
�l�I�Ɋ�{�Apython�X�N���v�g�ň����t�@�C����f�B���N�g���̐�p�X��
env�t�@�C���ɏ����Ă�
���ϐ��ɂ��Ă��������A���Ȃ�env�t�@�C���ɒ��ڃA�N�Z�X�����o�����
�o�����K����p�X�ɂȂ�̂�env�̕ҏW�����C�ɂ��������������
__file__ ��n������chdir���Ă�����������āA���܂��Ȃ���1�s��lj����悤
windows�Ń����`���[����X�N���v�g�N�����ď���������g������venv�������Ǝv���Ȃ����
windows�̃����`���[���ĉ��H�T�[�r�X�ƈ���Ď��s����venv�w��ł��Ȃ��́H
def find_data_file(filename):
if getattr(sys, "frozen", False):
datadir = os.path.dirname(sys.executable)
else:
datadir = os.path.dirname(__file__)
return os.path.join(datadir, filename)
�����炻�ꂾ�ƁA���̊���o�^�������C�u�����̂���p�X��Ԃ�����
�R��́A�f�X�N�g�b�v�ɃV���[�g�J�b�g������āA
WSL2, Ubuntu-18.04, VSCode ���N�����āA
�v���W�F�N�g�t�H���_���J���Ă��邯��
�����N��
C:\Windows\System32\wsl.exe code .
��ƃt�H���_
\\wsl$\Ubuntu-18.04\home\<���[�U�[��>\test\proj1
python�ň����t�@�C���̃p�X���ĂقڂP�O�O��
�ݒ�t�@�C����������ÓI�������肷�邩��
python�t�@�C�����ɑ��p�X�ň����͔̂��Q�[���ł����Ȃ�
�����f�B���N�g����config.ini��u���āA�Ƃ��ނ���퓅��i�Ȃ̂ł�
������env����̂��퓅�Ȃ�Ȃ���
env��͑��p�X�ɂȂ�悤���Ȃ�����
python�X�N���v�g���ő�������������C�ɂ��Ȃ��Ă悭�Ȃ�
venv�͖w�ǎg�������ƂȂ���ɁA�g���ƍ�������̂łނ�������Ă�
�������Ă��R���\�[������g���Ă�Ⴕ��������Ȃ����ǁA
�Ⴆ��excel�̃}�N�����炳��ɌĂяo���āA�݂����Ȏ��ɂ��g����?
>>715��env��venv�͕ʂ����ȁH
import traceback
print(traceback.extract_stack()[0].filename)
����Ŏ��s�J�n�̃t�@�C��������ꂽ�肵�Ȃ��H
�X�^�b�N�g���[�X��1�ԍŏ�������Ă��銴��������
�����ĂȂ��̂ŁA�o���Ȃ������炲�߂�Ȃ���
>>718 env: ���ʂ͊��ϐ��̂��Ƃ�����
venv: �����̉��z���c�[��
������܂������W�Ȃ���
python.exe�̂���ꏊ���J�����g�f�B���N�g���ɂ��ė����オ��̂��Ԉ���Ă���
����ȏꏊ�ɗp�͂Ȃ�
�����̃I�v�V������t����ƁApy�̏ꏊ���J�����g�ɂ��ė����オ��Ƃ��ɂȂ��Ă�ׂ�
�{���͂��ꂪ�f�t�H���g�ł����ė~����
>>723 ���s������������Ă��ƁH
�C���X�g�[�����Ă郉�C�u�����[�����ɂ���ĈႤ�̂ɁH
�n�C���x���߂��Ă��čs���Ȃ�
if __name__ == '__main__': �� __main__ �`���Ă���l�͑����Ǝv������
__file__ �Ŏ����� .py �̈ʒu����̒m��Ȃ��l�͑���
>>727 > ������ .py
�Ƃ͉��B
>>702 �O�O���ĕ����邱�ƂȂ̂�...
> python.exe�̂���ꏊ���J�����g�f�B���N�g���ɂ��ė����オ��
�Ƃ��A���l���ό������킵�Ă���悤�ɂ������Ȃ����ǁA�F�^���ɘb���Ă���̂Ŏ����Ȃ낤��...
��̑O�ɓ����������Ă��ς��Ȃ�
�ς悤�Ƃ����Ȃ��t�V�A�i����ɂ�
Python�͖���
>>716 �g����
>>730 �����ł͂Ȃ�
VSCODE�Ń��[�N�X�y�[�X�ɒu���č�Ƃ���ΑS�ĉ�������b�Ȃ̂ł́H
>test.py�]�X
>>716 venv�Ȃ��Python�̎��s����venv�f�B���N�g�����ɂ��̂܂����Ă邾��������A������Python���s�t�@�C�����t���p�X�Œ��ڎw�肵�Ă���������
���ʂ�Python�Ƀp�X���ʂ��Ă��Ԃ�
python hoge.py
�Ƃ��Ŏ��s���邯�ǁA�����
C:¥foo¥bar¥puroguramu¥venv¥bin¥python hoge.py
�݂����ɂ��
venv���������̂Ȃ̂�
�R���\�[���ŃR�}���h�ł��āA�����炱�������o�[�W�����Ȃ�Ƃ��A�݂����Ɏg���Ǝv���Ă�
�����̃o�[�W�������ւ������v���͓��ɖ����̂őS���ŐV�ō\��Ȃ�
venv��hoge.py�������̏ꏊ�����邱�ƂƂ͊W�Ȃ����
python hoge.py������C���X�g�[�����python.exe���Ă�邯�ǁAvenv��activate�����ꍇ��python hoge.py������venv��python.exe���Ă��
Lib\site-packages�����l
���z�����Ă������C���X�g�[���������Ɛ藣���Ď��s�����\�z�ł���̂�venv
venv����Python�o�[�W������venv���Ƃ��Ɏ��s����Python�̃o�[�W�����Ɠ����ɂȂ�
<div class="form-input-wrapper" data-v-a0d39a18=""><input type="text" name="" value="" placeholder="���[���A�h���X" class="form-input" data-v-a0d39a18=""></div>
selenium�ł����element���擾����send_keys()���Ă���������Ȃ�
�������Č����鎩�����O�C���̋L����html�̏��������Ⴄ
�����ʂ̕��@���K�v?
�Ǝv������ł���
> input ��������̂�Y��Ă�
�܊p������̂ɁA�{�Ԋ���win7�ł͓����Ȃ�����
selenium4�������̂������݂�����3�ɂ����瓮����
�J���p�͕��ʂɃC���X�g�[�������̂ɂȂ��3��������?
cwd(current working directory)�̈ړ����H
VSCode �̊g���@�\�ECode Runner �Ȃ�A���̐ݒ���`�F�b�N���Ă���
Code-runner: File Directory As Cwd
Whether to use the directory of the file to be executed as the working directory.
��������Ǝ��s����cd �ŁA���̃t�@�C��������ꏊ�փJ�����g�f�B���N�g�����ړ����Ă���A
ruby "��p�X/�t�@�C����.rb"
���́Aruby "��p�X/tempCodeRunnerFile.rb"
�ŁA���̃t�@�C�������s����
tempCodeRunnerFile.rb �́ARuby�̃R�[�h�Ђ��R�s�[�����ꎞ�I�ȃt�@�C��
�ݒ荀�ځAexecutorMap �ɂ́A�����̌���̎��s�R�}���h�������Ă���B
"code-runner.executorMap": {
"javascript": "node",
"c": "cd $dir && gcc $fileName -o $fileNameWithoutExt && $dir$fileNameWithoutExt",
"cpp": "cd $dir && g++ $fileName -o $fileNameWithoutExt && $dir$fileNameWithoutExt",
"python": "python -u",
"ruby": "ruby",
python�ɂ́A-u ���t��
�Q�[����BGM�̒�������ʉ��𒊏o����python�v���O��������肽����ł����A�������C�u�����Ƃ�����܂����B
>>711 >>719 ���X�����ǂ�sys.argv[0]�ł����s�J�n�̃t�@�C�����擾�ł���
config.ini�ǂ݂����ꍇ�͂�����chdir���Ă���ǂ߂���
os.chdir(os.path.dirname(os.path.abspath(sys.argv[0])))
exe�������exe�t�@�C���̏ꏊ��__file__���ʂɂȂ����肷�邩�炱��g��
���Ȃ݂ɍ��ǂ���Selenium���pyppeteer�̕���������ˁH
test.py�̂���ꏊ�Ɉړ�����
python test.py
�Ƃ���ƁAsys.argv[0]��test.py�Ȃ��
test.py�̐l�̓��W���[����������������s�J�n�t�@�C���̏ꏊ���擾����
�ݒ�t�@�C���Ƃ���ǂ݂��������݂���������
�����������������̂�main������ꏊ�ł���Ĉ����œn���̂���ʓI
python���n�߂�1�N��������������
����Ƌ@�B�w�K��������悤�ɂȂ���
numpy��pypy3.9�܂ł����Ή����ĂȂ��Ă炢
���O�瑁��3.10�Ή�������
���C�u������҂���ς���
����ɏオ��{�̃o�[�W�����ɖ����őΉ���������
open�ŐV�K�������݂ŊJ�����ɁA���̃t�@�C���𑼂̃\�t�g�Ō��Ă��肷��ƃG���[�ɂȂ�
�ⓚ���p�ŏ���������I�v�V�����Ƃ�����?
