>>4
オブジェクト指向の何たるかをきちんと理解していれば、概念として使えなくはない。
もっとも、C 言語に限った話ではないけど。 >>4
原則、C言語ではclassは使えない。
そもそも、CをOOPの概念に対応させようとして、
classの概念(classというキーワードも)を追加したところから
始まったのがC++。 >>4
Win32API?
C++以前から(純粋OOPLな)smalltalk的な価値観をC言語に押し付けた結果。 テンプレートをテンプレートクラスで特殊化したい場合ってどうするの?
次スレから>>2に登場人物を列挙してはどうでしょうか? VS2019来てるじゃん
まともなメモリ使用量になってる奇跡だ
C++erはVS毛嫌いする人も多いけどVS2017あたりからC++対応もマジでかなり良くなってる
一番使えるIDEなのに毛嫌いする人はいないと思います。
4/2を選んだのはエイプリルフールを避けたからかな。
>>16
そう言う輩はプログラマーではなく言語オタか、最新規格対応の入門書売って糧を得てる様な奴だけ。 最近はCMakeに優しいけど標準的なビルドシステムに優しくない
clのオプションが独特すぎる
Linuxで動かない
Windows上でのライブラリの取り回しが悪すぎる
wslやらvcpkgでだいぶましになったとはいえまだ若干抵抗がある
VS2017以前よりもコンパイルが速くなっている気がする。
色々細かい不満は出てくるかもしれないが、完全に乗り換える価値は十分ある。
私はVS2017をアンインストールして退路を断った。
わかりにくかったので訂正。
VS2019はVS2017よりもコンパイルが速くなっている気がする。
デフォルトでスタックメモリ消費の静的解析をしてくれるので、
10KB以上のバッファをスタックからとるクセのある人は、
C++のstd::vectorなどへの置き換えを考える良い手助けになるなのでは。
つか、プラットホームに依存しないような
プログラミングをかける奴なんてほとんどいないだろ
素人が書いたようなおもちゃをなんで他に移植しなきゃいけないんだよ
hppファイルに実装を書いてることがたまにあって、すごく違和感があるんですけどどういうメリットがあるんですかね?
配布が容易
宣言と定義が分かれないから読みやすい(人による
宣言と定義が分かれないからリンケージとかの罠にはまりづらい(場合によってはむしろODRの罠にはまる
翻訳単位が大量にある状況ではヘッダに実装したうえで少数のcppからインクルードした方がコンパイル速い
テンプレートの場合はほぼそうせざるを得ない
などなど・・・
そもそもhppファイルは実装書くためのファイルじゃないの?
templateとかで、分割コンパイルできない場合の
もしかしてhppをhとcppの間の子みたいに思ってる?
Cのヘッダと区別するためにhppにしてる人がいるだけでただのヘッダ拡張子だぞ
VCだとヘッダはhになるけど
流儀なんか10年もしたらガラっとかわるから拡張子なんか好きにやれ
c++ではじめの頃の昔はたまにソースを .c++ で書いてるやつもいた
ファイルパスにプラス記号使うのは、文字コード自動判定でUTF-7と誤認されやすくなるからさけたほうがいいね。
>>28
無理やりテンプレート使ってビルドを腐らせる典型的アンチパターンじゃねーか。 >>28
配布出来るようなコードかけるの?
誰もお前さんのなんて欲しがらないだろ >>34
ほう、すごいね、そんな方法があったんだ。
これなら、enumの定義から自動的にunorderd_mapに登録して逆変換テーブルを作るとかもできるかもね。 .hは宣言だけ、.hppは実装ありって使い分けてたこともあったけどやめた
includeする方はそんなの知ったこっちゃないし、いちいちhかhppか判断させられるのが無駄だとわかった
>>40
>hppは実装あり
それは悪手なのでは? 別に全部入りって意味じゃないよ
テンプレートとかinlineとか、処理の実装も書いてますよーっていうこと
暗黙の了解でもそんなのないだろ
hppなら少なくともC言語ではないというくらいしかない
そもそもユーザーがincludeする部分は拡張子書いてないライブラリもある
だから意味ないからやめたって言ってるじゃん
意味ないし有害だよやめた方がいいよ
そもそも素人が書いたテンプレートを用いたものなんて使い物にならん
むしろプロの方がゴミみたいなコード書いてる人多いよね
boostで開発効率上がるとか信じてるバカが世の中にはまだいるのな。
実際上がるだろ
ライブラリ使えばコーディング量減るのは当然
コーディング量を減らしたいならC++使うのやめるべき
速くてコンパクトなソフト作るのに最適だろ。
慣れてりゃ開発速度も同じようなのLLで作るのと大差ないし
言語によって作業量が増えるとか無いから
目的に合ったフレームワークがあるかどうかが重要
どうせお前らなんて、数十行程度の小さなもばっか書いて、あーでもないこーでもない言ってるだけだろ
会社にもいるわ、細かいことばっか、正論言って
実際の仕事では何にもできない、言語規格ヲタ
仕事してるより細かいとこ突き詰めてる方が楽しいんだ、ごめんね
ドワンゴでコード書いてて江添みたいなバカに
しょうもないアドバイスされたらそらキレるだろうな。
あの手の連中って小さなサンプルしか書いたことないんだろ
実際の数百万行あるようなプロジェクトなんかには
参加したことないんだろうな
弁理士みたいなもんだろ。
自分じゃモノ作らないけど複雑なルールに精通してて「それじゃ通らないよ」とアドバイスする。
>>68
c++なんかでosなんか作れるかよ
遅すぎる >>67
作らないじゃなくて、作れないんだろ
標準ライブラリの使い方を示す小さなものは作れるけど、現実的に使用するアプリケーションはかけないんだろう >>72
で数百万行で何を参加して、そのうち何行書いたの? >>74
自動機が約1000台あるCAMで40%は書いてるよ >>75
じゃあこのスレで一番C++に詳しい人は君ね どうせその数百万行のコードで意味があるのは数万行から十数万行とかだろ
後は無駄なコピペやら、標準ライブラリにある機能を知らずに毎度一から書いて水増しされた無意味どころか保守考えたら害悪にしかならんくその塊
>>72
弁理士の喩えで言えば、弁理士自身が発明できなくても別によくね?って話なんだが。 どうせ納期に追われて妥協に妥協を加えたやっつけのコードを○行書きましたwとか言われても自慢にもならん
>>78
ダメだぞ
弁護士は立法の経験が無いとダメだしスポーツの評論家は一流アスリートじゃないとダメだし調理器具を作る人は繁盛してるレストランで勤務したことがないとダメw
ライブラリ開発や教材の執筆には数百万行のシステム開発と組み込みの経験が無いとダメw
ちなみに数百万行のシステム開発や組み込みの経験があると自動的にライブラリ開発者や教材の執筆者より現実を知ってる格上()だし現場のニーズを満たした理想のライブラリを作れるようになるぞ ビャーネなんて、ロクなの作ってないよなw
数十行程度のものをあーでもないこーでもない言ってるだけだろ
せやなw
建築物の工法の研究者なんかろくに家も建てたこともない雑魚w
ネイルガンの一つも使えないくせに机上でああでもないこうでもないって言ってるだけw
>>80
>立法の経験が無いとダメ
つまり議員の経験が無いとだめってことか STLの美しさは時代を超越してるし、オーパーツに認定してもいいのではないか。
ラムダ式使えない馬鹿「今まで書いたソースの行数は?」
そんなの気にしねえwwws
なるほどラムダ式が嫌いな奴は書く行数が減ってコードの生産量()が減るのが嫌なんだな
ボイラープレートコードを書き殴ってれば仕事したフリができる人たちは気楽っすなあ
まあ実際クヌースなんかもtexプログラム作ってプログラムの大変さに気づいた
的なことは言っているしな。
偉い人でもその辺実際に作ってみると感覚が違うってのはあるんだろう
>>68, >>77
こいつらみたいな世間知らずの根拠のない自信はどっから来てるんだろう >>90
そもそも世間知らずほど自信にあふれがちではある
初心者ほど偉そうだったりもする クソライブラリやクソ開発メソッドを持ち込む怪しいコンサルと一緒なんだよな。
それが押し通ることが結構あるから怖い世の中なんだが。
>>90
元号もろくに変えられない癖に何が自信だあほ 自分より劣る存在を想定してホルホルしててもお前の実力は上がらんよ
コードを書くしか能が無いというのでは
業界に名が通った有名人クラスにならない限り
コンサルに勝つのは難しい
>>88
それソースある?
TeXの前にも色々プログラム書いてるみたいだし、そもそも大学で俺ならもぅとうまくやれるとアセンブラとコンパイラを書き換える決心したらしいからTeXでどうのこうの言うのはちょっと考えづらい
あとTeX自体は今の基準だとそんなにでかく無い
ソースは24ks程度で半分以上はweave出処理される解説だし そんなインタビュー集までチェックするのか普通とか言われてもなぁ
>>98
自分は知らないからソースくれとだけ言えばいいところを、想像で要らんことをいうから反論されるのでは? >>99
根拠書いてあるんだから反論したいなら根拠に反論したら? なるべく高級な言語でちっさいOS作ろうと思うんだがよい言語ないかな?
armかrisc vの64bit
32bitでもいいです
比較対象のためにc/c++でも作る予定
そもそも高級言語で小さいOS作れる言語ってC言語一択じゃね?
rustでqemuでhelloworldして満足した(´・ω・`)
>>105
rustぐらいですかね?
全然違うパラダイムの言語で作れないもんかと
アセンブラとの相性考えたら結局cっぽい言語しか選択肢ないのかな OSつったって、どのレベルのこと言ってるかによってかわるしな
電源ONから自分でブートして起動できるレベルのものいってるならC+アセンブラ一択だし
ブラウザで仮想環境動けばいいぐらいなら、まあいろいろ変な言語系の実験できるけど
それ実際的な意味あるの?っていう話になってくるし・・
というわけでブラウザで C++ の実行環境を動かしてみるっていうのはどうだろう?
emscripten のオルタネートみたいな・・
>>100
事実でもなんでもない勝手な想像を根拠とか言われても反論できんわ。 >>110
> TeXの前にも色々プログラム書いてる
> 大学で俺ならもぅとうまくやれるとアセンブラとコンパイラを書き換える決心した
> あとTeX自体は今の基準だとそんなにでかく無い
> ソースは24ks程度で半分以上はweave出処理される解説だし
の中に事実でない箇所あるの? ソース出せと言った人が、ソースが出てきたら、ソース出すのは反則と言い出したって流れかな。
引っ込みつかなくなってるんだろww
話の内容変わってるし
>>109
ブラウザの仮想環境とは何?
osなのでcpuが見えてて欲しいのだけど
ひとまずqemuで始めるつもりです ビャーネストロヴストルップ先生のプログラミング入門買ったんだけど、読破した人っている?
いないんじゃあないの
本当に読破したと言える人間は日本人で20人しかいないと聞いた
>>120
毎日30分読むことにした
C++は仕事で使ったことない >>108
まずベアメタルに対応してる必要があることを考えると、選択肢はそうないのでは? >>119
もはやそれは「国語辞典」読破した奴おる?ってのに近い。 ストラウストラップの『プログラミング入門』って
日本語版で1100ページもあるんか。
このとっつぁん、厚い本を書きまくっとるなぁ。
そもそもプログラミング入門のお題でそんなに語るネタあるんか。
>>119
なんか『C++によるプログラミングの原則と実践』て本が
同じ原書の新版の和訳みたいだけど。
おまけに『ストラウストラップのプログラミング入門』よりお安い。 この界隈では「入門」といいながらどうみてもマニア向けの本が多いよね
上級者の評価が高い入門書ってのは本質や精神を理解し免許皆伝まで至るような道の第一歩であるものだもの
素人が何も理解しないままこうすればこうなるでおいしいとこだけいきなり得ようとするようなハウツー本とは違う
同価格帯のXeonとThreadripperではどっちの方がコンパイル速いか知ってる人いますか?
C++はF35にも使われている戦争の兵器
C++erを見たら悪魔の手先と思え!
それかCかC++のソースコードのコンパイルのベンチマークをCPU別で取っているサイトがあれば教えてほしいです
effective c++読めるくらいになればまあその先に薦める本や文献なんかは結構あるが、
そこまでにどういう本勧めればいいかは相当難しい。
とりあえずcからとか言いたいとこだがそれからeffective c++までの間に読む本としては何が良いのだろうか。
タイムマシンって何言語で、書かれてるの?
やっぱりc++
>>135
独習→acceleratedとプレC++11STL(ハーバードシルト)→テンプレート本、くらいを私は歩いてきました… >>135
どの言語でも、言語を学ぶ順番は、
1. 入門書
2. Effective 何々
3. 逆引き・レシピ本
4. (必要なら) メタプログラミング
Ruby なら、
1. たのしいRuby 第6版
2. Effective Ruby
3. 改訂2版 Ruby逆引きハンドブック
4. メタプログラミング Ruby 第2版
先にRuby で、1~3 を読んだ方が早いかも
もちろん他の言語でも良いけど、
プログラミング全般は、Rubyで学ぶのが、正確で紛れがないし、詳しい本が揃っている このご時世に本読んでプログラミング勉強するってあほだろ
少なくともeffective系統読んでもわけわからんレベルの人はまずはしっかりした本を読むべきと思う。
しかしc++は勧めたい本がない。。「独習c++」かな。。いいとは言いずらいがしかしほかに勧めたい本もない。
ネットさえありゃ本なんかいらんだろアホ、と思っていた時期が俺にもありました
実際ちょっと前まではそんな感じだったんだけど、最近は Google のアルゴリズムがポンコツなのか
それの裏をかく技がものすごく洗練されたからなのかしらんが、とにかく検索上位にアホみたいな
ページがひっかかる事が多い上に、ほんとうに必要な情報が見つからないことが多い
特に最近では Python 関係のネット情報はほんとどうしょうもなくぐらい腐ってるな
C++ 関係はまだかなりましな感じだが
外人が書いた「Effective 何々」には、良い本が多い
「Rubyのしくみ」も良い。
RubyVM(仮想マシン)の内部の仕組みがどうなっているのか、など
コンパイラ・インタープリタを作る人は、読んでおいた方がよい
C++ の場合「1. 入門書、2. Effective 何々」の間隔が大きい
つまり、仕様が複雑すぎるから、入門書の範囲が大きすぎる!
独習1冊で、Rubyの1~3 まで軽く読める
常識的には、C++ の本を読めるレベルは、Rubyなど数言語をやった後の話。
とてもじゃないが、素人がやるような言語じゃない!
素人は、細かい仕様の話よりも、
まず、Ruby on Rails などのフレームワークなどで、アプリが動くまでの全体の構造・工程を学ぶのが先
各部分の細かい仕様・バグは、後でよい。
そうしないと、バグってばかりで何も作れない
ネットで学ぶのがアホってドワンゴ社員のあいつの主張繰り返すのかよ
誰が仕様書読むんだあほ
>>146
例の医療関係のページビュー稼ぎ対策の影響で個人が細々とやってる良質なサイトが引っ掛かりにくくなってる
って新聞に書いてあったな >>146
お前のいうネットってqiitaとかだろ?