�t�@�C���n���h���̈ꗗ���擾����
OS�Ƀt�@�C���n���h���̃N���[�Y���Ă��炤
���̒��̑��̃\�t�g�͂���Ȃ��ƂɂȂ炸�ɁA������x�J���Ƃ����ƍX�V����Ă���
����炪������������Ȗʓ|�Ȃ��Ƃ����Ă�Ƃ͎v���Ȃ��āApython�������Ў�ɍ���Ă���Ƃ���
�u���̒��̑��̃\�t�g�v�ƌ����I�}�G�̕������ȂN���m���
�o�b�`��power shell�ł��������ʂɂȂ邾�낤
�ȒP�ȃX�N���v�g�Ŏ����ƁA���ɃG���[�ɂȂ炸�Ɋ��Ғʂ�ɏ�������
��������������������
����������̓I�ɏ����Ȃ��ƃA�h�o�C�X�͏o�Ă��Ȃ�����
selenium�ŃX�N���C�s���O���Ȃ����荞����json�ɏ����o���A
�Ƃ����̂����ۂɂ���Ă������ŁA�������ł̓G���[�ɂȂ���ǁA
���ʂ�json�����������ł͖�肪�N���Ȃ�
�t�@�C���T�C�Y���傫�����炩��
OSError: [Errno 22] Invalid argument:
�̃G���[�ɂȂ�Ƃ����̂��悭����Ȃ�
���̓p�X�̎w�肪�Ԉ���Ă�Ƃ������������ǁA���i�͂����Ɠ����̂�
���Ⴀ�u���i�v�ʂ�ɂ��ĂȂ����Ď��Ȃ낤��
�����œ��������Ă邶���
python��selenium�����ău���E�U���삵�Ď������O�C������Ƃ��ɂ��Ď��₳���Ă������������ł��B
�摜��I�ԃ^�C�v�̔F�����݂���ꍇ�͂ǂ̂悤�ɂ��ē˔j��������ł��傤���H
�ꉞ�����Ă݂����Ƃ́A
�E���O�C����ʂɑJ�ڂ�����A���[�U���A�p�X���[�h���������͌�A
�@��sleep()���g����10�b�~�߂Ă���ԂɑΏۂ̉摜���蓮�N���b�N�őI������
�@���̂���10�b�o������V�X�e���������Ń��O�C���{�^������������
�E���O�C����ʂɑJ�ڂ�����A���[�U���A�p�X���[�h���������͌�A
�@���݂�URL���擾���ĕ�����Ƃ��ĕϐ��ɕۑ�(oldUrl)
�@2�b�Ɉ���while����URL�����߂Ď擾(newUrl)��oldUrl��newUrl���ׂ�
�@�قȂ�URL�ɂȂ�����i���O�C����̉�ʂɑJ�ڂł�����j
�@����while���[�v���đ����̃u���E�U����̏��������s������@
�@����2�ڂ̕��@�́Awhile������Ă���Ԃɉ摜�̑I���ƃ��O�C���{�^���������蓮�ōs�����̂Ƃ��Ă��܂��B
����2�_�������Ă݂܂������A���܂����O�C����̉�ʂɑJ�ڂ��邱�Ƃ��ł��܂���ł����B
�����@�Ƃ����O�C���{�^���̓A�N�e�B�u�\���ɂȂ��Ă��āA
�����ڂƂ��Ă̓N���b�N���ł��ĂȂ��Ƃ��������������ł͂Ȃ������ł��B
�摜�I���ȂǁA���ʂȔF���K�v�Ȃ��ʃT�C�g�Ń��O�C���������Ă݂܂������A���O�C�����\�������̂ŁA
��܂��ȕ��@�͊Ԉ���Ă��Ȃ��̂��Ȃ��Ǝv���Ă���̂ł���...
�Ȃɂ��������@�Ȃǂ������̕���������Ⴂ�܂�����A�������������������ł��B�B�B
�n�C���x���ł��Ă����Ȃ��ƌ������蕶����������
���i���H
>>766 �}�E�X�̓������Ől�Ԃ�CPU���̔��f���Ă�^�C�v�̔F����ˁH
���ʂȓ�������Ă݂Ă���������
�Ⴆ�Γ��������^�]�ł�uwsc�݂����Ƀ}�E�X�J�[�\���̐���������ƃ��O�C���o�����Ȃ����낤��
���̃T�C�g�����Ȃ��ƕ������̂ɁA�ډB���őz�����ĖړI��B���郂�m�����Ƃ��S�{�c
�}�E�X�̓����ȂT�[�o�ɂ͓`����ĂȂ�
���f����Ƃ��Ă��N���b�N�ʒu�ƃ^�C�~���O����
from ��� import �n�C���x��
>>766 �蓮�^�X�N���K�v�ȉӏ��Ƀf�o�b�K�[�̃u���C�N�|�C���g������
�������蓮�^�X�N�����s���Ȃ���u���E�U�̃f�x���b�p�[�c�[����
DOM��HTTP���N�G�X�g/���X�|���X���m�F��������T�����
�܂��̓��O�C���{�^����������HTTP POST���N�G�X�g�̏����Ă݂�
�ƍ߂̂�����l�ɕ����悤�Ȃ��̂���
����Ȃ������I�[�v���ȏ�ŕ����Ȃ�
�ǂ����Ă����Ȃ玩���̗͂����ł��Ȃ���
>>773�������Ă邪�A���l�̉Ƃ�Ԃ̌��̊J�������Ă�̂Ɠ�������
�摜�F�����ʒ[���Ől�Ԃ����H
�蓮���O�C��������̏����擾���Ȃ�����Ɠ���l���āA
�ēxget()���Ă��܂��ă��O�C���O�ɖ߂��Ă���ƃG�X�p�[
766�ł��B
���������������A
����܂��낵���Ȃ��̂ł́H�Ƃ��w�E�����������������肪�Ƃ��������܂����B
������̕��@���摜�F�̕����͊��S�Ɏ蓮�̑z��ŁA���A�J�E���g���̂��������g�̂��̂��g�p���Ă��܂����̂ŁA
���l�̉Ƃ̌����J����悤�Ȉ������@�ŃZ�L�����e�B��˔j���Ă���Ƃ����ӎ��͂���܂���ł���...
�m���ɕ֗��ȋZ�p�Ȃ̂ŁA���p���Ă��܂��������邩������܂��玩���Ń��O�C�����邱�Ƃ�
�摜�F�͎蓮�������Ƃ��Ă��G���[���N�����������x���Ŗh�~���Ă���\���͂���܂���...
�����������Ă��܂��Ă��݂܂���A�݂Ȃ��肪�Ƃ��������܂���...