だからダメなんだよお前はw cpprefjpは仕様の成り立ちから使用例まで載ってる
cpprefjpは左の文字が小さすぎるのをなんとかしてほしい
>>145
独習の後は同じくハーバートシルトの stl 本(ただしC++11じゃない) でしょうけれども… C++の人気はだいたいWindowsと同期してて、XPで盛り上がり、その後下降して、Windows10発売後ちょっと盛り上がり、その後下降し始め、WSLでまたちょっと盛り上がり、みたいな感じで上下する。
>>165
ビャーネストロヴストルップのプログラミング入門はどうですか? >>165
◆QZaw55cn4c さんはプログラマーですか? cpprefjpかcppreference.com眺めるのが一番いいのでは
>>171
C++標準テンプレートライブラリがおすすめ C++ coding standards が、入門書と effective C++の間という感じで良かったのですが、今新品で買いやすい和書の中で同じくらい良い本ありますか
>>173
それでコードを書けるようになるとは全く思わん。 コード書くために勉強したことが無い人間とコード書くために勉強した人間に分かれるな
RPGのバトルシステムがいつまでたっても出来ない
どうなってんだコレ
そこでレポート プログラム ジェネレータを思い出さないと
文句はユニシスに言っとくれ
RPGなつかしいなw
知人でそれの専門で仕事やってるやついたが
今ごろどうしているだろうか・・
>>180
自分が具体的に何を作るのか見えていないとか、自分が何が分からないかがわかっていないとか。 これもSFINAE???
int plus(int a,int b){return a + b;}
double plus(double a,double b){return a + b;}
int main( int argc, char *argv[] )
{
double c = plus(1.0,2.0);
return 0;
}
SFINAEを理解してないな?
templateでわざと失敗させるんだぞ
それは関数のオーバーロード(オーバーロード関数)
SFINAEはテンプレートに関わる話
SFINAE ていう単語みるたびになぜか
ソフバンの白犬が低い声で「スフィ姉ーーー」て言ってる映像が頭にうかぶ
>>188
最初のplusで失敗して、次のオーバーロードを探しに行ってんじゃん。
もし最初でコンパイルエラーなら、このプログラムはコンパイルされないが、SFINAEのおかげでコンパイルエラーが出ない >>186
自分の興味のあることをやっていたら気づいたらコードが書けるようになっていた人と
コードを書けるようになることを目標に勉強をした人
前者は入門の仕方を聞かれると上手く答えられない傾向にある
とりあえず好きなもの作ってみて困ったらリファレンスとかみれば良いんじゃないの?とかは割とガチで言ってる せやな
なぜそこでロベール!?とか思ったけど、なんか納得した
rvalue・lvalueの見分け方について、=の左に書けないならrvalueって考えで良いですかね?
>>194 確かダメじゃないかな。
C の例でアレだけど、配列名 int a[5]; の a は
左辺値だけど代入の左辺に置けない、
「代入不可能な左辺値」というカテゴリになる。
『プログラミング言語C++』第4版 §6.4.1 (p. 175)の図によると
左辺値 lvalue は「アイデンティティを持ち、ムーブ不可能」
右辺値 rvalue は「(アイデンティティの有無によらず)ムーブ可能」
…ムーブできるか出来ないかの判断を、左辺値か右辺値か見分けることで
やろうとしてるなら、この説明は循環論法でしかないけどね。 その場で(1つの文の中で)ムーブされ得るやつが右辺値、ぐらいで良いのでは、
と言いたいところだが
SomeType a = b = 1;
でbあ右辺値なのかと言われるとうーん…
実際bがその場で所有権を失うこともできる(SomeTypeにムーブコンストラが定義されていた場合
のだから当たらずしも遠からずだとは思うが知らん
てかリファレンスだけ必要な奴はここにそういうことを聞きには来ないだろ。
なんかその辺の感覚がすでにずれてるように思うが。
>>195
「代入できない」って視点で言えば194で合ってるんでは?
確かに a[0] =5 なんかはできるけど、 a = b みたいにポインタそのものは代入できないわけだし。 >>196
右結合なんだから b は左辺値、 b = 1 が右辺値でいいんでは? 全く関係ない話になるけど、JNI = Java Native Interface(?) なるものを使えば、
C++で OS 非依存のアプリが作れるんだね。多分。
C++からJavaの任意のメソッドを呼び出せるし、逆も可能なので、
グラフィックをJavaに描かせて、キーやマウスのイベントをJavaからC++に
伝達すればよさそう。すると、LinuxやAndroidで共通に動くC++アプリ(?)
が出来てしまう。wasmも必要ない。
>>200
C++の部分はネイティブなのでOSに依存する スマン。CPU毎にバイナリは必要で、
clangに -macrh=xxx-xxx-xxx オプションを指定して CPUやOSを
指定してコンパイルしておくことを想定していた。
ただし、複数のCPU/OS向けのバイナリを1つのAPKにパッケージして、
使用時に自動選択する事が出来るらしい。
わざわざjavaを使わなきゃいけないのが気にくわない
その場合、javaだけで書くこと以上のメリットある?
Androidアプリは、Javaで書くのが基本とされてるけど、
Chromeブラウザなんかはきっと、C++で書いたものを ARMなどの
CPU向けのnative binaryに直し、それをAPKにパッケージ化して
配布してるのではなかろうか? AmazonのFire7 や Fire HD 8 などの
タブレットのCPUはどちらもARMらしい。スマホもARMが多いのかな。
>>205
基本的な描画系と入力系をライブラリ化しておけば、メインロジック部分は
C++で書けると思うよ。 さっき、AdoptOpenJDK なるものをインストールしてみたら、
java と javac コマンドが起動することを確認した。
多分このJDKは、Oracle フリーで無料でクローズド商用利用できると思う。
jniはjavaのプラットフォームにc++での開発成果物を持ち込むためのもので、そうでないならわざわざそんなもの使う意味は薄い
マルチプラットフォームなアプリを作りたいならQtなりwxなりを使った方が速いし楽
>>208
でもいつ訴えられるかわからないから怖いですう。 そもそも、Androidアプリにとってのシステムコール(API)とは、Javaの関数だと
思うので、この構造自体は Android における「最も高速なアプリ」になっている
と思う。
>>210
一般アプリ作者は大丈夫だと思うな。一番危ないのは、オイラみたいに、
ToolKit作って儲けようなんて思ってる人なのさ。(^_^;) 糞デカイ上に更新面倒なjavaのruntime入れさせるほうが害悪だろ
flashより糞度が高い
AndroidはJREはプリインストール済みなんじゃないの?
オイラは実機持ってないので全く分からないんだな。
androidで実質c++でのアプリ開発する仕組みなら既にある
jniそのまま使うよりは大分マシ
何でグラフィックをわざわざJavaに?
>>217
QtならほぼC++で書ける Qt は、内部的に Backend で Java を使ってるのかな。
vector に格納されてる値から添え字の番号を取得するための最も手軽な方法はなんでしょうか
イテレータから添え字番号を取得することはできますが、あくまで値からやりたいです
格納してる値にインデックスの手がかりがないんだったら
findで探して結果のイテレータから取得するしかないな
>>223-224
ありがとうございます
格納する値の範囲もサイズも小さいvectorなので、今回は辞書を作って対応しようと思います >>225
そんな単純な検索なら3行くらいなんだから作ればいいのに >>200
とても興味を覚えました
私は、そろそろ言語間でライブラリも共用されるべきだと考えています
一つの記述体で各言語共通というのはさすがに難しいにせよ、
Java のライブラリと同等なもの(名前と機能が共通のもの)が C++ にもあってもいいんじゃないか?と数年前から妄想しています… JavaとC++に共通インターフェースを作るのは反対。
車輪の再発明にしかならない。自由を奪うだけの愚策。
>>231
強要するのではなく、オプション(選択肢)として提供するのはどうでしょうか? >>232
共通ライブラリを使う側にとってはオプションであることは当然。
共通ライブラリを作る側の話をすべき。共通ライブラリの規格決定権者が増えすぎること自体が好ましくない。
これはEU諸国がトルコがEU参加することを拒否する感覚に近い。 >>233
私は EU には否定的(グローバリストの巣窟であり、普通選挙/自由選挙による合意形成をスキップするポジションを作って人を操作するからくり、トルコもたぶん目が覚めているのでは?)ですが、それはさておき、
すでにある java/classpath スケルトンを真似してしまおう、という低姿勢・低いプライドを貫くのであれば、規格策定者は基本要らなくなりませんか?だって真似するだけだし… まずは、Javaと瓜二つな C#、.NET、C++/CLIが今どうなっているか考えてみては。
>>229
ちょっと話しはズレるけど、あなたの賛同で嬉しくなったので、入手した耳寄りな
情報を書いておこうと思う。既に知ってる人も当然いると思うけど、
WebAssemblyで作ったようなWebAppliは、ブラウザのURL欄やタイトルバーなどが
表示されてしまうのが難点として残っていた。ところがなぜかElectronでは消せて
いたのでChromeではなくChromiumを使っているからかと思っていた。
ところが、manifest.json なるものを書いて、HTMLにそのファイルを使うように
書いておいて、display プロパティーを standalone やfullscreen にすると、
URL欄が消せるらしい。 >>237
もう時代はすっかり html/css/js ですね…
VSCode も Electron ですし… 質問を変えてみよう。
C++11やC++14のコードは、職場で取り入れられてますか。
>>239
ガンガン取りいれてるよ。
なにげにでかいのが日本語識別子の保証。適切に使うと可読性が笑っちゃうくらい上がるw
ヘッダーのプロトタイプ宣言とかが特におすすめかな。
あとchar16_t/char32_tも結構ありがたい。WindowsとUNIX系のOS間で同じ文字コードとして共通で使える型が以前はなかったからね。
20でようやく入るみたいだが、なぜchar8_tを入れかったのか(´・ω・`)
std::initializer_listもかなり便利。型安全で個数も分かる上に、引数の一番後ろじゃなくてもいいので、cの...と違って気軽に使える。
あとよく使うのは範囲for文と、イテレータの簡略化かな。いくつかの演算子をオーバーロードすれば良いだけだから、
結構気軽に範囲for文対応のイテレータを書ける。
ラムダ式も関数の引数に直接関数を埋め込んだりできて便利。 ガンガン最新を追うべきとまでは思わないけど、
C++11 は最低限度じゃないかなぁ。
17便利すぎ
variant,visit,lambda,if constexpr
のコンボで捗る
つーか今はもうC++11の機能は使わずにC++で書け!といわれても
やりきる自信がなくなった・・
c++11とか名乗るから誤解されるんだよ。
c++++とかのがイメージ的に正しい。
>>249
repeat(int i; n) で for(int i; i<n; i++) と同じ意味な機能 >>250
そんなどうでも良いもののために予約語追加する意味って
その文法じゃ初期値すら変えられない 初期値はi=0とかすればいいのか
でもそうなるとi=1にした場合何回ループするのか混乱しそう
>>229
QtとかGtk、wxとか色々有るじゃん。。。
入れるの面倒くさいなら、Power Builder(だっけ?)とかの有料開発環境はVSを除いてマルチプラットフォームなライブラリが売りだぞ。 >>253
Java の人も C# の人も c++ の人も python も ruby も一緒の名前で一緒の機能が使えたら,コストの中でも一番高くつく勉強コストを減らせるのではないでしょうか >>251
Linuxのカーネルにrepeatマクロ大量にあるもん >>254
wxでもQtでもメジャー言語のbinding位あるだろ >>254
うん。
それはまさにそうで、だからQt,Gtk,wxあたりのメジャー所は色んな言語にラッパーがある。 webプログラマーなんですが、右辺値、fowardっていつ使うのか気になります
というかなんでそこまで、厳密に分ける必要があるのか
業務で使ってる方、使用例を教えてください
右辺値というかムーブ関数の定義といらなくなるオブジェクトにstd::move付けとくのは絶対損にはならないからとりあえずやっとく
forwardはテンプレートライブラリ作るなら必須だけど自分では使ったことないなあ
コピーにコストがかかる場合は、std::swapやstd::moveのが早い場合があるからね。ムーヴはコピーじゃなくて引っ越しだから。
まあ理論上はね。。そういう実装になってるかどうかはコード見ないとわからんけどね。
基本的には高速化が目的でmove使わなくてもなんとかなるが、
所有権絡むとmoveは必須になる
forwardはtemplateで引数渡すときにmoveやら参照やらの完全転送する場合必須
ちょっと実際にやってみようか。コピーコンストラクタで十秒待つコードを書く。ムーヴコンストラクタとムーヴ代入でなにもしない。
この状態でstd::moveを使わないで代入すると十秒かかる。
>>264
>所有権絡むとmoveは必須
必須とまでは言えない
T::T(const T& obj)
という通常のコピコンを定義して、コピコンの中でconst剥がししたら
とりあえず所有権の移動もmove無しで逝ける >>260
高速化のために出来るのは、アルゴリズムのレベルでの工夫を別にすれば、出来ることはショートカットだ。
高速化とは近道なんだよ。
場合分けが出来るなら、どうしてもやらなければならないこと、やらなくてもいいことを「区別」できる。
区別できるなら、やらなくてもいいことは省略できる。
言語での区別が無くても、たとえば C でも区別を陽に書けばムーブみたいなことだって、そりゃあ出来るけども、
そんなクソ面倒くさいことはしたくないので言語でのサポートがあるとありがたい。
まあ速度的にそこまで必要ないってのなら、区別を積極的に利用しなくてもかまわないよ。
でも、必要なときに出来る方法が用意されているとうれしいし、
C++ を使うときというのはそれなりに実行速度が必要なときだろうし。 とわいえmoveコンストラクタの方が意図が明確なコードが書けるから良い。
moveコンストラクタがふさわしい例っていやーつぎごケース。
class BarWithBigData {
Foo* m_pBigData;
BarWithBigData() : m_pBigData(new Foo[1000000000000] { }
~BarWithBigData() { delete[] m_pBigData; }
BarWithBigData(BarWithBigData&& rhs) { m_pBigData = rhs.m_pBigData; rhs.m_pBigData = NULL; }
Foo* refBigData() { return m_pBigData; }
};
ちなstd::arrayは使った無いから知らん
訂正orz、
誤:
Foo* m_pBigData;
BarWithBigData() : m_pBigData(new Foo[1000000000000] { }
正:
Foo* m_pBigData;
public:
BarWithBigData() : m_pBigData(new Foo[1000000000000]) { }
コピコンの中でconst剥がしってちょっと何言ってるか分からない
十秒待つ待つコードはWindowsなら#include <windows.h>してSleep(10*1000);であり、
Linuxなら#include <unistd.h>してsleep(10);だ。
C++11ならstd::chronoに待つ関数があったはず。
>>271 「move無しで(未定義動作に)逝ける」ってことでしょ。 >>271
こうじゃわ;
BarWithBigData::BarWithBigData(const BarWithBigData& rhs) { m_pBigData = rhs.m_pBigData; const_cast<BarWithBigData&>(rhs).m_pBigData = NULL; }
>>269もmoveコンストラの変わりに↑のように書いても逝ける まあ実際にはそんなムーブをゴリゴリ書くことはなくて
m_pBigDataをunique_ptr<array<Foo, 1000000000000>>にしてムーブctor、ムーブop=、デストラクタを=defaultにするけどな
auto_ptrよりヤバイ奴
const_castでconst外した後実際に書き換えてしまうとかw
>>277
ちなconst T&で渡されたブツを関数内でconst_castして書き換えることはそれ自体は合法
ROM上のオブジェクトを渡して死ぬことは有り得るがしたら呼び出し側の違反
また最適化にしくるとしたらそれはコンパイラーのバグ >>278
ROM上になくても const T 型で構築されたオブジェクトを書き換えたら未定義動作になるから、
値が変わらない前提の最適化は許されてるよ。
const 無しで構築されたオブジェクトを指す const& の話と混同してそうだね。 質問: c🐴++のrust相対の優位性はなんですか?