�E�t���[�G���W�j�A���N��3,600���~�̔�����グ�����@���������
�E26�œƗ����Č���150���ɂȂ��� ������������G���W�j�A�̕���
�E�u���b�N��Ƃ���ސE���A�Ɨ���11�����Łg����300���~�����h�ɂȂ�܂ł̋O�Ղ�
�@�f�U�C�i�[�В��D�z�Ǒ��ɕ����Ă݂��I
�EIT�t���[�����X�Ō��z�P��150���~�I������̏A�ƕs�\�ɔ�����
�����̕ی�������u�N���E�h�e�b�N�v
�E�t���[�����X����Ɍ���4���~���ō�340���~��B�������D�z����ɁA
�u�����v�Ƃ̌������������Ă݂�
�E�t���[�����XSE���Ăǂꂭ�炢�҂���́H���P��160���~�̈Č���������ԃG�[�W�F���g
�E�t���[�����X�̎d����E�Ƃ̎�ނ��ĉ�������́H�Ɨ�5�N�ڂŌ���200���̖l���ڂ������
>>781 selenium���playwright��storage_state���g���ăZ�b�V�������ė��p���������ȒP����
���O�C�������͎蓮�ɂȂ邯��
���[�U���A�p�X���[�h���������͂��鏊�܂ł��A
selenium �Ŏ������삵�āA
����Ȍ���蓮�ɂ���H
�f�[�^�x�[�X����擾�������R�[�h���Arequests�łǂ����ɓ�����Ƃ�����
�f�[�^�x�[�X����擾�������_�ŃZ�b�V�������甲���������ǂ��Ǝv���̂����݂�Ȃǂ�����Ă�́H
�Z�b�V�����J���@���@���R�[�h���擾�@���@���R�[�h��ϊ����ĕϐ��Ɋi�[�@���@�Z�b�V��������
���@�ϐ��Ɋi�[���ꂽ���R�[�h�̓��e��requests.post�@���@����or���s�Ȃ�
���@�Z�b�V�����J���@���@id�Ȃǂ��烌�R�[�h�����@���@���R�[�h���X�V�@���@�Z�b�V��������
�Z�b�V�����J�����܂܂���
�Z�b�V�����J���@���@���R�[�h���擾�@���@���R�[�h�̓��e�𐬌^����requests.post�@���@����or���s�Ȃ�
���@���R�[�h���X�V�@���@�Z�b�V��������
�Ȍ������u����or���s�Ȃǁv�̕�����timeout������ꍇ���̉e�����C�ɂȂ�
���i�g���ĂȂ�����selenium��chrome���g���Ă�̂ɁA�����update���ăG���[�ɂȂ�
������116�p�̓e�X�g�ł�������
�O�_�O�_�����O�ɂ܂�����Ă݂��
>>785 DB�ւ̍X�V���K�v�Ȃ��{�R�l�N�V�����ێ����Ă���Ă��܂���
�X�V���ɃR�l�N�V������Ԃ��`�F�b�N���āA���Ă�����Đڑ����鏈��������
DB�ւ̐ڑ��̓R�l�N�V�����v�[�����g�p
����
txt.replace("����","�u��")
re.sub("����","�u��",txt)
���̈����̏��ԊԈ����
re.sub("����",txt,"�u��")
���Ă���Ă��܂��IJׯ�Ƃ���
�G���[�łȂ���
>>789 > re.sub("����",txt,"�u��")
sed 's/����/' txt '/�u��/g'
�Ƃ���悤�Ȕ��z�͂Ȃ��Ȃ������Ȃ��B�ւ��Ă����B
�ӂ�������selenium��3����4�ɏグ��
�e���ނ������Ȃ�
Microsoft�uPython in Excel�v�\
�L���ێq��pythonPython����
���l�v�Z��@�B�w�K�Ȃ�R��c++�ň���������
R���K�����p�r��R���������ǁA
�͈͂���������֗��ɂȂ�l�����Ȃ����
�G�N�Z����python�g����Ƃ��O���猾���Ă����ǂ��ɂ����Ȃ����̂�
mysql��sqlite3,postgresql�Ȃƈ����
�\���O���RDBMS���Ċ����H
�܂�VBA�������Ă��l�ɂƂ��Ă͑I������������̂͊�������Ȃ낤��
�܂��܂�����I�ȗ��p�����o���Ȃ���
LibreOffice�Ƃ����Ȃ�O����g���Ă�̂�
excel�̌`�����̂��̂��K���Ȃ��ǂ�
�f�[�^��ǂݍ����xlsx�ɂ��ĕۑ����邾����30�b�Ƃ�������
100���s�ɏ��������
�����Ə����������Ȃ�excel�͋ɗ͔����āA�l�ԂƂ�IF���������ɗ��߂�ׂ�
���̒��x�Ȃ�VBA�ł��債����Ԃɂ͂Ȃ�Ȃ�
�l�b�g����f�[�^�擾�o����l�ɂȂ��Ă�Α啪�����
�O���A�N�Z�X�͋@�\��������Ă���������
>>799 ����VBA�o����K�v����Ȃ���
>>804 Dim var �Ƃ��ϐ��錾���� Python ��������Ȃ���BPy# �Ƃ����Â����āB
>>800 ����͂킩���Ă��
�t���I�ɁA�Ⴆ�upython�ŁA�f�[�^�x�[�X������mysql�ŁA�G�N�Z�����ۂ��A�v�����܂����v�ƕς�炭�Ȃ��Ă���Ȃ��̂��Ă���
�ڂ����͒m��Ȃ�����Google Sheets�Ƃ��܂��ɂ�������Ȃ��́H
�f�[�^�x�[�X����L�肫��python���Ă��Ƃɂ͂Ȃ肻���ł͂���
�����܂��\�v�Z�\�t�g���Ăǂ��l���Ă��v�Z�@�\��̂����f�[�^�x�[�X��̂ōl�������������I�����
id�X�����Ƃ����ꔭ�ޏ�ɂȂ��Ăđ�
���͂�����python�ŃQ�[���v���O���~���O������������Ăق���
excel������Ȃ��Ƃ����Ȃ����Ƃ����邯�ǁApandas�Ƃ������������������͎̂g���Ȃ�
������2�����z��Ƃ��ēǂݍ���ŁA�K�v�ȃf�[�^�͎��͂ŒT��
�@�B�őf���ɓǂ߂�悤�ɂƋC���g���悤�Ȑl��������A
�ŏ�����f�[�^�`����excel��I��̂�
�����܂ŏo�͗p�Ńf�[�^�X�g�A�Ƃ��Ă̗��p�͖�����
>>806 �L������������VBA��}�N���̑����python��������悤�ɂȂ����Ƃ����v���Ȃ���
Python��excel�M��̂Ɖ����Ⴄ�B
Python��excel�M��̂�
15�N�ȏ�O����o���Ă�̂����X
excel���python�Ŏ��s��������x���\���܂ł���
�P��VBA�ł�����̂������Ă����ł���B����VBA�͌����B
�p�p��?!
�}�}�[�����Ⴂ��[!!
����Ȃ���͒����Y�̈�킾
�퍐��VBA�J��3�N�̌Y�ɏ���
���X�g��append���ď����ۏ���Ă������E�E�H
>>815 ���[�N�V�[�g�ɃR�[�h�������ƁA���I�u�W�F�N�g�����[�N�V�[�g�Ȃ̂ŁAexcel.workbooks[x].worksheets[x] �݂����ɒH��Ȃ��čςށu�C�����v�͂���̂�������Ȃ��B
��A�z�������ǁB
excel����python�g�������l�͂����g���Ă���
�r�����t�H���g���w�i���
�����̎�Ԃ��Ȃ���Ƃ����̂�����
excel��poor point�g���̂͑��l�Ȍ����������ł��邩�炾��
�摜�̓\��t���Ƃ��o���Ȃ�������
�����悤�Ȃ̂��t�H���g�ƐF���H�v���č����
��������Excel����Python OK�ɂ���͈̂�a���ł����Ȃ��̂�
Python�͊w�K�R�X�g���Ⴂ����
���̓_JS�ł��ǂ����ǁA��������10�i���^�g���Ȃ��Đ��l�v�Z�Ɍ����Ȃ�
�������ҏW��VBA�p�̕��G�f�B�^�����̂��Ȃ�?