>>280
正しくないコードをコンパイル出来る。
C++ はプログラマを信頼するのだ。 >>278
未定義じゃないか
c++03 5.2.11の7にはこんなことが書いてある
[Note: Depending on the type of the object, a write operation through the pointer, lvalue or pointer to data
member resulting from a const_cast that casts away a const-qualifier68) may produce undefined behav-
ior (7.1.5.1). ] >>282
Depending on the type of the objectにおいてmay produce undefined behaviorである
すわなちオブジェクトの型によっては未定義動作に成りえる、
と言っているだけなのでconst T&渡しされたパラメータの書き換えがNGの祥子にはなんね
>>279
>const T 型で構築されたオブジェクトを書き換えたら未定義動作になる
それはそう。しかしconst T&渡しされた関数内でコンパイラはそれを判断できないから
そういった関数内で、参照型かポインタ型引数で関数に渡されたlvalueのconst_castした結果はあくまでlvalue扱い
のはず… >>283
関数内では const& であることを根拠に最適化に使えないのは合ってる。
でもだからといって const& で受け取ったものを書き換えてもよいとは言えない。
void f1(int const&);
int f2()
{
int const x = 1;
f1(x);
return x;
}
x は int const なので、 f2() の return x は f1() が const_cast して x を
書き換える可能性を無視して return 1 に最適化できる、という話。
BarWithBigData const x; が >>275 のコピーコンストラクタに渡された後も
const_cast<BarWithBigData&>(rhs).m_pBigData = NULL; を無視して書き換え前の
m_pBigData が使われる可能性がある。 規格が云々言わなくても、9割のプログラマの意図に反してるで終わる話
頼むからそんなコードは頭の中にしまっといてほしい
つまりはそれ自体は問題ないが、constとして生成したオブジェクトを渡した瞬間にダメになると言うことか
で、渡すこと自体は制限できないから
プログラム中に罠を仕掛ける事が出来るわけだ。
const_castも要らないし良いことずくめじゃないかw
>>285
わかりたそうする。>>275のケースは素直にムーブコンストラクタを使えば良い。または↓でもだいたいおk
BarWithBigData::BarWithBigData(BarWithBigData& rhs) { m_pBigData = rhs.m_pBigData; rhs.m_pBigData = NULL; }
だいたいというのはムーブコンストラクタ有りの規格のC++コンパイラで↑の非constなコピコンだけ書く警告が出ることがあるからイヤン、
>>286
>つまりはそれ自体は問題ないが
いや問題がある可能性が潰せていない。
void f1(int const&);
int f2()
{
int x = 1;
f1(x);
return x;
}
(xがconst無し)の場合であってもf1(x)がxを書き換えない前提の最適化がf2()にかかったりすると、
f1(x)内で変更したxの値がreturnされるxの値に反映されない可能性がある(f1(x)の呼び出し前後でxがレジスタに乗ったままであるとか、 >>289
その x の型は const じゃないから return x は最適化できないよ。 ラムダに11個の引数を参照で渡すのと、キャプチャするの、どっちが速いかな?
>>291
メリットのときもデメリットのときもあるだろう。 参照渡しな時点でその場で呼び出すのだろ。
最適化かければ結局同じようなアセンブリになるよ。
それはわからんだろ
ブロック待ちするかもしれないわけで
引数で渡すとスタックに積まれる可能性があるけど、キャプチャするとそうならないのでは。
いや、形式上は無名クラスにキャプチャを変数としてぶちこんだもののインスタンス作ってメンバ関数のoperator()呼ぶのだから、スタックは使うだろ。
>>298
じゃあ、引数で渡すとスタックに積まれない可能性があるので、速い場合もあるのでは? 海外だと、Javaに負けて、Rustに圧倒的実力で追いやられるC++
本当に、コンパイル時に何かしたいならRustだけどね
全部足すと500%位になりそうだから、複数の言語を使う人が多いんだろね。
江添が転職できずに困っとるw
まあこいつがクソなだけでc++の問題ってわけじゃないんだがイメージは悪いわな。
こうしてみるとホッシーの全タクシー移動ってのは理に適ってるな
バカな公害に捕まる心配が減る
喫煙者が目に入った途端癇癪起こして殴り掛りかかる狂犬なんだっけ?
知らね
よく人を招いているようだし揉めたことがある人も少なくはないんじゃいか
>>310-311
当事者の様々な主張の食い違いがあるので、結論としては「わからない」。
少なくとも彼自信の主張としては掴みかかってきたのを払いのけた結果として眼鏡が割れたということになっている。
(江添が殴りかかったわけではなく、むしろ防衛した側、と江添は主張している。)
江添が煙草について過激な意見を持っているのは確かだが、
シェアハウス内で禁煙場所であると合意がなされている場所で煙草を吸った客人がいたというところは当事者全体が認めているようだ。 恨みというかまともにコード書かない奴がクソ意見で現場荒らすって事自体がクソだと思うわけで、
まあその反動で現場で働くことができないって事になればザマァって思う。
どのプロジェクトにも参加してないと認識してたけど乗り込んでケチつけてたりするのかな
まあ俺ドワンゴとは縁が無いからどこで何してようが関係ないけど
C++がPython抜いて3位 - 4月TIOBE言語ランキング 2019/04/17 10:55 後藤大地
https://news.mynavi.jp/article/20190417-810363/
TIOBE Softwareから、2019年4月のTIOBE Programming Community Index (PCI)が公開された。
TIOBE PCIは、複数の検索エンジンの検索結果から、対象となるプログラミング言語が
どれだけ話題になっているかをインデックス化したもの。
4月TIOBE Programming Community Index / 円グラフ
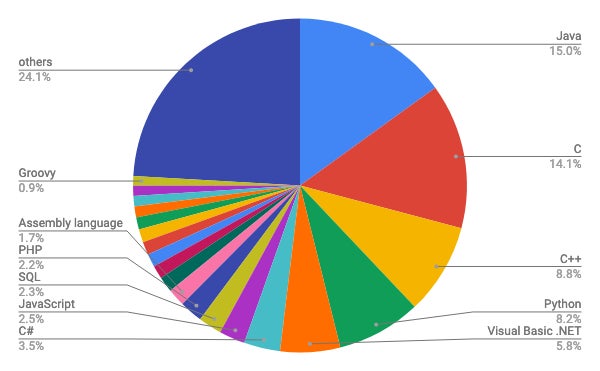
2019年4月はC++がPythonを抜いて3位に返り咲いた。ただし、Pythonのシェアが下落したの
ではなく、Pythonの増加傾向をC++の増加が上回ったことによる結果と思われる。C++は
長期にわたって下落傾向が続いていいたものの、2019年に入ってから増加傾向へ転じている。
Pythonも増加傾向が続いており、どちらも今後さらにインデックス値を増やす可能性がある。
長期にわたって1位を確保しているJavaは依然として1位のポジションにあるが、下落の
傾向が続いている。2位のC言語も長期で見ると下落を続けており、C++やPythonの存在感が
強くなってきている。 >>317
何回だからみんな何回もググってるんだよ 今もしインターネットが完全にシャットダウンされると
プログラム書けなくなるプログラマけっこう数いるだろうな
>>320
cpprefjp はとりあえず手元にダウンロードしてあるけど。 どうやってダウンロードしたの?
巡集じゃできなかった…
江添は職質裁判でも、不当判決が出たので控訴するみたい
警官は、複数人で口裏合わせするから、民間人は勝てない
漏れもやられたけど、酒酔い運転でも、漏れが機械に息を吹き掛けても、ランプが点かない。
そこで、警官がクルッと後ろを向くと、ランプが点く
そっと見たら、酔っ払い警官が、自分で息を吹きかけて、ランプを点ける
こういう裁判で争っている人もいるけど、
警官は複数人で口裏合わせするから、絶対に勝てない!
警官は皆、このやり方で出世しとる
ありゃ普通に対応してりゃ済む話だと思うがね。
やってることは完全に当たり屋だろ。
>>326
Rubyバカの人か。相変わらず思い込みが激しく、言っていることが滅茶苦茶だな。 だけ、というのは言い過ぎだと思うが、
日本語で最新の C++ の事情を本にしているのは江添くらいしかいないからなぁ。
江添本人は自分のことを実務家ではなく教育者だと考えているようだし、
(肩書は何なんだろ? エヴァンジェリストのようにも見えるが……)
今のポストは妥当なとこだろ。
そのままやってくれればありがたいもんだ。
江添個人の裁判は完全にスレチなんだよなあ
仮に違法な取り締まりだと判断されても警察のやり方が改まるわけもないだろうし
江添すなわちC++なのだから
江添の話題は全てC++の話題だょ
こんな事言うと勘違いされそうだが、はちみつ餃子はちゃんとしてると思うよ
C++に関しておかしなことは言っていない
ていうか、はちみつ餃子ってものすごい不味そうなんだがそんなの本当にあるのだろうか・・?
肉料理にはちみつを入れること自体はわりと普通
量の問題
いや明らかに開発してねーだろって感覚じゃねーか。
まあここならそれでもいいんだろうけれど。
>>338
ググればわかるけどはちみつ餃子はそこそこありふれた料理だよ。
その昔、 higepon が自分でもどうして higepon などと名乗ったかわからない
と述べていたので、そのくらい意味不明感じにしようと思って適当に
思いついた語をコテハンにした。
Scheme スレが本来の住処なので当初は SCHEME餃子 と名乗っていたけど、
他のスレにも顔を出すようになったのでなんとなくはちみつ餃子になった。
およそ意味不明な組合せにしたつもりだったんだけど、
実際にある料理だとは後になってから知った。 initializer_listを引数に取るオブジェクトを引数に取る関数で
下記のケースでUniversal Initializationが効かないのですが
何かいい手はないでしょうか
using KVPCollectionType = std::map<std::string, std::string>;
void f(const KVPCollectionType&& kvps = {});
f(); // OK
f({}); // OK
f(KVPCollectionType{{"key1", "value1"},{"key2","value2"}}); // OK
f({{"key1", "value1"},{"key2","value2"}}); // NG これをやりたい!!
すみません、訂正です
× void f(const KVPCollectionType&& kvps = {});
○ void f(const KVPCollectionType& kvps = {});
アークエンジェルに搭載されてるstd::variant<>。
wandboxで試したらclangでもgccでもc++11 -pedanticで通ったけど?
ごめんなさい、ごめんなさい。本当にごめんなさい。
勝手に脳内で要約したのが間違えまくってました
正確には以下の通りです。
#include <map>
#include <memory>
using KVPCollectionType = std::map<std::string, std::string>;
class c {
public:
c(const KVPCollectionType&& kvps = {}){}
};
int main()
{
auto ok = std::make_shared<c>(KVPCollectionType{{"key1", "value1"},{"key2","value2"}}); // OK
auto ng = std::make_shared<c>({{"key1", "value1"},{"key2","value2"}}); // NG!!!
}
全てのバグを絶滅せよ。
「今日は死に日和」好評発売中。
C++11や14を使ってる人、コンパイラは何ですか。
Twitchでプログラミングしてるやつの中でゲームエンジンも居たような
>>347
テンプレートの推論ルールとして「関数テンプレートのパラメータとして波カッコの初期化子リストを渡して型推論させることはできない。」
ということになっている。 ( https://cpprefjp.github.io/lang/cpp11/uniform_initialization.html )
make_shared の実際の型は template <class T, class... Args> shared_ptr<T> make_shared(Args&&... args); なので、
このとき Args が推論できない以上はどうにもならん。
型を固定した専用の関数をはさんでこんな感じにするくらいのことしか思いつかないな。
#include <map>
#include <memory>
#include <initializer_list>
#include <utility>
using KVPCollectionType = std::map<std::string, std::string>;
class c {
public:
c(const KVPCollectionType&& kvps = {}){}
c(const std::initializer_list<typename KVPCollectionType::value_type>){}
};
std::shared_ptr<c> make_c_shared(std::initializer_list<typename KVPCollectionType::value_type> a) {
return std::make_shared<c>(std::move(a));
}
std::shared_ptr<c> make_c_shared(KVPCollectionType&& a) {
return std::make_shared<c>(std::move(a));
}
int main() {
auto ok = make_c_shared(KVPCollectionType{{"key1", "value1"},{"key2","value2"}});
auto ng = make_c_shared({{"key1", "value1"},{"key2","value2"}});
} >>347 >>354
呼出す側で
auto ng = std::make_shared<c, std::initializer_list<typename KVPCollectionType::value_type>>({{"key1", "value1"},{"key2","value2"}});
というように型を明記してもかまわないけど、使う側でいちいちこんなこと書きたいわけじゃないだろ? >>347
ちゃんと考えたら >>354 はいらんことしとるな……
これで充分か
#include <map>
#include <memory>
#include <utility>
using KVPCollectionType = std::map<std::string, std::string>;
class c {
public:
c(const KVPCollectionType&& kvps = {}){}
};
std::shared_ptr<c> make_c_shared(KVPCollectionType&& a) {
return std::make_shared<c>(std::move(a));
}
int main() {
auto ok = make_c_shared(KVPCollectionType{{"key1", "value1"},{"key2","value2"}});
auto ng = make_c_shared({{"key1", "value1"},{"key2","value2"}});
} >>354-356
ありがとうございます、その手を使わせていただきます
状況によって推定ルールが変わるのはやめて欲しいなってちょっと思ったんですけど。 エディタの補完機能使いたいときにたまにそうやって補完して最後に消す。
が、たまに忘れる。
IDEの都合で付ける事が良くある
付けないと補完候補多すぎて
メンバ名は頭にm_付けろみたいなクソルールよりずっといいと思うので付けるべき
仮引数と別の名前つけるのだるいからm_は別に良いと思う
引数そのままメンバに入れるなら引数に_つけてvar(_var)って初期化してるわ
>>366
それって var(var) でも問題ないんですよ… ハンガリアン記法は、入力補完のないエディタ上での可読性を高めるのに役立ってるでしょ。今でも。
定期的にunsignedとsigned混在させてハマるアホをみるとハンガリアン必要だと思うわ
C#で入力補完のないエディタがどうとかさすがにナンセンスでは
だってvisual studio使うじゃん
どっちでもいいわ。
大抵の場合そんなとこに気を使わんといかんコードになってることのが問題。
>>375
こういうやつがそのうちハマって丸1日つぶしたりするんだよなw >>376
だから人を嵌めるようなコード書くなつってんだよばか。 >>380
コードの問題じゃなくて言語仕様の問題だから
こういうえらそうなくせに何もわかってないカスが一番始末に困る ハンガリアンも防御的なプログラミングと考えたら悪くないよ
成り立ち調べてみな
でも基本型とポインタだけだな
クラスには無用だと思う
てめーらはまともなIDEかエディタ使ってねえのかよ
c++みたいに型情報ありがデフォルトの言語でハンガリアンとか二重メンテもいいとこだわ。
前方宣言したクラスをTにしたスマポメンバでコンパイル通るときと通らないときがあって調べてたら
デストラクタがインライン(暗黙)だと駄目だとわかった
しかもこの問題が起こるのはunique_ptrのときだけでshared_ptrはデストラクタの定義に関係なく通る
わけわからんぞ
教科書に書いておいてくれ
class ClassB;
class ClassA{
public:
ClassA();
private:
std::unique_ptr<ClassB> u; // NG
std::shared_ptr<ClassB> s; // OK
}
---
class ClassB;
class ClassA{
public:
ClassA();
~ClassA(); ←これでunique_ptrもOK
private:
std::unique_ptr<ClassB> u; // OK
std::shared_ptr<ClassB> s; // OK
}
>>388
unique_ptr<T>のデストラクタはインスタンス化するときにTが完全型であることを要求する(デストラクタで直接Tのデストラクタを呼ぶ)
unique_ptrを内包するクラスのデストラクタが暗黙だとクラス内でコンパイラによって実装されるけど、その場でunique_ptrのデストラクタを要求する
しかし、その翻訳単位内でTの定義が無ければコンパイルエラーとなる
unique_ptr<T>を内包するクラスのデストラクタがとりあえず宣言だけでもあると
実際の定義がある場所で同様の事が起こるので、その場所でTの定義が見つかればいい
その場合に定義を書かないと、コンパイラさんが適切な翻訳単位内に定義をおいてくれるみたい
shared_ptrは動的削除子のおかげでデストラクタが呼ばれるところで適切にデリータを定義し、デストラクタを呼ぶようになっているのでこの様な問題は起こらない
shared_ptr<T>のデストラクタ内ではTのデストラクタを直接呼び出すようなコードが無い うーんC++プライマー8500円かぁ。本家のプログラミング言語C++第4版はもっとするし
情報量からすると安いが本一冊にポンと出すにはお高い……日本語である程度網羅的な本となるとこの2冊くらいよね
set<double> って int のときと同様にちゃんとソートされるんですか?