VS Code���ߍ���ŗ~������
�w�K�R�X�g�Ⴂ���Ċw�K���₷����ł͂Ȃ��ĉ��p�̕����L������R�X�g�Ⴂ�����₩���
�}���`�X���b�h�⏃�����z���Ȃǂ�����̂ő��̌���Ɗw�K���Ԃ��̂��̂͂���Ȃɕς��Ȃ�
�w�K���₷������c�ɔ�r���Ă��w�Ԃ��Ƒ����̂ɂ��H
�w�K���₷�����ĉ��������Ċw�K���₷�����Č����Ă�H
�I�u�W�F�N�g�w������ł���Α��Ƃ���ȕς��Ȃ����낤
Excel���ڂ�Python���Â��ăN�\���Č����関����������
>>830 > �w�K���₷������c�ɔ�r���Ă��w�Ԃ��Ƒ����̂ɂ��H
���Ȃ��̂łȂ����B�n�[�h�E�F�A���C�ɂ���K�v�Ȃ����B
>>832 >>794���������N���E�h��Ŏ��s����邩�炻��͂Ȃ�����
���̑���I�t���C���ł͎g���Ȃ���
Python�͖L�x�ȃ��C�u�����g���ĂȂ�ڂ�����A
�������̕����w��ł����ƂȂ�Ƃ߂��Ⴍ����ɍL��
Python�͊O�����C�u�������g��Ȃ��f�̏�Ԃ��ŋ�
�����c�[��������āA���[�U���@�\�g���ł���悤�ɂ���
���Ƃ��ϐ�����āA�����g�ݍ��킹�ă��W�b�N�����R�ɍ���ĖႤ
�����������̃X�N���v�g�̕��@�Ƃ���python�͍œK
class�Ƃ����C�u�����Ƃ��͖����Ă��f���ɏ�����
Excel���Python����Excel�𑀍삷��
Excel���Python����OpenOffice�𑀍�ł����肷��̂��낤���B
>>839 �o����ł���
���ʂɍl����
>>837 ���O�����@���Q�e���m����B���������Ă��炢�����B
enumerate���֗��Ȃ��ǎg���|���Ă������H
i=0��i+=1�ōċA�Ƃ��������������Ƃ��������
���́Alist_a[i]��list_b[i]���Z�b�g�ň���������������Ȃ�
list[i].a �� list[i].b �̕�����Αf��
emumerate�͒n���̊�
�����ʂȎg�p�͖��{�������s�����ƂɂȂ�
��̓I�ɂ͂������肱���������Ƃ���������
�����������@�Ȃ�����
items = [item1,item2,item3]
prms = [prm1,prm2,prm3]
# prms = [prm1]
max_prm_index = len(prms)-1
for i,item in enumerate(items):
�@item( prms[min(i,max_prm_index)] )
prms��prm1�̈�����Ȃ�������Aitems��item�S����prm1��K�p
prms��items�Ɠ������������������Ă���A���Ԓʂ��items��prms��K�p
���Ċ���
�������ꍇ�����ł����Ƃ͎v������
�ċA���ɂ��Ԃ鏈��������̂łǂ���������
>>846 prms�̗v�f����1�ł��Ȃ�items�Ɠ����v�f���ł��Ȃ��ꍇ�͂ǂ�����́H
����min(i, max_prm_index)�ł���Ă�悤��prms�̍Ō�̒l��K�p�����������́H
prms�̍Ō�̒l��K�p�����������Ƃ������Ƃł����
�Ȃ�ׂ����̈Ӑ}�f�����R�[�h�ɂ���
from more_itertools import repeat_last
zip(items, repeat_last(prms))
more-itertools�݂����ȕςȂ̂��g���̂��{���ɖ]�܂����̂��^��
�����Ȍ��ɏ�����python�Ă������Ȃ�
�R�[�h�͂Ƃ��ēǂꍇ�A�͂����߂��ĂČ�������������̂��ʂ���
���ꍇ�͂ǂ�����́H
�P�ɃG���[�f���ďI���
��prms�̍Ō�̒l��
�ł͂Ȃ�
������min(i, max_prm_index)�ł���Ă�悤��
��
prms���P�̏ꍇ�@���@max_prm_index = 0
items���ċA�����Ƃ��� i�@�� 0,1,2,,,,,,,,,,
min(i, max_prm_index)�̒l�@���@min(0,0)=0,min(1,0)=0,min(2,0)=0,,,,,,,
prms�������̏ꍇ�@���@��max_prm_index = 2
items���ċA�����Ƃ��� i�@�� 0,1,2
min(i, max_prm_index)�̒l�@���@min(0,2)=0,min(1,2)=1,min(2,2)=2
uncompile6��decompile3��pydumpck��marshal�g�����t�V���A������
�ł��Ȃ�pyc�t�@�C���̋t�R���p�C���ǂ�������炦�����
>>851 >�P�ɃG���[�f���ďI���
����Ȃ�ꍇ�����K�{�Ȃ̂�1���̏ꍇ�Ɨv�f������v���Ă�ꍇ���܂߂�
�ŏ����番�����ق��������I
min(i, max_prm_index)��prms��2����items��4���̂Ƃ�����
(prms[0], item[0]), (prms[1], item[1]), (prms[1], item[2]), (prms[1], item[3])�ɂȂ�ł���
�܂�s�����Ă�v�f��������prms�̍Ō�̗v�f��K�p��������
���������������Ӑ}���ĂȂ��Ȃ��߂��ق�������
���ƃ��[�v�������̓C�e���[�g�̂��Ƃ��ċA�ƌĂ�łȂ��H
>>853
��min(i, max_prm_index)��prms��2����items��4���̂Ƃ�����
�����>>846�́�prms��items�Ɠ���������
�Ƃ͈Ⴄ�����Ȃ����ݒ肵�����[�����Ǝv��
�����ƃ��[�v�������̓C�e���[�g�̂��Ƃ��ċA�ƌĂ�łȂ��H
�Ȃɂ���肪�H
���ŏ����番�����ق���
�S������Ă��ƁH
���ꍇ�����K�{
����@����ɁA�Ⴆ��
if items��prms�̃`�F�b�N:
�@if prms�����̏ꍇ and :
�@�@for item in items:
�@�@�@�����ɏ���
�@elif prms�ЂƂ̏ꍇ:
�@�@for item in items:
�@�@�@�����ɏ���
�݂����Ȃ��Ƃ��낤���H
�b�͂���邯�ǑO�����������ł��������̋^�₾��������
if items��prms�`�F�b�N:
�@raise
if ����:
�@pass
else:
�@pass
�݂����Ȃ��Ƃ��Ă��Ȃ��ق����ǂ��̂��낤���H
>>846�ł͈Ӑ}�I��if items��prms�`�F�b�N:rase
�̕������i����ȍ~�̏����ɊW�Ȃ��̂Łj�ȗ��������� shutil����ׂĂ��ċC�ɂȂ����̂ł���
�X�V������쐬�����������p�����悤�ȁAWindows�̒ʏ�̃t�@�C���ړ���
shutil.copy2()�Ŏ����ł��܂����H
���ׂ��os.system()��copy�R�}���h�𓊂�����@�Ȃǂ��o�Ă��܂���
�����C�ɂȂ����̂ł����A��������Windows�̕W���I�ȃt�@�C���ړ�����copy�R�}���h�Ɠ����Ȃ̂ł��傤���H
os����͂킴�킴import���Ċ撣���Ă��ǂ����݊����Ȃ������A
�R�}���h���s����̂��m���ŊȒP�ɂ�肽�����Ƃ�����
�ӂƎv�������ǂ����d���t�@�C����python�X�N���v�g��mv�Ȃ�R�s�[�����Ƃ�����
OS���H�ŏ������Ă�Ԃ�python���ŕ����ƂɂȂ肻��
�v��python����
�d���t�@�C�����ړ����鏈��()
print("�܂��ړ����I����Ă��Ȃ��̂ɂ������s�����")
���ĂȂ��Ă������H
os.system()����Ȃ���subprocess.run()�Ƃ�
asyncio��create_subprocess_exec()��create_subprocess_shell()�ő҂���
>>854
enumerate�Ƃ�min�Ƃ��g�킸�Azip�ŏ��������Ⴆ�H
>>848��repeat_last����������������
if len(prms) == 1 or len(prms) == len(items):
�@for item,prm in zip(items,prms):
�@�@item(prm) >>1 carnets�̃f�[�^���������̂����A
�ǂ���������̂��A�A�A
>>858 ��������
�ǂ��q���g��
���肪�Ƃ�
>>859
items���R�Aprms���P�̂Ƃ����ʂ͂ǂ��Ȃ����H
items = ["items","item2","item3"]
#prms = ["prm1","prm2","prm3"]
prms = ["prm1"]
if len(prms) == 1 or len(prms) == len(items):
�@for item,prm in zip(items,prms):
�@�@print(item,prm) shutil.copy(), shutil.copy2(), shutil.copyfile():
�����̃��\�b�h�́A�t�@�C���̓��e���o�C�g�œǂݎ��A
�R�s�[��̃t�@�C���ɏ������݂܂��B
�t�@�C���̃T�C�Y���傫���ꍇ�A���̃v���Z�X�͎��Ԃ�������܂����A
Python�͑��̃^�X�N���u���b�N�����A���̑����i�s�����܂��B
os.system���g�p�����ꍇ
�q�V�F�����쐬���A���̃V�F���ŃR�}���h�����s���܂��B
�t�@�C���̃T�C�Y���傫���ꍇ�A�R�s�[�Ɏ��Ԃ�������܂����A
os.system�̓R�}���h�̎��s����������܂Ńv���O�����̎��s���u���b�N���܂��B
���̂��߁A���̑����i�s�����邱�Ƃ͂ł��܂���B
os���W���[�����g�p�����ꍇ
�t�@�C���̓��e���o�C�g�œǂݎ��A�R�s�[��̃t�@�C���ɏ������ނ��߁A
�t�@�C���̃T�C�Y���傫���ꍇ�A���̃v���Z�X�͎��Ԃ�������܂��B
�������APython�͑��̃^�X�N���u���b�N�����A���̑����i�s�����܂��B
subprocess���W���[����run�����g�p�����ꍇ
�t�@�C���̃T�C�Y���傫���ꍇ�A�R�s�[�Ɏ��Ԃ�������܂����A
subprocess.run�̓R�}���h�̎��s����������܂Ńv���O�����̎��s���u���b�N���܂��B
���̂��߁A���̑����i�s�����邱�Ƃ͂ł��܂���B
subprocess.run�́A�f�t�H���g�Ŏq�v���Z�X�̕W���o�͂ƕW���G���[��
�e�v���Z�X�Ƀ��_�C���N�g���܂��B
���̂��߁A�R�s�[���ɃG���[�����������ꍇ�A
�G���[���b�Z�[�W�͐e�v���Z�X�ɕ\������܂��B
subprocess �� popen �ƂƂ��Ɏg������
run �Ȃ�Ă����� subprocess �̈Ӗ��Ȃ�
���S�҂��������R�͗ǂ��Ȃ�
��Ȃ����[�Ȃ�
���������������g���ꏊ������
>>864 �ڍׂɂ��肪�Ƃ��������܂�
�葱���̏������O�サ�������̂�
shutil����os.system��subprocess���g���ׂ��Ƃ��������ł��傤��
Windows�W���̃R�s�[���o�C�g��ǂ�Ńo�C�g�������Ƃ����d�l�Ȃ̂ł��傤���H
���݂܂���AWindows�W���̈ړ����@�ł�
������͓����h���C�u�Ԃ̃t�@�C���ړ����ƈ�u�ŏI���̂œǂݍ��ݏ������݂͂��Ă��Ȃ��̂��ȂƎv�����̂ł���
�v���O�����̓��삪�x���Ȃ�̂�IO���l�܂��Ă�ꍇ���唼�Ȃ̂ŁA
�{�g���l�b�N������100%�����悤�ɒ��߂���Ƃނ��������Ȃ�
�t�@�C���̃R�s�[�͒x���������݂ł܂��������ĂȂ��̂ɐ�ɐi�ނ��Ƃł���ɑ����Ȃ�
>>868 �����h���C�u�Ȃ�t�@�C���̒��g���ړ������킯�ł͂Ȃ��A�ǂ��Ɋi�[����Ă��邩�̈ʒu����ς��邾�������瑬���B
�R���X�g���N�^�̈������ăL�[���[�h�t���ɂł���?
���A�ł���
����������������
�������Ă�����ȃT���v����������o���Ȃ��̂��Ǝv����
�P�ɕ����̕ϐ�����ɑ��˂����A�Ƃ��������̗��R�ŃN���X����鎞�ɁA
�R���X�g���N�^�ɒl�����炸����ׂēn�����ƂɂȂ邯�ǁA
����������ŊǗ�����̂͂ǂ��l���Ă����������Ǝv���Ă�
���������̂�struct�g���Ƃ�������
C���ꂾ��struct�����ǁApython�̂̓o�C�i���f�[�^�������z�Ȃ̂ł�
>>873 ���X�g���A���p�b�N�œn���X�b�L��������
>>873 dataclass�Ŋȗ����ł���
�ʒu�����Ƃ��ēn���ꂽ�����͊����̏����̕ϐ��Ƃ��Ă͉��Ƃ������O�œn����Ă��ł��傤���H
�����I�Ɋ��S�ɖ����ł����H
�t���[���̒��ł͉����͕t���Ă�H
���ڂ��������������������B
�@Python�̃��C�u����xlwings�ŁA�s�{�b�g�e�[�u�����X�V�������Ǝv���Ă��܂��B
�A���AFILE.xlsx�ɂ́uSheet1�v�Ƀf�[�^�A�uSheet2�v�Ƀs�{�b�g�e�[�u��(Pivottable1)�����͂���Ă��܂��B
�B�ȉ��̂悤�Ƀv���O������g�݂܂����B
import xlwings as xw
app_excel = xw.App(visible = True)
wbook = xw.Book('FILE.xlsx')
wbook.sheets['Sheet2'].select()
wbook.api.ActiveSheet.PivotTables('Pivottable1').PivotCache().refresh()
wbook.save()
wbook.close()
�C�G�N�G���͗����オ��̂ł����A�s�{�b�g�e�[�u���͍X�V���ꂸ�ɂ��̂܂~�܂��Ă��܂��܂��B
�ǂȂ��������������Ē����܂��ł��傤���B
Python��3.10�AWindows10���g�p���Ă��܂��B
��낵�����肢���܂��B
import xlwings as xw
# Excel�A�v���P�[�V������\�����Ȃ��ꍇ�́Avisible=False�ɐݒ�
app_excel = xw.App(visible=False)
try:
# ���[�N�u�b�N���J��
wbook = xw.Book('FILE.xlsx')
# �V�[�g2��I��
sheet2 = wbook.sheets['Sheet2']
sheet2.select()
# �s�{�b�g�e�[�u�����X�V
pivot_table = sheet2.api.PivotTables('Pivottable1')
pivot_table.refresh()
# ���[�N�u�b�N��ۑ�
wbook.save()
finally:
# ���[�N�u�b�N����AExcel�A�v���P�[�V�������I��
wbook.close()
app_excel.quit()
�R�R�ŕ������AI�Y�킵��������������
excel �̘b��� �uexcel python �X���v �ł���Ăق�����
python����excel�ւ̃A�v���[�`��xlwings��openpyxl��2�������āA
openpyxl��python�̓��e�����ǁAxlwings�͂���excel�Ƃ�����VBA�̓��e�Ȃ��
�ǂ����Ă��ʖڂȕ����ȊO��openpyxl�Ŋ撣������K���ɂȂ��
�����肪�Ƃ��������܂��B
�������������Ƃ���ɂ���Ă݂܂�����
�u�E�Eobject has no attribute 'refresh'�v
�upywintypes.com_error: (-2147352570, '���O���s���ł��B', None, None)�v
�ƃG���[���o�܂����B
����ȍ~�́uexcel python �X���v�Ŏf���Ă݂܂��B
���萔�����������܂����B
pandas���ʂ�excel�̋@�\�������Ă��ł͂Ȃ��āAopenpyxl�̃��b�p�[�Ȃ���
������pandas��ʂ��ƃC���f�b�N�X�Ƃ��t�����ςȃf�[�^�\��������Ȃ��Ƃ����Ȃ��Ȃ�
���̃G���[�Ńs���Ɨ��Ȃ��Ȃ�VBA�ł������낤
�s���Ɨ���Ȃ�A���������Ԃ炸�A�����Ă�����Ɨǂ�����Ȃ��B
5ch�Ŏ���҂̐����Ƃ��l����K�v�Ȃ�
�ǂ�ȓz��������Ȃ�����
����Ȏ���������Ȃ��́H
�s���ǂ��^�����x��w
�G���[���b�Z�[�W
object has no attribute 'refresh'
# �s�{�b�g�e�[�u�����X�V
pivot_table = sheet2.api.PivotTables('Pivottable1')
pivot_table.refresh()
>>893 ������Ȃ��đ��k�ɗ�������ɁA�����������t�𓊂���Ӗ��͂���̂��ȁB
> ����Ȏ���������Ȃ��́H
> �s���ǂ��^�����x��w
>>894 �������炨�O��������ςޘb����
�����Ă��Ȃ��ƌ������Ƃ͂��O���������ނȂ�
>>893 �ʂ̐l�ł������肪�Ƃ��������܂�
���ɏh�肾�낤���Ȃ낤�����ʂɉ�����������@
>>891 ���������������Ă����Ă�Ƃ����������܂����ɂ���������
�҂��^����e���Ȃǐ��E�K�͂Ō���������m��Ă�
���V����ĂȂ����
�Ȃ�ł�����ł�������������ƍ������Ă悤��
���V�̊���ꂪ�E�E
�݂����Ȃ��Ƃł���
����A���ʂɃL����
AI�ɑ��Ă��Ȃ�ł�����ł��������
�Ƃ������Ă���
�����鋳���Ȃ��̘b�������̂��A�A�A�H
30��Python�o�J�`�����j�͋������̔ƍߎ҂ł��I
���Ȃ��̋߂��ɂ��܂��I
����Ƒc����̌ːГ��{���o�����܂��傤�I
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
�u^�N�\�`����w$�v��NG���[�h�o�^����
30��Python�o�J�`�����j�͋������̔ƍߎ҂ł��I
���Ȃ��̋߂��ɂ��܂��I
����Ƒc����̌ːГ��{���o�����܂��傤�I
�X����̓`������
�X����̓`������
�X����̓`������
�X����̓`������
�X����̓`������
30��Python�o�J�`�����j�͋������̔ƍߎ҂ł��I
���Ȃ��̋߂��ɂ��܂��I
����Ƒc����̌ːГ��{���o�����܂��傤�I
�N�\�`�����́A
�����Ȃ�I�����U�����͂��߂��B
���R���킩�炸�A�ߋ��̏������ׂ݂Ă݂�ƁA
�u�n���ł��`�����ł��v�Ə������̂��������Ƃ킩�����B
�������A���{�l�Ȃ�m���Ă邪�u�n���ł��`�����ł��v��
�`�����͊؍��l�̂��Ƃł͂Ȃ��I
���A���̃N�\�`�����̓I�����؍��l�����ʂ����Ɗ��Ⴂ���āA
�җ�ɂ�����U�����͂��߂��B
�����āA���ꂪ�������J�n�����킯���B
���ꂪ�S�Ă̎n�܂�B
�`�����͏����̍����I
�܂�����Ȃ��Ƃ���Ă郄�c�������
�d���Ɋ������Ηǂ��̂�
���̃N�\�`�����́A
�������N��������U���������Ă���킯���B
�����̊��Ⴂ����l���U�����Ă����āA
�܂��ŕ��`�������Ǝv�����B
�`�����͂����Ȃ�B
�����玟�ɒn�k�̂������Ƃ����A
�`�����͓��{�l�������E�s�E���邾�낤�ȁB