たしかにそうだな・・いよいよ平成最後なんだな
みなさん、>>393-394 みたいな事にならないよう、気をひきしめましょう 平成最後っていう言い回し使われすぎて嫌いになってきた
イテレータの参照を次に移すときってなんでitr++ではなく++itrなの?
素直な実装だとitr++より++itrのほうが速いんじゃないかなあ、となんとなくみんなが思っているから
インクリメント後のイテレーターの値を返す処理の実装を考えると
先の場合はインクリメントしてそのまま渡せばいいけど
後の場合はインクリメント前の値を保存しといてそれを渡さないといけないので一手間かかるから
・・なんだけど諸々の最適化とか色んな条件とか考えたらそこまで差がでるかどうかはよくわからん
it++だと、戻り値をコピーしてとっておいてから、ポインタなりを進めた後にreturnする必要があるが、
++itだと、ポインタを進めた後に参照を返すだけでするからな。
>>398
ite++と++iteなんて気持ちの問題
てか範囲for文使えばいい どうせ戻り値捨てるんだったら++itを選んでおいて損はない
無駄にit++を使うのは時期尚早な最不適化って奴だ
C++で書くんだから後置インクリメントの方がメインに決まってんじゃん
前置は異端だ
C++でいいんだよ。
規格は一歩進むけど、使ってるやつはbetter Cばかりってな
>>411
vectorとかstringとか使わんの? CArrayとCStringだぞ
コピコンは定義されてないから自分で作るぞ
CArrayは、<algorithm>ヘッダーで定義された信頼性の高いユーティリティ関数を使えないのがね・・・。
>>415
イテレータをうまいこと定義すれば使えるやつも結構あるんじゃね?
そうでもない? inconsistent begin/end types in range-based ‘for’ statement
gcc(g++) 8.2で -std=c++17オプションでコンパイルで
範囲forでこのエラーが出るんだが
begin endの型不一致の制限緩和されいるはずだよな?
原因わかる方いますか?
>>415
GetData()とGetData()+GetSize()を渡せば、とりあえず動くんじゃね? >>422
int _n = 0;
auto __begin = _container.begin();
auto __end = _container.end();
for (; __begin != __end; ++__begin) {
_n = *__begin;
}
比較演算子はちゃんと定義してるし
上のコードは何故かコンパイル通る
だけど
for (const auto _n : _container) {
//hoge
}
は何故か通らない 範囲for文のconst autoをconst auto&かauto&&に変えるとどうなる?
>>424
auto&&にした時のみエラーが増えます
cannot bind rvalue reference of type ‘const long unsigned int&&’ to lvalue of type >>426
using iterator = typename std;;vector<int>::iterator;
using const_iterator = typename std;;vector<int>::const_iterator;
using my_iterator = MYIterator;
my_iterator begin();
iterator end();
const my_iterator begin() const;
const_iterator end() const;
const my_iterator cbegin() const;
const_iterator cend() const; これで動かん?
for (auto&& _n : _container) {
}
MYIteratorの実体がunsigned longみたいだけど
vector<int>::iteratorの実体がポインタだったらoperator!=の定義できなくない?
>>423
bool operator != (~) const ← これ付け忘れてないか? >>427
自己解決
const iteratorとconst_iteratorが一緒だと勘違いしていた
const my_iteratorではなくmy_const_iteratorを実装して返り値とすべきでした struct A{
int member;
};
struct B: A{
void run(){member = 0;}//ok
};
template<typename T>
struct TA{
T member;
};
template<typename T>
struct TB:TA<T>{
void run(){member = 0;}//NG。this->memberとするとok
};
クラステンプレートを継承してクラステンプレートを作成した場合にthisでないと継承元のメンバーが見えないのは仕様?
仕様
一寸前までのmsvcではなぜか通っていたけど
>>437
2phase lookupだから
最初のTB解釈時にはTAが型引数一つのtemplate classであるという情報以外使わない
だいたいTAが特殊化される可能性があるだろ 8bitや16bitのintしか使えない環境で、
32bitなどの大きな数を扱うにはどうすれば良いですか?
変数をいくつかつなげて大きな数を表現できないかと思っているのですが、やり方が分りません。
ご存知の方いらっしゃいましたら教えて頂けると嬉しいです。
補足させて下さい。
足し算、引き算は出来るようにしたいです。
可能でしたら、掛け算や割り算もできると助かります。
>>438
> だいたいTAが特殊化される可能性があるだろ
なるほどそりゃそうか、サンクス karatsuba はかなり桁数が多いときじゃないと効果がないとも聞くけど
>>439
stdint.h で int_least32_t とか使えるのでは? >>446
8bit/16bit CPU で int_least32_t とかはそもそも存在しないのでは? >>447
「8bitや16bitのintしか使えない」を見て long や long long はもっと大きいんじゃないの?と思ったんだよ。
「整数型」の意味で"int"って書いてたんなら、確かに存在しない環境のことを言ってるのかもしれない。
その場合は ISO C/C++ の LONG_MAX の最低絶対値の要求に準拠できないってことになるんだけど。 8bit pic用XCでもlongは32bitなのに
>>449
それはそれですごいインプリメンテーションですね…
8 bit PIC で 32bit int がさくさく書けちゃうとは、そのインプリメンターは根性がありますね、それか頭のねじが何本か外れていて「無理を無理と思わない人」とか… shortは16bit固定でlongは32bit固定でしょ。何言ってんの?
>>451
残念でした、short も long もインプリメンターが好きに実装していいのですっ!きりっ! >>451
64-bit Linux でsizeof(long) が8だった。移植がある場合は<cstdint>使わんとあかん intが16bitならISOの規格は満たしてることになるかな。
32bit以上の長い整数はクラスと演算子オーバーロードで誤魔化すか。
頑張ってもリテラル表記もダメだろうから、使い勝手は悪いよな。
>>451
うろ覚えだが
VC Win32bit: int 32bit long 32bit pointer 32bit
gcc Linux32bit: int 32bit long 32bit pointer 32bit -ここまでは同じ
VC Win64bit: int 32bit long 32bit pointer 64bit -int64_tで64bit整数
gcc Linux32bit: int 32bit long 64bit pointer 64bit 厳密なbit長が必要なときにintだのlongだの使っちゃ駄目よ
intの配列のラッパーのようなものから再発明すりゃーいい
class Bignumber{
int number[4];
Bignumber(const String num){
for(int i=0; i<4; i++){
number[i] = //考えるのが面倒臭い
}
}
Bignumber operator+(){
//以下、延々とオペレータオーバーロードが続く
}
};
>>459
int64_t とか int32_t とか cstdint の面々を使うしかないでしょうね…私もデフォでそうするようになりました あ…ありのまま 今 起こった事を話すぜ。
平成の終わりにいろんな奴からshort/longに対する認識の誤りを指摘される恥辱を味わった。
何言ってるかわからねーと思うが(以下略
なんかもうビットという表現すら無くそうとしてるんじゃなかった?
制限された環境で使える多倍長整数のライブラリくらいいくらでもありそうだけど
>>462
なるほど、cstdint ですか!
教えてくださりありがとうございます ビット数を付けるのは、MISRA-C で決まっているだろ
int8, 16, 32
uint8, 16, 32
C++の規格上はintは16 bit以上(ターゲットのアーキテクチャで一番自然なサイズ
、longは32 bit以上
だったと思った
class ClassA
class ClassB: public ClassA
class ClassA::ClassC
のときに、ClassBはClassAのサブクラスと言いますがClassCはなんと呼ぶものですか?
>>469
>class ClassA::ClassC
この意味はなんですか? 基底クラス
スーパークラス
親クラス
ベースクラス
細かいことを言えば、規格準拠の処理系でも
int32_t (ピッタリ32bit) が定義されるとは限らないのね。
int_fast32_t, int_least32_t なら定義される。
8bit単位じゃないCPUへの配慮らしいから、
普通の(この表現も危険だけど)コンピュータを使う分には
int32_t があると仮定して書いてもたいがい大丈夫だろうけど。
コンパイルエラーが出るから出たら対処、で十分かと。
>>470
クラス内で定義したクラスです
class ClassA {
public:
...
private:
class ClassC;
ClassC * C;
}
class ClassA::ClassC {
...
}
の場合class ClassA::ClassC からClassA::を取るとコンパイルが通りません 「プログラミング言語C++」だと、入れ子クラス(nested class)とか
メンバクラス(member class)とか呼んでるみたい。
内部クラス(inner class)もよく聞くけど調べたらJava用語っぽいな
Inner Class、Java用語なのか。そう呼んじゃってたわ
>>473-474
nested class は仕様にあるので、
これが公式な用語と思って良いみたいだね。 以前、「完全さを求めるあまり今存在する良い物を犠牲にしてはならない」という趣旨のことわざをBBCハードトークで仄聞したのだが、原典はなんだろうか?
>>480
ググってヒットしたもののうち、これについてめぐらせています(ことわざとは関係ありません…)
http://www.kt.rim.or.jp/~hisashim/gabriel/WIB.ja.html
この人(原著者)、最後まで間違ったままでいるような気がしてなりませんが、実際のところどうでしょうか ストリームの遅さは凄い凄すぎる。
ほとんどの場合、遅くても問題ないということはわかる。
でもあそこ迄遅くする必要があったのだろうか。
今やどの言語もprintfのような書式付き文字列を指定する方式に回帰した(jsすら!)。
少なくとも書式付き出力に限れば、ストリームはプログラミング言語の中ではもう淘汰されてしまったんだと思うよ。
早いとこ、string::format()とかbasic_ostream::format()とか作ってほしいわ
多言語対応するためにはC#みたいに %1, %2みたいに引数を番号で指定できる書式じゃないとダメでしょ。
ストリームの精神はrangeに受け継がれて生き残るよ
だから書式はそろそろ負けを認めよう
<<には<<なりの良さがあると思うので、ストリームというより、stringがoperator <<をサポートすれば良いと思う。
文字列操作するためのインターフェイスとしては最悪だよ。
考えた奴は自分では絶対使わないで人に使わせるだけのタイプだろうな。
そもそもだけど、なんで文字って表示されるのに
<< とか %s とかこういうのが必要なの?
どの言語でもprint(a);だけで表示させればよくない?aが文字列でも整数でも小数でもさ。
引数で判断してくれよ。
>>493
え、そう?
文字列を連結する時に、+=と+を使い分けるより<<だけですむ方が楽だし、連結する順番も自明だし結構良くない?
std::string str;
str << "hoge" << 123 << ".txt";
みたいな。 >>492
それは私も考えていました、cerr に都度吐いているメッセージを、もう一度プログラムの最後にまとめて吐きなおす、とかをやってみたいんです… >>495
そのやり方は引数の順序を変えられないから語順が違う言語間での翻訳で困る コンストラクタの引数に出力先stringインスタンスを渡すostream派生クラスを作ればいいじゃない。
string str;
hogestream sstr(str);
sstr << "hoge" << 128;
>>499,500,501
ostream派生クラスじゃなくて独自のクラスのほうが軽量でいい。
stringインスタンスへのポインタのほかに、数値書き込み時の進数設定(oct,dec,hexを覚えておく)などをメンバ変数に持てばOK。 basic_ostream使えよっていつも思う
なんで決め打ちするのかわからない
b配列全てをa配列のケツにコピーするとき
std::vector<char> a;
char b[]={0,1,1,3,4};
a.insert(a.begin(),&b[0],&b[sizeof b]);
これでいいの?
&b[sizeof b]
これが死ぬほど気持ち悪いんだけど
そんな気色悪い書き方しなくてもこれでいいよ
a.insert(a.end(), std::begin(b), std::end(b));
>>508-509
std::copy に back_inserter を渡す方が効率的という豆知識。 >>511
insertのが速いんでね?
resizeしてmemcpyになるはず アルゴリズムよりvector::insertのほうが実装による最適化の余地は大きそうだな
ポインタがイテレータとして渡された時点で相手が連続バッファだってわかるからね
&b[sizeof b]でもstd::end(b)でもやってることは変わらないんだけどな
見映えは重要だな
sizeof bじゃcharでしか使えないんで、そういう意味でもイケてないかも
>>515
見栄えというか、名前が付いているってのはそれだけで単純にわかりやすいな。
(名前が妥当であれば。) 嫌儲で、東京五輪チケットのソースコードが出てるけど
C++使ってるお前らなら、こんなソースコードじゃないよね?