������`�����͊F�E���ɂ��Ȃ���Ȃ�Ȃ��B
������o���Ă������Ƃ��I
>>910 �����[���e�[�}��^����Ώ���ɍs������݂���������
�l�ɕ����Ȃ��ƂȂ�ɂ��ł��Ȃ����O����R�C�c�̕�������ۂǎg���邾�낤
����͌��X�A���ʂ͂�����I
�Ƃ�����`�������B
���̂���ɍ��ʔ���������܂�
�U������������A
�܂��A����ׂ����ݔS�������ȂƊ��S����B
���ׂĂ݂�ƁA���ꂪ�`�����̐����炵���B
����Ō��S�����B
����͎��ʂ܂Ń`���������ʂ��邼�A�ƁB
�`������S�������ɒǂ��Ԃ��܂Ő킢�܂��I
�V��@������A�V��@������ƞH�킴��҂́A��V��@���Ƃ�����Ȃ��̂�
�ƌÐl�͌����܂����B������Ȃ����͐ϋɓI�ɐu���܂��傤�B
����͌��X�A���ʂ͂�����I
�Ƃ�����`�������B
���̂���ɍ��ʔ���������܂�
�U������������A
�܂��A����ׂ����ݔS�������ȂƊ��S����B
���ׂĂ݂�ƁA���ꂪ�`�����̐����炵���B
����Ō��S�����B
����͎��ʂ܂Ń`���������ʂ��邼�A�ƁB
�`������S�������ɒǂ��Ԃ��܂Ő킢�܂��I
Python���Ȃ�܂��u���d�p���v�ȁI
�Ȃ����d�p�����Ƃ����ƁA���R���ꏈ���ɂ����Č��̈Ӗ��́u�����v�ɂ���ĈقȂ邩�炾�I
���Ӌ@�@�s���Ӌ�
�@�@↖�@�@�@↗
�@�@�@�`���|
�`���R�̐��Ӌƕs���Ӌ�
http://d.hatena.ne.jp/tottokotokoroten/20130516/1368716650
https://mobile.twitter.com/daikidomon/status/1385368820240437248
�y���M/Daiki Domon
@daikidomon
Python�̑��d�p�����킩��Â炢�B
�p���N���X�̍��̃N���X�����w��Ƃ����������B
https://twitter.com/5chan_nel (5ch newer account)
https://twitter.com/5chan_nel (5ch newer account) ���d����Ȃ��p������ǂ݂ɂ����Ȃ�?
���d�p���Ƃ����Ɏg���̂��z���������pathlib���K�b�c������Ă�炵����
���Ɏg���́H
�ق�Ƃɑz�����Ȃ�
�N���X���W���Ƒ����Ĕr���łȂ��������������ƂƂ�����Ȃ��邩�H
���[���[���ʃ_�C�������h�p�������~
����q�����������m�̓������
d1 = {"a":{"aa":1},"b":2,"c":{"cc":{"ccc":3}}}
d2 = {"a":{"aa":1},"b":2,"c":{"cc":{"ccc":3}}}
�L�[�ƒl�̑���������̂��m���Ȃ낤����
if d1==d2�ł�����ˁE�E�H�Ǝv���Ăӂƒl���C���X�^���X�������ꍇ������Ă݂���
class Hoge:
�@def __init__(self,a):
�@�@self.a=a
d1 = {"a":{"aa":1},"b":2,"c":{"cc":{"ccc":Hoge(10)}}}
d2 = {"a":{"aa":1},"b":2,"c":{"cc":{"ccc":Hoge(10)}}}
d1==d2 # False
False������
�����̒l���A���� or ���X�g or str or int or boolean or None�������Ȃ�
���đO���������d1==d2�ł������E�E
json.dumps(d1)==json.dumps(d2)���Ă̂��ǂ����ł݂����Ƃ��邯�ǂȂ����b�g����̂�����
==�͓����I�u�W�F�N�g�Ƃ����Ӗ�������
�C���X�^���X�͕ʂ̃I�u�W�F�N�g
>>919 class Hoge(int):
def __init__(self,a):
self.a=a
d1 = {"a":{"aa":1},"b":2,"c":{"cc":{"ccc":Hoge(10)}}}
d2 = {"a":{"aa":1},"b":2,"c":{"cc":{"ccc":Hoge(10)}}}
print(d1==d2) # True
d1 = {"a":{"aa":1},"b":2,"c":{"cc":{"ccc":Hoge(1)}}}
d2 = {"a":{"aa":1},"b":2,"c":{"cc":{"ccc":Hoge(10)}}}
print(d1==d2) # False
Hoge��l�Ŕ�r�������Ȃ�__eq__��__hash__��������dataclass�I�Ȃ��̂����p���邩
>>919-920 ==�͓����I�u�W�F�N�g�Ƃ����Ӗ��ł͂Ȃ�
x1 = {"a":{"aa":1},"b":2,"c":{"cc":{"ccc":3}}}
x2 = {"a":{"aa":1},"b":2,"c":{"cc":{"ccc":3}}}
print(x1 == x2)
print(x1 is x2)
class Hoge:
def __init__(self,a):
self.a=a
d1 = {"a":{"aa":1},"b":2,"c":{"cc":{"ccc":Hoge(10)}}}
d2 = {"a":{"aa":1},"b":2,"c":{"cc":{"ccc":Hoge(10)}}}
print(d1 == d2)
print(d1 is d2)
�悤�͑����b��
Hoge�������삾�����肵���Ƃ���
__eq__�Ŋg�����Ƃ��A��������for�Ƃ��ʼn��肹����
d1==d2�����ŃC�P����Ă��Ƃł����̂�
�킴�킴__eq__���������������dataclass�̂ق��������Ǝv��
��Paiza�����
��ʂ�I��������发�Ƃ��āA����Python3 ��2�ł����Ǝv���̂ł����A���ɗǂ��̂�������Ă�������
python��{�ŕ�����Ƃ������z����������
�{�ǂނƗǂ���
�߂����ዻ�����邵�G���{�ƕς���
�v�������Ȃ�APerfect series ���ǂ����ǁA
�p�[�t�F�N�g Python [����2��] (PERFECT SERIES 5)�A2020
����2�� �p�[�t�F�N�gRuby�ARuby�T�|�[�^�[�Y�A2017
�p�[�t�F�N�g Ruby on Rails �y��������Łz (Perfect series)�A2020
>>933 �l�^�Ƀ}�W���X���邯��
������perl����Ȃ���H
ROR����GPL�ɉ�������Ďg���Ȃ��Ȃ������ĕ�����
>>929 paiza�͊w�K�R�[�X�������{�Ȃ�ėv���
>>929 �{�Ŏd���ꂽ�m���Ȃ�ĕ��̖��ɂ�������
IT�͎��H����̂�
���p�ɂȂ�R�[�h�������܂����ē������܂���
effective python�͂��܂ɊJ���Ďh���Ă�
�{�Ŏd���ꂽ�m�������H�������
�{����ǂ�ł��Ȃ�ɂ��Ȃ�Ȃ���
�{��ǂ܂Ȃ��͔̂n��
�]�v�ȋ�J�������ׂ̏�肢�������ɔ[������ɂ́A
��x�͗]�v�ȋ�J�����Ă�K�v��������
Python�͖{���T�C�g�g���Ȃ��������̂��ǂ���
Python�`���[�g���A����ǂ݉������͂�����l�Ȃ�K�v�Ȃ�����
��������Ȃ��Ȃ�A�̌n�I�m����g�ɂ���ɂ͓��发�ǂނ̂�����
�Ƃ������x�X�g
Paiza�̓���R�[�X�I�����Ȃ牽������Ă݂��炢���̂�
���Ă������A�܂�����
�ŁA�{��ǂ�ł����Ƃ������@��m��
���ЂŌ�������G�a�V�X�e���́w���H100�{�m�b�N�x�͂ǂ���ǂ�����
O'Reilly����ԂȂ낤��
Effective Ruby �͗ǂ��B
�o�O���N���ɂ����A���S�Ō����I�ȃR�[�f�B���O�ƁA
�ԈႢ�₷���|�C���g�����
Effective�V���[�Y���A���{�l�̒��҂����邩��A�C��t����B
�uEffective Modern C++�v�̌��c�EScott Meyers �ƊW�Ȃ��̂ɁA
Effective�ƕt���Ă���{������
���̓_�AEffective Ruby�́AMeyers�Ƀ��r���[�����Ă�����Ă���B
Effective Python �͒m��Ȃ�����
effective perl�͓ǂ�ł�Œ���perl�ɑ��鋻���������Ă��܂���
T,o,k�i���f�Ƃ������́������ځ[�Ă��������B�j
�Ƒ��ɏЉ�鑤�ɂȂ�A�����ā�4000�~�l����GET�I

�����ŏ����͎̂��Ԃ̖���
����ChatGPT�ɂ���ȃR�[�h���~�����ƕ����Έ�u�ŏ����Ă����
�v���O���}�ɂ͂��͂�R�[�h�������\�͂͋��߂��Ă��Ȃ�
ChatGPT�̎d�g�݂�m��Ȃ��ƁA�����Ă����������Ǝv���Ă��܂����
�ߋ��ɒN�����������R�[�h�̊ۃR�s�[�Ȃ炤�܂������Ƃ�������
�ȒP�ȎZ������ԈႤ�z�ɘ_���I�v�l�����҂���̂��ԈႢ
>>949 ����
>>953 ����
ChatGPT�����グ�Ă�A���͕��n�n������
Python�����n�߂����NJ��\�z�ɂ��Ē��ׂĂ邾���ł����Ƃ����ԂɎ��Ԃ��n���Ă��E�E�E
>>956 ���\�z�͏o������肷���
�E�g���c�[���̓e�L�X�g�G�f�B�^�ƃR�}���h�v�����v�g�̂݁BVSCode�Ȃnj��ꓹ�f
�E�O�����C�u�����͈�؎g��Ȃ�
���̓�����g���u���̂Ȃ�Python���C�t�𑗂邱�Ƃ��ł���
>>957 ���ꌾ��̏��w�҂ɂ͗ǂ����낤����
�Ɩ��Ŏg���Ȃ璴����v���C����Ȃ��H
�܂�excel�ǂݏ������W���[���̓��삩�炾��
>>958 �Ɩ��Ȃ���\�z�̋K���菇����������Ă��邾�낤�������̐^����������������
���w�҂����͂ňꂩ����\�z���Ă̂͂��܂�ɖ����Q�[
�Ƃ肠����VSCode��devcontainer�𗘗p���Ċ��\�z��
�p�b�P�[�W�Ǘ���poetry���Ă̂��g���Ă݂邱�Ƃ�
mac��python�����l���������
mac�̐l���R�[�h�����Ƃ��S�R�C���[�W�����̂�
�ӎ������n�v���O���}�[�͊Fmac�g���Ƃ邾��
���̌���̐l��mac�g��Ȃ��̂ɁA���̂�python����mac����
YouTube �ŗL���ȎG�H�n�G���W�j�A�EKENTA �̃x�X�g�Z���[�{�A
�u21���I�ŋ��̐E�� Web�n�G���W�j�A�ɂȂ낤�v�ɂ��A
Web�n���ЊJ����Ƃ́A������Mac ���g���āA
Ruby on Rails �ŊJ������ƒ�`���Ă��邯�ǁA
YouTube��Rails�̑��l�ҁEDeanin �́AWSL2 �ŊJ�����Ă���B
VSCode, React, Docker �Ȃǂ��g��
BeautifulSoup��find����̂��A�g�킸�ɐ��K�\���Ń��X�g�ɂ���̂��A
�K�w��H���Ă�������{���I�ɂȂ���ς���ȂƎv���Ă����ǁA
select���ƈꔭ�ōs�����
���XCSS����b��������
CSS Selector �̏������ł���H
jQuery �ł�����H
�^�O #ID .class �����o���āA> �ŘA�����邾��������1���Ŕ���
flask������Ȃ��ǁA������ĐÓI��html��\���������Ƃ��A
return render_template('hoge.html')
�����̊���html�t�@�C���̐��p�ӂ��Ȃ��Ⴂ���Ȃ��̂��ȁH
>>973
�e���v���[�g�G���W���ł�����
���͐��`�i�e���v���[�g�j�ƂȂ錊������base.html�Ƃ�����čė��p�ł���悤�Ȏd�g�݂ɂȂ��Ă�
�C���[�W
base.html��
<html>
�@{% block head %}{% endblock %}
�@<body>
�@�@{% block body %}{% endblock %}
�@</body>
</html>
hoge.html��
{% extends "base.html" %}
{% block head %}
�@<title>hoge�^�C�g��</title>
{% endblock %}
{% block content %}
�@<span>hoge�R���e���c</span>
{% endblock %}
���� hoge.html
<html>
�@<title>hoge�^�C�g��</title>
�@<body>
�@�@<span>hoge�R���e���c</span>
�@</body>
</html> �ŁA�������Ⴆ�Έ����Œl��n�����肵�ē��I�ɐ����ł���
return render_template('hoge.html',{"title":"hoge�^�C�g��","content":"hoge�R���e���c"})
flask�ł̂����͂����Ă邩�ǂ����͂����
��̂ǂ������
���̓f�[�^�x�[�X�̃��R�[�h�̒l��n����
�e���v���[�g���œW�J���Ă��������ÓI��html�ɂ݂���A�݂����Ȏg�������Ǝv��
jinja2�g���Ȃ�f�[�^�x�[�X��select�ŕԂ��Ă����I�u�W�F�N�g�����̂܂܃e���v���[�g�G���W���ɓn�����͂�
�v���O�����͂���Ղ�Ղ�ő��̐l�̏������R�[�h���������炢�����o���Ȃ��҂ł�������ǂ��ł���
�R�}���h�v�����v�g�������Ĉ�T�Ԉȏ�O�܂ł͓����Ă����R�[�h��(�����܂Œ����Ă�15�����炢)
��ӋN��������S���i�܂��^�C���A�E�g����悤�ɂȂ��Ă��܂��܂���
���̕ω��Ŏv��������߂������ӂ�Ƀp�\�R���̍X�V�������炢�ł�
�X�V��R�[�h�������Ȃ��Ȃ���Ă���܂����H
�X�V��python��v���O�����Ŏg���Ă��郉�C�u�����̃o�[�W�������X�V����ē����Ȃ��Ȃ邱�Ƃ͂���
�������ꂪ�����Ȃ�A���̃v���O�����Ŏg���Ă��郉�C�u�����̃o�[�W���������킩��Ȃ�Ƃ��Ȃ�
README����Ƒ��́u���̃o�[�W�����g���āv�Ə����Ă���
>>978 �������܂���
���C�u�����̃o�[�W�����m�F�d���킩������o������ēx���₳���Ă��炢�܂�
�G���[���b�Z�[�W�ǂ߂Ȃ��́H
�܂�����ǂ܂Ȃ���
�t�@�C���̓ǂݏ����̑�����������̂ł���
�Ԉ���Ă��V�X�e���Ɋւ��悤�ȏd�v�ȃt�@�C���͏����Ȃ��悤�ɂ������ł�
Windows�ŃX�N���v�g�������Ƃ��āA�X�N���v�g�Ƀx�^��������Ă���p�X������𑽏��������Ă��J�����g�f�B���N�g�����ɓ������Ȃ��A�V�X�e���t�@�C���������Ȃ��悤�Ȑݒ�ɂ���ɂ͂ǂ�������悢�ł��傤���H
�Ǘ��Ҍ����̂Ȃ��A�J�E���g�œ��������Ǝv���Ă���̂ł����A���ꂾ���ł͑���Ȃ��ł��傤���H
�Ǘ��Ҍ����̂���A�J�E���g�œ������ꍇ�ɂ͂ǂ̂悤�Ȉ��S�l�����܂��ł��傤���H
���₷��O�ɂԂ����킵�Ă��������ōD���Ȃ�������Ă݂���?