>>518
サーバーサイドあまりやってないけどこんな泥臭い書き方するのか こんなもんだろ
SIerが間違ってコンシューマ系のWeb制作を請けてしまうとこんな感じになる
てかこんなもの韓国に出すのね
安くなさそう
ってもしや北の方?
parseInt(Num).lengthって動かなそう
ほんまやw桁でも返ってくるのかと思ったがundefinedじゃんかw
型に無駄にこだわった結末がstreamと知っとくのは重要。
あの間違いを覚えとけ。
ゲームのシーンを管理するクラスとシーンクラスがあり、管理するクラスはシーンクラスを保持しています
シーンクラスから管理クラスのシーンチェンジを行う関数を呼び出したいのですがどうやったらいいでしょうか
シーンクラスが管理クラスのインスタンスを持ちたくありません
>>518
webにあげるなら難読化まではしないにしても最低限圧縮するよね >>526
シーンクラスに管理クラスへの参照(ポインタ)を持たせればいいんじゃないのか >a.insert(a.begin(),&b[0],&b[sizeof b]);
>
これ、添字オーバーしてるけどメモリエラーとかにならないの?
>>530
イテレータ範囲のendは配列の場合最後の要素の次のアドレス
それは普通の実装ではアクセスされることはない
規格的にも最後の次の要素へのポインタだけは未定義じゃない &p[N]はp + Nと同じって規格にあったっけ?
確かに&b[sizeof b]はデリファレンスしてるわ
これはあかんそう
>>533
a[i]は a+i ではなく *{a+i} 経験上出来るプログラマーは言語オタクが多いイメージ?(ただし浅い)
&*pはデリファレンスなしで単にpと評価するってどっかで特別に決められてなかったっけ?
>>530
int a[5];
int *p = &a[5];
というコードが有効、つまり
「配列の最終要素の次の要素」(現実には存在しないデータ)のアドレスを取れる、
という仕様から、この場合は許される、というのが >>531 の指摘か。
一般的に >>538 が成り立つなら便利だけど、調べ切れなかった。
流れの元になった >>508 を見返したら、
a.insert(a.begin(),&b[0],&b[sizeof b]);
これだと b[] の内容はベクタ a の先頭に挿入されちゃうね。 >>530
>>a.insert(a.begin(),&b[0],&b[sizeof b]);
>>
>
>これ、添字オーバーしてるけどメモリエラーとかにならないの?
508だけど、これは
a.insert(a.begin(),&b[0],&b[sizeof b]);
こっちの間違いです。ごめんなさい。
a.insert(a.end(),&b[0],&b[sizeof b]);
&b[sizeof b]);
この部分は
b+sizeof(b)
これなら問題ない感じ?
どちらでも動くけど、たまたまいてる可能性捨てきれないから不安なんだよね。
実際のソースはsizeof(b)がbに格納されているデータのサイズを示していて、
char b[256];
int s = read( fd, b, sizeof b);
a.insert(a.end(),&b[0],&b[s]);
みたいな感じで書いてます。
んで、b最大数来た場合にちゃんと動くか気になったというわけっす。
int s = read( fd, b, (sizeof b)-1);
無難にこれの方がいいですかね? >>539
>int *p = &a[5];
これは多分だめで、ポインタ値としての存在なら許される
int *p = a+5; ややこしいからoperator <<を定義しようw
VC++だと
std::vector<T> a; &a[a.size()]はoperator[]のassertionに引っかかるね
std::transformって並列処理されてますか?
c++17のparallel版使えば並列実行されるかもしれない
visual studioでC++17にしたけどいまいち並列版の使い方が分からなかった
普通にfor回すのと、OpenMP使ってfor並列化するのと、transform(非並列)使うの比較したら
OpenMP>普通にfor≧transform だった
struct AとAを継承したstruct Bがあって
Aの内容をBの共通部分にコピーする方法ってないですか?
A a;
B b = a;
みたいにしたいんですけど親を派生先にキャストはできないので困ってます
struct B : public A
{
B* operator=(const A& a){ this->hoge = a.hoge;}
};
これ初期時にも使えるんかな
コピーコンストラクタが実装できたとしてメンバ変数は1個ずつコピーするしかないですかね
スライシングをさせるとか?
安全に?スライシング起こす方法ってあったっけな?
なんか危ういからやろうともしなかったが
>>549
初期化時は普通にコンストラクタ初期化リストで A(a) って書けるでしょ。残りのメンバをどうするのか知らんけど。
代入なら static_cast<A&>(b) = a か b.A::operator=(a) で済みそう。 普通にコンストラクタかオペレーター作ればいいんじゃね
B::B(const &A)
B::operator =(const &A)
A::operator B()
雑なキャストでよければdynamic_cast<A>でおk
↑dynamic_cast<B>の間違い
B b = dynamic_cast<B>(a);
>>551
sturctでまとめればデフォルトコピーコンストラクタが使えるけどね。
あとはintとかPODオブジェクトだけだったらmemcpyしちゃうとかも、俺はたまにやるなw 549です
解決しましたありがとうございます
以下のように書いたら思っていたことが出来ました
(派生先のコンストラクタで親のデフォルトコピーコンストラクタ呼べるの知りませんでした)
代入は現状使う予定がないので大丈夫です
B::B(const &A a) : A(a) {}
引数付きコンストラクタって、=default使えるの?
厳密にはC++の質問になるのかよく分からないんですが……
C++プライマーで勉強しててconstexprの部分にさしかかったんですけどコンパイル時評価、コンパイル時に評価される……みたいなことが書いてあるんですがこれの意味がいまいちよくわかりません
実行時評価という言葉も見られるんですがそれぞれの違いとそもそも評価ってどういう処理のことなんでしょうか
それとそもそもconstexprの使いみちが分かりません
よろしくおねがいします。
>>563
評価=機械語による演算。
コンパイル時評価とは、コンパイラ(PCなど)が演算してその結果を成果物に出力すること。
実行時評価とは実行機(スマホなど)でプログラム実行時に演算して利用すること。 constexprってのは#defineの置き換えのために生まれたんだよ
C++11以前はenum使ってたんだけどなんかかっこわるいから専用のキーワードが出来たってことさ
1+2を計算するアプリ作るとするじゃん?
constexpr int a = 1 + 2;って書くじゃん?
でもこれaが3なの分かりきってるじゃん?
アプリをインストールした世界中のスマホでいちいち1+2=3って計算するの資源の無駄じゃん?
だからそういうコードを書いてコンパイルするとコンパイラが最初から「a=3」って埋め込んで世界資源の浪費を防ぐんだよ
これがコンパイル時評価
実行時評価は普通の電卓アプリがやってること
ユーザーが計算したいのは1+2か5×5かlog123456789かは使われてみるまでわからないので、おとなしくスマホのCPUと電池を使って計算する
これが実行時評価
const int n = 5;
const int m = n * 100;
要するにこうするとmを計算してくれる
別にビルド構成に組み込めば済む話じゃね?くだらないな。
そんなことしなくてもソースコード中に普通のコードと一緒に書けるから
constexprはtemplateと組み合わせたときに真価を発揮する。
templateを実体化するときに、型や非型引数に加えて、変数や関数なども活用して複雑な条件をつけ、
実体化するコードをカスタマイズできるようになるからね。
constexpre定数って配列の要素数に出来るということ以外に本質的な意味ってあるの?
そのへんがよくわからない
「constexpr 中3女子」でぐぐると変態コードがたくさん出てくるよ
constexpr int f();
constexpr int a = f(); //OK
const int b = f(); //NG
違いってこれだけでしょ
constexpr以前でも定数伝搬とか意識して書いてたところはあったはず、でもそれが本当に定数になっているのかはアセンブリ見ないと分からない
constexpr導入によってconstexpr変数の初期化は確実にコンパイル時に実行される、できなければエラー
同様の理由でconstexpr関数(コンパイル時にも実行可能な関数)が導入される
単なる#define定数の代わりとしても名前空間が使える分価値はあるし
例えばconstexprでCRCを計算すれば文字列switchが可能になるとか難しいけど便利ではある
それ普通にヘッダーファイル生成コードでも書いた方がいいだろ。。
そっちのが明らかに可読性、デバッグのしやすさ上だし。
こんなもんありがたがってるのはどうせmakeもまともに書けない連中だろう。
そうやって何十万ものヘッダファイルを生み出した例を知ってる。
>>583
c++の規格内で完結するのと、make等の外部ツールを使うのとでは移植性が全然違うよ。 同じ記述でソースコード内に式が書け関数が使えるメリットは可読性に大きく影響するだろうに
configure なんて外部ツールを使ったソースファイルやヘッダーファイルを生成しまくりですが、新しい車輪の再発明ですか?
configureは古い。GitHubやるならCMake一択。
configureより100億倍マシだとは思うけど
それはそうとしてwindowsでpkgconfig使わせて
CMakeって使いづらいよね
ターゲットの属性指定するのに
属性が先にくるんだもの
Visual Studio(C#)のプログラミングに関する質問です。
インクルードする2ファイルが、双方のクラスを互いに必要とするケースにおいて、
コンパイルが通らなくて困っています。(当たり前なのですが…)
【Aファイル】
クラスAの定義{
クラスBの使用(インスタンス作成、メソッド利用)
}
【Bファイル】
クラスBの定義{
クラスAの使用(インスタンス作成、メソッド利用)
}
【全体インクルードファイル】
#include Aファイル
#include Bファイル
【コンパイル結果】
Bクラスが存在しません(Aファイルにて)
【質問】
お互いにクラス定義を必要とする場合、
★具体的に★どのような実装をすれば良いのでしょうか?
本当に複雑な計算が必要な定数なんてそんな多くないだろうに。。
やっぱバカしかいねーのな。。
>>596
前方宣言ありがとうございます。猛烈に調べてみます。
indexという構造体を作ってstd::vectorにぶち込んだらgcc8でエラーになるのだが。
ダメなん?
ideoneでやってみると通るんだけどな。
そのままコピペしてもgcc8だと通らない。
なんやねんこれ。
どうせそのクソ構造体コピーもムーブも出来ないんだろ
定義貼ってみ
deleteした後のポインタに0やnullを入れることを「仕様」にしないのは何か理由があるんですかね?
たとえばポインタのコンテナを扱ってる場合、
deleteしたポインタをコンテナから消そうと思ったら
その仕様だと逆に不便じゃね
>>604
・ポインタが右辺値だったら意味ないから
・今どきもうユーザーコード内に new, delete は出てこないから >>604,606
そんな貴方にスマポ。具体的には unique_ptr, shared_ptr。 >・今どきもうユーザーコード内に new, delete は出てこないから
こういう決めつけはどうかと思うんだよなぁ
とか言ったらまた荒れるんだろうな・・
というか理由は単にゼロオーバーヘッドだろ
ポインタを一時変数に代入していた時点で意味無くなるし
void*とかで持っていたらどうするつもりなんだか
スマポでdeleteは排除できてもnewはいるだろ
make_sharedに渡すのってT()がいいのかnew T()がいいのか分からない
>>602
それが、indexという名前がダメらしくて、アンダースコア一本付け足すだけで通るんだよ。 その環境の標準ヘッダを書き換えたバカがいるとかじゃね
>>613
コンストラクタのパラメータ渡すもんやろ WindowsのSleep関数みたいな変態マクロが実装されてるとか
さっさと元ソースとgcc -Eとgcc -dM -Eの結果貼るか死ぬかどっちか選べ
使われているだろ
少なくともGoogle、アップル、MSでは主要言語のひとつだよ
今をときめく人工知能のライブラリのほとんどはPythonの皮+C++のコアっていう構成だぞ
あれだけPython重点だったChainerもmasterにC++の自動微分マージしたしな
>それが、indexという名前がダメらしくて、アンダースコア一本付け足すだけで通るんだよ。
心当たりがありすぎるw
これは外には出せんなw
>>627
漠然としすぎでよくわからんのだがw
おれの周りだと、重い演算部分だけc/c++でライブラリ化するのはあるけど、
アプリを作るのはないな
c++使える人少ないし >>635
printfはフォーマット文字列を言語ごとに切り替えればいいけど、streamはハードコーディングになってしまう 具体的にどんな場面で困るのか例を挙げてもらうと助かる
>>636
語順変えられへんわ、引数がハードコーディングだわで
printfも変わらんやろっての >>638
streamでも文字列をリソース使えばいいだけやで 「Aさんが所有するBをCしますか?」という文章を多言語対応すると、ABCの並びを各言語に応じて変える必要があるでしょ。
書式指定で引数並びを変えることができないprintf()やiostreamでは対応不能。JavaやC#のような対応が正解。
>>640
streamだと文字列リソースが細切れになってもとの文字列が何だったかよく分からず翻訳者にそのまま渡せないって問題はあるかも。
いずれにしても、c++の文字列formattingは更新が必要 string_view、constexpr、templateを使えば、C#風のフォーマットも実現できそうな気はする。
とうとうstreamへの何癖もここまで頭おかしくなったか
>>643
それはコンパイル時に決定してしまうからだめだな。
ロケール設定に合わせて動的に変えられる仕組みではない 型指定文字間違えたら簡単に飛ぶscanf系
飛ばないけど書式文字列と書きたい値の型合わせが必要なprintf
まー、ostreamは数値の精度指定とか面倒っちゃー面倒だが
目くじら立てて本質的に駄目って話と違うからなぁ。
結局、eof までデータを読んで vector に格納する、の正しいやり方が分からない。
リードエラーまで気にするのはやり過ぎだとしても、空行がある場合などにも正しく動くものを作るにはどうするべき?
下のコードでダメな場合ある?
駄目じゃないとしたらもっと洗練されたやり方ある?
vector<double> invec(string filename){
vector<double> A;
ifstream fin(filename);
double temp;
while(not fin.eof()){
fin >> temp;
A.push_back(temp);
}
return A;
}
そのコードじゃむしろどのパターンでもダメじゃね
最後がダブって格納される
while(fin>>temp) {
A.push_back(temp);
}
>>649
そのwhileの条件ってtempにEOFが入ったら抜けるってこと?
double型の変数にEOFを入れたら何になるの? istreamのoperator boolはEOFでもtrue返すから無限ループだぞ
じゃあ
while(fin>>temp, (int)temp!=EOF) {
A.push_back(temp);
}
は?
>>651
いやdoubleの読み込み失敗するからfailになるだろ
空白読み飛ばすだけならeofしか立たないが any や、Automaticallyで、機械にやらせてる。
>>653
> そのwhileの条件ってtempにEOFが入ったら抜けるってこと?
ではなくて、doubleが読み込めなかったら false になるのですね
ありがとうございます 質問です。
単純なforループ処理の途中でエンターキーを押したらストップ、もう一度押すとスタートみたいなことをするにはどうしたらいいですか?