�����������̂����m��B
>>982 �Ǘ��Ҍ����̂Ȃ����[�U�[�Ŏ��s����A�ň����[�U�[�t�@�C�������������Ȃ�܂łɗ��܂�Ǝv��
�{���ɕs���Ȃ�VM�Ƃ��R���e�i�Ƃ�Colab�Ŏ����Ƃ����������
open�����b�v���Ă��ꂾ���g��
�Ⴆ���l�[������Ȃ�from to��print���Ċm�F���Ă��烊�l�[������Ȃǂł��邱�Ƃ͂���
�������~�X���Ȃ��悤�ɂ������̂��A���ӂ̂���N�����������Ƃ��ł��Ȃ��悤�ɂ������̂�
>>978 �����b�ɂȂ��Ă܂�
�m�F�����܂����Ƃ��남���炭����Python��3.10.6�œ����Ă�������Python��3.10 64-bit�ł����A���ꂪ�����ł��傤��
���Ǝg�p���Ă���R�[�h��note�Ō��J����Ă������ŁA�N���E�h��modal��Hugging Face�Ŕ��s�����g�[�N�����g�p���Ď��s���Ă��܂�
>>981 �G���[���b�Z�[�W�͎����ŕ�����͈͂�
�^�X�N�̏�Ԃ��^�C���A�E�g���܂������x�ɂ����킩��Ȃ���
�X�^�b�N�H�ɂ�Python�̃t�H���_��������Python�̃o�[�W����������Ȃ��Ȃ����̂��Ǝv������ł��ł����ǂ��ł��傤

�p�\�R���̍X�V���ċ�̓I�ɉ��ł���?
>>988 �킩���Ȃ炻�̂܂܌����{�b�N�X�ɓ����邩chatgpt�ɕ���
hugging face���牽���傫���T�C�Y�̃��f���_�E�����[�h����6000s�^�C���A�E�g�����Ƃ��ł͂Ȃ��āH
���������ł���ΑS�\�[�X�R�[�h����"6000"���Đ��l������Ή��}���u�ɂ͂Ȃ邩��
�ڂ����͌��ĂȂ����ǂ�����ӂȂ����悤�ȏǏ�ۂ�
�Ԉ���Ă��炷�܂�
https://zenn.dev/link/comments/b1a978d1a65058 >>992 ���肪�Ƃ��������܂�
�����ł�������̊Y���L�������Q�l�ɍ쐬���Ă܂���
�����lj��@�\������ۂɉ�������傫�ȕ����_�E�����[�h���Ă���̂��Ǝv���܂�
�����Ă����������Ǐ�̕��ƏǏ�͈Ⴂ�܂������Ԃ̘M����͌����Ƃ��ċ����̂ŏ�����܂�
���Ԃ�L���čēx�`�������W���Ă݂܂�
�Ȃ炱��ȃX���łӂ��肵��������������stable diffusion�̃X���ŕ���������������Ȃ��H
�����悤�Ȍ��ۂɑ��������l�����邩������
>>994 ���݂܂���
�v���O�����m���ɒ������l������̕����������Ǝv���Ă�����ő��k�����Ē����܂���
>>977���x�̏��ł̓v���O�����m�����ւ���������Ȃ���
�������̂�G���Ă�l�B�̃m�E�n�E�̕�������ۂǗ���ɂȂ�
�����X���Ȃ�Python�S�������Ȃ��l�̎���͗��ɔ������ׂ��łȂ�
lud20250104044902caID:MxLxGpNx0�̃��X�ꗗ�F
>>853
��min(i, max_prm_index)��prms��2����items��4���̂Ƃ�����
�����>>846�́�prms��items�Ɠ���������
�Ƃ͈Ⴄ�����Ȃ����ݒ肵�����[�����Ǝv��
�����ƃ��[�v�������̓C�e���[�g�̂��Ƃ��ċA�ƌĂ�łȂ��H
�Ȃɂ���肪�H
���ŏ����番�����ق���
�S������Ă��ƁH
���ꍇ�����K�{
����@����ɁA�Ⴆ��
if items��prms�̃`�F�b�N:
�@if prms�����̏ꍇ and :
�@�@for item in items:
�@�@�@�����ɏ���
�@elif prms�ЂƂ̏ꍇ:
�@�@for item in items:
�@�@�@�����ɏ���
�݂����Ȃ��Ƃ��낤���H
�b�͂���邯�ǑO�����������ł��������̋^�₾��������
if items��prms�`�F�b�N:
�@raise
if ����:
�@pass
else:
�@pass
�݂����Ȃ��Ƃ��Ă��Ȃ��ق����ǂ��̂��낤���H
>>846�ł͈Ӑ}�I��if items��prms�`�F�b�N:rase
�̕������i����ȍ~�̏����ɊW�Ȃ��̂Łj�ȗ��������� ���X�F1-200 201-400 401-600 601-800 801-1000 ALL
���̃X���ւ̌Œ胊���N�F http://5chb.net/r/tech/1677856680/
�q���g�F5ch�X����url�� http://xxxx.5chb.net/xxxx �̂悤��b�����邾���ł����ŃX���ۑ��A�{���ł��܂��B
TOP�� TOP�� �@
�S�f���ꗗ ���̌f���� �l�C�X�� |
Youtube ����
>50
>100
>200
>300
>500
>1000��
�V���摜
�@���uPython�̂��� Part70 YouTube����>1�{ ->�摜>11�� �v�������l�����Ă��܂��F
�EPython�̂��� Part5
�EPython�̂��� Part46
�EPython�̂��� Part49
�EPython�̂��� Part67
�EPython�̂��� Part51
�EPython�̂��� Part63
�EPython�̂��� Part74
�EPython�̂��� Part68
�EPython�̂��� Part75
�EPython�̂��� Part76
�EPython�̂��� Part72
�EPython�̂��� Part62
�EPython�̂��� Part62
�EPython�̂��� Part57
�EPython3������̏��S�҂ł���
�EPython�����悤�Ǝv�����A���ۂǂ��Ȃ�H
�E�y����IT���zVue��Webpack��Python3�c�c�w���s�̋Z�p�x�������K�v���Ė{���ɂ���́H���ǂ�邱�Ƃ͐�PHP��Java+Servlet�ƈꏏ���
�EPythonista�����X���yiOS�ŕ��ł���z 2 (3)
�EPython2�I���̂��m�点
�E�m��E�C�O�h���}�ʼnp��̂��� Part14 [���f�]�ڋ֎~]
�E�m��E�C�O�h���}�ʼnp��̂��� Part15 [���f�]�ڋ֎~]
�E�y���U�ɍł��z�}�E�}�E�̂�������2�y�߂��X���z
�E�y����zThe QABALISTIC TAROT�y�{�G�k�zPart6
�E�y�p�앶�z�}�E�}�E�̂��������i���U�ҁj3�y�������ԁz
�E�yTAC 2022�N���i�ڕW�s�����m�u���z�s�����m�����̂���
�E�y���͍��i�H�z�}�E�}�E�̂��������i���H�ҁj7�y�s���i�H�z
�E��k�����Ɂu���n�������̂������Ă�v�Ǝv���Ă�z�����������ăr�r���ȁB���̍�������Ă�
�E�y���w���z���ꂳ��ׂ̈̂����u��151204�y�����z (c)2ch.net [���f�]�ڋ֎~]
�E�����H��̎В��@���w�҂̐e�Ɂu�����ƕ����Ȃ��Ƃ��̂�������݂����ɂȂ���v�ƌ�����
�E�y������i����̂��m�点�z�M���Ɍ����āu�E�S�X�܂ŕ��� �E�Ď��J�����Ŋm�F���� �E�X�}�z�������֎~�v
�E�C�O���Ăǂ��������ɉp������Ă�́H���{�l�����p�꒝��Ȃ��̂�������������āI�����̂��߂̉p�ꋳ�������I
�EPyQt5 Python
�EPython���S�҃X��
�E�y�}��z�p��̕��@
�EPython�������ȗ��R
�E���E�j���@part13
�EPython4�n�Ɋ��҂��邱��
�Epython�ɏڂ�������Ă���
�Epython�ɂ��Ă�������
�EPython������Ă݂悤�Ǝv��
�EPython�}�X�^�[������
�EKivy Python���C�u����
�E�v���O���~���O�̕��@
�E���w�̕��̎d�� Part229
�E�v���O�����̕���������
�E��w��python���Ă���炵����
�E��������Python(�����S�җp) ����29
�E����Python��B����ɂ͉�������悫�H
�E�p��̕��̎d���y���X���b�h�z
�E�p��b �p����nYoutuber Part4
�E�v���O���~���O�������������
�E��������Python(�����S�җp) ����32
�EPythonista�ȃl���[���܂����H
�E�����̎Q�l���E���̎d��Part122
�E�p��b �p����nYoutuber Part 2
�E�d�ʑ�u�]�����Ǘ��N�̕��\��]�����Ă�
�E��������Python(�����S�җp) ����37
�E��������Python(�����S�җp) ����34
�E��������Python(�����S�җp) ����39
�EPython�P���������������^��������
�E���S���o�����v���O�������������
�EPython�グVBA�������Ă�C���������z��
�E��������Python(�����S�җp) ����48�y�܂�1�Łz
13:25:31 up 15 days, 4:47, 0 users, load average: 19.98, 20.74, 22.07
in 0.03764796257019 sec
@[email protected] on 110703
|