対象がコンソールか、ウィンドウかで違う。
conio.h使える環境で、コンソールだったら、_kbhit()と_getch()使えば実現はできるが、ウィンドウプログラムの場合はウインドウの作法に則る。
コルーチンは言ったら、少し楽になる予定??
>>656
fiber使うとか?
APIが環境によって違うのが難点だがコルーチンより融通効くし。 >>659
MITライセンスな~~っ。
暇だから書いたけど、自分の環境のVS2017だとこれしかわからない。
環境依存ちょびっとあるからご注意。
#include <iostream>
#include <cstdint>
#include <limits>
#include <thread>
#include <conio.h>
int main() {
for (std::intmax_t i = 0; i < std::numeric_limits<std::intmax_t>::max(); i++) {
std::cout << i << "\r";
if (_kbhit()) {
_getch();//output first key in.
std::cout << "Wait key in."<<"\r";
_getch();//wait next key in.
std::cout << " "<<"\r";
}
}
return 0;
} >>660
スレッドスリープするかもと思って、threadのヘッダーはいってるけど。使わなかったのを忘れていた。 独自定義したクラスAのlistに、プッシュした場合、新しいインスタンスが作られる?それともアドレスの代入??
list<A> List=new.....;
A a();
List.push(a);
>>649,653,655
俺は個数指定して読み込むということしかやったことないんだが、この方法って他の型でも使えるの?
int だったら
> doubleが読み込めなかったら false になる
というのが成立しないように思えるのだが ユーザー定義型なら演算子をオーバーロードするんやで
>>665
doubleじゃなかったら、じゃなくてEOFを読んだらfalseになるんだろ
こういうのお洒落なやり方だと思うがなんとなく怖いから俺も個数決めてやってるよ
スタンスの問題 まあテキストファイルと言っても普通はフォーマットがもっと厳密に決まっているから、一行読み込んでパースしてって感じでやるな
エラー起こったときにこれじゃ行数すら出せないし
その場合でもgetlineをwhileの中にいれておけば期待した動作になる
最後の行に改行があろうが無かろうがうまくいく
mainより上で
struct test{int x=0};
struct test obj;
obj.x=99;
ってやると三行目がエラーなんだけどなんでダメなん?
技術的になんでダメなのか教えてください
>>671
関数の外で
a = 2;
とか
a = a + 1;
は書けません T f();
auto a = f<Type>();
auto a=std::make_shared<A>();
みたいな感じで
実数と複素数のジェネリックプログラミングってどうやるの
実パラメータの数が違うから、結局ほとんどの機能を特殊化してるんだが
>>682
std::complexとテンプレートを 複素数と実数をジェネリクスでまとめると大抵死ぬぞ。
行列ライブラリなんかも基本別関数だから。
>>684
やらないのが正解ってことで良いですか? 理由?やる理由がないからだよ
できるからというだけの理由で無駄な汎用性を持たせようとして無駄に複雑で使いづらい糞が生み出されて結局使われないパターンを嫌というほど見てきたわ
うーんそういうもんかね
ある型について定義したジェネリック関数群全てを特殊化するはめになって
もうこれ型パラメータの意味ほぼねぇな
ってなったことはあったけど
パワー系がいて、通り過ぎる人が眼鏡をかけていれば「メガネ、メガネ」、胸の大きい女性なら「オッパイ、オッパイ」と特徴を呟いていたんです。
私は「ヒゲ」と言われたのですが、ひげ生やしていないんですよね。
誰かこの暗号解ける?
>>692
一応関数インターフェースの統一ができるから… std::complex使えばおおよその計算はdoubleその他と共通化できない?
虚部実部を見に行かない範囲ならなんとか
そこまで無理に場合分けして共通化させるなら初めから
独立に定義したほうがいい。
しっかり勉強してきた奴ほど無理やり継承ツリーでまとめようとする傾向にある。
それが行き過ぎると無駄なジェネリックの登場となる。
コルモゴロフ複雑性は計算不能なのだから
プログラムのあるべきコンパクトさについて一般論は存在しない
この点プログラムの記述方法の選択はまさに個々人のセンスに依存したartであり
真に人間らしい営みであると言える
仮に実数と複素数を継承関係にさせるとして、どっちを親にすべきかで広い合意は取れないからな
円楕円問題と同じ
たとえすべての関数を特殊化することになったとしても、大部分のifを共通化できるはずで、他のクラスのテンプレ引数として区別なく使えるようになるからそれなりに意味はあるでしょ。
意味はないよ
そもそも複素数なんて仮にそれを多用する分野のタスクだったとしても実数に比べて使用頻度は低いんだから、
タスクで本当に必要なものだけを実装すればよい
いや、実数が使えたためしがないから、俺の爺ちゃんが量子を考案したのだが。
高校のとき、心のお兄ちゃんとか心の妹とか流行ってたな。
29=(5+2i)(5-2i)
こんな風に因数分解して欲しくケースなんてほとんどないだろ。
変にポリモルフィックにやるべきじゃない。
は?c++でジェネリクスやろうとすればデフォルトで使うことになるだろ?
ボケちゃったのかな?
えっそうなの?
C++でジェネリクスてtemplate使うから継承とか関係なくね
例えば実数と虚数に対応するplus関数を作るとしてどういう実装を想定してんの
>>707
テンプレートによるstructual subtypingはポリモーフィズムの実装の一種だよ conceptはともかく現行のc++のそれを構造的部分型とは言いたくない気持ちがあるのは分からないではない
マルチエージェントシミュレーションをしたいんですけど、環境と個々のエージェントのクラスはどういった関係で持てばいいんでしょうか
現在はエージェント・環境の全部のインスタンスを進行を行うクラスに持たせています
しかし個々のエージェントが相互の情報を知りたいときに相互にアクセスできるようにするにはどうしたらいいでしょうか?
全てのエージェントが全てのエージェントの参照を手にするのはどこで書き換えが起こるか分からなくなるのでしたくありません
>>710
お前は街にいる人間全員のパンツの柄を知っているのか?
意味のあるシミュレーションをやるからにはエージェントが知ることのできる情報の範囲や内容は明確に定義されていなければならないはずだろう
その定義に従った情報を取得する手段がエージェントに提供されていればよい 例えば互いの距離を知りたい場合どうすればいいですか?
>>712
神クラスが更新対象のエージェントと周囲の各エージェントとの距離を予め計算し、更新対象のエージェントに計算結果のセットを渡す
そして更新対象エージェントはその結果セットの内容のみに従った行動をするだけ
それをエージェント毎、ステップ毎に繰り返す
実際に必要とされるまで計算を遅延する等、効率化のための実装の工夫は必要だろうけどね あらゆる数値型二つを引数にとるdistance関数を定義しろ
あとは二人の心の位置を表す型で特殊化しろ
STGの当たり判定やガンパレの頭から伸びるラインだろ
神のような仲介者mediatorを置けばいい
神クラスが全エージェント間の距離を計算し続けるのはエージェントN個の完全グラフの枝
N*(N-1)/2個の長さを更新し続けるということであっていかにも無駄が大きい少なくともエー
ジェントが置かれる環境のデータ表現と「互い」とは何かが定義されねばならないありがちな
環境表現としては二次元座標のリストとか正方形や六角形のセル表現とかがありがちで「
互い」というのは普通はエージェントの感覚器と環境(遮蔽物とか)とのインタラクションで規
定されるように作るからそういったブツもシミュレートせよ
>>714
まずは心の距離を定義するところからはじめよう 質問よろしいでしょうか?CORBAってもう古いですか?
CORBAのサンプルをこねくり回して送受信するオブジェクトを2つと一時停止や終了をコントロールする
オブジェクトを作ったのですが、お互いに送受信すると思ったら片方が送信しまくって受信が検出できな
いようで困ってます。送信を止めると前に送ったものを受信します。
送信する時に少しsleepを入れると遅いですが思った通りの動きになります。
出来ればsleepなしで動いてほしいのですが、omniORBって同時に送受信できないのでしょうか?
CORBAの動きはよく分からんあれ本当にまともに動くのか
d1の実部 d1の虚部
d2の実部 d2の虚部
...
か
d1
d2
...
というフォーマットのファイル(の名前)が与えられたときに、前者なら複素数として、後者なら実数として読んで vector に格納する関数ってどう書くべきでしょうか
auto f(std::filesystem::path const& n)
{
using T=double;
auto ret=
std::vector<std::complex<T>>{};
std::ifstream in(n);
std::string line;
while(std::getline(in,s)) {
std::istringstream ss(s);
T r{},i{};
ss >> r >> i;
ret.emplace_back(r,i);
}
rerurn ret;
}
【速報】金券五百円分とすかいらーく優侍券をすぐもらえる

① スマホでたいむばんくを入手
② 会員登録を済ませる
③ マイページへ移動する
④ 招待コード→招待コードを入力する [Rirz Tu](スペース抜き)
今なら更に4日18時までの登録で2倍の600円の紹介金を入手
クオカードとすかいらーく優待券を両方ゲットできます。
数分で出来ますのでぜひお試し下さい valgrindって今も使われてますか?
通信にBoost.MPI、ファイル入出力にHDF5を使う並列プログラムをInfinibandなネットワーク環境で走らせてるんですが
valgrindにかけるとアホみたいにエラーが出てうんざりします。
シコシコSuppression Fileを用意するしかないんですかね
vectorなりstringなりの各要素をfor文で回すとき何も考えずに例えば
for(int i = 0; i < v.size(); ++i)みたいなコード書いてたんだけどさ
C++プライマーで勉強してたらやっぱsize_typeとかautoとかイテレーターとか使ったほうがいいのかなぁって
signedかunsignedかなんてまず問題にならないようなちょっとしたループでも気をつけるべき?気をつけてます?
要素インデックスを表現する変数にはint型を使わずsize_t型を使うようにする、とかかな。
nposによる未検出判定があるから仕方なしにだけど。
んなくだらんことで悩むくらいならその外側で監視するコードでも組んだ方が100倍生産的だわ。
ループ変数にsize_t使うのを徹底しようと思い立ったことも昔あったけど
operator[]とかにsize_t変数入れると「intじゃない!!!ムキー!!!」って警告ほざくクソライブラリがこの世に多すぎて挫折した
今や64bitコンパイラが普通だからintよりも暗黙な64bit対応としてsize_tを使うこと増えたんじゃないかな。
intみたいな32bit変数のままだとコンパイル時に警告が大量に出るし、とりあえず無難にsize_tにしとくわ的な感じになってる。
size_tは符号ありにすべきだった
と誰か反省してたよな
ホントめんどくさい
その前にビットサイズ付きintでかかれるケースが増えるだろ。
BigInteger書いてるんだけど、補数表現がわけわかめで死にそうになってる。
ウィキペディア頼りで加減算はできたけど、掛け算どうやるねん。
そこで、補数で小学生にもわかるレベルの補数表現の解説プリーズ。
そのままunsigned同士の掛け算すればいいんじゃね?
で長くなったbit数の結果からMSBから変わる直前まで好きなように切り詰める。
>>743
とりあえず4bitで正数、負数を使った四則演算を手で紙に書いて解いてけば理解できないかな コピーコンストラクタを避ける目的でswap使うことってありますか?
俺転職するわ

会社に行っても仕事しないのに、リモートワークとか無理だわ
給料は働いた分だけでいいならリモートワークやりたい
>>747
インディーゲームデベロッパでリモートワーク・・年収500万から800万・・・
怪しい匂いしかしない・・ void func(int& n){...}
int main(){int a = 0; func(a)}
こんな感じで関数の引数が参照のとき呼び出す側は変数そのまま突っ込みますよね
これなんで&aにしないんですかね。型がちげーよって怒られそうなもんですが
基本的なことだと思うんですけどどうもググっても大丈夫な理由が見つからないもので
そもそも
int val = 0;
int& refval = val;
みたいな書き方もしますよね。やっぱり左右で型違うよねって
ポインタならint* p pval = &valって&つけるのに。どうなってんでしょ
>>750
ネコぱらがアホみたいに売れたから気前よくなってる可能性 template <auto N>とかできるんだな。
カッコつけずに byref とか予約語作ればよかったんだよ。
同様に関数の後に=0でpure virtualとかバカジャネーノ。
参照ってもともと演算子オーバーロードのための機能なので
呼び出し側でなんかさせるわけには行かなかったんだよ
>>759
参照とオーバーロードにどういう関係がありますのん? 専門家が深く考えて議論して決めたことを素人が批判してて草
>>752は、operator->()をみたらしぬ >>761
= 0 だけならまだしも
= default とかあまり深く考えてなくね?
まあ後付で言うのは容易いよな
って言われたらぐうの根もでないがw Cの古い文法を(ほぼ)そのまま残した上にC++を作ったから
いきなりC++から勉強すると気色悪いと感じる面もあるかもな。
ポインタと参照が同時期に言語に入ってたら、
int a; // 通常の変数
int &ra = a; // 参照
int *pa = a; // &演算子なしで暗黙にポインタに変換
てな書き方になってたかも知れん。
void func(int n);
void func(int *pn);
void func(int &rn);
これらは曖昧で解決できない、になってたかも。
>>765
ポインタのポインタやキャストのこと考えたら、その例のような暗黙のポインタ変換とか持ち込むとかえって混乱やミスの元になりそうだし、現状の仕様もしかたないものかなと思うよ 参照引数に結果を代入とかたまに使うけど呼び出す側から分かりやすいようにC#のout修飾子とかほしい
C#のoutは言われてみれば確かにって感じだけど、そうやって問題提起されるまではそもそも当然すぎて問題だと思われてなかったんだろうね
引数に代入することで呼出元へ値を返すのってfortranとかの時代から続く悪しき伝統だから
>>768
それconst付きかどうかで判断すべきと言うか判断するだろ? 世の中には引数にconst付けない糞ライブラリがあるんですよ
>>772
問題はそこじゃない
呼出元のコードだけを見たときにソース上で区別がつかないだろ
C#のoutは呼出元にも付ける必要があるんだよ
C++でも出力引数に参照渡しを使うことは禁止しポインタを使う流派があるが、
あれも呼出元を見たとき書換えの可能性の有無を&の有無だけで判別できるようにするのが目的 >>774
それいちいちつけさせられたらメンドイだけのような
どうせIDEで見りゃわかるのに class Person
{
public:
Person& set(int);
private:
int age;
}
Person& Person::set(int num)
{
age = num;
return *this;
}
*thisを返す関数ってことで大雑把にこんな感じのサンプルが本に出てました
メンバーセットするだけならわざわざ本体の参照返す必要無くない?voidで良くない?って思ったんですけど何かメリットってありますか?
基本的には複数の値を戻したいならtuple返すべきだし、オブジェクトの状態を書き換える関数はそのオブジェクトのメンバにするべき
データ構造体を一部書き換えるような処理は、書き換えじゃなくて新しいのを作って返した方が読みやすいし効率的なことも多い
全部が全部そうとは言わないけど、参照引数は書き換え分かりにくいってブーブー言う奴のコードって大体汚いイメージある
>>776
operator=系は組み込み演算子と挙動合わせるために*thisを返すことが多い
今はあんまり推奨されないけどif(a=foo())とか書けるようにね
その例はif(p.set(40))とか書きたいのか、operator=系の話と混同してよく分からずに適当に書いてるか、そのどっちか >>776
メリットとは言い難いがこんなことが出来る。
a.setx(1).sety(2);
参考書でそれをやるならoperator演算子でやるべきだったな。 C++の言語仕様にケチつけたところでどうにもならんでしょ。
なにがしたいの。 >>2 にある「すっぱい葡萄」な人? 呼び出し側の制約がしたいならtemplateでちょこっと書けば出来るし
template<typename T>
struct Out {
T& ref_;
explicit Out(T& ref_):ref_(ref_){}
T& operator()() const{return ref_;}
};
template<typename T>
inline auto out(T& ref_for_out)
{
return Out<T>(ref_for_out);
}
void func(Out<int> const& v)
{
v()=1;
}
int main()
{
int i;
//func(i);
func(out(i));
}
>>761
専門家の意見は奴がもう少し構文解析勉強してればって意見だがな。
権威だけ気にするバカがほんと増えたね。 >>777-779
ありがとうございました。本は定評のあるC++プライマーなんで多分私が書いた例がなんかおかしいんだと思います
演算子オーバーロードは今やってるところではまだ出てきてないですね。>>779は実際本にも出ていましたがやはりそれがわかりやすいメリットになりますか メソッドチェーンか
Ruby, jQuery のマネw
Kotlin も真似してる
メソッドチェーンって便利か?
>>779の
> a.setx(1).sety(2);
も
a.setx(1);
a.sety(2);
って書けばいいだけだよね? 2個くらいならいいが
10個くらいつなぐやついて長すぎて改行するから結局同じ
メソッドチェーンの利点で調べてみたら名前付き引数みたいなことが可能とあったな。
//メソッドチェーンで設定してない値は初期値を使用
//コンストラクタとは違いチェーンしてるので値の設定の順番は自由
void test(data().year(2019).manth(12).day(24));
void test(data().manth(12).day(24).year(2018));
>>793
間違えて1つ抜かしたり重複しててもエラーにならない
デメリットの方がでかくね? >>795
重複したら後の方が優先されるし、抜けた分は初期値を使用するし...
ただし、それだけのためにクラスを作る手間はデメリットだと思う。
あくまで使い方の一例 >>796
> 重複したら後の方が優先されるし、抜けた分は初期値を使用するし...
だからいいってか?
抜けた部分はともかく重複をエラーにできないのは名前付引数に比べてデメリットでしかないだろ >>794
行数が増えるのに耐えられるのか?
俺はできない range adapter、C++20から使えるよ、メソッドチェーンだよ・・・
ようするにラムダ式をチェインさせればいいんだろ
かんたんじゃん
Lispの時代に近づいてるだけだ
>>798
理想的な名前付き引数が存在するなら「名前付引数に比べてデメリット」といえるんだろうけど、
C++には名前付引数ないよね? メソッドチェーンとかいらんわ
リファクタリングしにくいし
Kotlinのapplyがベスト
横に長いのがいやなんだよな
多少冗長でも縦の方がいい
特になっがいメソッドチェーンで途中から返り値変わってるやつとか殺意わく
>>802
そのうち追加されるだろうから待ってなよ >>799
行数増えるのになんの問題があるんだ?
横に長いとか見辛いし差分も取りにくいしメリットないだろ ところで>>776のような return *this; だとコピーが発生しないか?
return this;; として->でメソッドチェーンにするのならわかる >>810
普通はメソッドチェーンとかいらんけど
GUIのライブラリとかはそっちのほうが使いやすそうな気がする ちゃんとした設計になっていればどんなスタイルでもいいよ
sortの比較関数についてなんですけど
たとえばvector<int> v = {0, 1, 2, 3, 4, 5}があったら
bool compare(const int& num1, const int& num2) { return num1 > num2; }
sort(v.begin(), v.end(), compare)で降順になりますよね
なるほど、0< n < v.size()でどのv[n]とv[n+1]でもcompareがtrueを満たすように
並び替えてくれるんだな、って理解したんです
それで試しに
bool compare(const int& num1, const int& num2) { return num1 == (num2 + 1); }
って書き換えたんですけど降順になってくれないんです
どのv[n]もv[n + 1] + 1に等しい→降順になると思ったんですけど
評価関数ってどう理解したらいいんでしょう?
pred内でprintfデバッグでもしてみたら?
n番目ととn+1番目の要素以外でも比較が発生しているのがわかるから。
比較関数の右辺と左辺が入れ替えて比較した結果が矛盾してると、ソートは意図しない挙動になる。当たり前ではあるけど。
>>813 俺も理解せずに言葉だけ覚えてるんだけど、
比較関数の性質として「狭義の弱順序」を示さなくちゃいけないのだ。
「狭義の弱順序」でネット検索すれば分かると思うよ。
少なくとも俺の場合「自分には(今のところ)理解できない」ことが分かった。
…て言うか、誰か分かりやすい解説サイトなど紹介してください。 >>793
俺は好きだな。 jQuery みたいでかわいい 関数チェイン入るんかいな。
任意のコンテナにチェイン出来るフリー関数を書きたいお年頃なオレ。
最初はsp(10)sp(11)sp(12)sp(13)sp(14)
remove_ifするとsp(10)sp(11)sp(13)sp(14*)sp(14*) (*は共有)
sp(12)の参照カウンタがなくなったので破棄される
普通の挙動では?
ムーブするからsp(10)sp(11)sp(13)sp(14)sp(null)か
結論は一緒だけど
参照カウンタ増やさない方法で移動されてるのかな??
インプレースだから、扱いが雑な気がする。
まあremoveの外側はunspecifiedだからどうするかは実装の勝手
雑に扱われてても文句は言えない
各位、どうも
なんとなく分かってきました
cpprefjpでも「有効だが未規定な値」とのこと
実装依存で参照カウントが減ってゼロになるときもあるよ、そういうmoveもされ得るよ
ということですね
とりあえず返却されたイテレータが示す範囲は正常だと思うので
erase()はそのまま使う方向でいってみようと思います
雑とかそう言う話ではなく
remove_ifの実装でremove後の空きshared_ptr部分に後の要素をどうやって詰めているかだけの話
swapじゃないなら、代入にせよmove代入にせよ、その場で参照カウント減ってデストラクタが呼ばれるよ
実装がとある一つなのだから、変数に持ち直してやるのもオーバヘッドがーという場合もある。
コンテナ上の空き領域の作り方も幾つかあって、
今回は疑似ポインタだからコピーが軽いけど、実態をいじるときは涙目になるきがす。
実装を定義してないはずだから言いようはいくつかあるけど、
インプレースでやるときは面倒だということだけ知っておけばよい気がする。
整数の事情って結局どうするのが正しいの?
powは遅いだの何だの以前にdoubleとの間で一々キャストするのが姿勢として正しいように思えない
マクロでやってる人が多い?
>>833
整数値で指数みたいな物を扱う場合、簡単にオーバーフローが起きるので
本気でやるとしたらだいぶ恣意的なサイズ区切りを入れることになる。
そんなことやるくらいなら浮動小数からのキャストのがだいぶ楽だし実装も安定する。 負の数が指数に与えられたら結果は少数になるけどそれでもいいなら
底が2でない3乗以上の累乗なんか整数でやろうと思ったことないな
整数の冪は速度云々よりオーバーフローが気になる
100を5乗しただけであっという間にuint32_tをぶっちぎるんだぞこえーよ
n乗してオーバーフローする整数は予め求められるんだからn乗する前に判定するだけだろ
>>843
判定のためにdoubleにキャストして、みたいな? >>846
100がオーバーフローする最大値なら100と予め整数比較するだけだろ なるほど n=100くらいまで全て持っていればいいと。
まあそうかもな。
C++知らないことが多すぎてちょっと勉強するだけでもあーあそここれ使って書いてればよかったーってなることばっかりだわ
しばらく前に書いたコード見直したくねぇ
そのうちこれわざわざこれ使って書く必要なかったなになるゾ
それはない
コンテナはやっぱり便利
動的ポリモーフィズムは必要ねえなぁ
テンプレートで十分
>>836
modpowは自分のライブラリとして持ってるので、それ使うことにすれば良いですかね
機能過多な感じもしますが
>>837
?
普通の挙動ですよね?
>>839
ありがとうございます。読んでみます
結果によっては素直にpowを使うことにします
>>840
今はマクロでそうしてます テンプレートもそろそろガンだってことが普通に認識されるようになるだろうな。
標準のテンプレートだけ使ってりゃいいんだよ(それでも使いこなせないだろうが。)
バカの作るテンプレートライブラリほどひどいものはない。
そりゃ堂々巡りの言い方だろ
酷い奴の作るテンプレートライブラリは酷い。そりゃそうだ
テンプレートライブラリが酷けりゃ作ったヤツは酷い。こうなるわな
>>852
>動的ポリモーフィズムは必要ねえなぁ
データの通りにオブジェクト作るような設計一切出来ないぞ いやテンプレート「ライブラリ」ともなれば十分な機能と性能と使いやすさを全立させるには必要スキルがダンチになる印象
そうではなくて問題に特化した形でテンプレートを使ってコードの記述量を激減させることは常人のもできる
ただし他人に理解してもらうのが困難になるからそういのうはモジュール内に囲ってテンプレートそのものを外に出さなければ宜しい
もし使いにくいとか理解しがたいだけでなく動作品質に問題があるなら、
その場合は問題のある人物が取り替えられる方向へと管理者のソーシャルスキルの発動の時間である
正直アプリレイヤーでテンプレートを駆使したライブラリを作ることはあんまない
使う側からすれば便利な仕組みだわ
これがライブラリを提供する側になると途端に言語仕様と環境との闘いが始まる
テンプレートは、コンパイラのエラーや警告が意味不明なのが玉にキズ。
>>861 と >>865 は文面は異なれど、意図として
同一の内容を繰り返してるような気がするんだが。
「同じ話を何度も投稿する人に対する敵意」ってくくり。
これは単なる感想(自己言及的で面白い)だけどね。
発言に対しての賛同でも否定でもなく。 だったら無駄なことしてないで直接乗り込んで二度とライブラリを作れないようにしてこいやゴミ
1. より優れたライブラリを提供すれば良い
2. 労力の関係で0スタートで新規作成は無理ということであれば
糞ライブラリをうまくwrapしてせめて使いやすい形にして見せれば良い
3. 2の場合も中身は追って作り直すこと
4. 自身の頭脳がへっぽこだと、高度すぎるライブラリは全く理解できない。
自分が使いこなせないものはダメである。
わたしの頭のレヴェルに合わせろ。
俺なら使いこなせるって持ってきたやつが一番使えてないパターンなんだが。。
持ってくるwww
2ちゃんガイジのくせに偉くなったと錯覚してて草
エモーショナルエンジン搭載。
その日の気分で結果が変わります。
仕事で無駄に時間かけてテンプレート使ったライブラリ(という名のほぼ何もしないクソコード)書かれたら殺意も湧くだろうな、ネットでもそういうのはたまに見かける
熟練者が長年かけて作った、良くできたフリーのライブラリしか知らんアマチュアの人にはわからんかもしれんが
そんなもん飼ってる上司の責任だろ
糞ができるまで放置してたのか?
俺は仕事でそんなの見たことないけど>>854の肩を持ったまでだよ
>>854以降の流れを読んでからほざけ テンプレートってそんな身構えるようなものかな?
外部ツールとマクロで武装した旧黒魔術系のコードに比べたら、なんぼかましな気がするがw
もちろん便利にはなったけど、STL以来むやみにテンプレートを持ち上げる風潮が・・・
初心者が上級者を気取りたくてテンプレート持て囃し、それだけに留まらずオブジェクト指向や昔ながらのテクニックをこき下ろしてるのを良く見かける
実行時、コンパイル時、プリプロセス時でそれぞれメリットデメリットあるんだけどなぁ
プロ(仕事)の話と初心者の話が一緒になっちゃってるな
初心者を指導せずほったらかしにしてる上司がいるらしい
>>854は「普通に」って書いてるけど、
バカがテンプレートライブラリを書いてそれが仕事に害悪をもたらすなんてことが
普通にあるわけがないだろ。
仕事なら出来る奴に書かせるし、趣味なら仕事には無害。 できる奴が書いたテンプレートライブラリを使いこなせない奴が、グダグダ文句言っているだけだろ。
言っている奴ができる奴なら文句言う前に修正しているわ
まあマクロとかテンプレートとかみんな一度はやり過ぎるぐらい作り込んだことあるだろ
多分>>854をそれを経験した直後ぐらいなんだろ 無職がおしごとごっこでつか?w
以下、職業プログラマじゃない者は書き込み禁止
お前らautoとdecltype(auto)の違いとか言語仕様の話しで盛り上がれよ
イテレータを受け入れる関数もオーバーロードで書いてるんですか?
>>886
逆だろ
プロがこんなとこに来て語ってる方が異常だわ auto int i =0;
K&Rはこれでいけたんだがのう
decltype(auto)はあまり使わないなぁ
長いし
面倒だからauto&&で受けちゃうし
戻り値推論もauto&とかで済ましちゃう
>>884
こういうクソな思想が広まってるからクソライブラリがあとを絶たないわけだ。 クソクソ言うだけで、何がどう悪いとすら具体的に例を上げないのだからもうね
>>892
(´・∀・`)ヘー
アマチュアさんはそう考えるんだね >>898
え?お前だけだぞこんな底辺まで来てるの
もう少し世間体とか気にしようよ utf8の文字定数って実質ASCIIしか使えないのかコレ
>>898
アマチュアをからかうプロwww
エンジニアがそんなんじゃ日本の将来は暗いわ ていうかテンプレートが絡むととたんに問題解決できなくなるプロ
テンプレートの問題なんてもう語り尽くしたわ。
それでもバカがあと立たないのもずっと見てきた。。
テンプレートの問題について何も聞いてないし、その状態で語り尽くしたというなら何も問題はないな。
新規参入者がいるってことだから恐悦至極なのではないか
(果たして彼にとってはテンプレートのみが例外的に特殊な問題であって
テンプレート以外については十分なスキルを有しているのであろうか…
コンパイル時に発見できるような問題はそもそもたいして深刻な問題ではない。
>>907
コンパイル時にわかる程度の問題でも、ランタイムでエラー吐かれたらデバッグ大変だよ
Pythonの型違いで嫌と言うほど思い知った >>908
私は、ランタイムエラーを解決することの困難さに比べればコンパイルエラーなんて大したことない、という意味で言ったんだが。
あなた、読解力がないって遠まわしに指摘されること多くない? そもそも文脈不明な中でそれだけ書かれてもなぁ
コンパイル時の分かるような問題かどうかではなく、エラーをコンパイル時に吐いてくれるとデバッグが捗るみたいに書けば良いのに
実際、assertやstatic_assert
SFINAE使ってのなるべく上位レイヤーでエラー発生させるのは重要でしょ
テンプレート駆使したライブラリ使うと最適化ありなしで速度かなり変わるの困る
デバッグビルドだとくそおっそくてデバッグがままならん
なんか良い解決法ないですかね?
適当なところで切る
処理の定義を別ヘッダに分けて、特定のソースファイルで定義ヘッダを読み、デバッグが必要ないところは最適化Onで明示的インスタンス化をする
>>911,912
> 処理の定義を別ヘッダに分けて、特定のソースファイルで定義ヘッダを読み
自前の切り替え処理自体が不具合の原因になりかねない。
素直にprintf()するのが一番確実でしょう。 C++14以降でテンプレートのデザインパターンの参考書って無い?
>>912
ソースファイルごとに最適化変えるのって簡単にできます?
VSプロジェクトかCMakeで VSならプロジェクトじゃなくソースのプロパティ選んで最適化変えればそこだけ反映される
まあ、それ用の構成作っておくのが安全
CMakeはわからん
makeなら簡単だけど
c++の場合、このコンパイラでは通るけどこっちのコンパイラでは通らないとかが
普通にある方が問題。
静的だとか動的かとかそういう問題とはまた違う。
>>918
コンパイラごとに違う言語なんだから当然では?
むしろコンパイラが1つしかない言語以外でそういう問題が発生しない言語ある? Java、C#は「コンパイラが1つしかない言語」に含む?
どのみち比較の対象が少ないね。
「コンパイラが通らない問題を解消するためにビルドツールをご用意いたしました。」
で、configureやらcmakeやらantやらといった車輪の再発明が続々生まれてくる。
モダンなC++を学ぶべく右辺値参照について勉強しているのですがさっぱりわかりません
本に右辺値参照は実際は左辺値でstd::moveは実際は何もmoveしない
と書いてありましたが本当に意味がわからない
言葉遊びはいいからわかりやすく教えてくれ
>>927
正確に言うと右辺値参照が左辺値なんじゃなくて右辺値を参照している「変数」が左辺値なのさ。
それ自体ひとつの変数なんだから当然のことだろう? >>927
誤解を恐れずに言うと、std::moveを付けると、&&が付いた特殊な型になる。その型のことを右辺値参照という。ムーヴコンストラクターやムーヴ代入などは、その特殊な型に対して行われる。 &&が付いた引数は、中身の所有権を他の場所に譲り渡すことができる。
例えば、文字列クラスだったら、ポインタが指し示す文字列の所有権だ。所有権をコピーせずに、移動するだけなら、処理コストが低くて済む。
>>930
所有権って何ですか?
私は一つの関数で new/malloc() した領域を、別の関数に渡し、さらに別の関数で delete/free() してますが、効率よくそういうことをする場合には所有権という架空のフレームは邪魔だと思います >>928
あーなるほど確かに変数に代入してる時点でそうですね
右辺値参照を保持する左辺値ということですね
納得です
>>929
std::moveに渡す型も&&ですよね
&&をもらってさらに特殊な&&を返すんでしょうか?
remove_referenceとかその辺がさっぱりです
なぜこれが必要なのか
さらにその型で所有権が移るというのもよくわからず 右辺値というのはほっといたら消える。
どうせ消えるんだったら右辺値が確保してるメモリ、こっちでちゃんと解放するからもらうね→所有権の移動
もちろん所有権移動したので右辺値でメモリ解放しちゃダメよ。
>>933
所有権が移るというか...
T&& x を引数に持つ関数(コンストラクタが多い)は右辺値を受け取るけど、
そこで x の所有するリソースを
分捕っていいという「慣習」「イディオム」があるというだけなんだよ。 class STRING
{
public:
...
// ムーヴコンストラクタ(一例です)。
STRING(STRING&& s) : m_ptr(nullptr)
{
std::swap(m_ptr, s.m_ptr);
}
// ムーヴ代入(一例です)。
STRING& operator=(STRING&& s)
{
std::swap(m_ptr, s.m_ptr);
return *this;
}
protected: char *m_ptr;
};
...
STRING s("abc123");
STRING t;
t = std::move(s);
右辺値参照で挫折したら、Rustに進むがいい。
C++を完全に理解した人間は1%も居ない。
難しいというよりただ複雑
概念的にそれほど難しいわけではない
ムーブセマンティクスは今世紀最大の発明と言われてるからね。
最近は標準ライブラリも文法も分かりやすくなったなと思ったら
initializer_list絡みの初期化がこのやろう
・仮引数が右辺値参照&&なら、そこに渡した変数はぶっ壊される(そのかわり速いかもしれない)
・ただし安全のために使い捨ての一時変数か、std::moveを付けて「壊していいよ」と明示したものしか渡せないようになってる
これだけ理解してればだいたいOK
ややこしいとか言う奴に限ってパターンの一覧表作っていつでも参照できるようにしないよな
このスレを読んだらだんだんわかってきました
>>937
なるほど
この例で使い方は何となく理解できたかもしれないです
abc123を一切コピーすることなく引き渡しているということですね
コンストラクタに右辺値が渡された時は自動的に&&のコンストラクタがよばれ(これはコンパイラが自動で判断してくれる)
コピーでは明示的に右辺値参照にしないとダメなのでstd::moveを使うと 【 constexpr の掟】
「ブッ殺す」と心の中で思ったならッ!その時スデに行動は終わっているんだッ!
>>931
所有権というのは権利を連想させるようないかにもお得な感じを醸し出しているネーミングだが
その実体はオブジェクトの開放を最後の一人だけがやる「義務」に他ならない
で、「最後の一人だけに開放させる」というのを>>931のように
>別の関数に渡し、さらに別の関数で delete/free()
というのは大悪手に他ならない
なぜなら呼び出し先で最後かどうかなど(所有権やレキシカルな手法では)管理し切れない
所有権は呼び出し元ががっちり掴んでおくもの moveしたあとの変数を使おうとしたらエラー出してくれるの?
元の内容について所有権を失っているだけで普通は使える様になっている
スマポならnull相当
vectorみたいなのならemptyもしくは何らかのごみが入っているのでclearか新たに代入すればおk
>>953
>元の内容について所有権を失っているだけで普通は使える様になっている
moveしたあとの変数について述べているのなら完璧な間違いだ
藻前のプログラムはバグだらけだな 合ってるだろ
ムーブ後のオブジェクトは内容は未規定だけど有効な状態だぞ、少なくとも組み込み型と標準ライブラリはな
褒められたプログラミングスタイルかはともかく、再利用すること自体が即間違いとは言えない
>>951
ムーブコンストラクタを書いて自分で処理するんだよw コンパイル時に既に顧客の要求を満たしてるとかマジカッコいい
少なくとも標準ライブラリでこれが出来ないと、メンバ変数の内容一つmoveしただけで親のオブジェクトまで使えなくなる。
メンバ変数再利用する術が無いってことだからね
>>957
未初期化の変数をコンパイル時に検出できるんだからmoveした後かどうかも判定できるはずでしょ >>958
メンバ変数1つムーブって、どういうこと?
普通メンバ変数は右辺値にならないでしょ。 2分木で子のスマポ所有しているような場合、付け替えとかで所有権の移動するときshared_ptrならコピーでokだけど、unique_ptrみたいなのだとmoveする事になるが、メンバ変数で持っていた子の内容をmoveしたあとその変数が再利用可能じゃないと困るだろ
>>961
c++11で導入されたmoveはいわゆる所有権の移動とは違うもなので、その場合はmoveは使えないと思う。 >>962
unique_ptrのmoveが所有権の移動じゃないと言うなら一体何なら「所有権の移動」だと言うのか。 もともと右辺値参照とmoveセマンティクスの話じゃなかったっけ?
ループの中で int a なる整数を使うとき、ループ内で毎回宣言するのとループの外で宣言して使い回すのどっちが結局速いの?
範囲for文を使ってそんなどうでもいいことは忘れろ
>>967
逆じゃないか?
インスタンスの生成にコストがかかるときはトレードオフだが、そうでないなら可能な限りスコープを狭くなるように変数を宣言した方が良いと思う スコープ気にするならループ関係の部分だけでスコープ区切ればいいじゃん
cppcheckやVisual Studioのような静的コード解析にかけると「スコープを小さくできるよ?」みたいなアドバイスが出るよね。
実際のところ、どうなんだろうね。typoしにくくなったりスタックサイズが小さくなる利点があるとは思うけど。
ちょうど今朝cppcheckかけたら
style: The scope of the variable 'c' can be reduced.
「変数 c のスコープを縮小できますよ」って出たわ。
つまり「スコープを狭くできるなら狭くすべき」っていう方針を、
(少なくともcppcheckを作ってる人は)採用してるんだろうな。
どっちが速いかについては、ちょっと最適化オプションつければ
結局同じマシン語になっちゃうんじゃないかしら。
>>967
セオリーだからって鵜呑みにするの良くないよ
(というか文面だけ覚えても意味ない スコープ広いほうが良いなら最終的に全部グローバルにしろやになるやんけ
オブジェクト指向って実はprivate変数のスコープをかなり広く取ってるセミグローバル指向だと思う
>>977
それってクラスを大きくしすぎているだけじゃないか? この流れは関数切り出しをまともにやってない連中が多いってことだな。。
グローバル変数と言っているのはオブジェクト指向スレを荒らしてるバカだろ
任意の型に対応する整数を返すメタ関数ってC++11の標準であったりします?
intなら1
stringなら2
みたいな
上記の技法をなんと呼ぶかわからないので検索ワードも思い付かず…
質問ですがC++のクラスのメソッドは、大別すると、
コンストラクタとデストラクタとsetterとgetterと何になるの?
move? be?
ステートチェンジしていくのだから、動作になるのか?
setterとgetterって何?
Javaじゃあるまいしそんなの言語要素としては用意してないよ
>>991
setterとgetterが何かについてはググった方が良い
Javaは詳しくは知らないが、ググった限りにおいて
Javaでもsetter/getterを定義する専用の言語要素など用意されていない印象 で、C++/Javaどっちも
{ setter } ∪ { getter } ⊂ { メソッド }
であることは明らかだが、では
Q1. { メソッド } - ( { setter } ∪ { getter } )には何か専用の名前は無いのか?、
というのが>>909の質問の主旨。
ついでに言うと
Q2. { setter } や{ getter }というのは本当に確定した集合なのか?
と、
Q3. 「操作」と言ったときそれは{ メソッド }を指すのか { メソッド } - ( { setter } ∪ { getter } ) を指すのかどっちなんじゃ、
とかも知りたい >>994
シグナルとスロットというのはGUI操作を処理する目的のブツなので、
実行時の時間コストがゼロコストに近いことを気体されているハズ、
よって { メソッド } - ( { setter } ∪ { getter } ) の全て(この中には実行時の時間コストが青天井のブツも含まれる)を
包含しはしないのではないか、
まあここまで書いてオモタが、 { setter } ∪ { getter } こそ実行時時間コスト0を期待されるから、
setterやgetterは次の定義で良いのではないかという気がしてきた…
- 属性を取得する目的の操作であり、かつ実行時時間コスト≒0の実装が今現在も保たれているのがgetter
- 属性を変更する目的の操作であり、かつ実行時時間コスト≒0の実装が今現在も保たれているのがsetter 後ろ2行訂正orz、
正:
- 属性を取得する目的で設けられた操作であり、かつ実行時時間コスト≒0の実装が今現在も保たれているのがgetter
- 属性を変更する目的で設けられた操作であり、かつ実行時時間コスト≒0の実装が今現在も保たれているのがsetter
補足すると、「属性を取得する目的」や「属性を変更する目的」というのは、
インターフェースをクラスの主要な機能とは独立に変更できることを暗に言っている
例えばクラスFooのsetBar()が真にsetterならば、
属性をsetterでセットするのをやめて(Foo::setBar()を廃止して)ファイルから
直接読み込むメソッドFoo::readFromFile()に置き換えても、
クラスの主要な機能Foo::mainFunc()は変更せずに済むハズ
getterについても同様
operator=がsetterでoperator()がgetterにならない?
c++かどうかなんて関係ない、オレオレ分類しているだけだろ
ずれてるのを承知で書くけど、直接読み込むメソッドってやつも含め setter なんてない方がいいよ
mmp2
lud20190718082117ca
このスレへの固定リンク: http://5chb.net/r/tech/1554124625/ヒント:5chスレのurlに http://xxxx.5chb.net/xxxx のようにbを入れるだけでここでスレ保存、閲覧できます。TOPへ TOPへ
全掲示板一覧 この掲示板へ 人気スレ |
Youtube 動画
>50
>100
>200
>300
>500
>1000枚
新着画像
↓「C++相談室 part142 ->画像>13枚 」を見た人も見ています:
・C++相談室 part126
・C++相談室 part158
・C++相談室 part152
・C++相談室 part124
・C++相談室 part154
・C++相談室 part150
・C++相談室 part151
・C++相談室 part164
・C++相談室 part155
・C++相談室 part156
・C++相談室 part153
・C++相談室 part157
・C++相談室 part165
・C++相談室 part149
・C++相談室 part148
・C++相談室 part159
・C++相談室 part162
・C++相談室 part163
・C++相談室 part161
・C++相談室 part166
・C++相談室 part147
・C++相談室 part134
・C++相談室 part140
・C++相談室 part144
・C++相談室 part133
・C++相談室 part146
・C++相談室 part130
・C++相談室 part145
・C++相談室 part117
・C++相談室 part141
・C++相談室 part139
・C++相談室 part137
・C++相談室 part137
・C++相談室 part135
・C++相談室 part143
・C++相談室 part138
・C++相談室 part132
・C++相談室 part131
・C++相談室 part136
・C++Builder相談室 Part21
・0からの、超初心者C++相談室
・Cygwin + MinGW + GCC 相談室 Part 3
・Cygwin + MinGW + GCC 相談室 Part 8
・C++相談室 part123 [無断転載禁止]©2ch.net
・C++相談室 part129 [無断転載禁止]©2ch.net
・C♯相談室 Part20
・C言語相談室(上級者専用)
・MFC相談室 mfc22d.dll->動画>2本
・Mac G5 中古買入相談室
・河田さんによる人生相談教室
・MFC相談室 mfc23d.dll
・C#, C♯, C#相談室 Part79
・C#, C♯, C#相談室 Part75
・C#, C♯, C#相談室 Part78
・C#, C♯, C#相談室 Part93
・自営業 悩みごと相談室 16
・自営業 悩みごと相談室 40
・C#, C♯, C#相談室 Part94
・C#, C♯, C#相談室 Part91
・C#, C♯, C#相談室 Part90
・C#, C♯, C#相談室 Part97
・0からの、超初心者C#相談室
・C#, C♯, C#相談室 Part91
17:07:46 up 130 days, 18:06, 0 users, load average: 7.79, 8.26, 8.39
in 0.028505086898804 sec
@0.028505086898804@0b7 on 082606

|